python爬取网页图片并下载
python爬取网页图片并下载之GET类型
准备工作
【1】首先需要准备好pycharm,并且保证环境能够正常运行
【2】安装request模块
pip install requests
import request导入request内置模块
【3】安装lxml模块
pip install lxml
from lxml import etree导入lxml.etree内置模块
如果导入etree失败的话可以尝试
from lxml import html
etree = html.etree
目标网站
今日的目标是爬取图片信息
网址:[loryx.wiki]([home LoR丨中文百科] (loryx.wiki))
分析网站
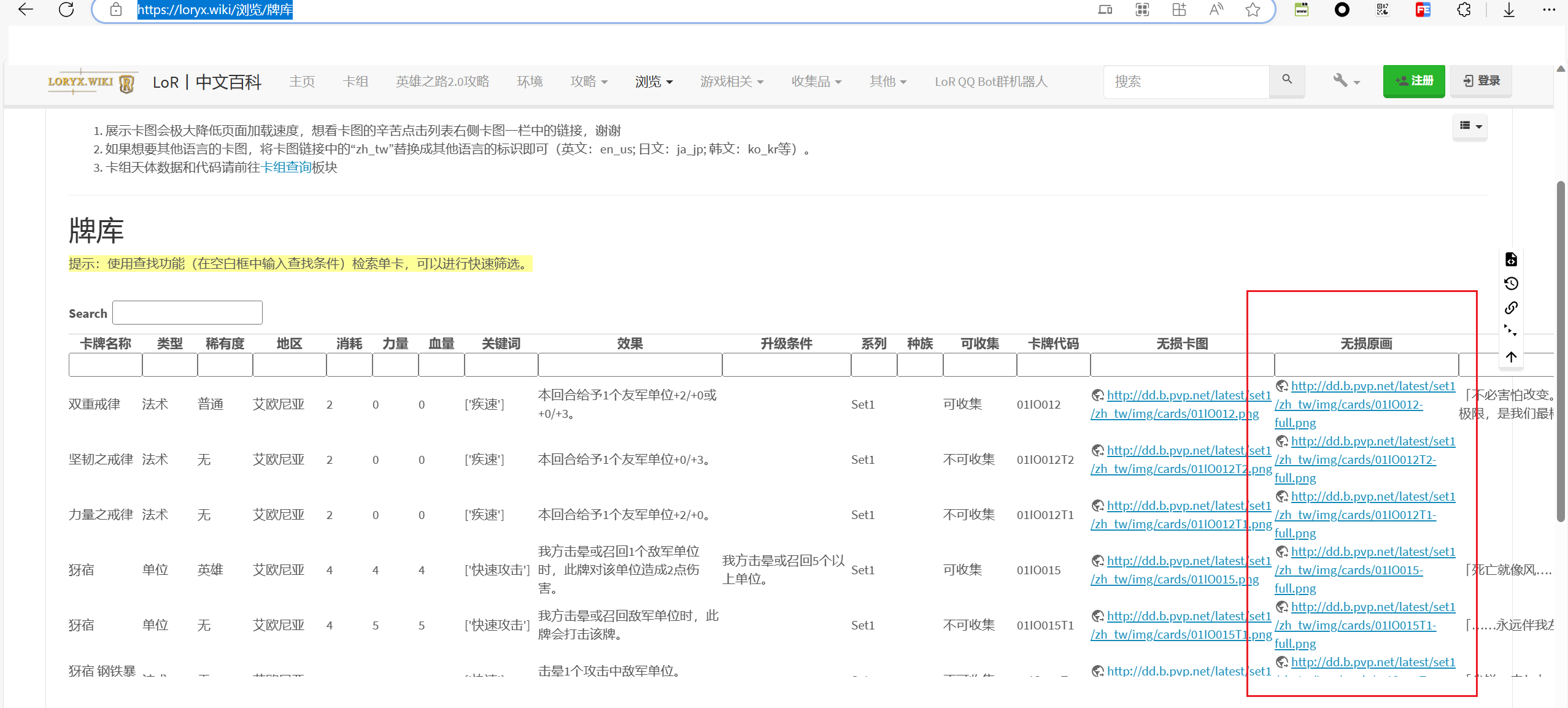
该部分是这次要爬取的所有图片内容,首先F12打开网络并且选中ALL,然后Ctrl+R刷新页面
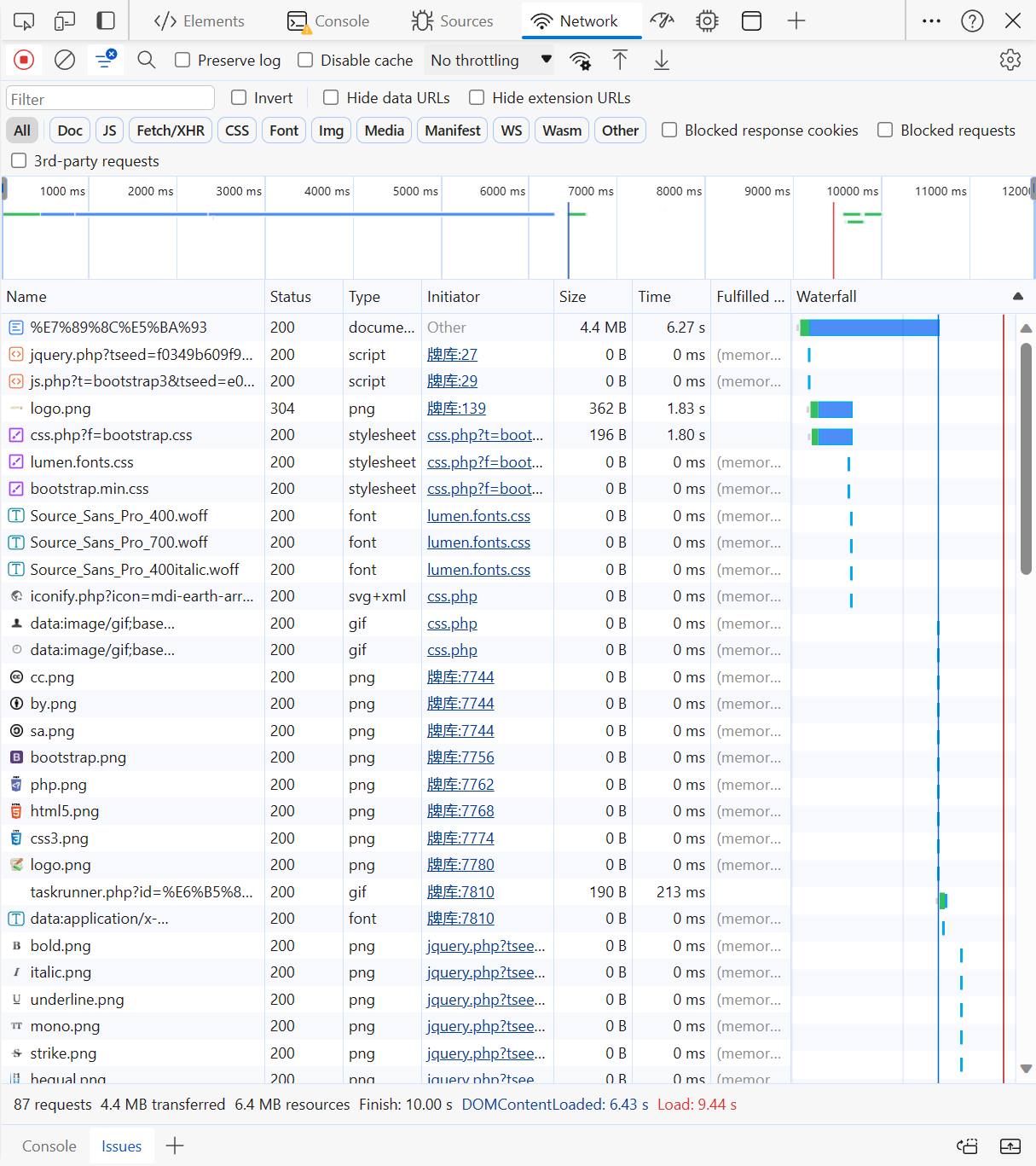
打开最上方加载的文件的Response,发现和页面的源码非常相似,并且编码类型为utf-8
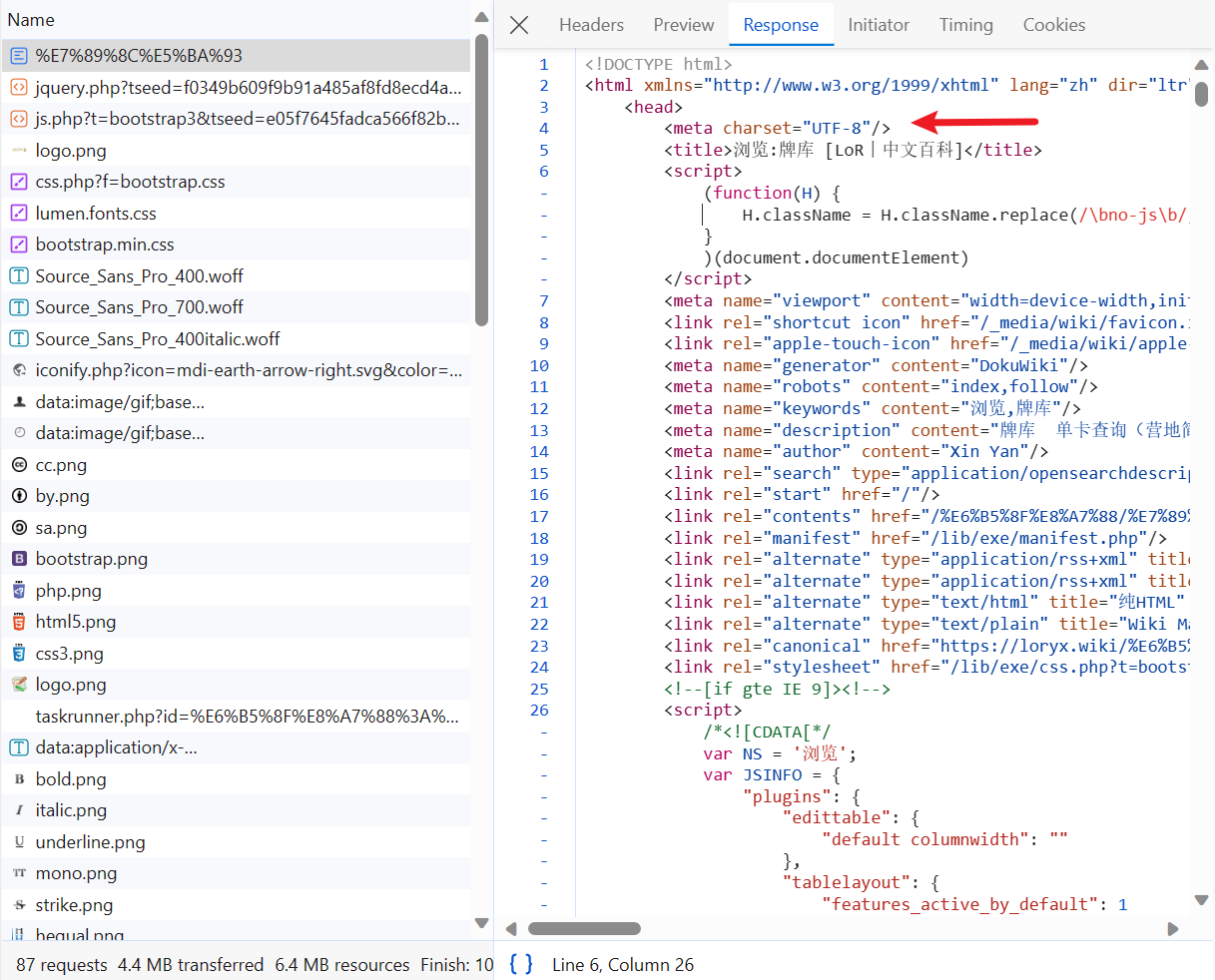
接着点开Headers
可以看到该网页是GET类型,并且状态码是200,URL也和该页面相同
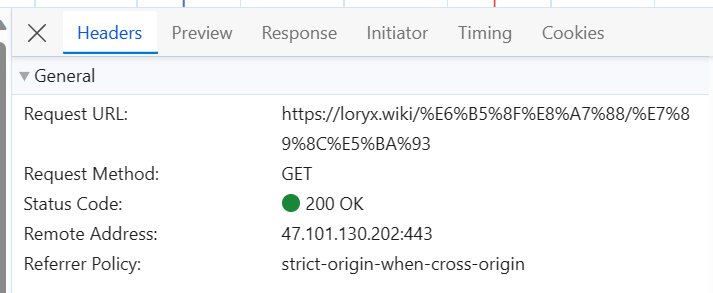
那么接下来就可以用python来模拟request请求了
爬虫代码
