Netty-4-网络编程模式
我们经常听到各种各样的概念——阻塞、非阻塞、同步、异步,这些概念都与我们采用的网络编程模式有关。
例如,如果采用BIO网络编程模式,那么程序就具有阻塞、同步等特质。
诸如此类,不同的网络编程模式具有不同的特点,这些网络编程模式就相当于我们的网络编程套路。
因此,了解并掌握网络编程模式是学习Netty和使用Netty进行网络编程的必经之路。
下面我们学习网络编程模式以及Netty如何对它们提供支持。
网络编程的3种模式
当我们去饭店吃饭时,会经常遇到以下三种模式。
- 排队打饭模式。这种模式主要出现在食堂等场所。人们在窗口前排队,饭菜打好后才走,若饭菜没有打好,人们一般是不会主动离开的。
- 点餐等待被叫模式。在这种模式下,我们会收到点餐号,饭店备好饭菜后就呼叫点餐号,我们需要自行去取。
- 包厢模式。这是我们最喜欢的模式,点餐后什么都不用管,坐在那里等着饭菜被服务员端上桌即可。
为了方便解释,我们可以将就餐模式与服务器应用做类比。
例如,把饭店比作服务器,而把饭菜比作数据。
这样的话,饭菜好了就相当于数据就绪,而端菜行为则可以当作读取数据。
通过进行类比,我们发现就餐的3种模式其实正好对应经典的3种网络编程I/O模式。

阻塞与非阻塞之间的区别在于要不要一直等,直到饭菜做好。
换言之,对于阻塞而言,在数据没有传输过来之前,会阻塞等待,直到数据到来;写的过程也类似,当缓冲区满时,写操作也会被阻塞,直到缓冲区"可写”。
但是,对于非阻塞而言,遇到这些情况则不做任何停留, 直接返回。
同步和异步之间的区别在于数据就绪后谁来读,类似于“饭菜好了谁来端”的问题。
数据就绪后,如果需要应用程序自行读取,就是同步过程;数据就绪后,如果由系统直接读取并回调给程序,就是异步过程。
在区分完以上两组概念后,我们可以做下对应:BIO是阻塞同步方式;NIO是非阻塞同步方式;AIO是非阻塞异步方式。
网络编程模式的选择要点
从表面上看,我们一般倾向于使用新的模式。
例如,我们青睐的顺序可能是AIO-NTO-BIO但是实际上,看似明显的优先顺序并不是什么"黄金准则”。
我们需要结合更多的因素来决定如何做出选择。
服务的连接数
假设应用程序的连接数有限,比如只有一两个连接,我们就无法预见NIO模式的性能肯定比传统程序的BIO模式好。
不过,可以预见的是,NIO模式的代码实现复杂度肯定高于BIO模式。
因此,在选择I/O模式时,我们需要了解应用程序到底能够支持多少个连接。
服务将要部署到的平台
对于Windows平台,我们一般都会优先选择AIO模式。
但是对于Linux平台,情况将可能有所不同,毕竟Linux平台对AIO模式的支持还不够成熟。
另外,有关NIO和AIO模式的一些测试表明,其实在Linux平台上,NIO和AIO模式的代码实现并无太大性能差别。
因此,对于大多数使用Linux作为服务器的应用平台而言,NIO模式或许才是更好的选择。
当前已有的架构和可用的实现
如果当前项目一直使用某种模式,那么我们一般很少有勇气去直接变革和采用新的模式,而是修修补补并沿用旧的模式。
此外,即使对于全新的项目,也不一定会选择我们想用的模式。例如,假设要选择AIO模式,但我们的技术栈是基于Netty的,那么AIO模式用不了。
综上所述,不同网络编程模式有自己适用的场景,我们不能仅仅依据推出时间的前后就直接做出决策。
换言之,具体问题具体分析、具体场景具体选择才是永恒之道。
Netty对网络编程模式的支持

Netty目前只推崇NIO模式。为什么不推荐另外两种模式呢?
Netty为什么不推荐BIO/OIO模式?
