Linux线程概念

1. 什么是线程
线程是进程的一个执行分支,线程的执行粒度,比进程要细
2. Linux中的线程
一个进程所享有的资源,都是提供地址空间来进行查看,也就是说地址空间是进程的资源窗口
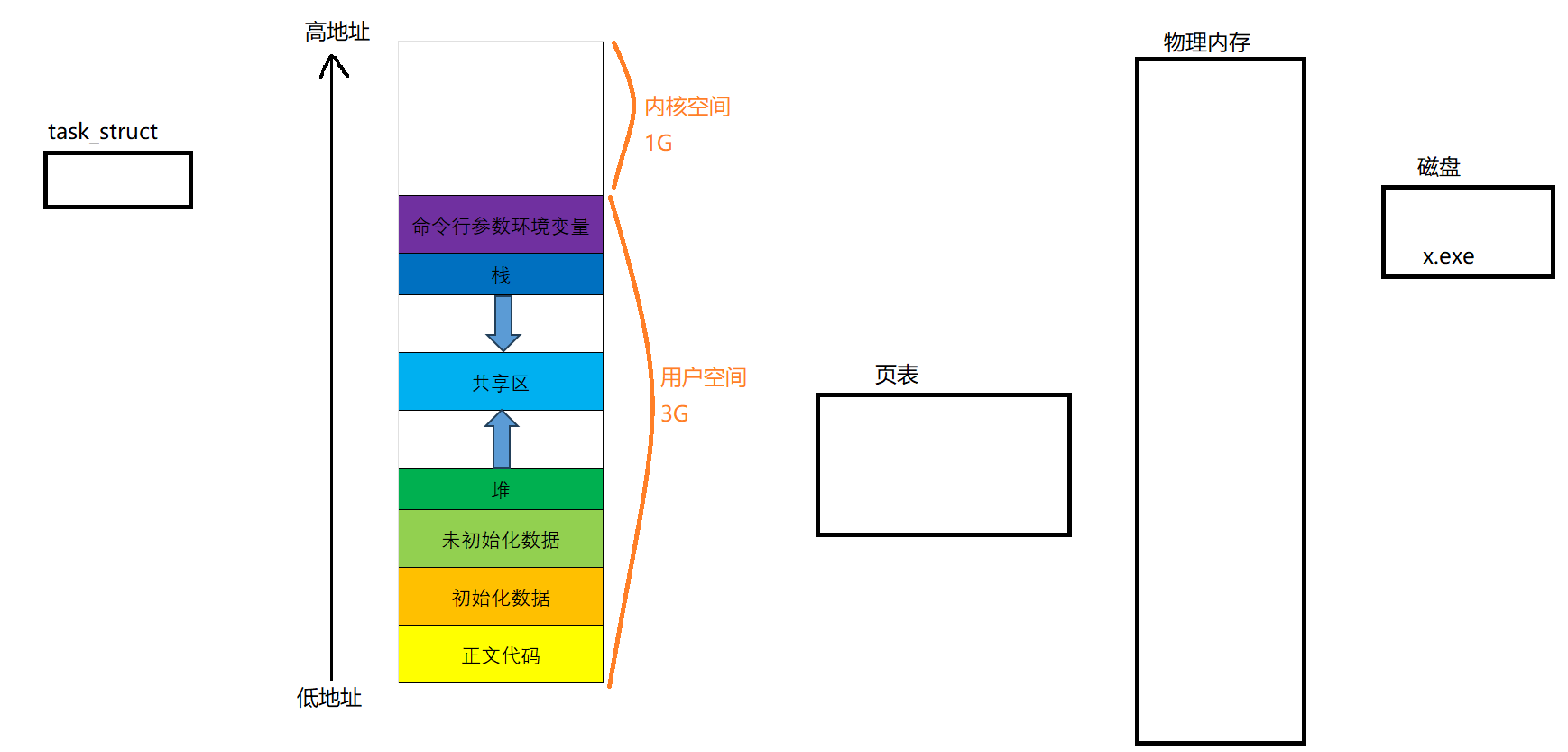
当我们在fork创建子进程的时候,又会再重新开一个这样的独立的PCB、独立的进程地址空间、独立的页表,然后通过映射到不同的物理内存块,所有这就有了父子进程各自独立。
而线程,只建立pcb,和进程共享地址空间,在进程的地址空间内运行,是进程的一个执行流分支
任何执行流要执行,都要有资源,而地址空间就是进程的资源窗口
在CPU的角度,它并不知道它调度的是进程还是线程,它只有执行流的概念。
所以,线程是操作系统调度的基本单位,进程是承担分配系统资源的基本实体(内核角度),线程是进程内部的执行流资源。
线程 <= 执行流 <= 进程
Linux中的执行流,又叫做轻量级线程
进程:
一大堆的执行流,独立的地址空间,页表,在物理内存中申请保存代码和数据的内存空间,这些整体才叫进程

在之前的角度看待进程,只有单个进程,这其实是操作系统以进程为单位,给我们分配的的资源,只不过这个进程内部,只有一个执行流。
在概念的角度,这个进程只有一个执行流是特殊情况;而在实际情况,一个进程一个执行流是正常情况
3. Linux线程管理
一个进程里面至少是有一个线程的,也就是说比例是1:N,那这些线程执行的时候,我们要知道当前的状态,执行到哪里了,要访问哪些资源,它属于哪个进程等等,所有,操作系统也要对其进行管理,还是六个字:先描述再组织。
对于Windows操作系统,它就是重新定义了一个数据结构来描述这些线程;而对于Linux来说,线程和进程一样,也需要调度,只不过它所需的资源少一点而已,于是就直接复用了进程的数据结构和管理算法,来模拟线程。
所有有些教材上说,Linux没有真正意义上的线程,而是用“进程”模拟的。
