计数排序(线性时间排序)
发布时间:2024年01月19日
背景
1954年由 Harold H. Seward 提出
基本思想:
假设:计数排序假设n个输入元素中的每一个都是介于0到k之间的整数
举例:10 个年龄不同的人,统计出有 8 个人的年龄比 A 小,那 A 的年龄就排在第 9 位,用这个方法可以得到其他每个人的位置,也就排好了序
年龄有重复时需要特殊处理(保证稳定性) 算法最后一步
优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法
当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序
算法基本步骤:
(1)找出待排序的数组中最大和最小的元素
(2)统计数组中每个值为i的元素出现的次数,存入数组C的第i项
(3)对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
(4)反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
计数排序伪代码
正常的思路
COUNT—SORT(A,B,k)
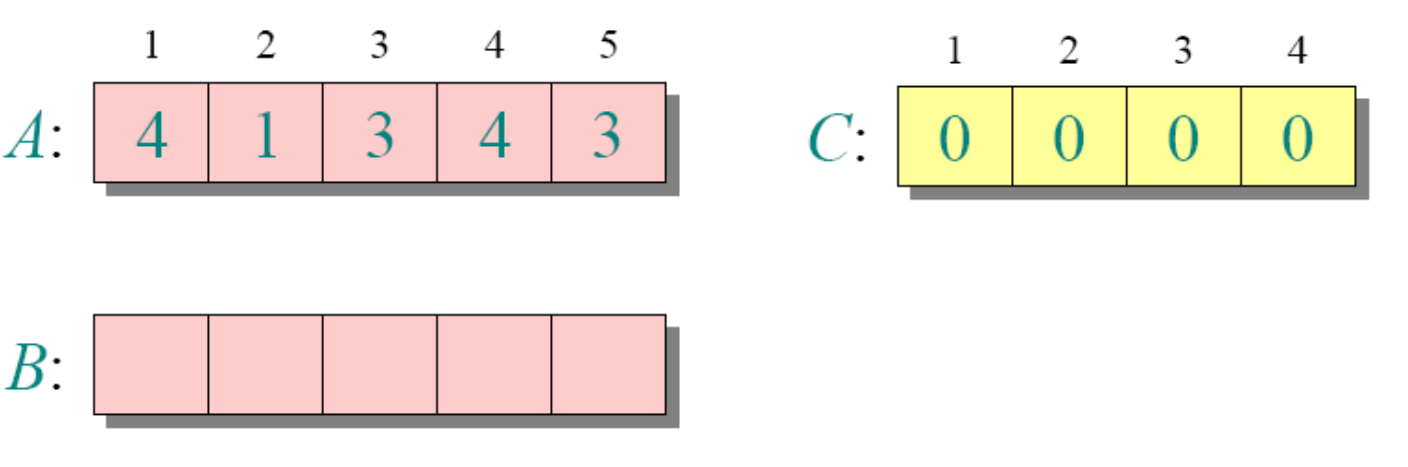
let C[0..k]be a new array
for i=0 to k
