springcloud之链路追踪
写在前面
源码 。
本文一起来看下链路追踪的功能,链路追踪是一种找出病因的手段,可以类比医院的检查仪器,服务医生治病救人,而链路追踪技术是辅助开发人员查找线上问题的。
1:为什么微服务需要链路追踪
孔子同志月过,有则改之,无则加勉,其中的后半句无则加勉,springcloud已经通过提供sentinel组件 ,但如何才能做到有则改之呢,想要改之,就必须知道要改啥,即要知道程序的bug是哪里造成的,而要定位问题的具体所在,在微服务场景下,有时候并不是一件那么容易的事情,因为可能涉及到非常多组件的调用,甚至还有消息队列,数据库之类的中间件,如下图:
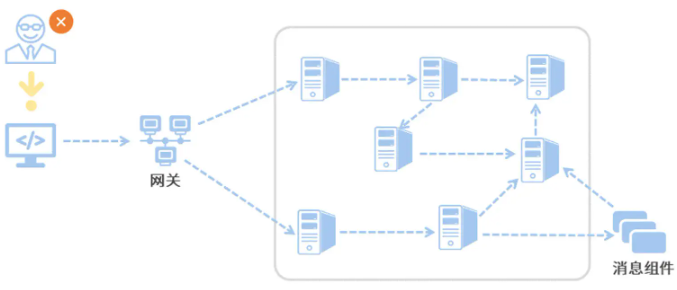
组件多,并且一般多是多节点集群方式部署,用户的请求量还大,想要排查一个请求的错误,无异于大海捞针,因此啊,我们就需要一种技术来帮助我们将请求给串起来,这样在出现问题之后就可以拔出萝卜带出泥的定位到没有节点的请求日志,从而轻而易举的定位到问题所在,做到有则时的改之。而本文要分析的正是这样一个组件:sleuth。
那么sleuth是如何将每个请求串起来的呢?对于整个请求链路,sleuth定义了trace ID,对于一个请求定义了spanId,parentSpanId,其中spanId代表本次处理节点,parentSpanId代表上次处理节点,如下图:
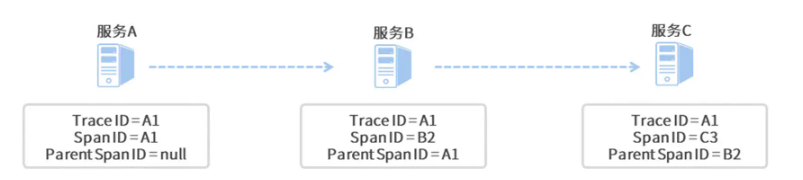
有了调用链的日志之后,对于我们排查问题就会简单很多了,但是还是需要一个一个日志文件的来查找,其实还不是很方便,效率也比较低,此时如果能有一种图形化的展示方式,将这个跨进程的调用栈以UI的方式展示出来就太完美了,此时我们就需要zipkin组件的帮助了,所以应用程序sleuth需要将日志发送到zipkin供zipkin分析展示,但为了应用的解耦,我们一般会引入消息中间件,此时整个架构如下图:
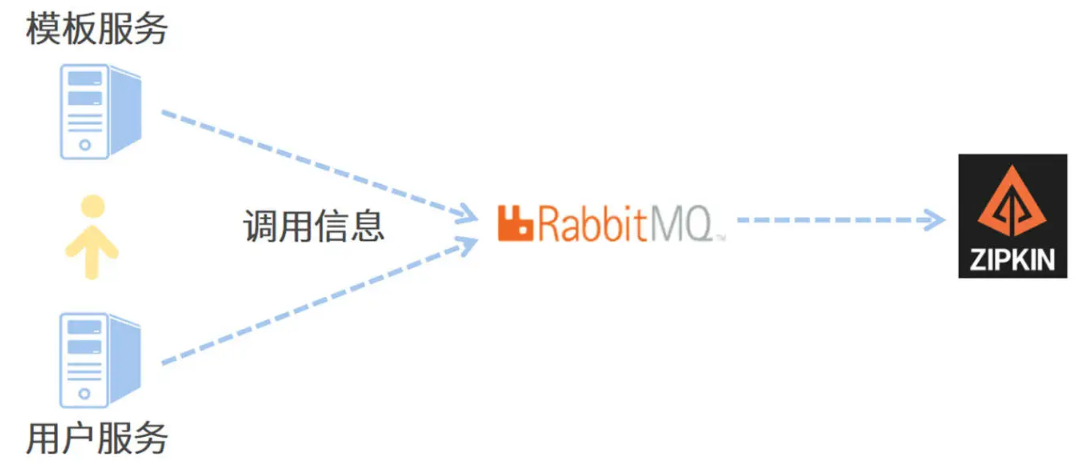
接下来,进入实战。
2:实战
首先我们在模板,计算,用户三个模块添加依赖:
<!-- Sleuth依赖项 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
接着添加配置:
spring:
sleuth:
sampler:
# 采样率的概率,100%采样
probability: 1.0
# 每秒采样数字最高为1000
rate: 1000
logging:
level:
...