在连接数较多的情况下,BIO/OIO模式的阻塞特性就意味着耗资源、效率低。具体而言, 阻塞就意味着等待,等待就会占用线程。
考虑一下,在连接数比较多的情况下,如果每个连接上的请求又都在等待,占用的线程将会非常多,资源耗费就太大了。
不仅如此,一个进程对所能创建的线程数量也是有约束的,这一点无法克服。
其次,Netty为什么废弃AIO模式?原因主要有三点。
- Windows平台上的实现虽然已经非常成熟,但是Windows平台本身很少用作服务器。
- Linux平台经常用作服务器,但是Linux平台上AIO模式的实现还不够成熟。
- Linux平台上AIO模式的实现相比NIO模式而言稍复杂一些,但性能提升并不明显。
由上可知,对于Netty而言,NIO是Netty推崇的核心I/O模式。但是,有必要补充说明的是,对于NIO模式的实现方式,Netty支持的不止一种。
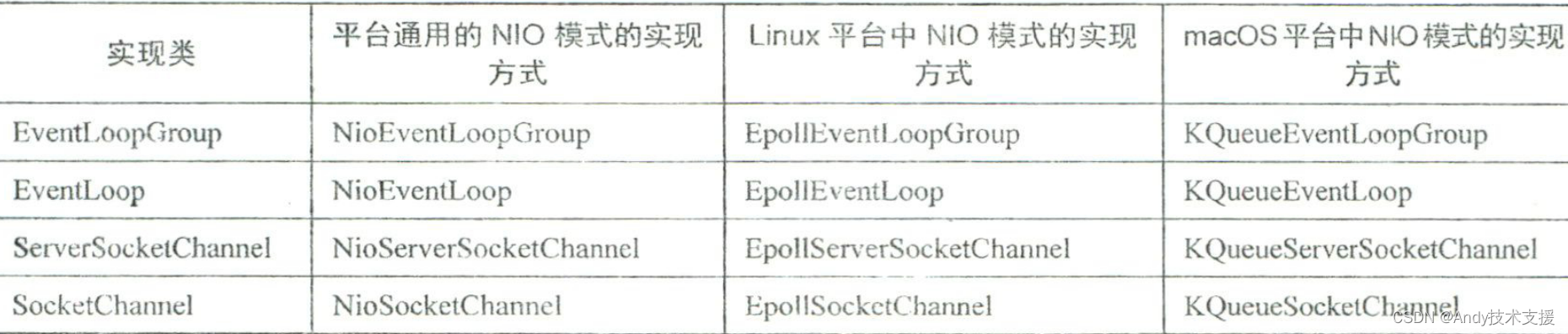
Netty的通用NIO模式的实现方式在Linux平台上使用的也是EpolL那么为什么此处还需要一套专有的Epoll相关实现呢?
“重新造轮子”无非有两个原因,自己的轮子更好、更强,这个道理同样适用于此。
具体原因包括以下两个方面。
-
Epoll相关实现能够暴露更多可控的参数:JDK的很多参数都不可调。例如,JDK的NIO模式在Linux平台上默认是水平触发且不可修改的;但对于Netty而言,水平触发和边缘触发都支持,并且可以切换(默认是边缘触发)。
-
垃圾回收更少,性能更好:这是Netty开发者自己给出的理由。不过,我们有理由相信Netty确实做到了,否则没有必要"重新造轮子"。
Netty对网络编程模式的实现
// 创建一个ServerBootstrap实例
ServerBootstrap serverBootstrap = new ServerBootstrap();
// 设置服务器通道类型为OioServerSocketChannel
serverBootstrap.channel(OioServerSocketChannel.class);
// 创建一个OioEventLoopGroup实例
OioEventLoopGroup eventLoopGroup = new OioEventLoopGroup();
// 设置服务器线程组为创建的OioEventLoopGroup实例
serverBootstrap.group(eventLoopGroup);
OIO模式的使用主要涉及OioServerSocketChannel和OioEventLoopGroup这两个关键类。
ServerSocketChannel 的创建
当执行 serverBootstrap.channel (OioServerSocketChannel.class)时,实际上执行的是如下方法:
//AbstractBootstrap.java
/**
* 设置通道的类型为指定的通道类
*
* @param channelClass 通道类
* @return 通道配置对象
*/
public B channel(Class<? extends C> channelClass) {
return channelFactory(new ReflectiveChannelFactory<C>(
ObjectUtil.checkNotNull(channelClass, "channelClass")
));
}
上述代码创建了 ReflectiveChannelFactory 来负责创建 OioServerSocketChannelo 顾名思义,ReflectiveChannelFactory使用“反射"方式来完成上述工作。
//ReflectiveChannelFactory.java
private final Constructor<? extends T> constructor; // 构造器,用于创建指定类型的对象
public ReflectiveChannelFactory(Class<? extends T> clazz) { // 构造函数,用于创建ReflectiveChannelFactory对象
ObjectUtil.checkNotNull(clazz, "clazz"); // 检查clazz是否为null
try {
this.constructor = clazz.getConstructor(); // 获取指定类的无参构造函数
} catch (NoSuchMethodException e) {
throw new IllegalArgumentException("Class " + StringUtil.simpleClassName(clazz) +
" does not have a public non-arg constructor", e); // 如果指定类没有无参公共构造函数,则抛出异常
}
}
@Override
public T newChannel() { // 创建一个指定类型的对象
try {
return constructor.newInstance(); // 使用构造器创建对象
} catch (Throwable t) {
throw new ChannelException("Unable to create Channel from class " + constructor.getDeclaringClass(), t); // 如果创建对象过程中发生异常,则抛出ChannelException异常
}
}
EventLoopGroup 的功能
EventLoopGroup 负责给每个通道分配 EventLoop0 例如,OioEventLoopGroup 负责给 BIOChannel分配ThreadPerChannelEventLoop (注意,这里的命名方式和其他的EventLoop不同)。
