Linux------进程的fork()详解
目录
3.fork的两个返回值,为什么会给父进程返回子进程pid,给子进程返回0?
前言
在之前,我们学习了进程的概念以及命令行启动进程,今天我们来学习另一种进程创建方法:用代码创建进程。
这里我们简单回顾一下,进程 = 可执行程序+task_struct对象。
创建一个进程,在系统中要申请内存,保存当前进程的可执行程序 + task_struct对象,并将 task_struct对象添加到进程列表
一、fork()的使用
我们在命令行man fork 看一下fork函数的用法与作用。?

根据图片可以得到fork会创建一个子进程,?在执行fork()过后,会从一个执行流变成两个执行流,这两个执行流都会执行后续的代码。这里说起来还是有点抽象,我们直接上代码试一试。代码如下。

我们发现明明我们只写了两句打印代码,却输出了三句,fork之后,打印代码执行了两遍。?还发现本身进程为21554,现在还多了一个进程为21555。

我们打印更多消息看一下?

执行看一看效果,这里我们发现,调用fork()后,新生成的进程是当前进程的子进程。

现在我们可以总结一下结论:只有父进程执行fork之前的代码,fork之后,父子进程都要执行后面的代码。
二、fork()的返回值
我们命令行? man fork 再来看一下fork的返回值。失败了返回-1,并且没有子进程被创建,如果成功,父进程返回子进程的PID,子进程返回0。这直接颠覆了我们的认知,为什么一个函数可以有两个返回值啊。

我们编辑代码,打印出来看看怎么回事。
?

我们发现确实如此,返回的值真的不一样?

虽然现在fork我们大概什么情况,但这里还有问题。
- 我们为什么要创建子进程?
- 我们创建子进程是为了让子进程和我们父进程做一样的事情吗?
我们为什么要创建子进程?
之前,我们学习C/C++的时候,根本就没听说过什么fork父进程子进程,这是因为当时我们的任务是线性的,只需要完成一件事就行了,现在,我们想让子进程协作父进程完成一些工作,这些工作是单进程解决不了的。
举个例子,我最爱迅雷边下边播这个功能,我们想让一个进程去下载,另一个进程去播放,这样才可以达到我们的目标。
我们创建子进程,就是为了让子进程和父进程做不一样的事。
但是,现在问题又来了,你如何保证他们两可以执行不同的代码呢?
父进程与子进程的分流
我们可以通过fork的返回值的不同,判断出谁是子谁是父,从而让他们执行不同的代码。