org.springframework.cloud.sleuth: debug
- probability
0到1的数字,设置采样的百分比。1为全部采样,0为全都不采样。 - rate
设置每秒最大采样数。
请求,如果看到类似如下的日志就说明sleuth已经成功开始采集了:
DEBUG [coupon-customer-serv,69e433d6432522e4,936d8af942b703d2] 81584
--- [io-20002-exec-1] c.g.c.customer.feign.TemplateService:xxxx
好,接着我们来搭建rabbitmq环境,具体不在这里赘述,可移步这里 查看。
接着,来搭建zipkin,首先从maven 的中央仓库 下载 zipkin-server-2.23.9-exec.jar,接着执行如下命令启动zipkin服务:
# 注意mq地址改成你自己的
java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=localhost:5672
另外mq默认的信息如下:

如果需要指定的话,再启动命令中特殊指定即可,启动成功后会看到zipkin特有的logo:
$ java -jar zipkin-server-2.23.9-exec.jar --zipkin.collector.rabbitmq.addresses=192.168.10.79:5673
oo
oooo
oooooo
oooooooo
oooooooooo
oooooooooooo
ooooooo ooooooo
oooooo ooooooo
oooooo ooooooo
oooooo o o oooooo
oooooo oo oo oooooo
ooooooo oooo oooo ooooooo
oooooo ooooo ooooo ooooooo
oooooo oooooo oooooo ooooooo
oooooooo oo oo oooooooo
ooooooooooooo oo oo ooooooooooooo
oooooooooooo oooooooooooo
oooooooo oooooooo
oooo oooo
________ ____ _ _____ _ _
|__ /_ _| _ \| |/ /_ _| \ | |
/ / | || |_) | ' / | || \| |
/ /_ | || __/| . \ | || |\ |