C[i]=0
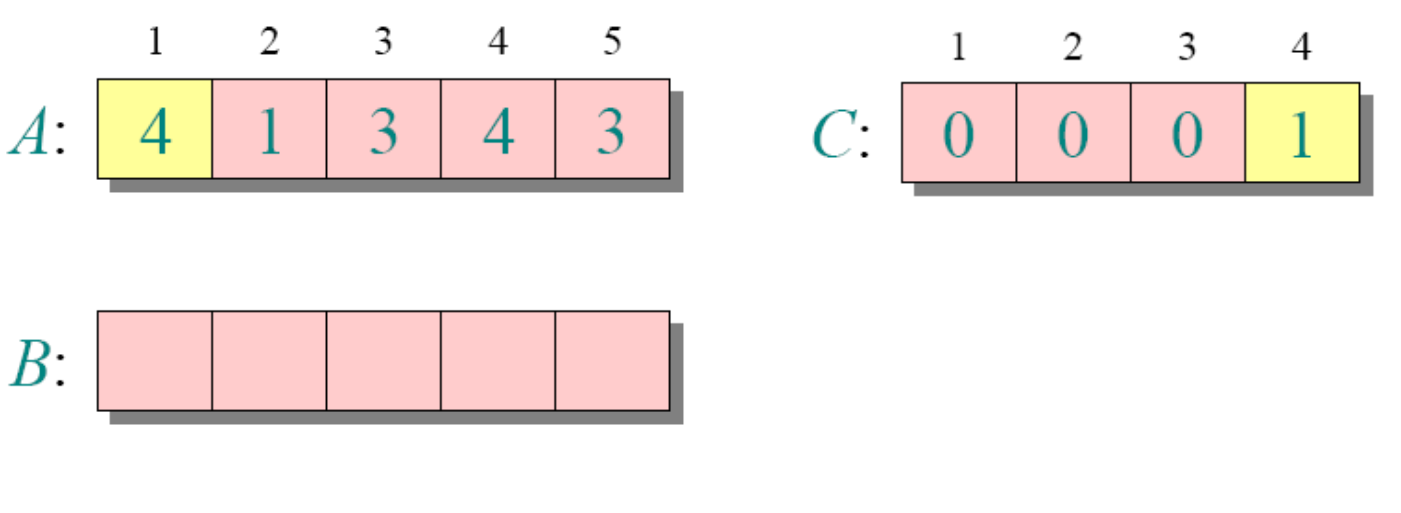
for j=1 to A.length
C[A[j]]=C[A[j]]+1
//C[i]now contains the number of elements equal to i
for i=1 to k
C[i]=C[i]+C[i-1]
//C[i] now contains the number of elements less than or equal to i
//在这里最终得出的C有这样的规律,A[j]最终应该放在
//下标为C[A[j]-1]+1~C[A[j]]的位置
