强烈推荐收藏!LlamaIndex 官方发布高清大图,纵览高级 RAG技术
近日,Llamaindex 官方博客重磅发布了一篇博文《A Cheat Sheet and Some Recipes For Building Advanced RAG》,通过一张图给开发者总结了当下主流的高级RAG技术,帮助应对复杂的生产场景需要。
喜欢记得收藏、点赞、关注。
通俗易懂讲解大模型系列
以下是 LlamaIndex 从基本RAG到高级RAG迭代的文字版介绍
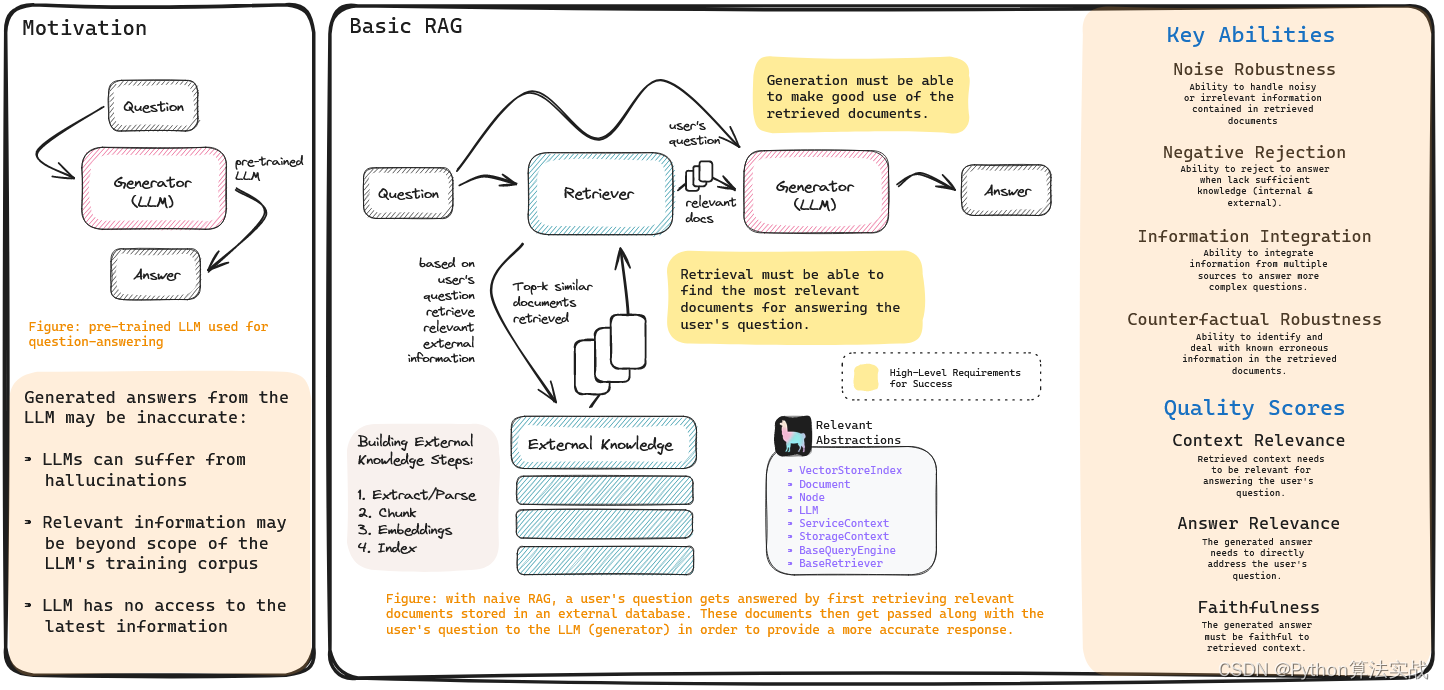
基础 RAG
目前主流 RAG 技术包括从外部知识库检索文档,并将这些文档和用户的查询一起传递给 LLM 以生成响应。换言之,RAG 包括一个检索组件、一个外部知识库和一个生成组件。
LlamaIndex 实现基本 RAG 示例:
# load data
documents = SimpleDirectoryReader(input_dir="...").load_data()
# build VectorStoreIndex that takes care of chunking documents
# and encoding chunks to embeddings for future retrieval
index = VectorStoreIndex.from_documents(documents=documents)
# The QueryEngine class is equipped with the generator
# and facilitates the retrieval and generation steps
query_engine = index.as_query_engine()
# Use your Default RAG
response = query_engine.query("A user's query")
RAG应用成功标准
要使 RAG 系统被认为是成功的(从为用户问题提供有用和相关答案的意义上来说),实际上需要满足以下两个深层次的要求:
-
检索必须能够找到与用户查询最相关的文档。
-
生成必须能够很好地利用检索到的文档来充分回答用户的查询。
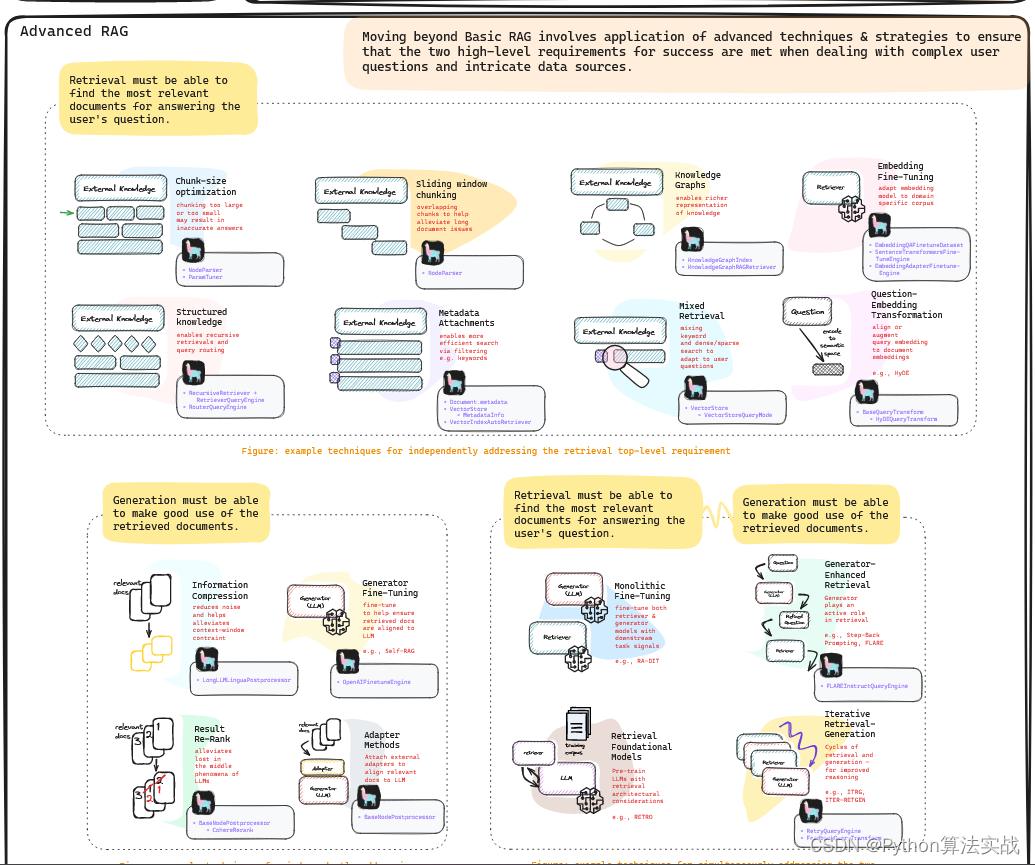
而高级 RAG技术其实就是要应用(检索或生成组件的)更复杂的技术和策略,以确保最终满足这些要求。此外,还可以将这些复杂的技术分为两种:一种是独立于(或多或少)另一种成功要求的技术,另一种是同时满足这两种要求的技术。
高级检索技术必须能够找到与用户查询最相关的文档
下面我们简要介绍几种有助于实现第一个成功要求的更先进技术。
1.块大小优化(Chunk-Size Optimization):由于 LLM 受上下文长度的限制,因此在建立外部知识库时有必要对文档进行分块。分块过大或过小都会给生成组件带来影响,导致响应不准确。
LlamaIndex块大小优化示例:
from llama_index import ServiceContext
from llama_index.param_tuner.base import ParamTuner, RunResult
from llama_index.evaluation import SemanticSimilarityEvaluator, BatchEvalRunner
### Recipe
### Perform hyperparameter tuning as in traditional ML via grid-search
### 1. Define an objective function that ranks different parameter combos
### 2. Build ParamTuner object
### 3. Execute hyperparameter tuning with ParamTuner.tune()
# 1. Define objective function
def objective_function(params_dict):
chunk_size = params_dict["chunk_size"]
docs = params_dict["docs"]
top_k = params_dict["top_k"]