|____|___|_| |_|\_\___|_| \_|
:: version 2.23.9 :: commit d6b1cc3 ::
2024-01-16 17:19:11.706 INFO [/] 20860 --- [oss-http-*:9411] c.l.a.s.Server : Serving HTTP at /0:0:0:0:0:0:0:0:9411 - http://127.0.0.1:9411/
接着可以访问http://127.0.0.1:9411/:

zipkin会默认监听rabbitmq的队列zipkin来消费消息,所以此时你登录rabbitmq后台的话可以看到这个队列:
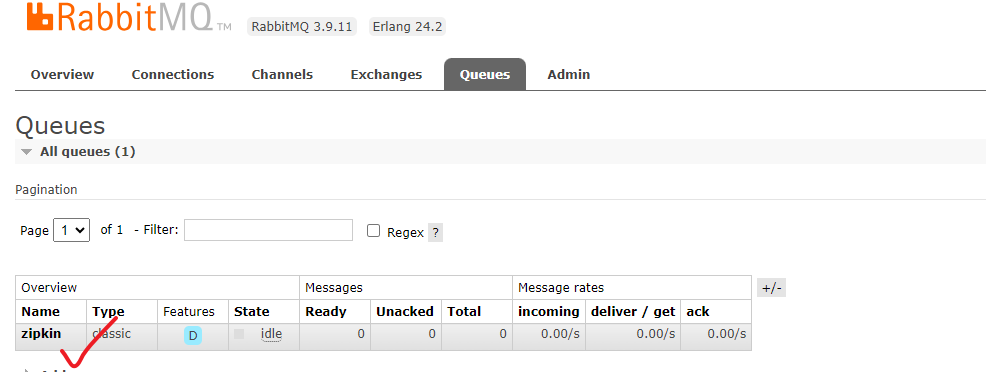
这样zipkin就搭建完成了。接着我们来改造服务,将采样信息生产到rabbitmq的zipkin队列中,首先在template,calculate,cusotm模块引入zipkin适配依赖,以及stream依赖完成生产消息的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<!-- 提前剧透Stream -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
接着添加配置:
spring:
zipkin:
sender:
type: rabbit
rabbitmq:
addresses: 192.168.10.79:5673
queue: zipkin
rabbitmq:
addresses: 192.168.10.79:5673
我们来几个请求后,就可以通过zipkin来查看了,会以栈的形式展现整个调用过程:
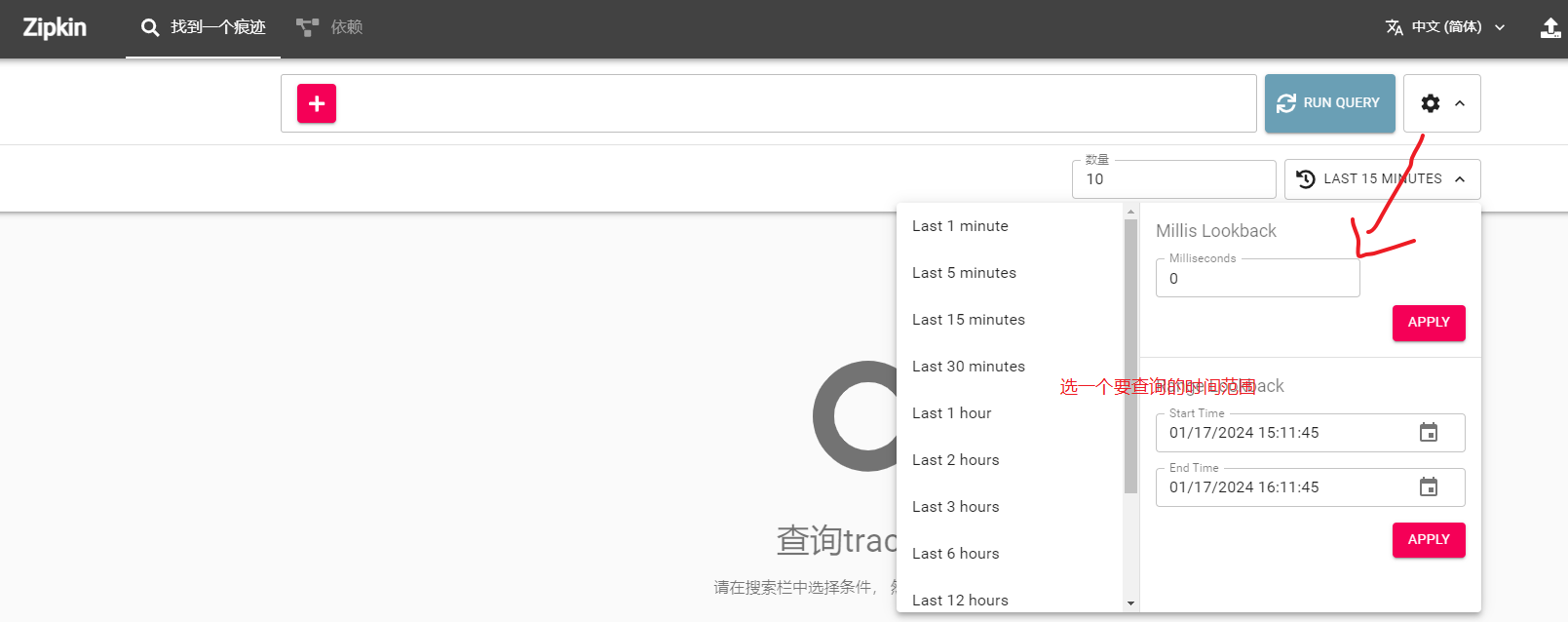
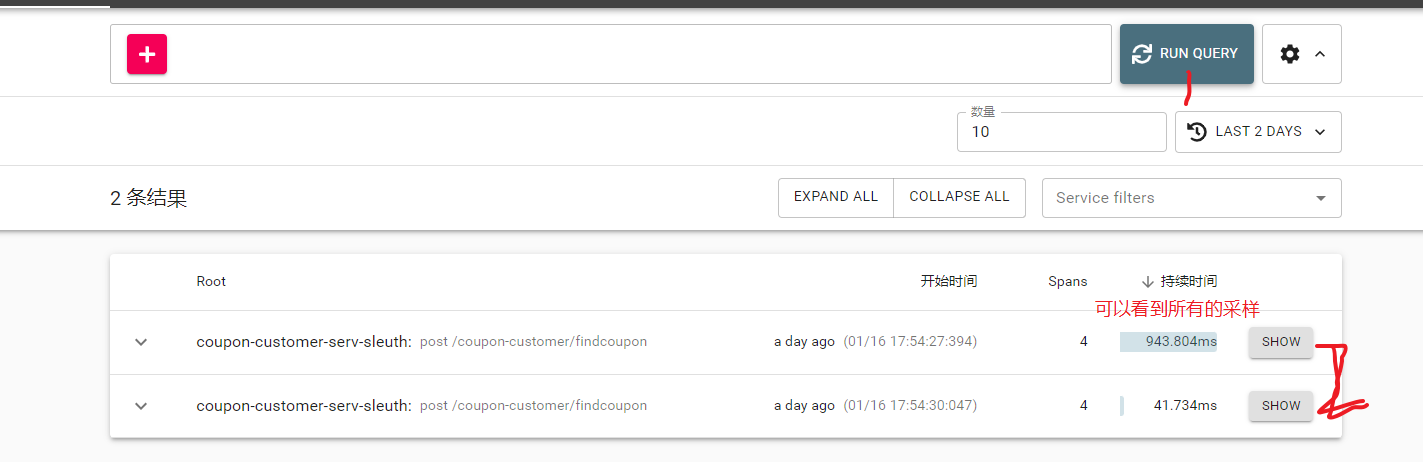
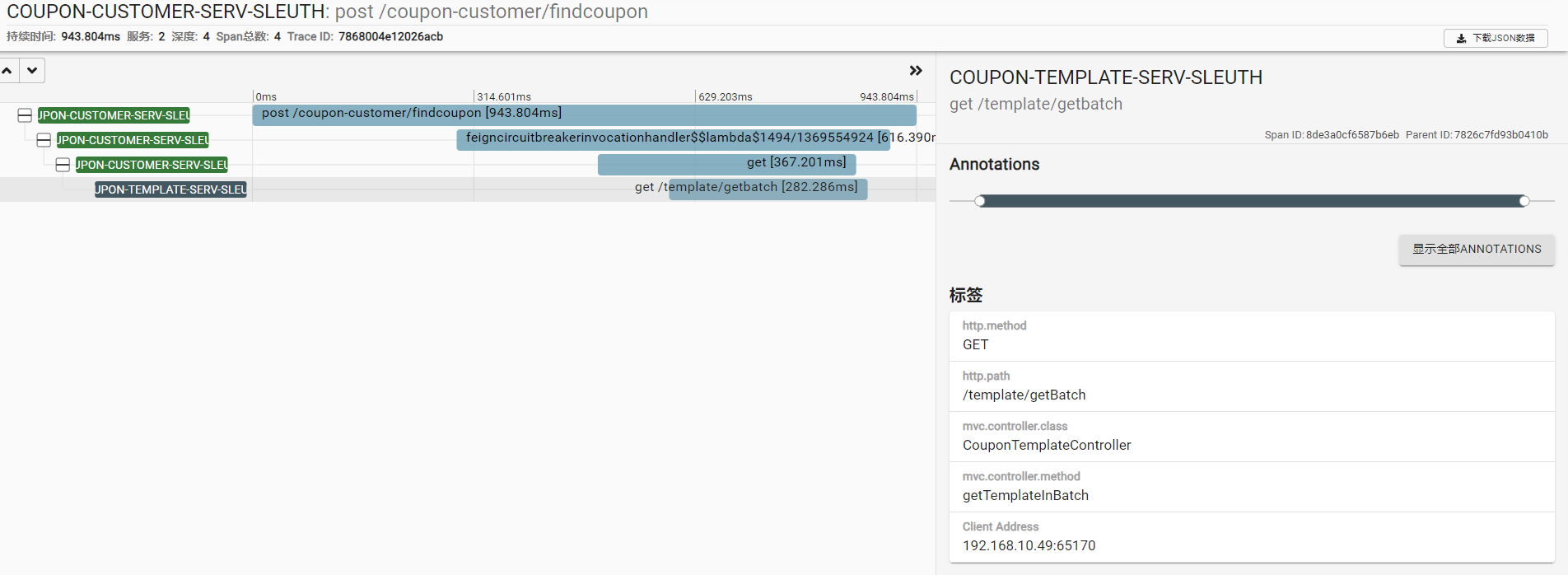
点击show就可以看到调用的整个过程了:
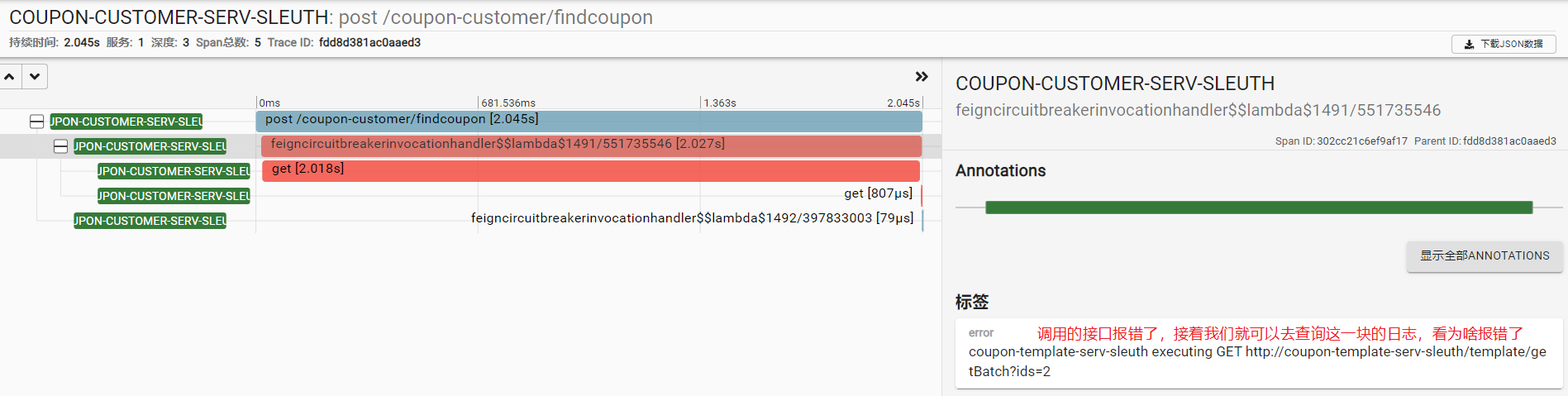
如果是某个服务调用报错的话,会显示为红色,如下:
如果知道traceId可以通过右上角直接搜索,如下:

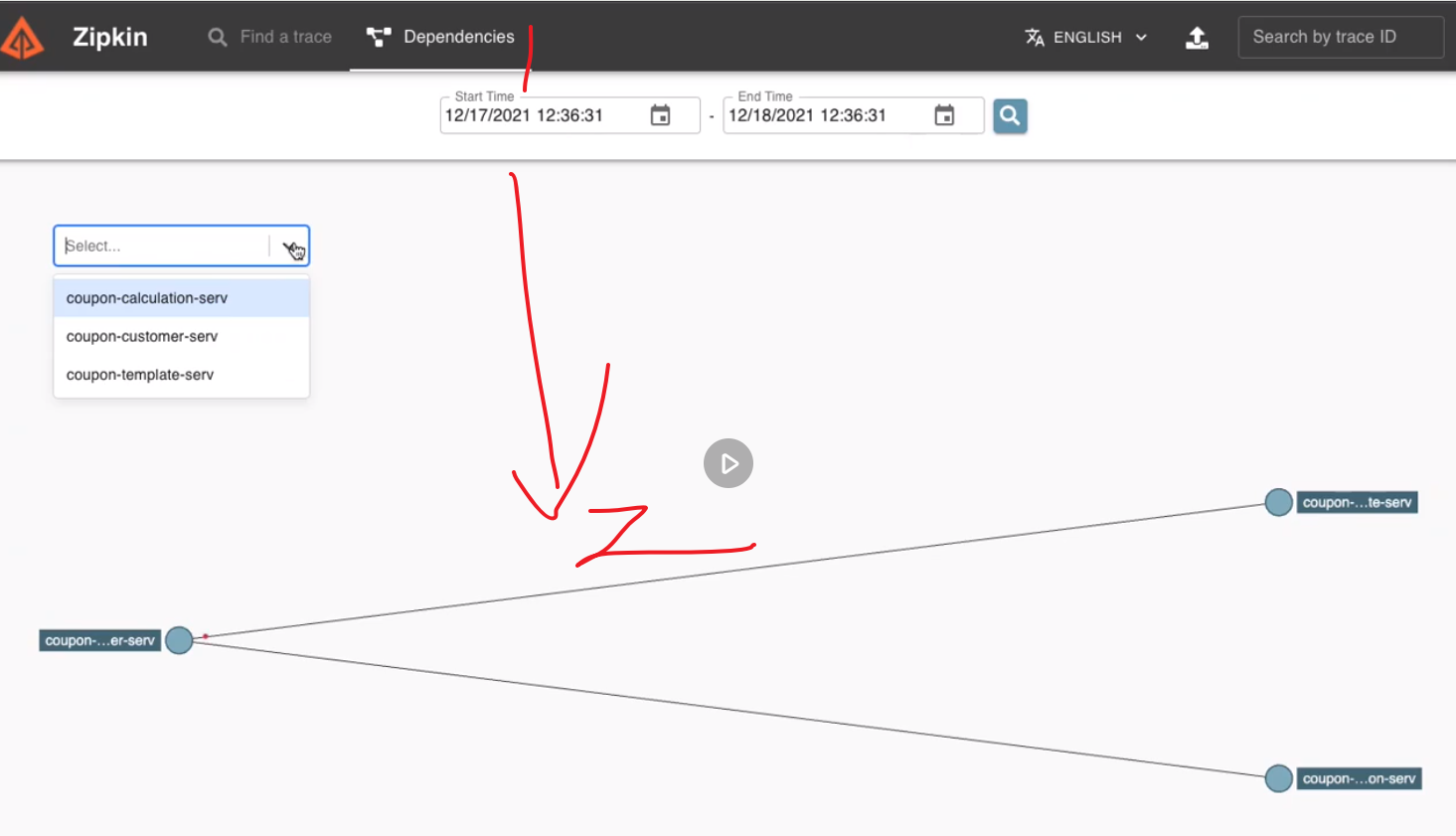
zipkin也会根据服务调用关系生成依赖图,如下:
2.1:原理
