cpp学习日记6(只是记录给未来的自己看的)
C++中如何处理多返回值
法一:传指针或传引用。cherno个人喜欢在前面添加前缀out,比如outA,
法二:直接返回一个数组。当然这不通用,因为必须要同一类型。
法三:tuple或pair
tuple的一个小笔记:https://zhuanlan.zhihu.com/p/415508858
std::make_tuple,取得时候用std::get,std::tie之类的。
法四:比如要返回一个int和string,就创建一个struct包含int和string,然后返回类型设置为这个struct,定义一个结构体。
C++的模板的冰山一角
模板有点像宏,他可以让你做很多事,然而泛型却非常受限于类型系统以及其他很多因素,模板template要强大的多。
模板允许你定义一个可以根据你的用途进行编译的模板,你可以让编译器为你写代码,基于一套规则。所谓模板就是让编译器基于你给编译器的规则为你写代码。所谓的元编程。
例如,当你写一个函数时,你在这个函数里使用模板,你实际上在做的是,创建一个蓝本,因此当你决定要调用这个函数的时候,你可以指定特定的参数,这个参数决定了放到模板中的实际代码,这些就决定了你实际上是怎么使用这个函数的。
在这个例子里面,为了print不同类型的值,你必须写上很多个函数重载来搞定
void Print(int value) {
std::cout << value << std::endl;
}
void Print(std::string value) {
std::cout << value << std::endl;
}
int main() {
Print(5);
Print("hello");
}
实际上,每个重载函数直接大部分都是重复代码
template<typename T>//这是一个模板,通过template定义,意思是,这是一个模板,他会在编译期被评估,
void Print(T value) {//即,这不是一个实际的代码,也不是一个真的函数