这句话并不完全正确,因为Linux的线程也遵循了操作系统的规矩,只不过没有单独为其创建线程的PCB。说用进程模拟线程,也不完全正确,因为线程只是用了进程的内核数据结构。
也正是因为Linux复用了进程的代码,所以它维护线程的成本降低,很简洁,那它的健壮性比其他操作系统要强。也就是Linux操作系统能在一些服务器上一直跑。
举个例子:
在我们国家,基本上都以家庭为单位进行社会资源的申请,在家里,我们一家人都有各自的“任务”(下面的例子无任何它意,只是单纯举个例子,还以实际情况为主):
爷爷养老,去公园打打太极什么的;爸爸出去工作;妈妈在家收拾家务,准备饭菜;孩子上学读书,好好学习。每一个都有不同的事情。虽然每个人的“任务”有所不同,但是都有一个主线任务,就是将这个家庭建设好。那么进程就可以看作是一个家庭,而线程就可以看作家庭里面的人,线程在进程内部运行。
4. Linux线程的资源分配
4.1 程序地址空间——页表
在CPU内有一个CR3寄存器,这个是专门用来保存页表的地址,用来快速找到进程所对应的页表。CR2寄存器,保存引起缺页中断异常的虚拟地址。
物理内存从CPU读到的地址是虚拟地址,而虚拟地址转换为物理地址,是通过页表转换映射的。
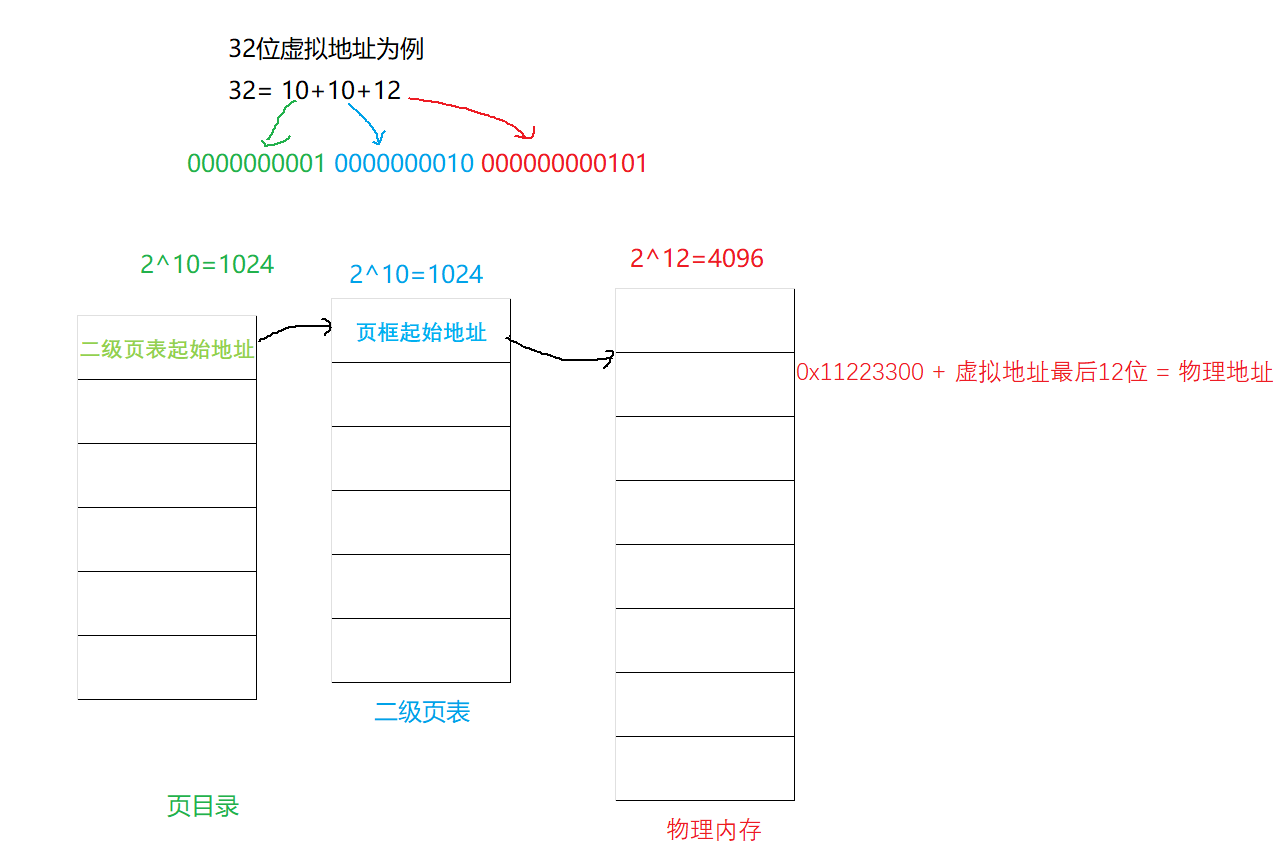
以32位虚拟地址为例
32位拆分成了
10、10、12:
高10位:一级页表(页目录)
范围:[全0,全1],转换成十进制就充当了页表的下标,里面存放的是二级页表的地址
次高10位:二级页表
范围:[全0,全1],索引二级页表,存放的是页框的起始地址
低12位:页框(物理内存)
212,4kb正好是页框的大小,就是实际的页框地址再加上虚拟地址的最后12位,就得到了物理地址,也就是要访问物理内存在页框中的偏移量。
一个页表差不多正好可以放在页框里面,而一个进程最多就是1024*1024=1MB,所以一个进程页表的大小差不多1MB,但是进程并不会用完所以的地址空间,所以二级页表不一定全部存在,大部分情况下都是不全的。这样进程的页表就大大的减少了。
