PostgreSQL16中的新增功能:双向逻辑复制
在这篇博客中,我们将深入探讨Postgres 16中引入的一些更高级的新功能。为了更好地理解这些功能,读者应具备一些Linux、Postgres和SQL的基础知识,因为我们将深入探讨这些新功能并指导如何实现它们。
本博客以在Ubuntu 23.04上运行的PostgreSQL 16(开发版)为基础进行编写。首先,我们将介绍一些背景信息,并简要介绍什么是双向复制,以及为什么它很重要,然后介绍我们如何实现双向逻辑复制。
#1?背景
在开始学习双向逻辑复制之前,我们首先必须了解什么是逻辑复制。
#2??逻辑复制的基础知识
从 PostgreSQL 10 就支持逻辑复制功能,并且在接下来的几年中逻辑复制功能已得到广泛应用和持续更新。逻辑复制是复制?(ie. replicating)数据对象的过程,其表示为它们的更改。通过这种方式,我们可以只复制表等对象的特定更改,而不是复制整个数据库,并将这些更改流式传输到不同的平台和版本。与物理复制形成鲜明对比,逻辑复制更注重于抽象层面的数据表示,这使得它能在不同平台和版本之间实现无缝的数据流传输。相比之下,物理复制更依赖于确切的块地址,导致其复制范围局限于整个数据库,且无法跨平台或版本进行数据流传输,因为每个平台或版本的数据结构必须完全匹配。

图1
逻辑复制还引入了理解其双向对应关系所必不可少的两个非常重要的元素:发布者和订阅者,你可以将它们理解为领导者节点(发布者)和跟随者节点(订阅者)的角色。发布者将收集其最近的更改,并将其作为有序的命令列表发送到订阅者。一旦订阅者接收到这一系列命令,就会将其应用于其数据。如果两个数据库最初具有相同的数据,那么订阅者将与发布者保持同步。?
#3?双向复制
现在我们了解了什么是逻辑复制,那么双向复制有什么不同之处呢?简而言之,双向逻辑复制是指复制中的所有节点都同时充当发布者和订阅者。现在,每个数据库都可以处理读写请求,所有的更改都会以流式传输的方式传递给彼此。这就是双向的方面,与之前只有单向变化流动不同,现在变化在两个方向上都进行流动。?
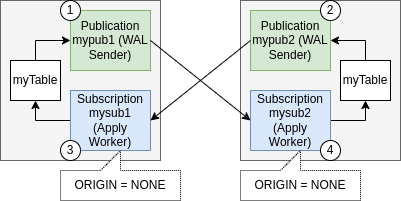
图2
Postgres 16 新添加的地方是它向 WITH 语句添加了一个新参数,用于过滤掉来自特定节点的复制。双向逻辑复制使用此参数 WITH(ORIGIN = NONE),这会过滤掉所有具有非NONE起源的连接的复制。从本质上讲,这只允许复制新添加的数据,您或许可以看到为什么会这样。如果一个数据库插入新数据并将其复制到第二个数据库,则第二个数据库将复制数据并插入该数据,从而触发对原始数据库的另一次复制。我们很快就陷入到无限复制的循环中,这就是为什么需要这个选项来保持一切有限的原因。
#4?好处
双向逻辑复制的主要优势在于,它提供了更多的可用性,既可以满足读请求,也可以满足写请求,因为我们有两个主节点。这对于许多需要强调写操作的应用程序来说尤其有益。
#5?缺点
双向逻辑复制需要一些前提条件才能正常运行,因为它的许多缺点都来自这些特定条件。例如,在设置复制时,每个数据库中的表必须遵循相同的架构、相同的名称和列,否则订阅服务器将无法找到该表。在逻辑复制可以支持复制用于创建表的数据定义语言 (DDL) 之前,用户必须手动执行此操作以确保一致性。
#6?建立
现在我们了解了双向逻辑复制的基础知识,我们可以深入研究如何在两个数据库之间实现它。开始与设置常规逻辑复制非常相似,但在创建发布服务器和订阅服务器时有一个非常重要的区别。
首先,我们将创建两个主数据库,它们将相互跟随:
$?initdb?-D?database1
$?initdb?-D?database2在每个数据库的 postgres.conf 文件中,将每个数据库的way_level设置为逻辑,并为每个数据库指定一个唯一的端口号:
postgres.conf 数据库1
port?=?5432
wal_level?=?logical
postgres.conf 数据库2
port?=?5433
wal_level?=?logical>>>启动两个数据库:
pg_ctl?-D?database1?-l?database1.log?start
pg_ctl?-D?database2?-l?database2.log?start>>>为每个数据库创建发布服务器:
#?CREATE?PUBLICATION?mypub1?FOR?TABLE?mytable;
#?CREATE?PUBLICATION?mypub2?FOR?TABLE?mytable;>>>为每个数据库创建订阅服务器:
#?CREATE?SUBSCRIPTION?mysub1?CONNECTION?'host=127.0.0.1?port=5433?user=postgres?dbname=postgres'?PUBLICATION?mypub2?WITH(ORIGIN?=?NONE);
#?CREATE?SUBSCRIPTION?mysub2?CONNECTION?'host=127.0.0.1?port=5432?user=postgres?dbname=postgres'?PUBLICATION?mypub1?WITH(ORIGIN?=?NONE);?
请注意,创建发布者和订阅者的顺序至关重要。首先,我们需要创建发布者,然后才能创建订阅者。为了更直观地理解,请参考图2。每个组件角落的数字表示它们的创建顺序,这有助于确保复制过程的顺利进行。
现在,当任何数据插入任一数据库时,都应在两个节点之间进行同步复制。
#7?结论
在这篇博客中,我们介绍了 PostgreSQL 16 中的新双向逻辑复制功能。首先,我们简要介绍了逻辑复制的背景以及用于同步数据的发布者/订阅者模型。然后,我们讨论了双向逻辑复制的工作原理以及允许其在不触发无限复制循环的情况下运行的新参数。
最后,我们了解了如何在两个主PostgreSQL 数据库之间设置双向复制。通过支持主节点之间的同步,增加可用性和数据持久性对于任何数据库应用程序都应该是轻而易举的。
*参考文献:
C, Vigneshwaran. Bi-Directional Replication Using Origin Filtering in PostgreSQL, Fujitsu, 31 Aug. 2023, www.postgresql.fastware.com/blog/bi-directional-replication-using-origin-filtering-in-postgresql.
原文链接:
https://www.highgo.ca/2023/12/18/new-in-postgresql-16-bi-directional-logical-replication/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 回环检测算法:Stable Trangle Descriptor
- MySQL如何处理约束
- Git教程学习:01 Git简介与安装
- RPC 框架之Thrift入门(一)
- 大津法(OTSU)点云强度信息分割
- K8s client go 合并informer
- 如何构建高效测试体系?掌握5大自动化测试模式就够了
- 学习Java API(二):基础知识点一文通?
- MOSS & 混元 巅峰对话!2024大模型发展都在这里
- 03-数据结构-栈与队列