其实GET方法在这里data不带进去也行,写在这里是为了更方便理解
import requests
from lxml import etree
url = 'https://loryx.wiki/%E6%B5%8F%E8%A7%88/%E7%89%8C%E5%BA%93'
data = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/231.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/231.36 Edg/120.1.1.0'
}
res = requests.get(url=url, data=data)
res.encoding = 'utf-8'
接下来拿到了request对象后就可以来对元素进行筛选了
首先获取完整的网页源码print(res.text)
打印结果为
可以看见没有问题,那么继续用etree进行解析
et = etree.HTML(res.text)
继续分析网页内容
在图片链接处右键进入检查

然后我们就得到了标签页信息,我们将要获取的就是td标签中的col15 leftalign元素中的a标签的href链接信息,于此同时我们还需要对应的内容来作为图片的名称,否则你将会看到一堆乱码的哈希值
这里就用卡牌名称作为图片名,取元素的方法也和图片同理
# 图片链接
src = et.xpath("//td[@class='col15 leftalign']/a/@href")
# 图片名称
name = et.xpath("//td[@class='col0 leftalign']/text()")
当前所有采集到的内容都存储在src,name这两个列表中
我们打印src就可以看到这样的图片链接
打开后就可以在浏览器中看到图片
该效果说明我们下载图片的原理还是向这个网页发送请求然后再获取返回的结果
图片下载
演示只取9张图片,不然的话可以直接range(len(src))
for i in range(9):
with open(f"img/{name[i]}.png", 'wb') as f:
f.write(requests.get(src[i]).content)
这里需要注意要用wb,因为写入的是二进制数据
运行程序
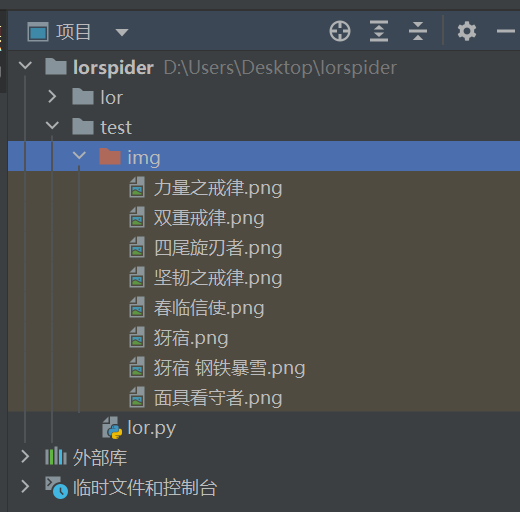
OK完工
总结
以上就是python中最基础的爬虫案例,当然实际项目中基本不会有用with open(f"img/{name[i]}.png", 'wb') as f:这种写法,因为效率太低了,本篇文章只是为了以最直观的方式呈现爬虫下载图片的原理
完整代码:
import requests
from lxml import etree
url = 'https://loryx.wiki/%E6%B5%8F%E8%A7%88/%E7%89%8C%E5%BA%93'
data = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
res = requests.get(url=url, data=data)
res.encoding = 'utf-8'
et = etree.HTML(res.text)
# print(res.text)
src = et.xpath("//td[@class='col15 leftalign']/a/@href")
name = et.xpath("//td[@class='col0 leftalign']/text()")
for i, index in enumerate(name):
name[i] = index.strip()
for i in range(9):
with open(f"img/{name[i]}.png", 'wb') as f:
f.write(requests.get(src[i]).content)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 三、安全工程—物理安全(CISSP)
- 家教上门助教小程序源码,家教小程序,家教系统,家教app,家教源码
- Docker实用篇
- 【【通过VDMA驱动HDMI显示的简易实验】】
- Java中的System类和一些练习
- 【PyTorch】在PyTorch中使用线性层和交叉熵损失函数进行数据分类
- 怎么理解AP AUTOSAR ara::com中的CommunicationGroup?
- 【动态规划】 【字典树】C++算法:472 连接词
- 南京观海微电子---时序分析基本概念(二)——保持时间
- SpringBoot对接支付宝当面付