大模型的理论分析
摘要:
? ? ? ?理论的学习,为在各种情况中应用机器学习,提供了广泛的基础。理论提供了理解、原则和保证,对实证研究的结果做出补充。目前,对基础大模型的研究在很大程度上是经验性的:标准监督学习理论虽然相对成熟,但不足以充分解释基础大模型。具体来说,在基础大模型体系中,预训练阶段和适应阶段之间的差异指出了现有理论的不足,因为这些阶段对应可能完全不同的任务和数据分布。尽管如此,我们努力在理论上解决这种差异,即使在简单、有限的环境中,也将提供有用的见解。
? ? ? ? 严谨的数学理论在许多工程和科学学科(如电气工程中的信息论)中起着基础作用。我们认为,基础大模型理论在指导技术决策和创新方面可能特别有益,因为在基础大模型上进行实验需要巨大的计算成本。此外,理论见解有助于阐明基本局限性并解释令人惊讶的经验现象。然而,尽管最近取得了许多进展,但该社区目前对基础模型的理论理解有限。
? ? ? ?深度神经网络构成了基础模型的主干。即使在经过充分研究的监督学习设置中,训练和测试场景具有相同的分布,围绕深度网络仍然存在许多未决问题,例如理解非凸优化、优化器的隐式正则化效果以及表达性。基础模型提出的问题明显超出了监督式深度学习的设置。从理论上分析基础模型的核心问题是理解为什么在一个可能存在无监督/自监督损失的分布上进行训练,会在不同的下游分布和任务上产生良好的自适应性能。
? ? ? ?我们将讨论一个直观的模块化来分析基础模型,它揭示了监督学习和基础模型、具体和核心技术问题之间的联系,以及一些有前途的理论工具来解决这些问题。这些新的核心问题可以为基础模型提供有用的见解,并且可以与监督深度学习理论并行研究。当我们专注于分析下游性能时,所提出的模块化和工具可以证明对分析其他感兴趣的指标是有用的,例如对分布位移的鲁棒性和安全性。
1. 理论的公式化和模块化
? ? ? ? 回想一下,基础模型是在大量原始数据上进行训练的,然后适应特定的任务,因此可以自然地分解为预训练和适应阶段。我们识别它们之间的接口,并将基础模型特有的部分与标准的深度学习理论部分分离出来,这样就可进行独立地分析了。我们引入了一个模块化的分析框架,它也被隐式或显式地应用于最近的论文中。我们发现,这种模块化分析中最关键组成部分,是预训练-适应的接口。我们首先描述了模块化,并讨论了为什么我们发现这种模块化很有前途,最后讨论了一些限制。
? ? ? ?我们明确地将训练阶段称为“预训练”,以将其与适应阶段的训练区分开来,适应阶段也可能涉及对特定任务的部分样本进行训练。
? ? ? ?预训练阶段:基础模型的预训练通常涉及到一个数据分布(例如,自然文本的分布)和预训练损失函数
(例如,GPT-3中的语言建模损失),预训练损失函数
用于测量参数为
的模型在输入
上的损失。让
表示来自
的大量独立样本的经验分布。
? ? ?预训练最小化了在上的损失
,我们称
为经验预训练损失,并产生一个模型
:
![]()
我们考虑相应的总体分布上的损失,称为总体预训练损失,作为中心概念:
![]()
? ? ? 基于优化的适应阶段:我们将适应定义为一般的约束优化问题,它依赖于,抽象化基于优化某些损失函数的自适应方法,如微调和即时调优。
? ? ? 由于不同的自适应方法可以修改模型参数的不同子集,因此我们用一些来表示自适应模型参数的空间。给定一个下游任务分布
(例如,特定领域的问题回答)和一些经验样本
从
中采样 ,我们将适应阶段建模为最小化在
上的一些适应损失
,适应参数
:
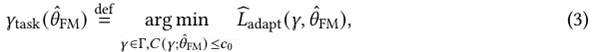
?其中![]() 定义为经验适应损失,
定义为经验适应损失,是控制适应参数复杂性的可选约束,包括显式正则化(如模型维数和规范)和适应过程的隐式正则化。
? ? ? ?我们列举了一些常用的适应方法,并讨论了相应的适应参数和约束条件
.
