2024.1.2 Spark 简介,架构,环境部署,词频统计
目录
一. Spark简介?
????????1. Spark 和MapReduce
MR:大量的磁盘反复写入,运行是基于进程进行数据处理,创建和销毁的过程比较消耗资源,并且速度较慢
Spark:基于线程执行任务,引入新的数据结构RDD(弹性分布式数据集),让spark基于内存进行运行,比磁盘速度快很多?
????????2. 进程与线程

进程:app,不同软件
线程:微信里的每个聊天对话
????????3. 四大特点
高效性 (快), 易用性(多语言), 通用性(提供了多个工具库), 兼容性(任何地方运行)
二 . Spark 框架模块
?
?Spark Core:实现Spark的基本功能
Spark Sql : 使用Sql处理结构化数据
Strctured Streaming :基于Spark SQL进行流式/实时的处理组件,主要处理结构化数据
三. 环境准备

三台虚拟机 的快照恢复到spark阶段
主机做ip地址映射

3.1 Spark Local模式搭建?
local模式 指的是在本地一个进程中,创建多个线程来模拟Spark程序分布式运行
?1.把包放到虚拟机中
?
2. cd命令进到目录中,然后命令解压??
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz ?-C /export/server/
解压后重命名一下
mv?spark-3.1.2-bin-hadoop3.2?spark
之后 进到bin目录
cd?/export/server/spark/bin
使用命令开启spark
./spark-shell
?
Spark context available as 'sc' (master = local[*], app id = local-1704164639145).
Spark session available as 'spark'.其中''sc ''是SparkContext实例对象
''spark'' 是SparkSession 实例对象
3.2 通过Anaconda安装python3环境
Spark是一个独立的框架
PySpark是Python的库,由Spark官方提供
1.下载好包
?
2.上传到三台虚拟机中
?3.执行脚本
bash Anaconda3-2021.05-Linux-x86_64.sh
运行后阅读一堆注意事项,然后yes,回车,开始下载库,会有点久,三台都需要运行?
?4.配置环境变量
配置anaconda的环境变量,三个节点都需要进行相同的操作:
vim /etc/profile
##增加如下配置
export ANACONDA_HOME=/root/anaconda3/bin
export PATH=$PATH:$ANACONDA_HOME
重新加载环境变量:?source /etc/profile
修改bashrc文件,三个节点都需要进行相同的操作:
sudo vim ~/.bashrc
在最上面添加如下内容:
export PATH=~/anaconda3/bin:$PATH
添加完后,node1重新连接一下,如果命令前面出现了(base),就再去到?vim ~/.bashrc ,在最后一行插入conda deactivate
最后输入python,版本为3.8.8就是安装完了?

