Python如何对csv文件进行操作
发布时间:2024年01月12日

csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格:
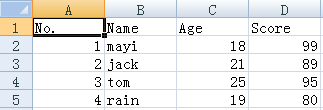
就可以存储为csv文件,文件内容是:
No.,Name,Age,Score1,mayi,18,99 2,jack,21,89 3,tom,25,95 4,rain,19,80
假设上述csv文件保存为"test.csv"
1.读文件
如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Python自带的csv模块,有两种方法可以实现:
第一种方法使用reader函数
接收一个可迭代的对象(比如csv文件),能返回一个生成器,就可以从其中解析出csv的内容:比如下面的代码可以读取csv的全部内容,以行为单位:
#!/usr/bin/python3
#?-*-?coding:utf-8?-*-
import?csv
#读with?open("test.csv",?"r",?encoding?=?"utf-8")?as?f:
????reader?=?csv.reader(f)
????rows?=?[row?for?row?in?reader]
print(rows)
得到:
[['No.',?'Name',?'Age',?'Score'], ?['1',?'mayi',?'18',?'99'], ?['2',?'jack',?'21',?'89'], ?['3',?'tom',?'25',?'95'], ?['4',?'rain',?'19',?'80']]
要提取其中某一列,可以用下面的代码:
#!/usr/bin/python3
#?-*-?coding:utf-8?-*-
import?csv
#读取第二列的内容
with?open("test.csv",?"r",?encoding?=?"utf-8")?as?f:
????reader?=?csv.reader(f)
????column?=?[row[1]?for?row?in?reader]
print(column)
得到:
['Name',?'mayi',?'jack',?'tom',?'rain']
注意从csv读出的都是str类型。这种方法要事先知道列的序号,比如Name在第2列,而不能根据'Name'这个标题查询。
这时可以采用第二种方法:
第二种方法是使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
#?-*-?coding:utf-8?-*-
import?csv
#读
with?open("test.csv",?"r",?encoding?=?"utf-8")?as?f:
????reader?=?csv.DictReader(f)
????column?=?[row?for?row?in?reader]
print(column)
得到:
[{'No.':?'1',?'Age':?'18',?'Score':?'99',?'Name':?'mayi'},
?{'No.':?'2',?'Age':?'21',?'Score':?'89',?'Name':?'jack'},
?{'No.':?'3',?'Age':?'25',?'Score':?'95',?'Name':?'tom'},
?{'No.':?'4',?'Age':?'19',?'Score':?'80',?'Name':?'rain'}]
如果我们想用DictReader读取csv的某一列,就可以用列的标题查询:
#!/usr/bin/python3
#?-*-?coding:utf-8?-*-
__author__?=?'mayi'
import?csv
#读取Name列的内容
with?open("test.csv",?"r",?encoding?=?"utf-8")?as?f:
????reader?=?csv.DictReader(f)
????column?=?[row['Name']?for?row?in?reader]
print(column)
得到:
['mayi',?'jack',?'tom',?'rain']
2.写文件
读文件时,我们把csv文件读入列表中,写文件时会把列表中的元素写入到csv文件中。
#!/usr/bin/python3
#?-*-?coding:utf-8?-*-
__author__?=?'mayi'
import?csv
#写:追加
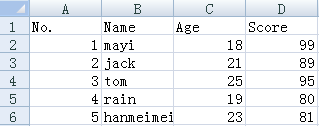
row?=?['5',?'hanmeimei',?'23',?'81']
out?=?open("test.csv",?"a",?newline?=?"")
csv_writer?=?csv.writer(out,?dialect?=?"excel")
csv_writer.writerow(row)
得到:
文章来源:https://blog.csdn.net/hakesashou/article/details/135560842
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!