(1)、线性探索: 在基础模型的表示之上训练线性分类器。这里是在
维线性分类器的集合,
可以是
的
或
范数。
(2)、微调:前几步优化一个随机初始化的线性头,所有其他的参数从
的初始化中得到。这里𝛾是𝜃和线性头的联接。此过程对应于𝛾对初始化
的某种隐式正则化,即
。确切的术语
取决于所使用的优化算法,而这种对优化的隐式正则化的表征是一个活跃的研究领域。
(3)、提示微调:优化任务输入前的一组连续的特定于任务的向量。这里𝛾是通常维数较小的连续提示向量,我们可以选择性地对𝛾的规范进行约束。
适应阶段两个核心量分别是总体适应损失:
![]()
和最小适应损失:
![]()
对模块化阶段进行单独分析:?
? ? ? ?现有的标准监督学习概化理论的目的是证明和
。专门针对深度网络的这些问题是一个活跃的研究领域。我们还可以利用标准学习理论分解,通过过量的泛化误差和最小的自适应损失来约束最终下游任务的损失,如下所示。
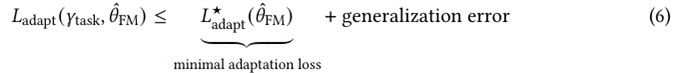
? ? ? ?在哪里泛化误差捕获了和
之间的亲密度这些关键数量之间的分解和关系如图所示。如上所述,泛化和优化箭头在有监督的设置下,很大程度上简化为深度学习理论。我们剩下的是基础模型的主要挑战,那就是理解为什么最小适应损失
可以由于预训练的小总体损失而很小。
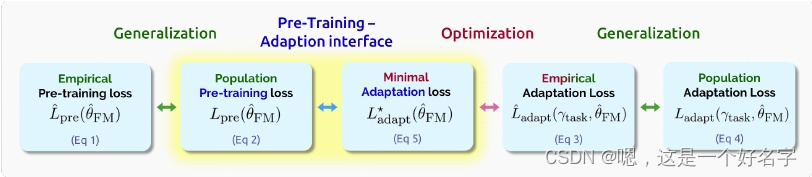
图?分析从不同数据的预训练到适应任务的下游性能的基础模型,需要聚焦到如上图所示的不同损失项之间的关系。主要的挑战是分析图中高亮显示的预训练-适应接口,除了预训练和适应阶段的模型架构、损失和数据分布外,还需要仔细推理总体损失。对泛化和优化的分析在很大程度上归结为对标准监督学习的分析。
? ? ? ? Arora等人的工作开创了这个问题的研究,在对比学习的中,通过从到跳跃到
之上,同时,HaoChen等人放宽了数据假设。其他前训练方法包括使用语言模型的前训练或使用自我训练算法的自我监督,以及多监督任务,也在这个框架下(隐式或显式)得到成功分析。
2.为什么预训练-适应接口有吸引力?
? ? ? ?导致成功的接口的条件可能取决于几个量,如预训练和适应的分布,目标和训练方法,以及模型架构。这个问题超出了标准泛化理论的范围,但它确实把我们的范围缩小到一些特定于基础模型的重要因素,并抓住了我们在下面讨论的各种重要的基础模型开放问题的本质。
? ? ? ?首先,我们注意到这个接口处理的是涉及两个不同分布的总体数量。因此,一个成功的接口的条件很可能涉及分布的特殊性质,例如,预训练分布的多样性和预训练数据与适应数据之间的结构转移。这使得对接口的分析具有挑战性,因为我们需要对两个分布之间的关系进行谨慎的建模假设。然而,这也提供了一种可能性,即用于分析此类接口的工具和技术可能有助于理解分布转移的影响,并预测何时基础模型可以提高鲁棒性。
? ? ? ?第二,总体损失,可能还有成功接口的条件,都取决于模型架构。这就提出了打开神经网络黑匣子的挑战。在一个特定的分布上,一个小的预训练损失能告诉我们什么关于中间层的属性?这样的分析也将指导我们设计新的适应方法,更仔细地利用不同的中间表示。
? ? ? 第三,在最小的适应损失下,通过复杂度测度的约束,可以捕捉到少样本学习或适应训练的样本效率。我们需要正式地描述这些复杂性度量(例如,通过理解适应过程的隐式正则化效应),并进一步理解为什么小总体预训练损失,意味着低复杂性的适应参数
。对这个问题的满意回答可能会使我们提高下游适应的采样效率。
? ? ? ?最后,重要的是,接口的关键组成部分是预训练损失和适应性损失的选择。我们想了解如何最好样本地结合预训练和适应目标,以获得成功的适应。最能保证成功适应的预训练目标可能与预训练过程中明确最小化的目标不同——上面的接口允许人们在预训练分布上使用任何替代总体目标。此外,新的替代目标可以证明在广泛的任务集合中导致良好的适应,这可以阐明使基础模型成功的基本方面。