首先我们打开spring.factories文件:
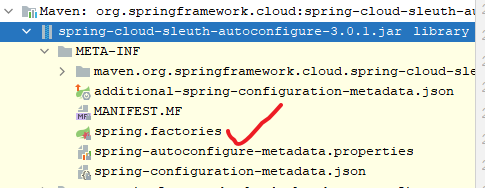
先看自动配置类TraceEnvironmentPostProcessor,这是一个EnvironmentPostProcessor,在该类中首先修改日志打印的格式,启动时会进入到这里:

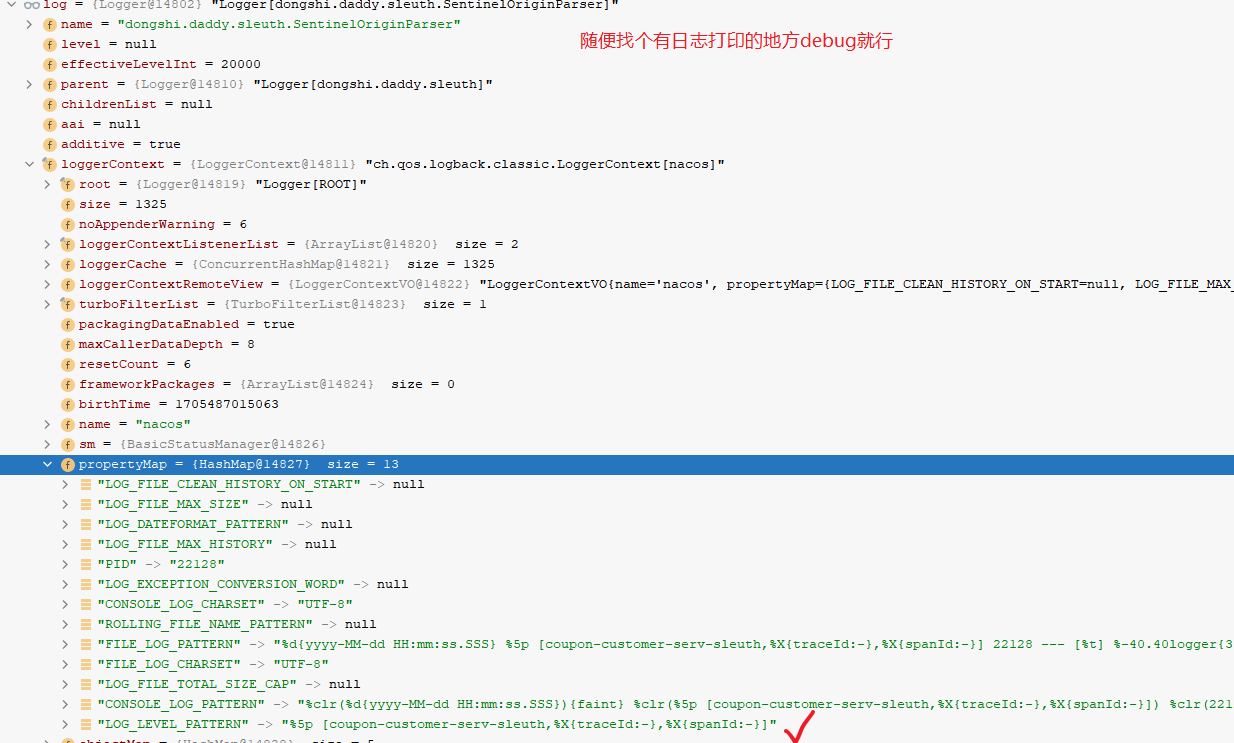
这样日志格式就修改了,后续使用slf4j打印日志的话,只要有相关的信息,就会打印出来了了。接下来的问题就是spanId,tranceId等信息时什么时候设置的呢?继续看TraceWebAutoConfiguration自动配置类,源码如下:
@Configuration(proxyBeanMethods = false)
@ConditionalOnBean(Tracer.class)
@ConditionalOnSleuthWeb
@Import({ SkipPatternConfiguration.class, TraceWebFluxConfiguration.class, TraceWebServletConfiguration.class })
@EnableConfigurationProperties(SleuthWebProperties.class)
@AutoConfigureAfter(BraveAutoConfiguration.class)
public class TraceWebAutoConfiguration {
}
继续看Import的TraceWebServletConfiguration,在该类中会创建TranceFilter,源码如下:
class TraceWebServletConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnProperty(value = "spring.sleuth.web.servlet.enabled", matchIfMissing = true)
static class ServletConfiguration {
...
@Bean
@ConditionalOnMissingBean
TracingFilter tracingFilter(CurrentTraceContext currentTraceContext, HttpServerHandler httpServerHandler) {