3.3 PySpark库安装
1.把这个包传到虚拟机中

2.传好后不用解压,在software文件路径里直接敲命令运行
pip install pyspark-3.1.2.tar.gz
?py4j: 将python代码转换成java代码
运行Spark?
?cd /export/server/spark/bin
./pyspark
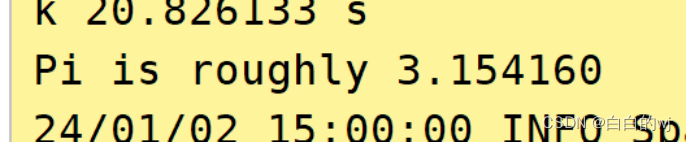
测试圆周率
cd /export/server/spark/bin
./spark-submit /export/server/spark/examples/src/main/python/pi.py 100
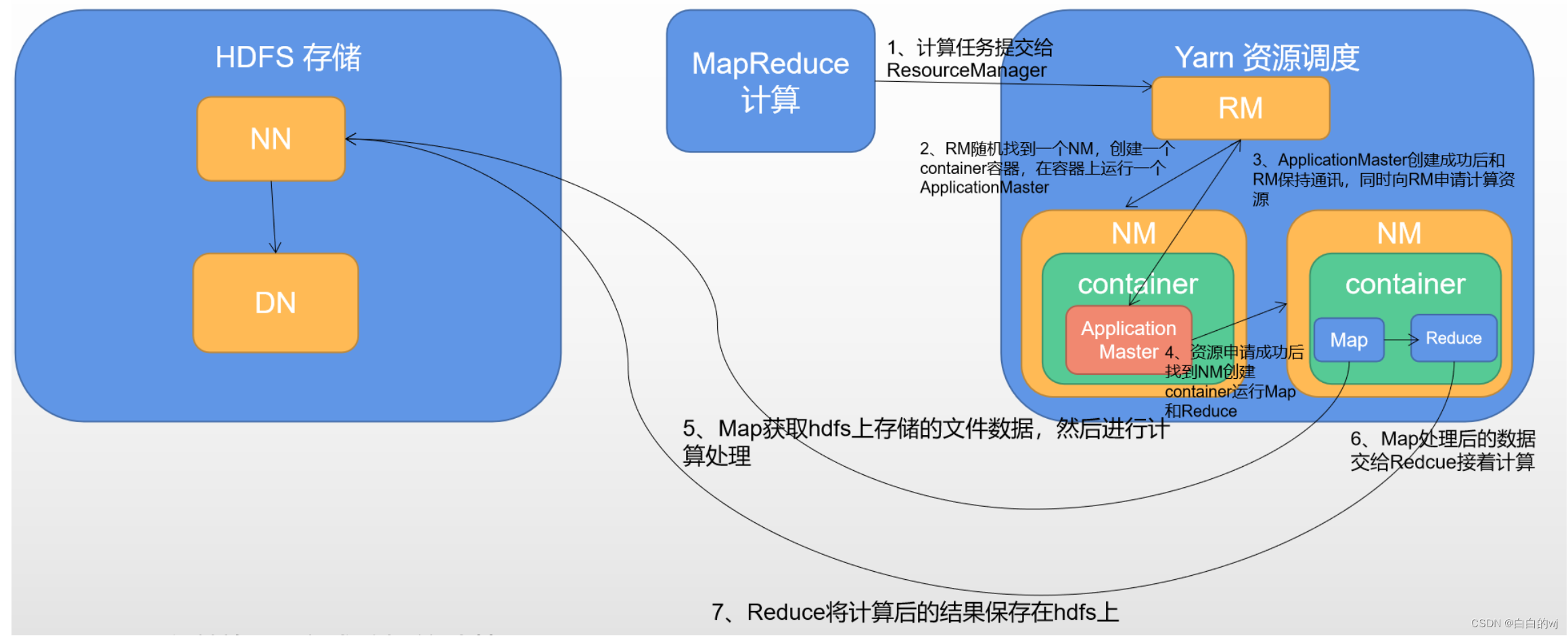
?四 . Spark集群模式架构介绍
一个主角色 Master的职责:
? ? ? ? 1.管理众多的从角色
? ? ? ? 2.负责资源管理和任务的分配
? ? ? ? 3.将Driver进程分配给到Worker进行运行
? ? ? ? 4.接收Spark任务的请求
多个从角色 Worker的职责 :
? ? ? ? 1. 负责具体任务的执行
? ? ? ? 2.向Master汇报心跳,汇报任务运行的状态
? ? ? ? 3.Driver随机选择一个Worker从角色进行启动和运行
? ? ? ? 4.接收执行来自Driver分配来的任务
Zookeeper高可用环境下为了防止单点故障,会有多个Master,主节点的角色分为Active和Standby
五. pycharm远程开发环境?
?? ?远程连接方案, 允许所有的程序员都去连接远端的测试环境, 确保大家的环境都是统一的, 避免各种环境问题的发生,而且由于是连接的远程环境, 所有在pycharm编写代码 都会自动上传到远端服务器中, 在执行代码的时候, 相当于是直接在远端环境上进行执行操作
1.创建新项目是连接ssh
2.选择python解释器在虚拟机里的位置
3.pycharm里勾选tools的deployment 的automatic upload
4.pycharm里tools选择最下面的browse remote host,就可以在pycharm里显示虚拟机的文件目录了
 ?
?
?六. Spark词频统计
1.需求描述
文本内容如下:hello hello sparkhello heima spark
?
代码流程步骤:
创建Spark Context对象
数据输入
数据处理
? ? ? ? 文件内容切分
? ? ? ? 数据格式转换
? ? ? ? 分组和聚合
数据输出
释放资源
?需要自己建一个文件先,存储要统计的词语,路径为
'file:///export/data/2024.1.2_Spark/1.2_day01/content.txt'
import os
from pyspark import SparkConf, SparkContext
# 指定远端的环境地址
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# pyspark程序运行需要有main函数入口
if __name__ == '__main__':
print("PySpark入门案例:WordCount词频统计")
# 创建SparkContext对象(Spark基础的顶级对象)
"""
setAppName:设置Spark程序运行时的名称
setMaster:设置Spark程序运行模式,这里是设置的本地模式
"""