? ? ? 总而言之,界面排除了泛化的问题,并允许我们正式地推断出几个重要的预训练阶段和适应阶段之间的相互作用,它们可以以重要的方式指导实践。
3.挑战:分析语境学习和其他突发性行为
? ? ? ?GPT-3 展示了上下文学习的力量,这是一种适应方法,它不需要任何参数优化。在适应阶段,预先训练的语言 Foundation模型接受一个提示——一个连接任务的输入-输出示例的标记序列——然后是一个测试示例,通过对到目前为止看到的序列(提示加测试示例)进行条件设置,简单地生成测试示例的标签。换句话说,没有对模型参数进行明确的训练或更改。模型通过简单地将示例作为输入执行而从不同的示例中“学习”的机制是什么?之前的模块化没有直接应用,因为我们在适应过程中没有获得新的模型参数,而只是通过执行结构设计的输入来使用基础模型的生成能力。然而,分离使用无限数据的预训练和使用有限数据的预训练的想法仍然是有用的。例如,最近的一项工作从假设无限的预训练数据和足够的模型表达力来研究上下文学习开始。这些假设将上下文学习的表征简化为分析上下文学习提示条件下的预训练分布,这些分布来自于与预训练数据不同的分布。特别地,Xie等提出语境学习产生于预训练分布中的长期连贯结构,该结构由具有连贯结构的潜变量生成模型来描述。更广泛地说,虽然本节中提出的模块化提供了一个很好的框架,以获得对基础模型有用的理论见解,但一些突发行为,如上下文学习和其他尚未发现的能力,可能需要超越模块化,例如,通过打开架构的黑盒。
4.挑战:适当的数据假设和数学工具
? ? ? ?与传统的监督学习相比,理解前训练和适应阶段之间的接口需要更仔细地研究数据分布。这是因为预训练和任务适应分布有本质上的不同。根据定义,基础模型是在原始数据上训练的,这些原始数据通常是极其多样化和任务无关的,而适应数据则严重依赖于任务。类似地,上下文学习是生成类似于预训练分布的数据的学习结果,因此理解上下文学习需要对预训练数据进行仔细的建模。因此,要回答围绕基础模型的核心问题,就需要现实的、可解释的假设,这些假设也要经得起分析。最近的研究要么假设了种群数据的某些性质,例如HaoChen等人,或者总体数据是由具有某种结构的潜在变量模型生成的。?
? ? ? 我们通常缺乏将基础模型的性质与总体数据分布中的结构联系起来的数学工具。HaoChen等人应用谱图理论来利用种群分布中的内类连通性。对于潜在变量模型,通过概率和解析推导可以更精确地刻画,但到目前为止,还仅限于相对简单的模型。社区将从更系统和通用的数学工具中获益,以解决这个问题。
? ? ? ?定义简单的玩具盒也是非常可取的,这样理论家就可以精确地比较各种工具和分析的优势。例如,HaoChen等人和Wei等人认为流形的混合问题可能是视觉应用的一个很好的简化测试平台。对于离散领域,如NLP,我们需要更有趣的测试平台。我们认为,捕捉真实数据集相关属性的可处理的理论模型是将基础模型置于坚实的理论基础上的关键一步。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 三级网络技术——第十章 网络安全技术
- STM32_通过Ymodem协议进行蓝牙OTA升级固件教程
- 【Qt之Quick模块】6. QML语法详解_2类型系统
- 【网络安全】-入门版
- 径向基函数插值
- 分享一个剧本(改编自我)
- 一文带你掌握ThinkPHP6中的数据验证技巧,提升开发效率!
- 3D模型格式转换工具HOOPS Exchange的层次结构遍历
- 【小程序】如何在微信公众号中申请小程序?
- 华为OD机试真题- 小华最多能得到多少克黄金-2023年OD统一考试(C卷)