std::cout << value << std::endl;//只有当我们实际调用它的时候,这些函数才被真的创建,
}//而当我们调用这个函数的时候,基于传递的参数,这个函数才被创建出来,并作为源代码被编译
//接下来的部分是模板参数,在这里我们选择typename作为模板参数的类型,用T作为名字
//我们可以在整个模板代码中使用T,替换在例子里出现的类型
//本质是复制粘贴,这里就把模板里面的T换成了得到的实际类型
int main() {
Print(5);//这个例子中类型是隐式地从实际参数中得到,是编译器自己推导出来的。
Print("hello");
Print<float>(2.1f);//这个例子中的类型是我们自己指定的
}
更进阶一点使用是这样子的:
template<typename T, int N>
class Array {
private:
T m_Array[N];
public:
int GetSize() const { return N; }
};
int main() {
Array<int,5> array;
}
以下还有一些比较主观的观点:
一些游戏工作室和公司禁止使用模板,这疑似有点极端了,毕竟模板的确非常有用,事实上,你可以深入地使用模板,但是如果搞得太复杂了,这将是一场噩梦。
C++堆与栈内存的比较
在应用程序启动后,操作系统要做的就是:它会将整个程序加载到内存并分配一大堆物理ram以便使我们的应用程序可以运行。
栈和堆是ram中实际存在的两个区域:栈通常是一个预定义大小的内存区域,通常为2M左右,堆也是一个预定义了默认值的区域,但是它可以生长,并随着应用程序的进行而改变。重要的是要知道这两个区域的实际位置(物理位置)在我们的ram中是完全一样的。这两个内存区域的实际位置都在我们的内存中。
对于这样子的一段代码
struct Vector3
{
float x, y, z;
Vector3()
:x(10), y(11), z(12) {};