eval_qs = params_dict["eval_qs"]
ref_response_strs = params_dict["ref_response_strs"]
# build RAG pipeline
index = _build_index(chunk_size, docs) # helper function not shown here
query_engine = index.as_query_engine(similarity_top_k=top_k)
# perform inference with RAG pipeline on a provided questions `eval_qs`
pred_response_objs = get_responses(
eval_qs, query_engine, show_progress=True
)
# perform evaluations of predictions by comparing them to reference
# responses `ref_response_strs`
evaluator = SemanticSimilarityEvaluator(...)
eval_batch_runner = BatchEvalRunner(
{"semantic_similarity": evaluator}, workers=2, show_progress=True
)
eval_results = eval_batch_runner.evaluate_responses(
eval_qs, responses=pred_response_objs, reference=ref_response_strs
)
# get semantic similarity metric
mean_score = np.array(
[r.score for r in eval_results["semantic_similarity"]]
).mean()
return RunResult(score=mean_score, params=params_dict)
# 2. Build ParamTuner object
param_dict = {"chunk_size": [256, 512, 1024]} # params/values to search over
fixed_param_dict = { # fixed hyperparams
"top_k": 2,
"docs": docs,
"eval_qs": eval_qs[:10],
"ref_response_strs": ref_response_strs[:10],
}
param_tuner = ParamTuner(
param_fn=objective_function,
param_dict=param_dict,
fixed_param_dict=fixed_param_dict,
show_progress=True,
)
# 3. Execute hyperparameter search
results = param_tuner.tune()
best_result = results.best_run_result
best_chunk_size = results.best_run_result.params["chunk_size"]
2.结构化的外部知识(Structured External Knowledge):在复杂的情况下,可能有必要建立比基本向量索引更具结构性的外部知识,以便在处理合理分离的外部知识源时允许递归检索或路由检索。
llamaindex结构化知识示例:
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.node_parser import SentenceSplitter
from llama_index.schema import IndexNode
### Recipe
### Build a recursive retriever that retrieves using small chunks
### but passes associated larger chunks to the generation stage
# load data
documents = SimpleDirectoryReader(