//ThreadPerChannelEventLoop.java
@Override
protected void run() {
for (;;) {
// 从任务队列中取出一个任务
Runnable task = takeTask();
if (task != null) {
// 执行任务
task.run();
// 更新最后一次执行时间
updateLastExecutionTime();
}
// 获取当前的通道
Channel ch = this.ch;
if (isShuttingDown()) {
// 如果正在关闭
if (ch != null) {
// 关闭通道
ch.unsafe().close(ch.unsafe().voidPromise());
}
// 如果确认关闭
if (confirmShutdown()) {
break;
}
} else {
// 如果没有正在关闭
if (ch != null) {
// 处理注销
if (!ch.isRegistered()) {
// 执行所有任务
runAllTasks();
// 注销
deregister();
}
}
}
}
}
ThreadPerChannelEventLoop在本质上相当于任务的执行体,而任务本身就是执行通道上的读写操作。例如,当写数据时,写数据这一操作会被当作任务提交给SingleThreadEventExecutor (ThreadPerChannelEventLoop 的父类)的 execute 方法来执行。
//SingleThreadEventExecutor.java
private void execute(Runnable task, boolean immediate) {
// 判断是否在事件循环中
boolean inEventLoop = inEventLoop();
// 添加任务到任务队列
addTask(task);
if (!inEventLoop) {
// 启动线程
startThread();
// 如果已经关闭
if (isShutdown()) {
// 是否从任务队列中移除任务
boolean reject = false;
try {
// 如果移除了任务,则标记为拒绝
if (removeTask(task)) {
reject = true;
}
} catch (UnsupportedOperationException e) {
// 任务队列不支持移除任务,只能继续希望在任务完全终止之前能够取而代之。
// 最坏情况下在任务终止时进行日志记录。
}
// 如果被拒绝,则进行拒绝处理
if (reject) {
reject();
}
}
}
// 如果不希望通过添加任务唤醒线程以及立即执行
if (!addTaskWakesUp && immediate) {
// 唤醒线程
wakeup(inEventLoop);
}
}
最终执行的是OioByteStreamChannel#doWriteBytes()方法。
//OioByteStreamChannel.java
@Override
protected void doWriteBytes(ByteBuf buf) throws Exception {
// 获取输出流
OutputStream os = this.os;
// 如果输出流为空,则抛出未连接异常
if (os == null) {
throw new NotYetConnectedException();
}
// 将ByteBuf中的字节写入输出流中
buf.readBytes(os, buf.readableBytes());
}
要完成对一种I/O模式的支持,我们至少需要两个组件: SocketChannel负责完成具体的读写务;NioEventLoop负责任务的执行。当需要切换I/O模式时,直接替换掉这些实现即可。
常见疑问
水平触发和边缘触发的定义
Netty既支持水平触发也支持边缘触发。Netty确实提供了这两种触发方式的定义。
public enum EpollMode {
EDGE_TRIGGERED,
LEVEL_TRIGGERED;
private EpollMode() {
}
}
那么什么是水平触发和边缘触发?在理论层次上进行解析。
水平触发
当被监控的文件描述符上有可读写事件时,通知用户去读写。如果用户一次没有读写完数据,就一直通知用户。
在用户确实不怎么关心这个文件描述符的情况下,频繁通知用户会导致用户真正关心的那些文件描述符的处理效率降低。
比如:点餐后,饭菜做好了(数据就绪),服务员端上来问你吃不吃(读写数据)。 不管你吃溢还是吃不完,服务员总是过来反复提醒你吃饭。
边缘触发
当被监控的文件描述符上有可读写事件时,通知用户去读写,但只通知一次,这就需要用户一次性把数据读写完。
如果用户没有一次性读写完数据,那就需要等待下一次新的数据到来时,才能读写上次未读写完的数据。
比如:服务员端来饭菜后,你没有一次性吃完,等你想吃剩下的饭菜时,就必须再次点餐才行。
Epoll既支持水平触发也支持边缘触发,那么该如何选择呢?如果选择水平触发,就要注意效率和资源利用率;而如果选择边缘触发,就要注意自身是否能一次性完成数据的读写。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JAVA版鸿鹄云商B2B2C:解析多商家入驻直播带货商城系统的实现与应用
- python 以及集成环境的安装
- CTF-Reverse学习-为缺少指导的同学而生
- 测试开发工具推荐(含自动化、性能、稳定性、抓包)
- 桉木芯建筑模板与其他材质比较有何不同?
- 机器学习——主成分分析(PCA)
- 低代码搭建工程项目管理方案:实现高效智能的数字化管理
- 前端性能优化二十:构建工具选型构建工具选型
- 3D视觉-ToF测量法(Time of Flight)
- iOS中的视频播放