};
int main() {
int value = 5;//栈上面分配内存
int array[5];
array[0] = 1;
array[1] = 2;
array[2] = 3;
array[3] = 4;
array[4] = 5;
Vector3 vertor;
int* hvalue = new int;//堆上面分配内存
*hvalue = 5;
int* harray = new int[5];
harray[0] = 1;
harray[1] = 2;
harray[2] = 3;
harray[3] = 4;
harray[4] = 5;
Vector3* hvertor = new Vector3();
delete hvalue;
delete[] harray;
delete hvertor;
}
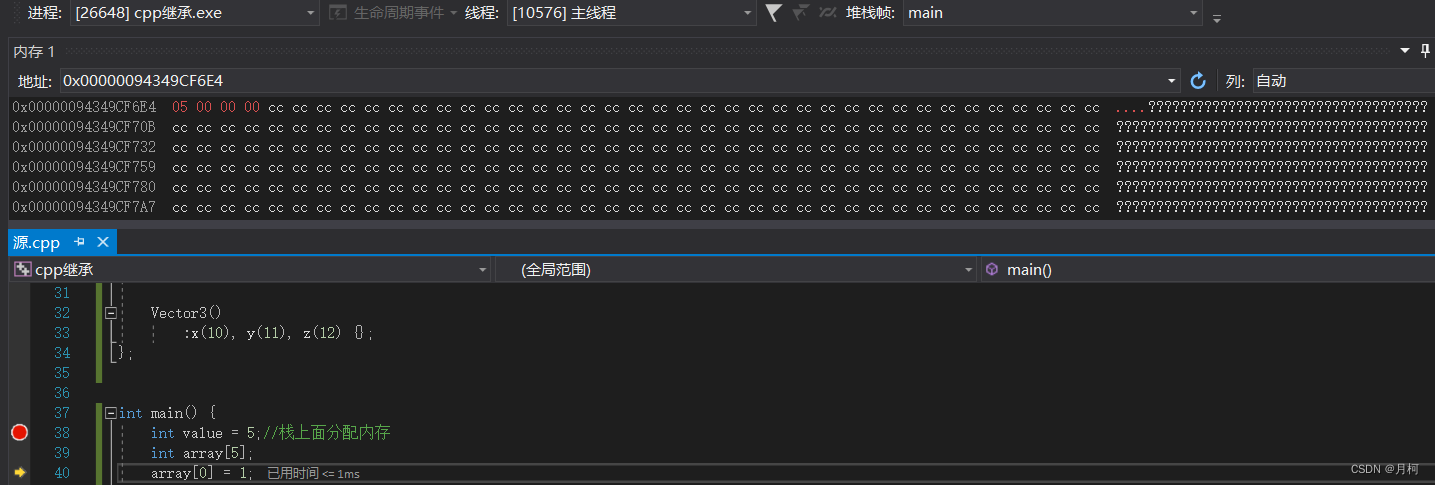
value在内存中的视图
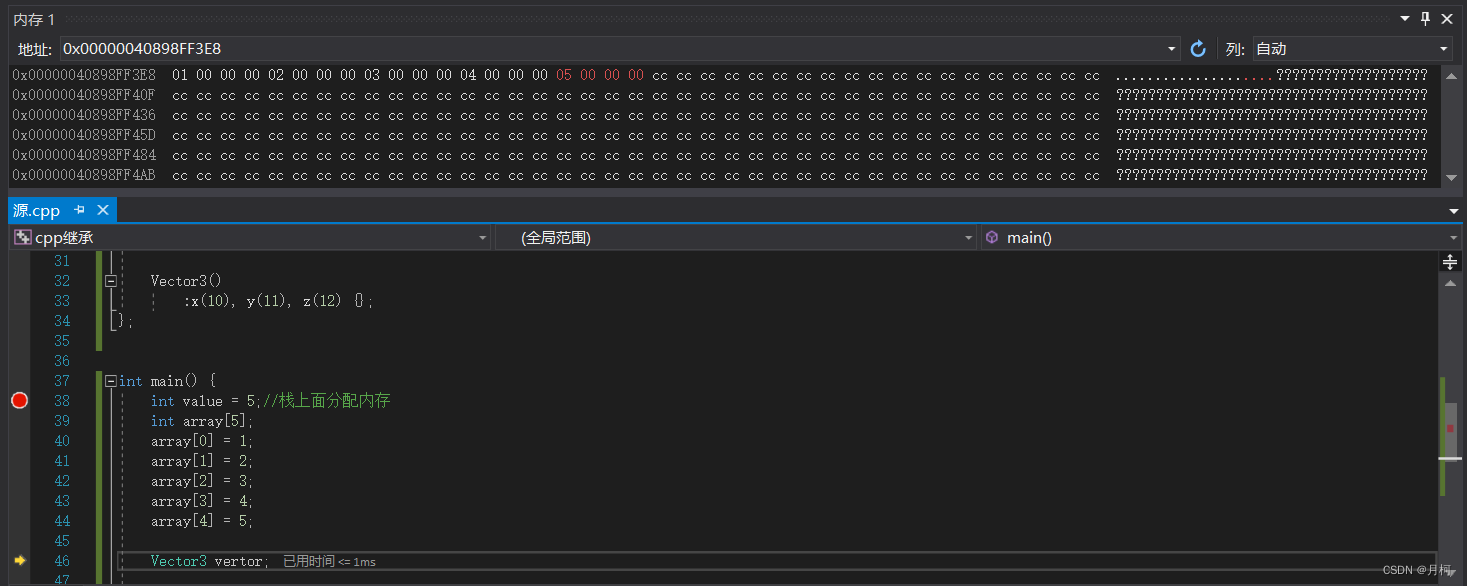
栈保存的数组。
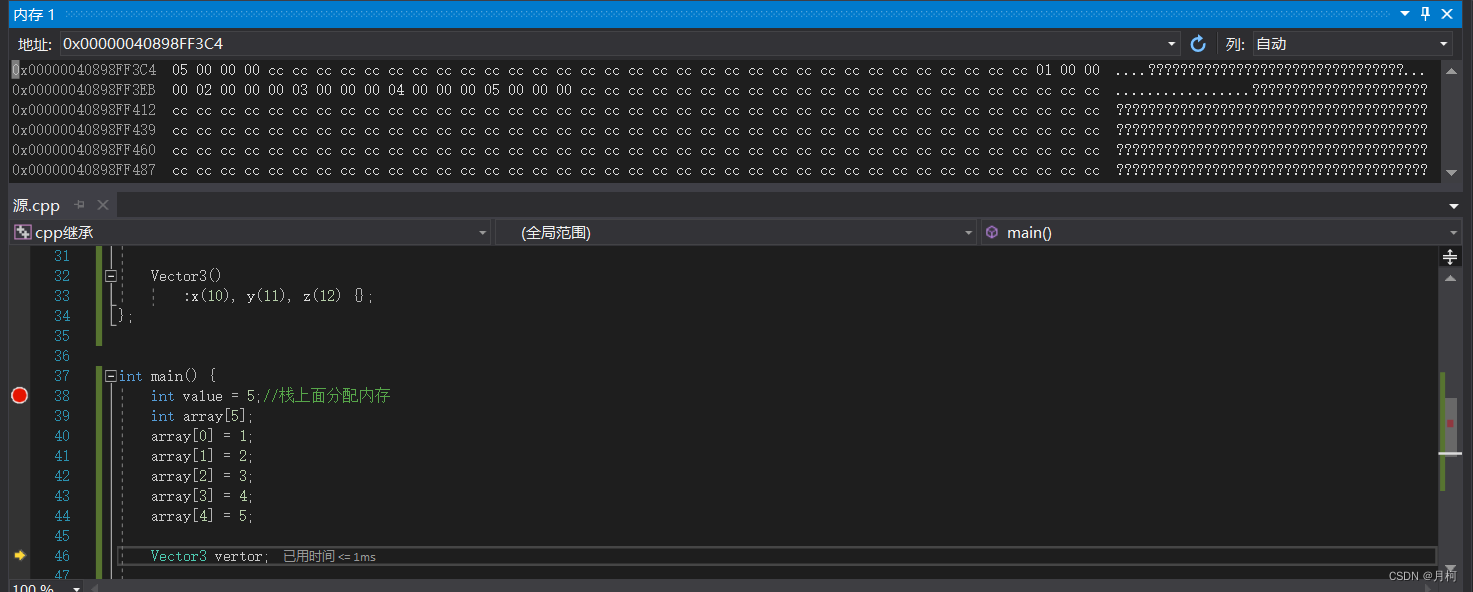
现在可以看到内存视图上一行就是之前保存的整数5了。
两者直接有一些字节,这其实是调试模式添加的安全守卫,用来确保我们不会溢出所有的变量。
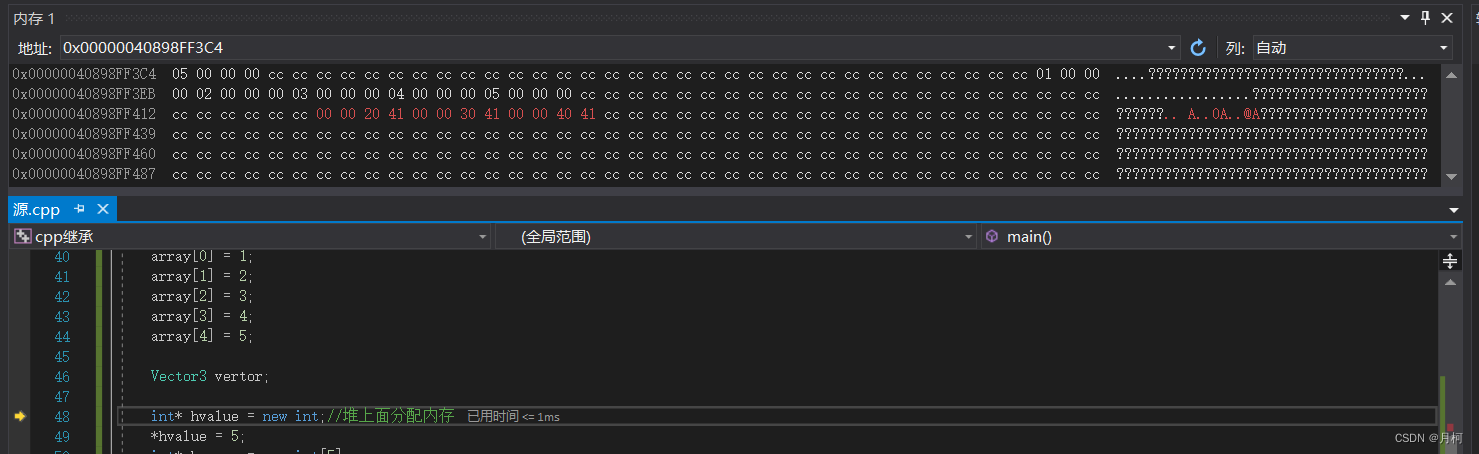
现在你甚至可以同时在内存中看到这三个变量了。
他们这么接近的原因是,当我们在栈里面分配变量时,发生的是,栈指针基本上就是移动这么多字节,如果想分配一个四字节整数,栈指针就移动四个字节,如果想分配一个数组,就移动数组大小的字节,另外,栈底一般在高地址所以先申请的变量在上面。栈做的事情就是,把东西堆在了一起,这就是栈分配内存很快的原因,就像pc指令一样,只需要移动栈指针就行。
而堆分配不是,他们并没有分配到“一堆”。
