Deep Learning for Precipitation Nowcasting:A Benchmark and A New Model

?This paper was published at?31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
简介
??Encoder-Decoder CNN也是一种可以用于时序预测任务的模型,它是一种融合了编码器和解码器的卷积神经网络。在这个模型中,编码器用于提取时间序列的特征,而解码器则用于生成未来的时间序列。
具体而言,Encoder-Decoder CNN模型可以按照以下步骤进行时序预测:
- 输入历史时间序列数据,通过卷积层提取时间序列的特征。
- 将卷积层输出的特征序列送入编码器,通过池化操作逐步降低特征维度,并保存编码器的状态向量。
- 将编码器的状态向量送入解码器,通过反卷积和上采样操作逐步生成未来的时间序列数据。
- 对解码器的输出进行后处理,如去均值或标准化,以得到最终的预测结果。
需要注意的是,Encoder-Decoder CNN模型在训练过程中需要使用适当的损失函数(如均方误差或交叉熵),并根据需要进行超参数调整。此外,为了提高模型的泛化能力,还需要使用交叉验证等技术进行模型评估和选择。
Abstract
? ??ConvLSTM模型被证明在短时预测方面优于传统的方法,这表明深度学习模型在解决这一问题上有巨大的潜力。然而,基于ConvLSTM的模型中的卷积递归结构是位置不变的(location-invariant),而自然运动和变换(如旋转)通常是位置变化的(location variant)。此外,由于基于深度学习的降水临近预报是一个新兴领域,尚未建立明确的评价方案。针对这些问题,提出了一种新的降水临近预报模型和一个基准。具体来说,本文超越了ConvLSTM并提出了Trajectory GRU (TrajGRU)模型,该模型可以主动利用循环连接学习基于位置变化的结构。此外,文章还提供了一个基准,其中包括来自香港天文台的一个真实世界的大型数据集、一个新的training loss和一个促进未来研究和评估是否是state of the art的综合评估方案。
??
1 Introduction??
? ?降水临近预报是指利用雷达回波图1、雨量计等观测数据,结合数值天气预报(NWP)模型,对局部地区降水强度进行极短时间(如0-6小时)预报的问题。
? ?文章作者提出的ConvLSTM模型使用卷积结构扩展了LSTM,结果表明 ConvLSTM具有更好的时空相关性捕获能力,预测精度高于既有模型。然而,尽管在这个方向上做出了开拓性的努力,这篇论文还是有一些不足之处。
? ?首先,深度学习模型仅在包含97个雨天的相对较小的数据集上进行评估,仅比较0.5mm/h降雨率阈值下的临近预报技术得分。由于现实降水临近预报系统需要对暴雨等对社会造成更大威胁的强降水事件给予额外的关注,仅在0.5mm/h阈值(表示是否下雨)下的性能不足以体现算法的整体性能。事实上,降水临近预报领域的深度学习还处于起步阶段,如何评价模型以满足实际应用的需要还不明确。
? ? 其次,虽然ConvLSTM中使用的卷积递归结构在捕获时空相关性方面优于全连通递归结构FC-LSTM,但它不是最优的,还有改进的空间。对于旋转和缩放等运动模式,不同的空间位置和时间戳会导致连续帧的局部相关结构不同。因此,使用位置不变滤波器来表示这种位置变量关系的卷积是低效的。之前的研究尝试通过将一个递归神经网络(RNN)的输出从原始预测修改为输入的某个位置变量变换来解决这个问题,比如光流或动态局部滤波器。然而,通过修正递归结构本身来解决这一问题的研究并不多。