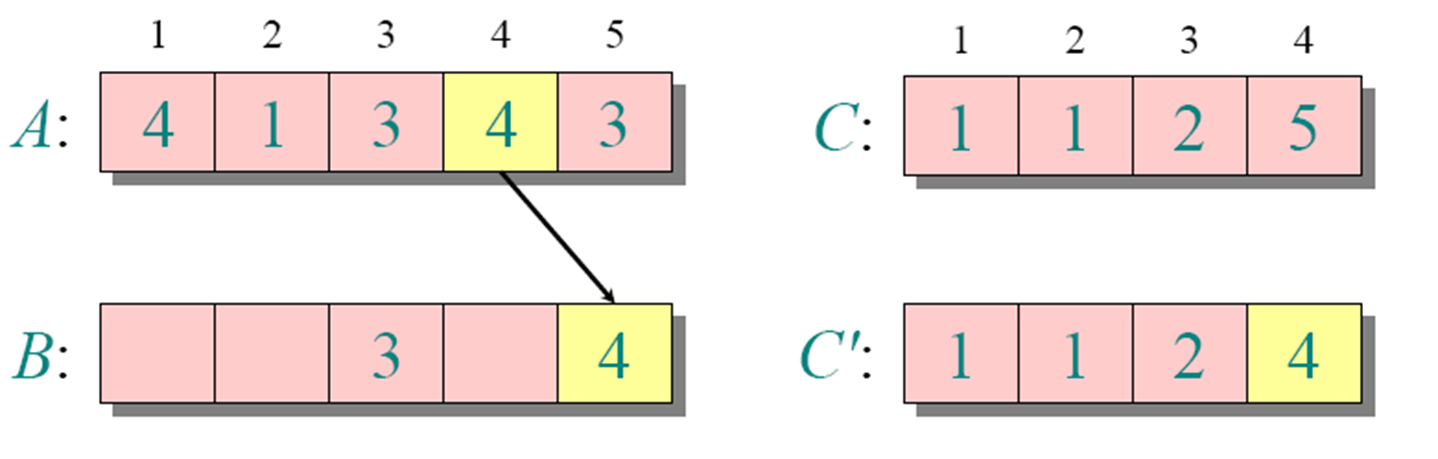
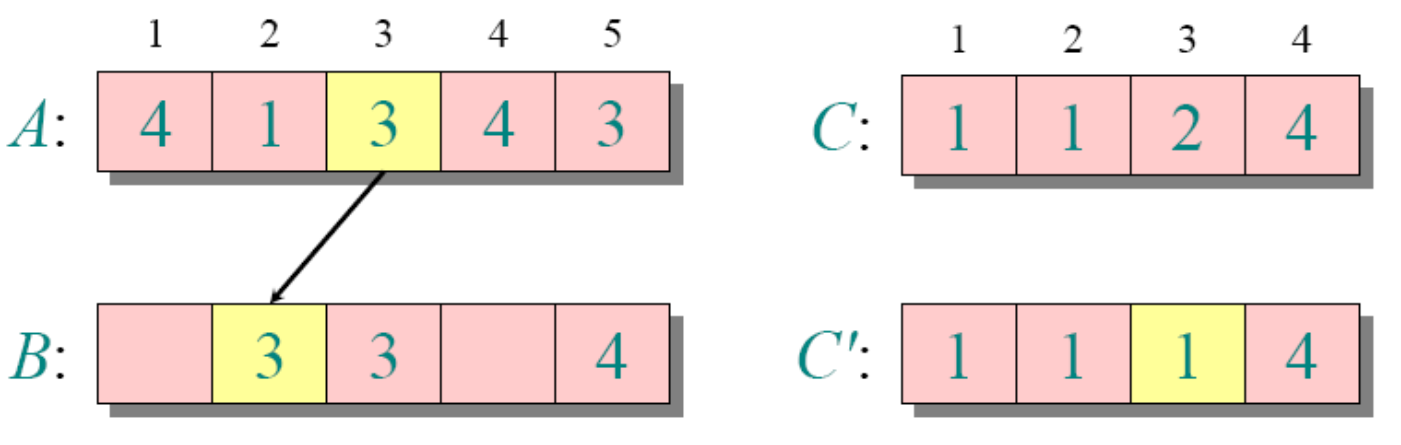
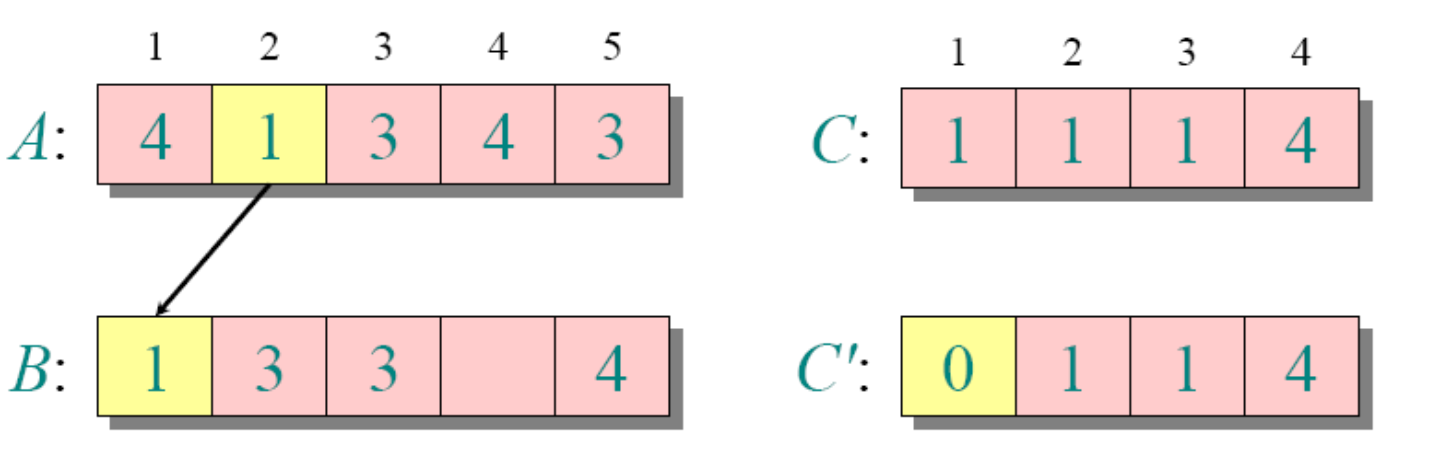
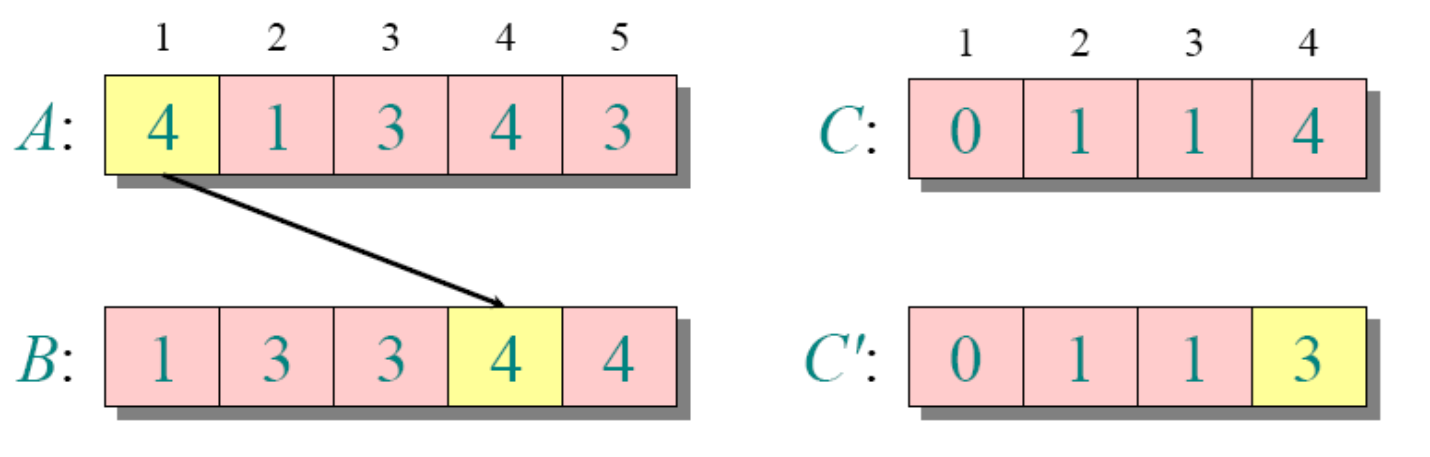
for j=A.length downto 1
//为了保持稳定性,这里从后面开始遍历了
//如果换成for 1 downto j=A.length,那么元素相等的地方刚好反过来
B[C[A[j]]]=A[j]
C[A[j]]=C[A[j]]-1需要注意的是k为A中的最大值-(A中的最小值-1)