这里使用的是new关键字,然而如果使用智能指针,用make_unique或者make_shared等函数,这都是一样的,他会为你调用new。其次当然是需要delete你使用new分配的内存,智能指针可以为你做这个(释放内存)
而对于栈,释放内存没有任何开销,因为栈释放内存与分配一样,不需要将栈指针反向移动然后返回栈指针地址,在这里我们只需要弹出栈中的东西,我们的栈指针自然就回到了作用域开始之前。一条cpu的删除指令就可以释放所有东西。
对于new关键字,其实际上调用了malloc(malloc allocate的缩写),这样做通常会调用底层操作系统或平台的特定函数,这将在堆上为你分配内存。他这样做的方式是,当你启用你的应用时,你会得到一定数量的物理ram分配给你,你的程序会维护一个叫做空闲列表(free list)的东西,它是跟踪哪些内存块是空闲的,还有他们在哪里等等。所以当你使用malloc请求堆内存时,他可以浏览空闲链表,然后找到一块空闲内存至少和你要的一样大,会给你们它的一个指针,然后还要记录比如分配的大小和它现在被分配的情况,有一堆记录要做。
因此,在堆上分配内存是一堆的事情,而在栈上分配内存,就像是一条cpu指令。除此之外,栈上分配内存因为都是连续的,所以可以放在cpu缓存线上(cache line,可以理解为cpu cache中的最小缓存单位)。因此在栈中分配可能不会得到cache miss(CPU要访问的数据在Cache里面有,称为hit,反之则称为Miss)而堆中分配则有可能(少量的cache miss没啥,大量的就有问题了)。因此它们之间最大的影响就是分配的过程。
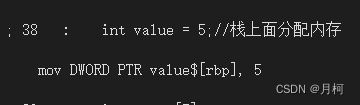
栈上面分配一个内存只对应了一条汇编指令。
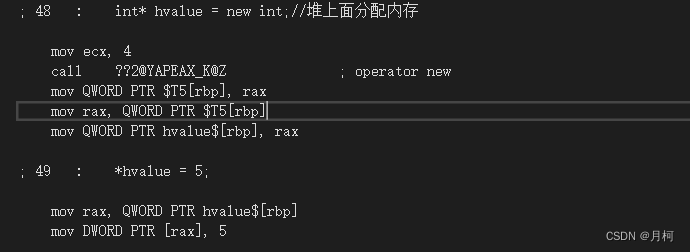
堆上面分配则一堆。
栈的优点真的一大堆,但是,真的太小了。
堆的缺点一大堆,但是,真的很大。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!