? ?在本文中,我们通过提出降水临近预报的基准和新模型来解决这两个问题。对于新的基准,我们建立了HKO-7数据集,该数据集包含2009年至2015年香港附近的雷达回波数据。由于雷达回波图在真实场景中是连续的,能够瞬时获取,因此临近预报算法可以采用在线学习的方法来动态地适应新的模式。为此,我们在基准测试中使用了两个测试协议:离线时只能使用一个固定的窗口前面的雷达回波地图,在线时可免费使用所有历史数据和在线学习算法。降水临近预报任务的另一个问题是不同降雨率阈值下降水事件的比例高度不平衡。降雨量较大的情况较少发生,但对现实世界的影响较大。因此,我们提出了平衡均方误差Balanced Mean Squared Error (B-MSE)和平衡平均绝对误差Balanced Mean Absolute Error (B-MAE)是用于训练和评估的度量方法,它们在计算MSE和MAE时为较重的降雨分配了更多的权重。结果表明,在多降雨率阈值下,损失函数的平衡变量比原损失函数更符合短时预报的整体性能。此外,我们的实验表明,训练与平衡损失函数是至关重要的深度学习模型,以在较高的降雨率阈值情况下取得良好的性能。
? ? ?对于新的模型,我们提出了轨迹门控递归单元(TrajGRU)模型,该模型利用子网络在状态转换之前输出状态到状态的连接结构。TrajGRU允许沿着一些学习轨迹来聚合状态,因此比连接结构固定的Convolutional GRU (ConvGRU)更灵活。结果表明,TrajGRU的性能在一个合成的Moving MNIST++数据集和HKO-7数据集中优于ConvGRU, Dynamic Filter Network (DFN),以及2D和3D卷积神经网络。
? ? 利用新的数据集、测试方案、训练损失函数和模型,我们对七个模型进行了广泛的评估,同时提供一个大型的降水临近预报基准。实验表明:(1)所有的深度学习模型都优于基于光流的模型; (2)TrajGRU在所有深度学习模型中整体性能最好; (3) 应用在线微调后,在在线设置下测试的模型始终优于在离线设置下测试的模型。据我们所知,这是针对降水临近预报问题的第一个深度学习模型的综合基准。此外,由于降水临近预报可以看作是一个视频预报问题,我们的工作第一次提供了证据和理由,证明在线学习可能在总体上有助于视频预报。
?
2 Related Work
Deep learning for precipitation nowcasting and video prediction
??对于降水临近预报问题,雷达回波图中的反射率因子首先转换为灰度图像,然后输入预测算法[25]。因此,降水临近预报可以被视为一种使用固定“相机”(即天气雷达)的视频预测问题。因此,提出的用于预测自然视频中未来帧的方法也适用于降水临近预报,并且与我们的论文相关。视频预测的通用架构分为三种类型:基于 RNN 的模型、基于 2D CNN 的模型和基于 3D CNN 的模型。兰萨托等人。 [24]提出了第一个基于 RNN 的视频预测模型,该模型使用具有 1 × 1 状态核的卷积 RNN 对观察到的帧进行编码。斯里瓦斯塔瓦等人。 [26]提出了 LSTM 编码器-解码器网络,该网络使用一个 LSTM 对输入帧进行编码,并使用另一个 LSTM 来预测前方的多个帧。该模型在[25]中得到推广,用 ConvLSTM 替换全连接 LSTM,以更好地捕获时空相关性。后来,芬恩等人。 [5] 和 De Brabandere 等人。 [3]通过使网络预测输入帧的变换而不是直接预测原始像素来扩展[25]中的模型。鲁本等人。 [28]建议同时使用捕获运动的 RNN 和捕获内容的 CNN 来生成预测。除了基于 RNN 的模型之外,[22] 和 [29] 中还分别提出了基于 2D 和 3D CNN 的模型。马蒂厄等人。 [22]将帧序列视为多通道并应用2D CNN来生成预测,而[29]将它们视为深度并应用3D CNN。这两篇论文都表明,生成对抗网络(GAN)[6]有助于生成准确的预测。
Structured recurrent connection for spatiotemporal modeling