conf = SparkConf().setAppName('spark_wordcount_demo').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 数据输入
"""
textFile:读取文件。支持本地文件系统和HDFS文件系统
本地文件系统:file:///路径
HDFS文件系统:hdfs://node1:8020/路径
"""
init_rdd =sc.textFile('file:///export/data/2024.1.2_Spark/1.2_day01/content.txt')
# 数据处理
# 文本内容切分:flatMap
# 输出结果:['hello', 'hello', 'spark', 'hello', 'heima', 'spark']
flatmap_rdd = init_rdd.flatMap(lambda line: line.split(' '))
# 数据格式转换:map hello -> (hello,1)
# 输出结果:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1),('spark', 1)]
map_rdd = flatmap_rdd.map(lambda word: (word,1))
# 分组和聚合:reduceByKey
# 输出结果:[('hello', 3), ('spark', 2), ('heima', 1)]
"""
reduceByKey:该算子是先对数据按照key进行分组,分组的时候会将value放到一个List列表当中。然
后对value形成的List列表进行聚合处理
lambda agg,curr: agg+curr 这个自定义的lambda表达式的实际含义是:agg是中间临时聚合结果,
默认值是列表中的第一个元素,
curr是当前遍历到的元素,默认值是列表中的第二个元素。agg+curr实际上是等同于agg=agg+curr
底层运行过程说明,以hello为例,首先是分组
输入的是:[('hello', 1), ('hello', 1), ('spark', 1), ('hello', 1), ('heima', 1),
('spark', 1)]
分组后的结果: hello [1,1,1]
spark [1,1]
heima [1]
2-接着是聚合操作
第一次聚合:agg的值是1,curr的值是1,聚合结果是1+1=2,并且会将结果赋值给agg,所以第一次聚合
之后agg的就变成了2
第二次聚合:agg的值是2,curr的值是1,聚合结果是2+1=3,并且会将结果赋值给agg。由于已经将
value形成的List列表中元素遍历完成了,所以最终hello的结果就是3
"""
result_rdd = map_rdd.reduceByKey(lambda agg, curr: agg + curr)
# 数据输出
print(result_rdd.collect())
# 释放资源
sc.stop()
结果:
?

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 猿人学第五题(js逆向)
- 亚马逊云科技AI应用 SageMaker 新突破,机器学习优势显著
- 直播获奖(live)CSP2020
- keepalived知识补充
- Python数据处理048:Python读写pkl文件
- 填充点云孔洞(较大的洞)halcon算法
- 墨天轮国产数据库排行榜年终总结-2023年
- 文本生成中的解码器方法
- ZZULIOJ 1126: 布尔矩阵的奇偶性
- ByConity 社区回顾|ByConity 和开发者们一起展望未来,携手共进!