另一种思路
如果第13行,我非得从1开始呢,但又想保持稳定性呢,该如何办
我们记得:
在这里最终得出的C有这样的规律,A[j]最终应该放在下标为C[A[j]-1]+1~C[A[j]]的位置
COUNT—SORT(A,B,k)
let C[0..k]be a new array
for i=0 to k
C[i]=0
for j=1 to A.length
C[A[j]]=C[A[j]]+1
for i=1 to k
C[i]=C[i]+C[i-1]
//这里需要单独处理一下,需要C[-1]=0
//当然下标不可能为负数,我们可以让下标整体都+1就可以解决问题
//这里为了方便与上面思路对照,直接认为C[-1]=0是允许的
C[-1]=0
for j=1 downto A.length
B[C[A[j]-1]+1]=A[j]
C[A[j]-1]=C[A[j]-1]+1
//这个思路也是稳定的计数排序举例(正常思路)
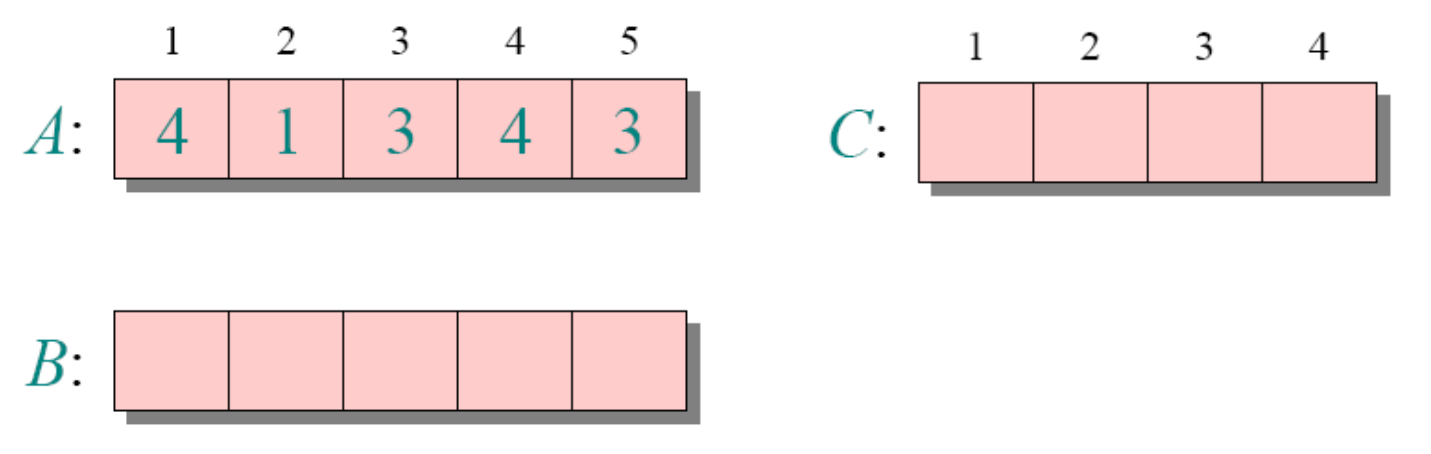
循环1
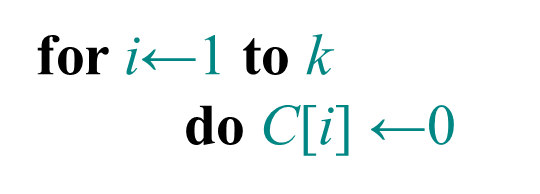
循环2
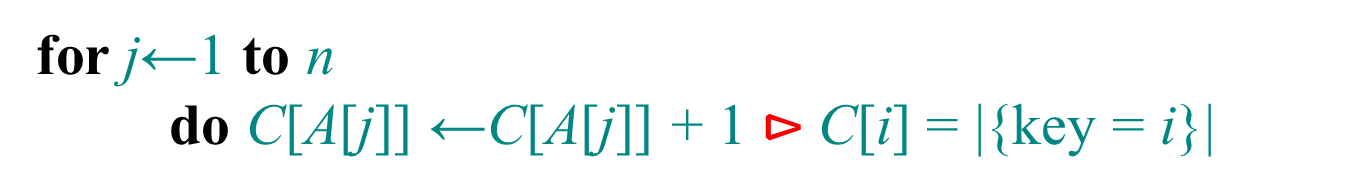
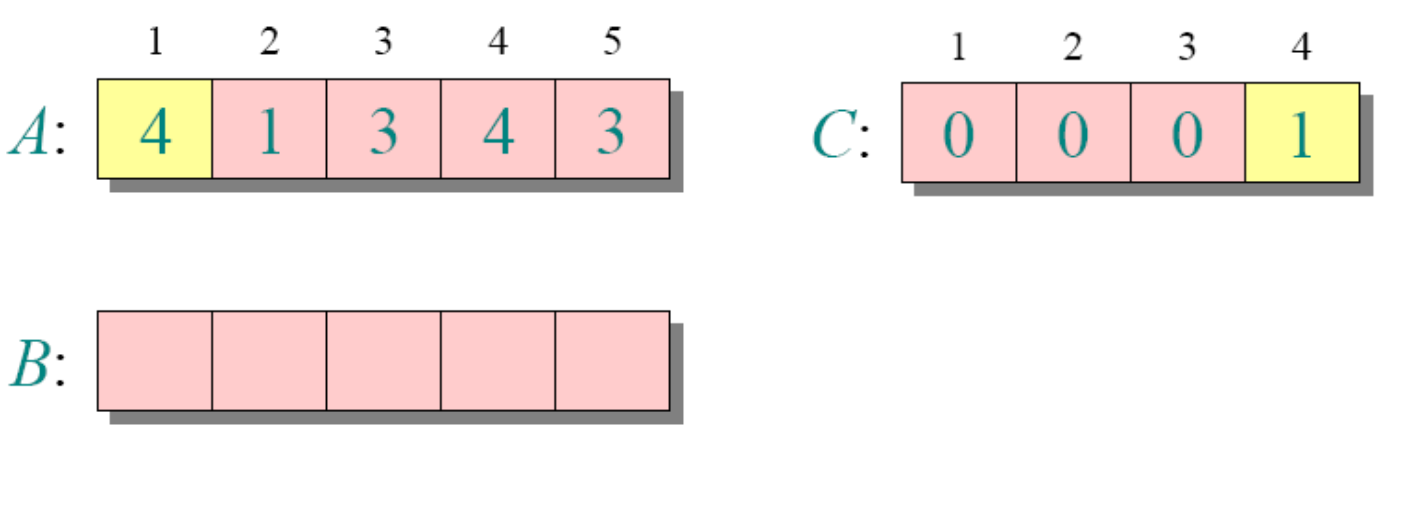