input_file="some_data_path/llama2.pdf"
).load_data()
# build parent chunks via NodeParser
node_parser = SentenceSplitter(chunk_size=1024)
base_nodes = node_parser.get_nodes_from_documents(documents)
# define smaller child chunks
sub_chunk_sizes = [256, 512]
sub_node_parsers = [
SentenceSplitter(chunk_size=c, chunk_overlap=20) for c in sub_chunk_sizes
]
all_nodes = []
for base_node in base_nodes:
for n in sub_node_parsers:
sub_nodes = n.get_nodes_from_documents([base_node])
sub_inodes = [
IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes
]
all_nodes.extend(sub_inodes)
# also add original node to node
original_node = IndexNode.from_text_node(base_node, base_node.node_id)
all_nodes.append(original_node)
# define a VectorStoreIndex with all of the nodes
vector_index_chunk = VectorStoreIndex(
all_nodes, service_context=service_context
)
vector_retriever_chunk = vector_index_chunk.as_retriever(similarity_top_k=2)
# build RecursiveRetriever
all_nodes_dict = {n.node_id: n for n in all_nodes}
retriever_chunk = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever_chunk},
node_dict=all_nodes_dict,
verbose=True,
)
# build RetrieverQueryEngine using recursive_retriever
query_engine_chunk = RetrieverQueryEngine.from_args(
retriever_chunk, service_context=service_context
)
# perform inference with advanced RAG (i.e. query engine)
response = query_engine_chunk.query(
"Can you tell me about the key concepts for safety finetuning"
)
在llamaindex官方文档中其他高级RAG技术,以帮助确保在复杂情况下进行准确检索。如:
-
使用知识图谱构建外部知识[1]
-
使用自动检索器执行混合检索[2]
-
构建融合检索器[3]
-
微调检索中使用的嵌入模型[4]
-
转换查询嵌入(HyDE)[5]
先进的生成技术必须能够很好地利用检索到的文档
与上一节类似,举例说明了这一类别下的高级技术,可以说是确保检索到的文档与生成器的 LLM 高度一致。
1.信息压缩(Information Compression):LLM 不仅受到上下文长度的限制,而且如果检索到的文档包含太多噪音(即无关信息),响应速度也会下降。
LlamaIndex 信息压缩的示例
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe
### Define a Postprocessor object, here LongLLMLinguaPostprocessor
### Build QueryEngine that uses this Postprocessor on retrieved docs
# Define Postprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort", # enable document reorder
},
)
# Define VectorStoreIndex
documents = SimpleDirectoryReader(input_dir="...").load_data()
index = VectorStoreIndex.from_documents(documents)
# Define QueryEngine
retriever = index.as_retriever(similarity_top_k=2)
retriever_query_engine = RetrieverQueryEngine.from_args(
retriever, node_postprocessors=[node_postprocessor]
)
# Used your advanced RAG
response = retriever_query_engine.query("A user query")
2.结果重排(Result Re-Rank):LLM 存在所谓的 "迷失在中间 "现象,即 LLM 只关注Prompt的两端。有鉴于此,在将检索到的文档交给生成组件之前对其重新排序是有好处的。
LlamaIndex 重排示例:
import os
from llama_index import SimpleDirectoryReader, VectorStoreIndex
from llama_index.postprocessor.cohere_rerank import CohereRerank
from llama_index.postprocessor import LongLLMLinguaPostprocessor
### Recipe
### Define a Postprocessor object, here CohereRerank
### Build QueryEngine that uses this Postprocessor on retrieved docs
# Build CohereRerank post retrieval processor
api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=api_key, top_n=2)
# Build QueryEngine (RAG) using the post processor
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
index = VectorStoreIndex.from_documents(documents=documents)
query_engine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[cohere_rerank],
)
# Use your advanced RAG
response = query_engine.query(
"What did Sam Altman do in this essay?"
)
同时满足检索和生成成功要求的先进技术
在本小节中,我们将考虑使用检索和生成协同作用的先进方法,以实现更好地检索和更准确地生成对用户查询的响应。
1.生成器增强检索(Generator-Enhanced Retrieval):这些技术利用 LLM 固有的推理能力,在进行检索之前完善用户查询,以便更好地指出用户究竟需要什么才能提供有用的响应。
LlamaIndex生成器增强检索示例:
from llama_index.llms import OpenAI
from llama_index.query_engine import FLAREInstructQueryEngine
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
ServiceContext,
)