??从更高层次的角度来看,降水临近预报和视频预测本质上是时空序列预测问题,其输入和输出都是时空序列[25]。最近有一种趋势是用其他拓扑取代RNN循环连接中的全连接结构,以增强网络对时空关系建模的能力。除了用卷积代替全连接并专为密集视频而设计的 ConvLSTM 之外,SocialLSTM [1] 和 Structural-RNN (S-RNN) [13] 也被提出了类似的概念。 SocialLSTM根据不同人之间的距离定义拓扑,专为人类轨迹预测而设计,而S-RNN根据给定的时空图定义结构。所有这些模型与我们的 TrajGRU 的不同之处在于我们的模型主动学习循环连接结构。梁等人。 [19]提出了Structure-evolving LSTM,它也具有学习RNN连接结构的能力。然而,他们的模型是为语义对象解析任务而设计的,并学习如何自动合并图节点。因此,它与旨在学习时空数据的局部相关结构的 TrajGRU 不同。
Benchmark for video tasks
? ?在线对象跟踪 [31] 和视频对象分割 [23] 等多个视频任务存在基准。然而,降水临近预报问题没有基准,这也是一个视频任务,但有其独特的性质,因为雷达回波图是完全不同类型的数据,并且数据高度不平衡(如第 1 节所述)。作为这项工作的一部分创建的大规模基准可以帮助填补这一空白。
3 Model
?在本节中,我们提出了降水临近预报的新模型。首先介绍了本文所采用的通用encoding-forecasting结构。然后,我们回顾了ConvGRU模型,提出了新的TrajGRU模型。
?3.1 Encoding-forecasting Structure
??我们采用了与ConvLSTM类似的公式,问题描述如下,利用前j个观测值预测后K步
本文的encoding-forecasting结构首先将观测值输入到N层RNN中,得到N个RNN state:
![]()
然后基于这些编码得到的状态,利用另外一个N层的RNN网络获取预测值:
![]()
图1展示了网络结构,其中,n = 3; J = 2; K = 2。我们在神经网络之间插入了下采样层和上采样层downsample and upsample,这些层是通过带tride步长的convolution卷积和deconvolution反卷积来实现的。将预测网络的顺序颠倒,是因为高阶状态high-level state能够捕捉全局的时空表征,从而指导低阶状态low-level state的更新。此外,low-level state进一步影响预测。这种结构比之前的ConvLSTM结构更合理 (ConvLSTM并没有反向链接预测网络), 因为我们可以自由地在上面插入额外的RNN层,而不需要skip-connection来聚合底层信息。在这种一般的编码预测结构中,只要有状态张量,就可以选择任何类型的神经网络来代替RNN,如ConvGRU或我们新提出的TrajGRU。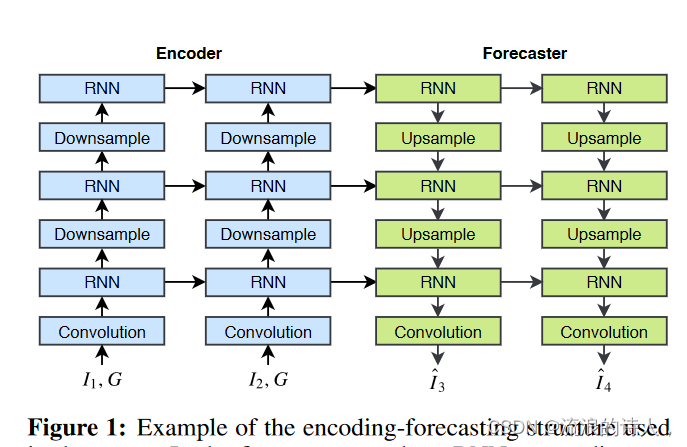
图 1:本文中使用的编码预测结构示例。在图中,我们使用三个 RNN 来预测给定两个输入帧 I1、I2 的两个未来帧 ? I3、? I4。空间坐标 G 连接到输入帧,以确保网络知道观测值来自不同位置。 RNN 可以是 ConvGRU 或 TrajGRU。如果输入链接丢失,则将零作为 RNN 的输入。
3.2 Convolutional GRU
本文所采用的ConvGRU的主要计算公式如下: ?3.3 Trajectory GRU
?3.3 Trajectory GRU
当用于获取时空相关性时,ConvGRU或者其他ConvRNNs等的不足在于所有位置的连接结构和权值都是固定的。卷积运算基本上是对输入应用一个位置不变的滤波器。如果输入都是0,重置门都是1,我们可以在一个特定的位置(i,j) t时刻,重写获取新状态的计算过程,具体如下:

?