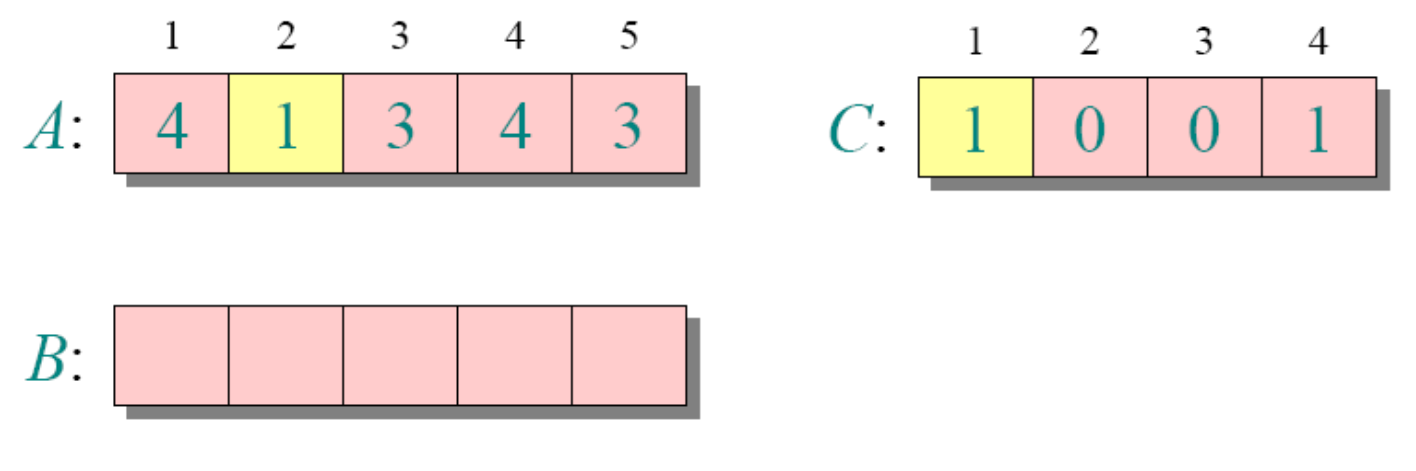
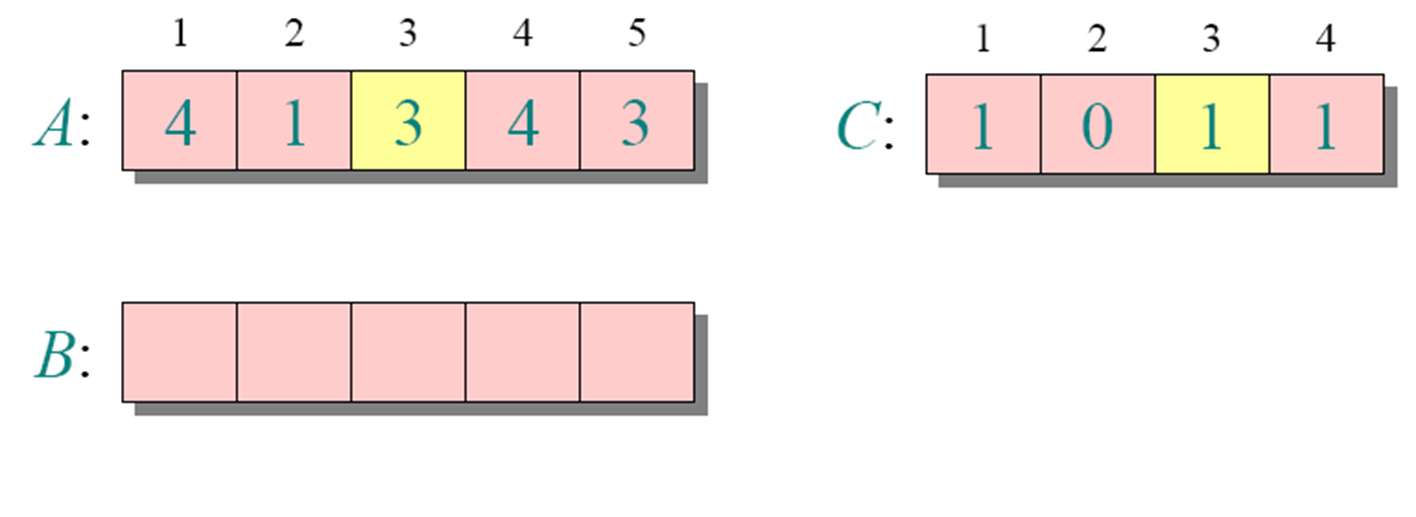
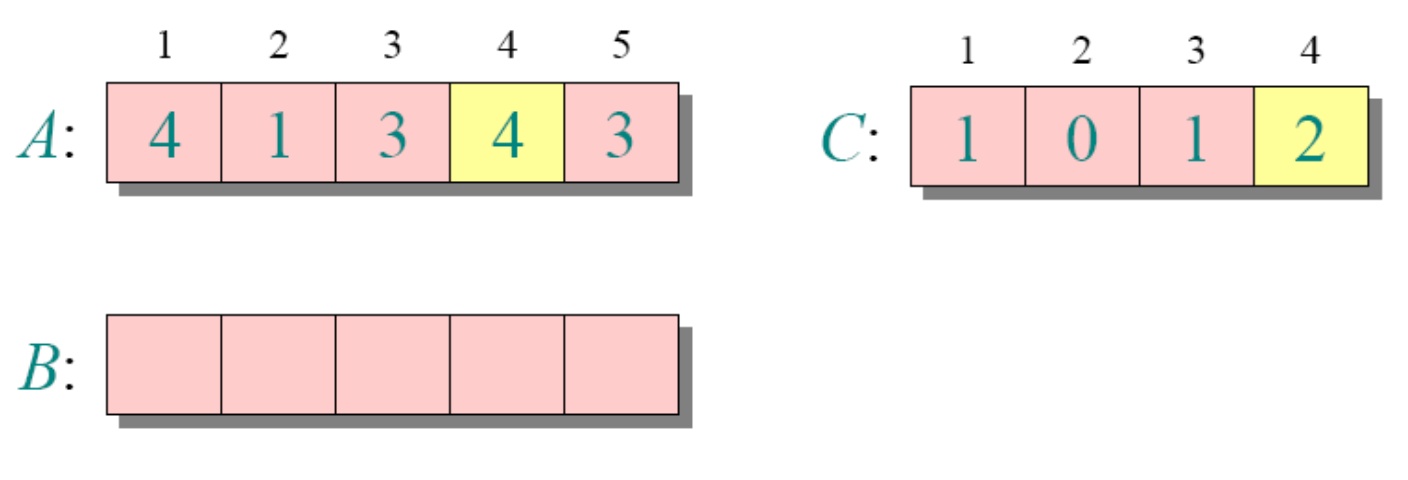
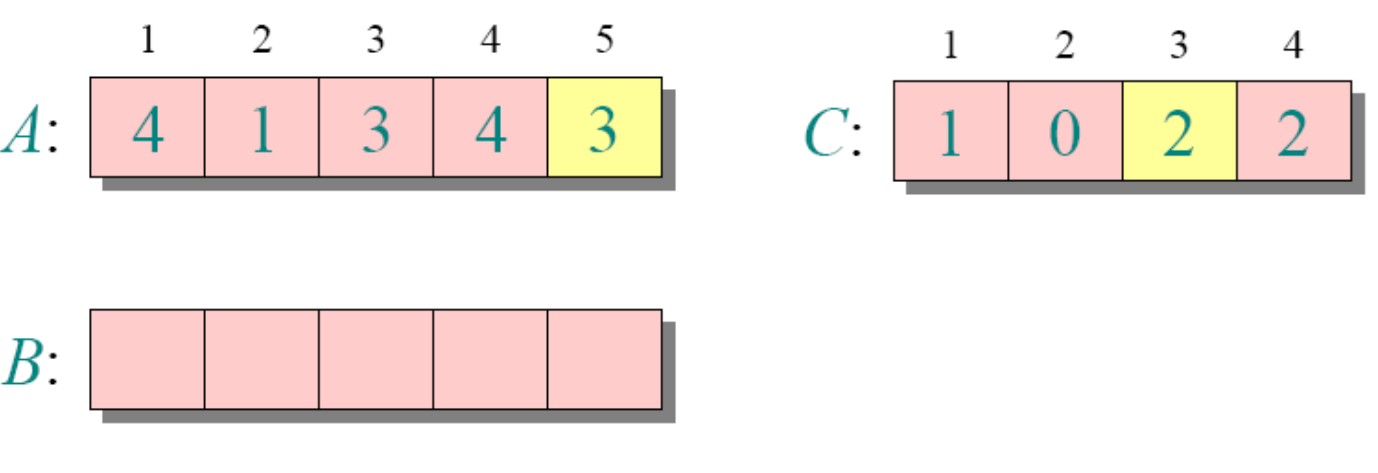

循环3
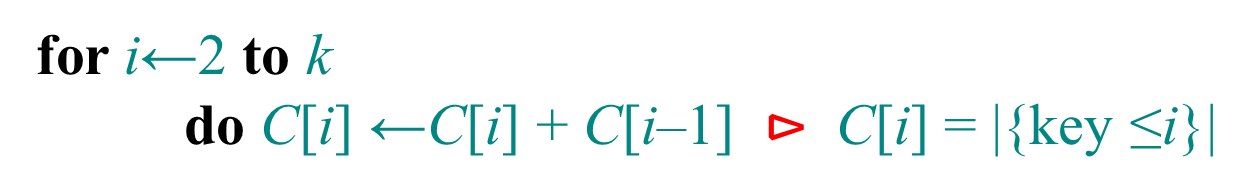
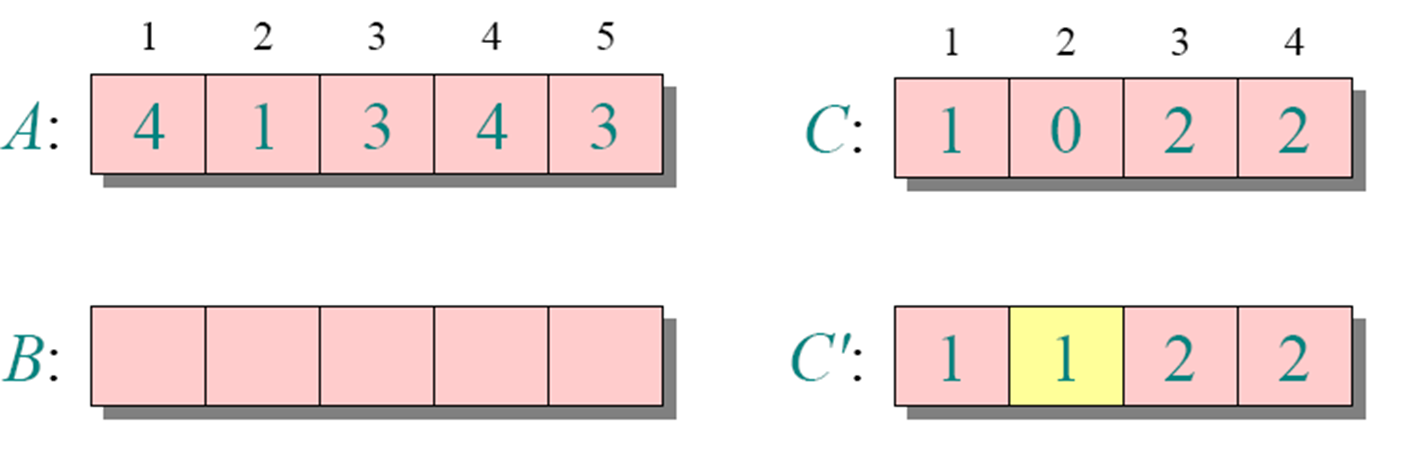
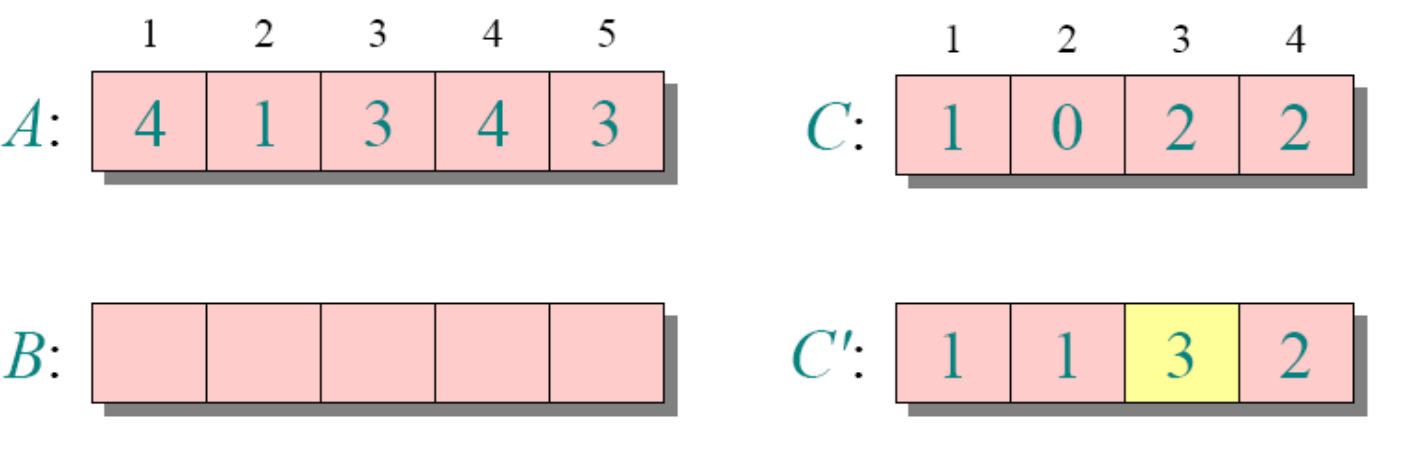