return TracingFilter.create(currentTraceContext, httpServerHandler);
}
...
}
}
在TracingFilter会生成(第一个span时)或者时从header中获取traceId,spanId,等信息,并通过slf4j的MDC设置,这样,在打印日志的时候就会打印出这些信息了,源码如下:
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// 生成span,这里执行完traceId,spanId等就有值了
Span span = handler.handleReceive(new HttpServletRequestWrapper(req));
...
// 设置到slf4j的MDC,这样打印日志就能获取到trance_id,span_id等信息了
CurrentTraceContext.Scope scope = currentTraceContext.newScope(span.context());
try {
chain.doFilter(req, res);
}
...
}
那么故事的最后就是通过openfeign调用其他服务时是怎么实现拦截从而打印日志了,以RestTemplate方式调用为例,继续看spring.factories文件的TraceWebClientAutoConfiguration, 源码如下:
class TraceWebClientAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RestTemplate.class)
static class RestTemplateConfig {
...
@Configuration(proxyBeanMethods = false)
protected static class TraceInterceptorConfiguration {
...
@Bean
static TraceRestTemplateBeanPostProcessor traceRestTemplateBeanPostProcessor(
ListableBeanFactory beanFactory) {
return new TraceRestTemplateBeanPostProcessor(beanFactory);
}
...
}
}
...
