10、基于LunarLander登陆器的Dueling DDQN强化学习(含PYTHON工程)
10、基于LunarLander登陆器的Dueling DDQN强化学习(含PYTHON工程)
LunarLander复现:
07、基于LunarLander登陆器的DQN强化学习案例(含PYTHON工程)
08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程)
09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程)
10、基于LunarLander登陆器的Dueling DDQN强化学习(含PYTHON工程)
基于TENSORFLOW2.10
0、实践背景
gym的LunarLander是一个用于强化学习的经典环境。在这个环境中,智能体(agent)需要控制一个航天器在月球表面上着陆。航天器的动作包括向上推进、不进行任何操作、向左推进或向右推进。环境的状态包括航天器的位置、速度、方向、是否接触到地面或月球上空等。
智能体的任务是在一定的时间内通过选择正确的动作使航天器安全着陆,并且尽可能地消耗较少的燃料。如果航天器着陆时速度过快或者与地面碰撞,任务就会失败。智能体需要通过不断地尝试和学习来选择最优的动作序列,以完成这个任务。
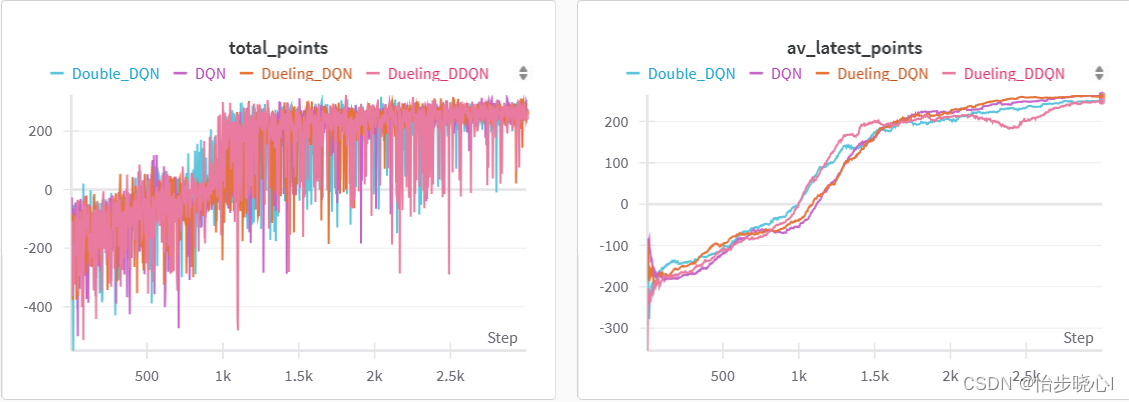
下面是训练的结果:
1、Dueling DDQN的实现原理
Dueling DDQN实际上就是Dueling DQN和DDQN结合,其对应的具体理论参考:
08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程)
09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程)
上面文章里面提及,Dueling DQN是在网络结构上进行改进,将原来的动作价值函数Q网络拆为状态函数和动作优势函数的和。
而DDQN实在迭代方式上进行改进,在进行贝尔曼方程的迭代求解时,将鸡蛋放在两个篮子里,同时使用Q网络和target Q网络对max(Q(s’,a’))进行计算,由此解决了Q函数的高估问题。
因此,两种结合,即可得到Dueling DDQN。
2、Dueling DDQN的实现关键代码
详细的代码各位可以下载后查看,在此只展示最为关键的改动部分,首先是网络的差异:
if self.model == 'DQN' or self.model == 'Double_DQN':
self.q_network = DeepQNetwork(num_actions, input_dims, 256, 256)
self.target_q_network = DeepQNetwork(num_actions, input_dims, 256, 256)
self.optimizer = Adam(learning_rate=lr)
if self.model == 'Dueling_DQN' or self.model == 'Dueling_DDQN':
# self.q_network, self.target_q_network = Dueling_DQN(num_actions, input_dims, 256, 256, 256)
self.q_network = GenModelDuelingDQN(num_actions, input_dims, 128, 128, 128)
self.target_q_network = GenModelDuelingDQN(num_actions, input_dims, 128, 128, 128)
self.optimizer = Adam(learning_rate=lr)
def DeepQNetwork(num_actions, input_dims, fc1, fc2):
q_net = Sequential([
Input(shape=input_dims), # 输入层,形状由state_size定义
Dense(units=fc1, activation='relu'), # 全连接层,128个单元,使用ReLU激活函数
Dense(units=fc2, activation='relu'), # 全连接层,128个单元,使用ReLU激活函数
Dense(units=num_actions, activation='linear'), # 输出层,单元数由num_actions定义,使用线性激活函数
])
return q_net
def GenModelDuelingDQN(num_actions, input_dims, fc1, fc2, fc3):
# define input
input_node = tf.keras.Input(shape=input_dims)
input_layer = input_node
# define state value function(计算状态价值函数)
state_value = tf.keras.layers.Dense(fc1, activation='relu')(input_layer)
state_value = tf.keras.layers.Dense(1, activation='linear')(state_value)
# state value and action value need to have the same shape for adding
# 这里是进行统一维度的
state_value = tf.keras.layers.Lambda(
lambda s: tf.keras.backend.expand_dims(s[:, 0], axis=-1),
output_shape=(input_dims,))(state_value)
# define acion advantage (行为优势)
action_advantage = tf.keras.layers.Dense(fc1, activation='relu')(input_layer)
action_advantage = tf.keras.layers.Dense(fc2, activation='relu')(action_advantage)
action_advantage = tf.keras.layers.Dense(fc3, activation='relu')(action_advantage)
action_advantage = tf.keras.layers.Dense(num_actions, activation='linear')(action_advantage)
# See Dueling_DQN Paper
action_advantage = tf.keras.layers.Lambda(
lambda a: a[:, :] - tf.keras.backend.mean(a[:, :], keepdims=True),
output_shape=(num_actions,))(action_advantage)
# 相加
Q = tf.keras.layers.add([state_value, action_advantage])
# define model
model = tf.keras.Model(inputs=input_node, outputs=Q)
return model
其次是训练过程迭代的差异:
if self.model == 'DQN' or self.model == 'Dueling_DQN':
# 计算最大的Q^(s,a),reduce_max用于求最大值
max_qsa = tf.reduce_max(target_q_network(next_states), axis=-1)
# 如果登录完成,设置y = R,否则设置y = R + γ max Q^(s,a)。
y_targets = rewards + (gamma * max_qsa * (1 - done_vals))
elif self.model == 'Double_DQN' or self.model == 'Dueling_DDQN':
next_action = np.argmax(q_values, axis=1)
# tf.range(q_values.shape[0]构建0-batch_size的数组,next_action是q_network得出的动作,两者组合成二维数组
# 从target_q_network(next_states)输出的batch_size*action dim个数组中取数
Q2 = tf.gather_nd(target_q_network(next_states),
tf.stack([tf.range(q_values.shape[0]), tf.cast(next_action, tf.int32)], axis=1))
y_targets = rewards + (gamma * Q2 * (1 - done_vals))
3、Dueling DDQN的实现效果
LunarLander环境下,使用Dueling DDQN并没有带来特别大的性能改善:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!