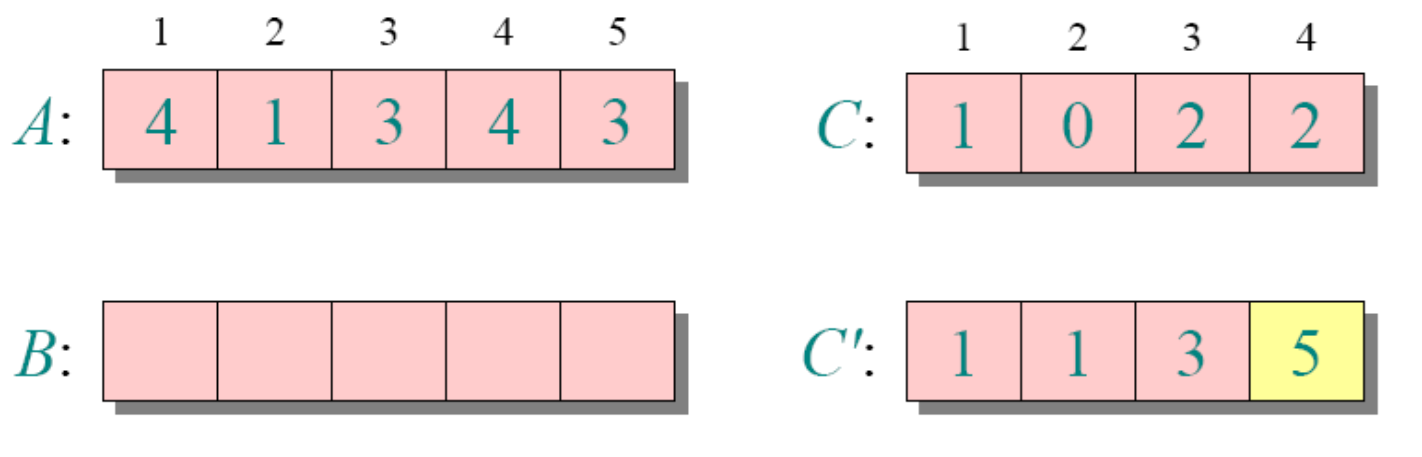
循环4
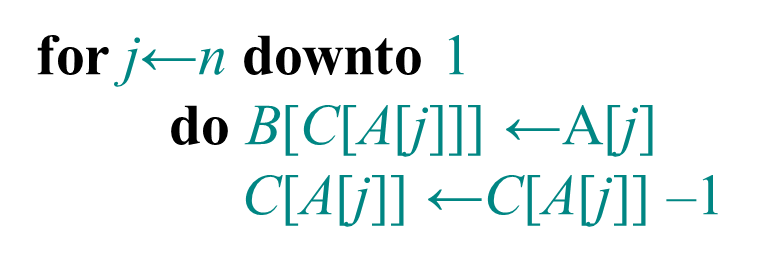
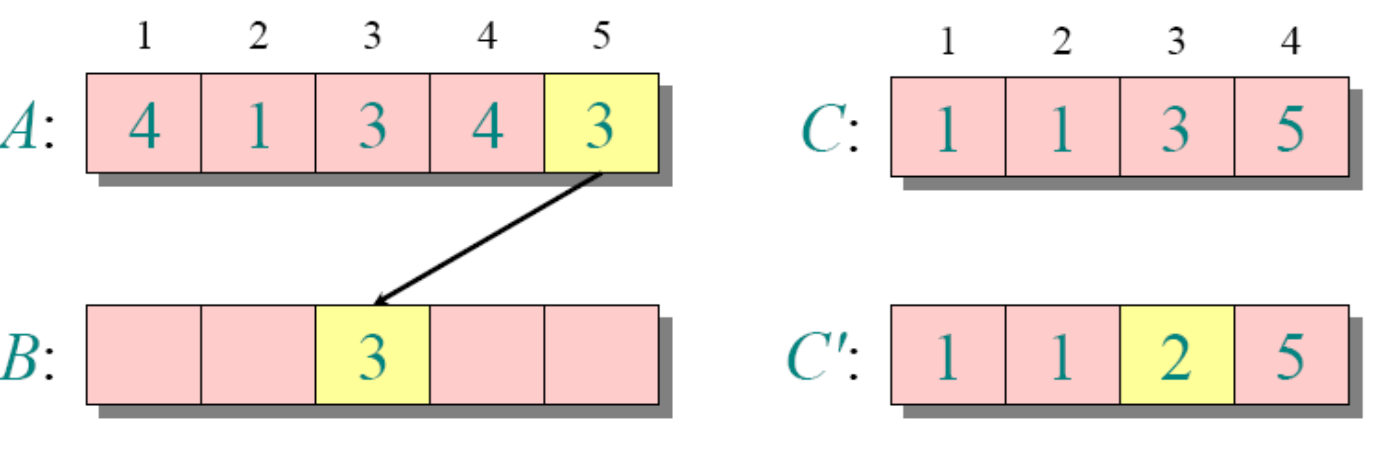
运行时间
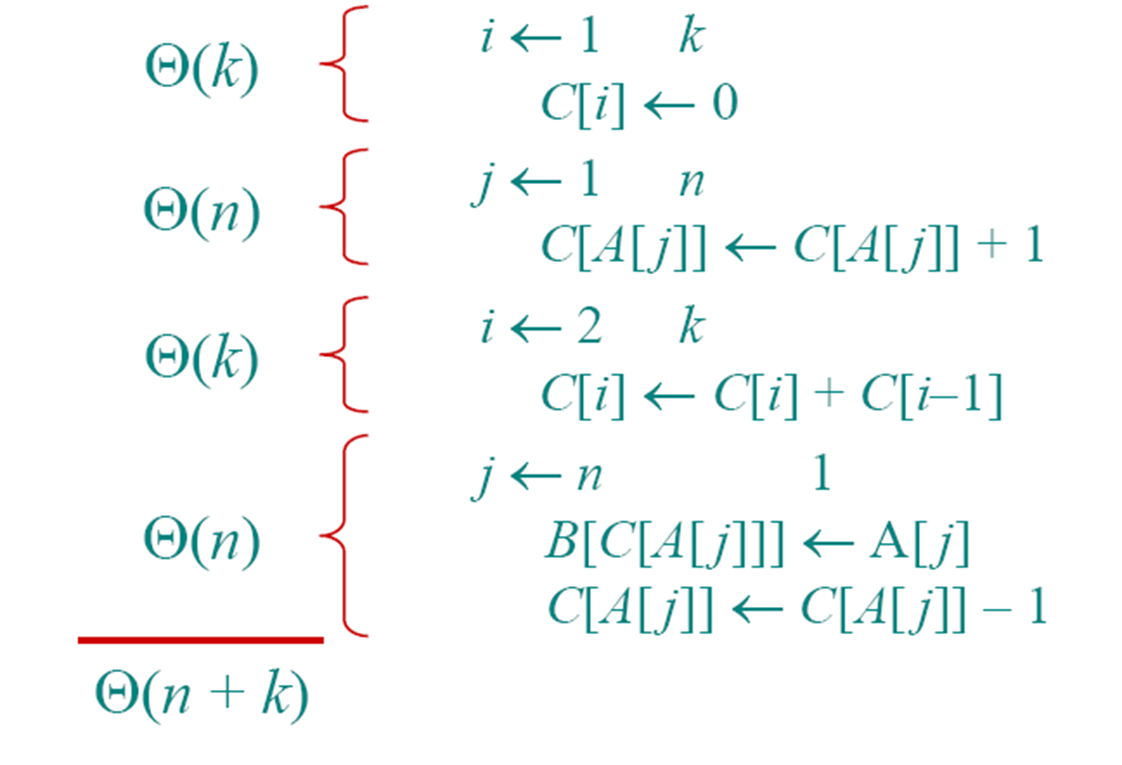

文章来源:https://blog.csdn.net/weixin_50917576/article/details/135703703
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章