}
继续看TraceRestTemplateBeanPostProcessor这个后置bean处理器,最终执行如下方法,设置sleuth日志打印的拦截器:
// org.springframework.cloud.sleuth.instrument.web.client.TraceRestTemplateBeanPostProcessor#postProcessAfterInitialization
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof RestTemplate) {
RestTemplate rt = (RestTemplate) bean;
// 设置拦截器
new RestTemplateInterceptorInjector(interceptor()).inject(rt);
}
return bean;
}
这样在发起真正的日志调用之前就能打印日志了,其他的方式,如grpc,feign,也都是通过类似的方式来实现的,但不同的通信方式拦截的方式不同罢了,具体用到哪种再去研究吧!
3:elk
通过sleuth我们已经可以定位到异常发生在哪个模块了,并且可能也已经知道初步的异常信息了,但是仅仅如此还是没有办法定位到具体的异常原因,还需要详细的上下文日志信息,自然我们可以通过tranceId,spanId这些信息到具体的日志文件中去查找,但一般我们的实例都是多节点部署的,少则三四个,多则几十个上百个,所以人肉挨个查找日志文件的效率无疑会非常低。如果是能将所有的日志进行汇总,并提供一种简便的查询方式,就再也完美不过了,而elk ,就能很好的满足我们的需求。
首先来现在docker 的elk镜像 ,这里使用sebp/elk,如下命令:
# 比较大,耐心等待
docker pull sebp/elk:7.16.1
# 我这里设置为5G内存,小了容易不够用导致无法正常启动
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk --memory 5G sebp/elk:7.16.1
项目的日志文件,有错误可以通过日志文件排查问题:
==> /var/log/logstash/logstash-plain.log <==
==> /var/log/kibana/kibana5.log <==