我们看一下结果,确实可以通过fork返回值的不同来分流。
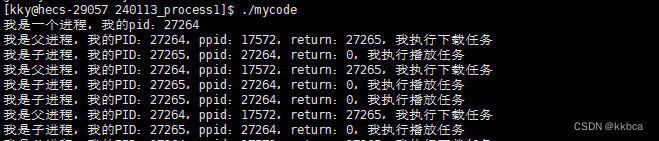
大家知道了fork的分流,但是底层逻辑我们还不清楚,这是如何分流的呀。怎么来了两个返回值呢?这些我们在下一章讲。
三、fork的一些难理解的问题
1.fork干了什么事情?
fork之后,子进程是没有自己的代码和数据的,子进程会和父进程共享代码和数据,因此他们执行的是一样的代码。
fork之前的代码,子进程也可以看见,但是fork之后,eip(是寄存器,用来存储CPU要读取指令的地址,CPU通过EIP寄存器读取即将要执行的指令)指向的fork后续的代码,eip也会被子进程继承,因此子进程只会执行fork之后的代码。
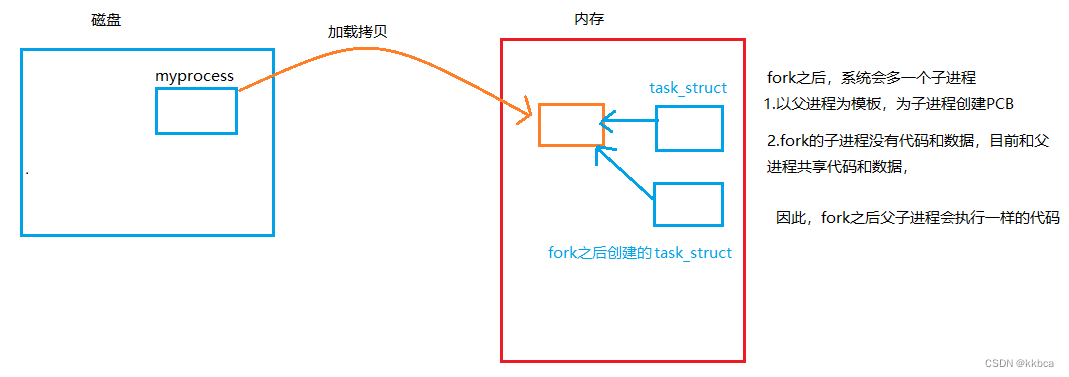
2.fork为什么会有两个返回值?
fork是系统接口,本质上就是一个函数,在fork里面进行创建子进程,将子进程放入调度队列中。我们现在知道,fork之后,代码共享,这里指的在fork内部,代码就已经被共享了,也就是子进程已经被创建出来了,最后需要return返回。
父进程需要return,子进程也需要return,因此fork会有两个返回值。
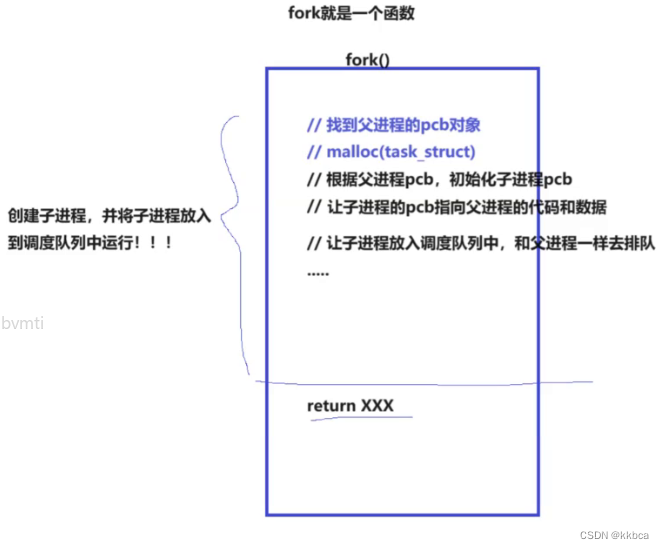
3.fork的两个返回值,为什么会给父进程返回子进程pid,给子进程返回0?
在现实中,你生了五个儿女,你叫他们不能统一的叫儿子或者女儿,因为这样儿女不知道你叫的是哪个儿子哪个女儿,因此你需要叫他们大儿子,二儿子,大女儿来区分他们。而他们叫你爸爸,正常情况下爸爸只有一个,不需要做额外区分。
计算机也要标识出到底是哪一个儿子,由于父只有一个,而子进程可以有很多个,因此父进程返回子进程的pid,来标识你创建好的子进程pid是多少。子进程返回0,因为子进程只有一个父亲,不需要额外标识出来。
4.fork之后,父子进程谁先运行?
首先,fork创建完成子进程,这仅仅是一个开始,创建完成后,系统的其他进程,还有当前的父进程和子进程,是要被CPU调度执行的。
当父子进程的PCB都被创建并在运行队列中排队的时候,哪一个进程先被CPU调度,哪一个进程就先运行,因此我们不确定,这是由各自PCB的调度信息(时间片,优先级等)+调度算法自助决定。
5.如何理解同一个变量,会有不同的值??
要理解这个问题,我们得先知道父子进程是具有独立性的。
比如之前我们提到的边下边播,你由于断网问题,下载停止了,但是只要你当前观看内容片段已经下载,播放就不会停止。
同理,如果我们fork之后,有了父子进程,父进程被杀掉,子进程也应该还在啊,或者子进程被杀掉,父进程应该也还在。如下。
杀死父进程,子进程仍在运行

杀死子进程,父进程仍在运行?
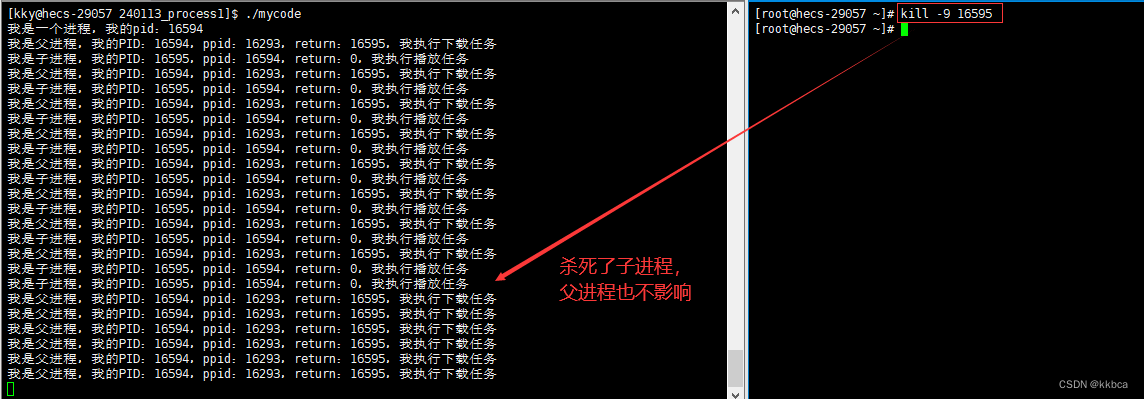
现在我们可以得知, 进程在运行的时候,无论什么关系,进程之间都具有独立性。
这个独立性是如何做到的呢?
进程的独立性,首先表现在有各自的PCB。但是我们之前提到fork之后,子进程是没有代码和数据的,他和父进程共享代码和数据。代码本身是只读的,不会影响。但是数据是会修改的。因此父子进程代码共享,数据各自必须想办法私有一份。
这运用到了写时拷贝,如果数据值是一样的,那我就不做处理,如果数据不一样,那我子进程要想办法深拷贝一份数据,当子进程的值覆盖上去,这就完成了父子进程数据各自一份。
正是由于返回的时候发生了写时拷贝,因此同一个变量会有不同的值。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!