当卷积的超参数固定时,邻域集合N对所有位置保持不变。然而,大多数运动模式对于不同的位置有不同的邻域集。例如,旋转和缩放会产生指向不同方向的不同角度的流场。因此,更合理的做法是使用基于位置变化的连接结构location-variant connection structure:
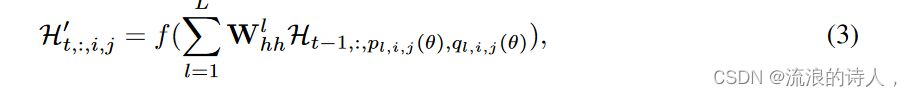

?基于此,我们提出了TrajGRU,它使用当前输入和以前的状态在每个时间戳为每个位置生成本地邻域集。由于位置指数是离散的、不可微的,我们用一组连续的光流来表示它们“指标”。TrajGRU的主要公式如下:

?这种结构的优点是,我们可以学习子网的连接拓扑通过学习参数γ。在我们的实验中,γ需要连接的Xt和Ht?1作为输入和固定是one-hidden-layer的卷积神经网络(5×5的kernel size和32个filter)。因此,γ只有少量的参数并增加几乎没有成本的整体计算量。与K×K state-to-state卷积的ConvGRU相比,由于L![]()
如果L和K2(K方)相同,TrajGRU的参数数量也可以小于ConvGRU,TrajGRU模型能够更有效地使用这些参数。ConvGRU和TrajGRU的循环连接结构说明如图2所示。

? ?最近,有研究在CNN中使用了类似的思想来扩展卷积运算。然而,他们提出的Active Convolution Unit (ACU)关注于图像领域,the need for location-variant filters is limited。我们的TrajGRU专注于视频,其中location-variant filters对于处理旋转等运动模式至关重要。此外,我们正在修改循环连接的结构,并测试了不同数量的链接,而改研究将链接数量固定为9。
?
4 Experiments on MovingMNIST++?
?
?5 Benchmark for Precipitation Nowcasting
5.1 HKO-7 Dataset
这个数据是香港天文台提供的2009年到2015年降雨雷达图数据,图片是480*480的灰度图,812 天用于训练、50 天用于验证、131 天用于测试。

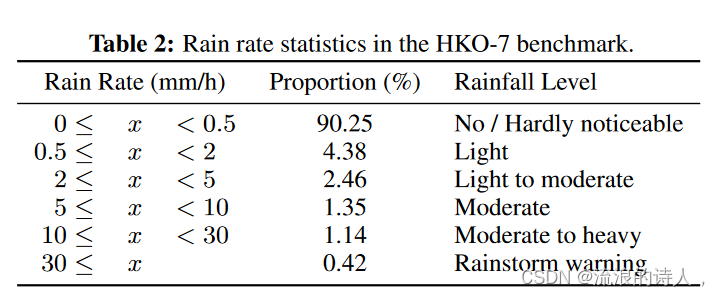
?表2显示了数据集中不同降雨概率的分布。
5.2 Evaluation Methodology
随着雷达回波图实时获取,临近预报算法可以应用在线学习来适应新出现的时空模式。我们在评估方案中提出两种设置:(1)离线设置,算法始终接收5帧作为输入,提前预测20帧; (2)在线设置,算法依次接收长度为5的片段,每接收一个新片段,提前预测20帧。评估方案在附录中有更系统的描述。测试环境保证在脱机和联机设置中测试相同的序列集,以便进行公平的比较。
?6 Conclusion and Future Work
??在本文中,我们提供了降水临近预报的第一个大规模基准,并提出了一种新的具有学习循环连接结构能力的TrajGRU模型。我们已经证明TrajGRU比ConvGRU更有效地捕捉时空相关性。在未来的工作中,我们计划测试TrajGRU是否有助于改善其他时空学习任务,如视觉对象跟踪和视频分割。我们也将尝试使用提出的算法建立一个临近预报系统。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FileNotFoundException(文件未找到异常)可能的原因和解决方法
- 别墅家庭泳池建造选择混凝土结构还是装配式结构?
- Redis设计与实现之数据库
- (1)(1.13) SiK无线电高级配置(三)
- 运筹说 第84期 | 网络计划-网络图的基本概念
- 难道说 IT行业的下一个风口是鸿蒙开发吗?
- 服务器管理平台开发(2)- 设计数据库表
- 基于YOLOv8深度学习的西红柿成熟度检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
- stm32——串口通信的分类以及串口发送数据的原理和配置
- 操作系统课程设计:常用页面置换算法(OPT、FIFO、LRU)的实现及缺页率的计算(C语言)