==> /var/log/elasticsearch/elasticsearch.log <==
启动后可访问es:
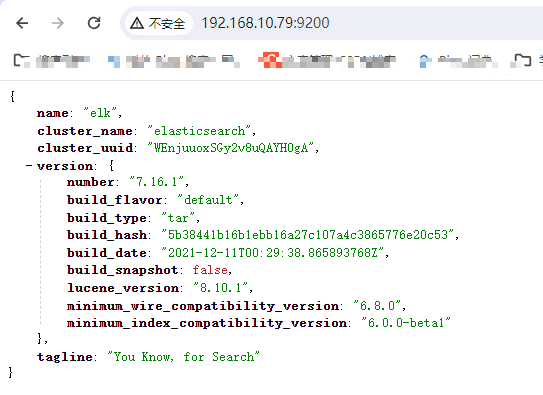
kibana:
接着进入容器修改文件/etc/logstash/conf.d/02-beats-input.conf:
docker exec -it elk /bin/bash
input {
tcp {
port => 5044
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "geekbang"
}
}
指定输入源和输出源,支持的详细输入源和输出源如下:
Logstash Input 插件列表 。
退出容器后,重启容器:
docker restart elk
接着我们来改造应用,支持将日志写到logstash中,首先在template,calcualte,custom三个模块中引入依赖,支持logback写数据到logstash:
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.0.1</version>
</dependency>
接着添加两个appender,分别输出日志到控制台和logstash:
<!-- 控制台 -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<!-- 日志输出编码 -->
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- 输出的JSON格式的信息到Logstash -->
<appender name="logstash"
class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 这是Logstash的连接方式 -->
<destination>192.168.10.79:5044</destination>
<!--<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder">
</encoder>-->
<!-- 日志输出的JSON格式 -->