从这里也能看出,创建进程是一个很“重”的工作,所以这就有了线程存在的背景和意义
因为页表只前20位,所以内存管理的基本单位就是4kb,而我们的C/C++里面有整形,浮点型什么的,这些都是4byte、8byte。
以int a = 10为例,a是4byte,按理说要有4个地址,可是我们&a的时候,只拿到一个地址,这里拿的就是4个字节中地址值最小的那个字节,要读取的时候,往上读4个就行了。
CPU内置了一些命令,它知道是读取几个字节
所以在语言层面寻址方面,任何变量只有一个地址,那就是它的起始地址,这也就是为什么所以的变量都需要有类型,本质上就是起始地址+偏移量,这个是x86CPU的特点。
4.2 线程资源
由于页表、物理内存什么的都已经分配好了,而线程又不会单独开这些资源,所以线程资源分配,本质上就是分配地址空间范围
5. Linux线程周边概念
进程 和 线程
-
线程的创建和释放更加轻量化
-
线程切换更加轻量化
线程是进程的执行分支,
CPU和内存在数据进行交互时,它会将数据
cache到内存里面(冷数据->热数据),进程在调度的时候会越跑越快,这是因为它的命中率越来越高。当线程进行切换的时候,此时上下文虽然在变化,但是缓存里面的数据变化幅度不大,所以不需要做·
cache数据的保存;但如果整个进程需要切换,此时缓存的数据需要全部重新替换缓存别的数据(热->冷->热)
线程虽然共享进程的数据,但是它也有一部分自己的数据:
- 线程ID
- 一组寄存器
- 栈(体现线程之间执行流不会错乱)
- 独立的上下文(能够体现线程是被独立调度的)
- errno
- 信号屏蔽字
线程虽然共享进程的数据,但是它也有一部分自己的数据:
- 线程ID
- 一组寄存器
- 栈(体现线程之间执行流不会错乱)
- 独立的上下文(能够体现线程是被独立调度的)
- errno
- 信号屏蔽字
- 调度优先级
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!