### Recipe
### Build a FLAREInstructQueryEngine which has the generator LLM play
### a more active role in retrieval by prompting it to elicit retrieval
### instructions on what it needs to answer the user query.
# Build FLAREInstructQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
index_query_engine = index.as_query_engine(similarity_top_k=2)
service_context = ServiceContext.from_defaults(llm=OpenAI(model="gpt-4"))
flare_query_engine = FLAREInstructQueryEngine(
query_engine=index_query_engine,
service_context=service_context,
max_iterations=7,
verbose=True,
)
# Use your advanced RAG
response = flare_query_engine.query(
"Can you tell me about the author's trajectory in the startup world?"
)
2.迭代检索生成器 RAG(Iterative Retrieval-Generator RAG):对于某些复杂情况,可能需要多步推理才能为用户查询提供有用的相关答案。
LlamaIndex 迭代检索生成器示例:
from llama_index.query_engine import RetryQueryEngine
from llama_index.evaluation import RelevancyEvaluator
### Recipe
### Build a RetryQueryEngine which performs retrieval-generation cycles
### until it either achieves a passing evaluation or a max number of
### cycles has been reached
# Build RetryQueryEngine
documents = SimpleDirectoryReader("./data/paul_graham").load_data()
index = VectorStoreIndex.from_documents(documents)
base_query_engine = index.as_query_engine()
query_response_evaluator = RelevancyEvaluator() # evaluator to critique
# retrieval-generation cycles
retry_query_engine = RetryQueryEngine(
base_query_engine, query_response_evaluator
)
# Use your advanced rag
retry_response = retry_query_engine.query("A user query")
RAG 的度量
评估 RAG 系统当然至关重要。高云帆等人在他们的调查报告[6]中指出了 7 个度量维度,在图的右上角。llama-index 库包含多个评估抽象以及 RAGAs 集成,以帮助构建者通过这些测量方面的视角了解其 RAG 系统达到成功要求的程度。下面列出的一些内容可以查阅:
-
答案相关性和语境相关性[7]
-
忠实性(Faithfulness)[8]
-
检索评估(Retrieval Evaluation)[9]
-
使用 BatchEvalRunner 进行批量评估[10]
至此,希望你已经能够有能力和信心应用这些复杂的技术来构建自己的高级 RAG 系统。
附录链接:
[1]:https://docs.llamaindex.ai/en/stable/examples/query_engine/knowledge_graph_rag_query_engine.html
[2]:https://docs.llamaindex.ai/en/stable/examples/vector_stores/elasticsearch_auto_retriever.html
[3]:https://docs.llamaindex.ai/en/stable/examples/retrievers/simple_fusion.html
[4]:https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html
[5]:https://docs.llamaindex.ai/en/stable/examples/query_transformations/HyDEQueryTransformDemo.html
[6]:https://arxiv.org/pdf/2312.10997.pdf
[7]:https://docs.llamaindex.ai/en/latest/examples/evaluation/answer_and_context_relevancy.html
[8]:https://www.notion.so/0754edd9af1c4159bde12649c184c8ef
[9]:https://github.com/run-llama/llama_index/blob/main/docs/examples/evaluation/retrieval/retriever_eval.ipynb
[10]https://docs.llamaindex.ai/en/stable/examples/evaluation/batch_eval.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- QT上位机开发(子窗口通知父窗口更新进度)
- (学习日记)2024.01.13:一份关于自行车定位的调研 2
- 虾皮购物利器:Shopee买家通系统完美解密
- 2023年航天大事件
- NumPy 中级教程——广播(Broadcasting)
- 批量剪辑方法:掌握视频剪辑技巧,按指定时长轻松分割视频
- 【深入理解计算机系统 第三版 导读】第一章 计算机系统漫游
- RFID珠宝门店智能管理设计解决方案
- spring Security源码讲解-Sevlet过滤器调用springSecurty过滤器的流程
- iOS实时查看App运行日志