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${applicationName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
通过appender logstash我们指定了json格式的数据。
- 日志完整配置请参考源码。
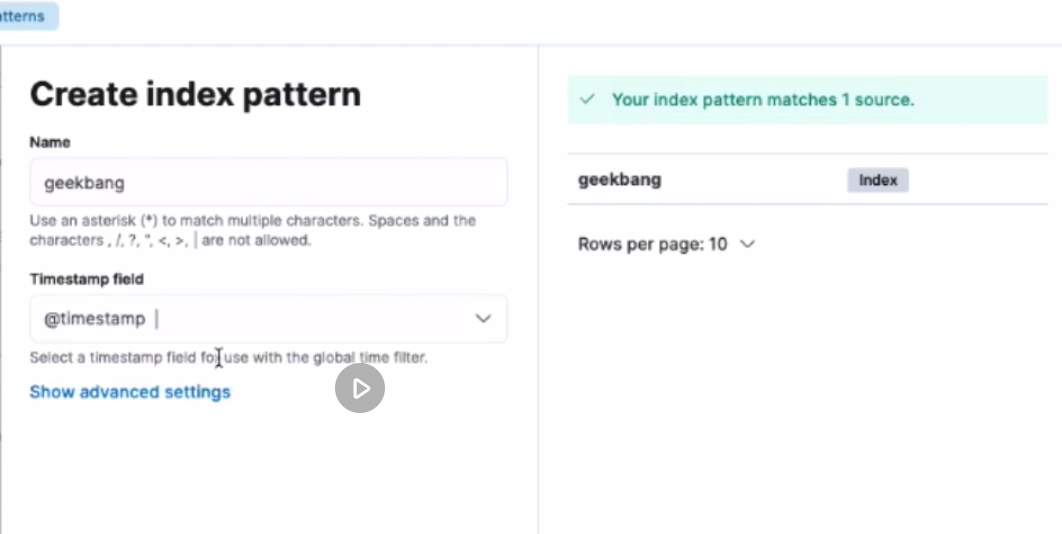
接着我们来启动项目,发几个请求,这些数据就会被写到es中了,接着我们访问http://192.168.10.83:5601/需要首先创建index,大概操作如下:
接着点击如下位置:
一切顺利的话会进入如下页面:
接着选择一个时间段,refresh,就可以看到我们的日志信息了:
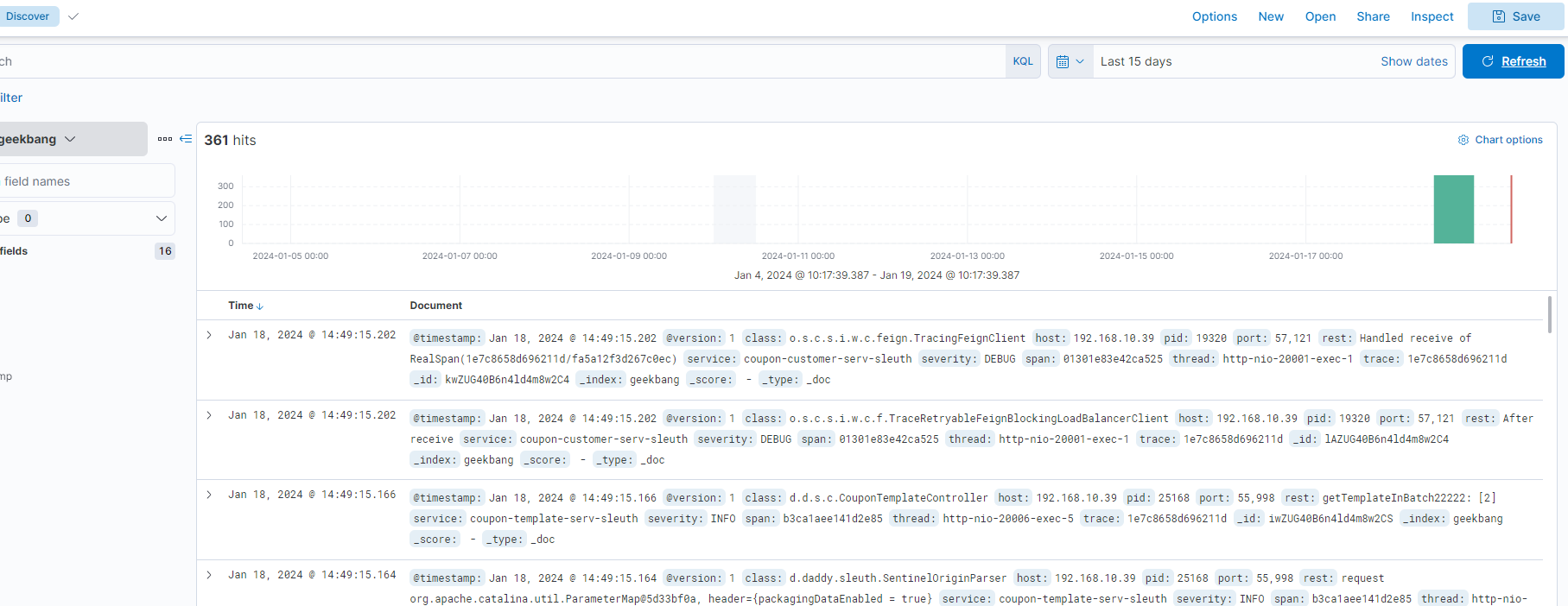
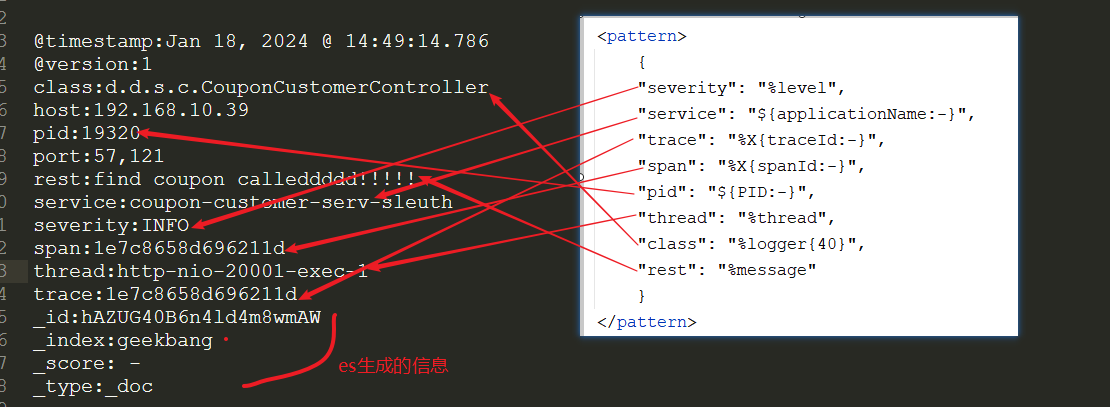
每一项就是es的每个文档了,其中的rest就是具体的日志信息,是我们在logback日志中设置的,可对比下图:
这样比如我们定位到了如下的调用链追踪日志:
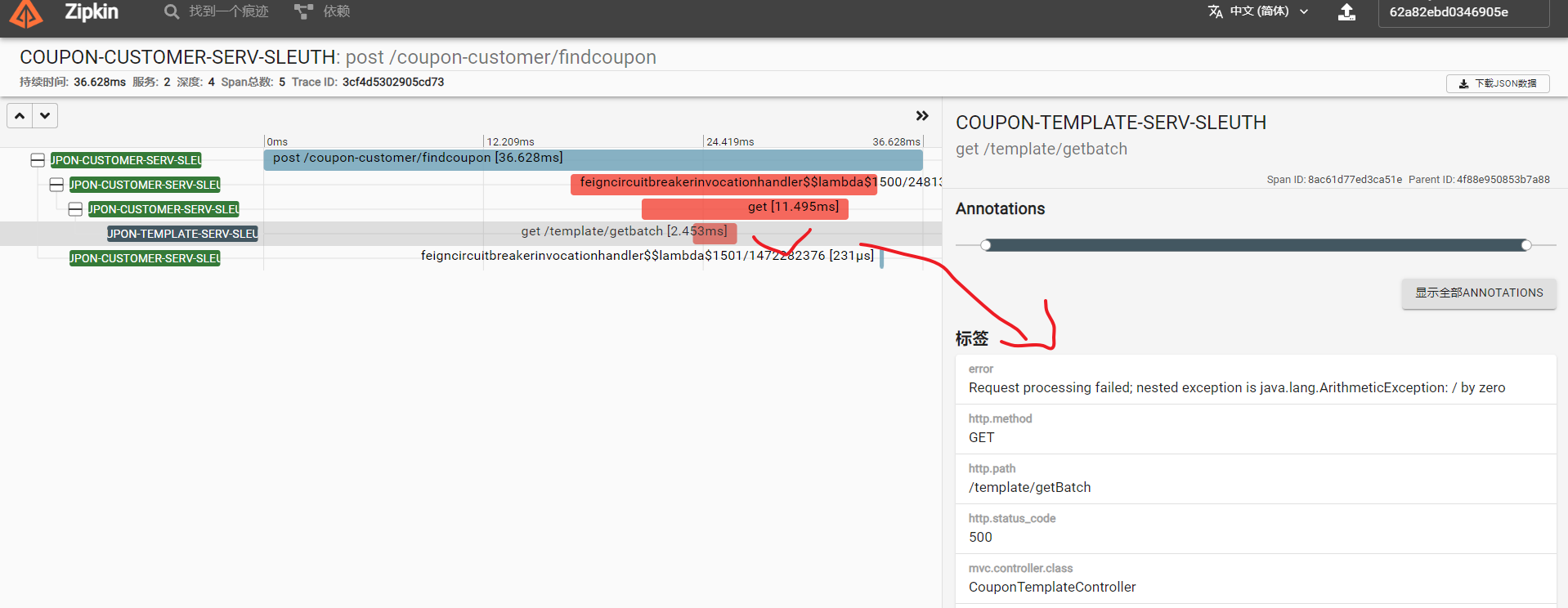
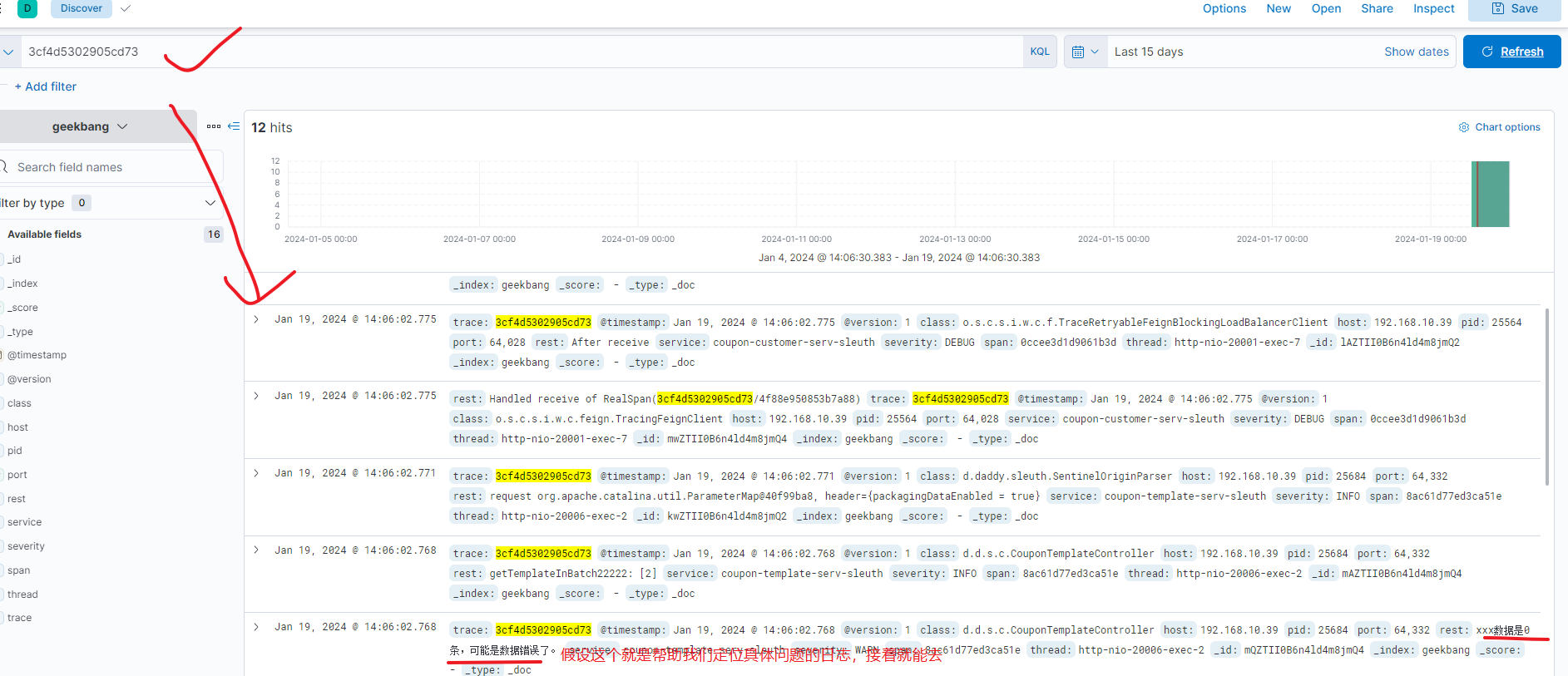
可以定位到问题发生在template模块,并且指定知道是发生了java.lang.ArithmeticException,但为什么会出现这种情况就需要继续排查上下文的详细日志,此时我们就可以通过traceId:3cf4d5302905cd73到kibana中查看详细日志了:
写在后面
参考文章列表
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 利用Pandas进行高效网络数据获取
- Spring Framework中BeanFactory与ApplicationContext的关系与区别
- 基于Java的毕业设计,可作课程设计,已通过验收可运行
- 非常基础的白平衡算法分享
- 【H3C】链路聚合配置
- 实现域名解析通常会用到哪些解析技术?
- 日期处理第二篇:Java8新时间和日期API,看完你就全明白了
- Python+OpenGL绘制3D模型(八)绘制插件导出的模型
- IDEA中Git的常用使用方式
- 如何在 iPhone 上检索已删除的短信:6个有效方法分享