集成xxljob项目如何迁移到K8S

前言
大家好,今天我们将基于XXL-Job,探讨任务调度迁移到云端的相关话题。
XXL-Job是一款功能强大、易用可靠的国产分布式任务调度平台,是目前国内使用比较广泛的分布式任务调度平台之一。它的主要特点包括:
- 支持分布式、多线程任务调度;
- 具有完整的管理后台,可以实现任务调度的创建、修改、启动和监控;
- 提供了丰富的调度方式,包括cron表达式、API调用、消息队列等;
- 支持任务执行过程的日志记录和错误处理,可以帮助用户快速定位问题。
随着云计算的全面普及和发展,越来越多企业开始认识到公共云平台的无限潜力。许多企业开始将自己的应用程序和业务迁移到云环境中,以获取更高的灵活性、弹性和可扩展性。然而,任务调度作为企业中的一个重要业务组件,对于软件开发和运营的质量都有着极大的影响。在云环境下部署和运行任务调度组件,需要考虑诸多因素,如安全性、可靠性、性能等。因此,企业需要认真思考如何在云平台上部署和运行任务调度组件,以保证运营效率、降低成本、提高应用程序的质量和性能。
云端迁移过程
由于历史原因,我们的 xxl-job-admin 端是部署在 k8s 集群外部的。在我们的项目中,我们是使用XML文件来集成xxl-job的,相关的集成配置如下所示:
<bean id="xxlJobExecutor" class="com.xxl.job.core.executor.impl.XxlJobSpringExecutor">
<property name="adminAddresses" value="${xxl.job.admin.addresses}"/>
<property name="appname" value="${xxl.job.executor.appname}"/>
<property name="ip" value="${xxl.job.executor.ip}"/>
<property name="port" value="${xxl.job.executor.port}"/>
<property name="accessToken" value="${xxl.job.accessToken}" />
<property name="logPath" value="${xxl.job.executor.logpath}"/>
<property name="logRetentionDays" value="${xxl.job.executor.logretentiondays}"/>
</bean>
其中,相关配置值如下:
xxl.job.admin.addresses = http://127.0.0.1/xxl-job-admin
xxl.job.executor.appname = xxl-job-executor-sample
xxl.job.executor.ip =
xxl.job.executor.port = 30065
xxl.job.accessToken = mytoken
xxl.job.executor.logpath = /etc/logs
xxl.job.executor.logretentiondays = -1
解决注册IP错误问题
当我们使用了与其他普通 Spring 项目的 JAR 包相同的部署方式将任务调度组件部署到了 k8s 上后,虽然我们通过管理页面看到已经成功将服务注册到了 xxl-job-admin,但我们发现该服务的 IP 地址为 k8s 中 Pod 的私有 IP 地址。因为k8s 集群内部通信的私有 IP 地址在集群外不可访问,这导致了任务无法正常执行,系统提示 IP 地址无效。
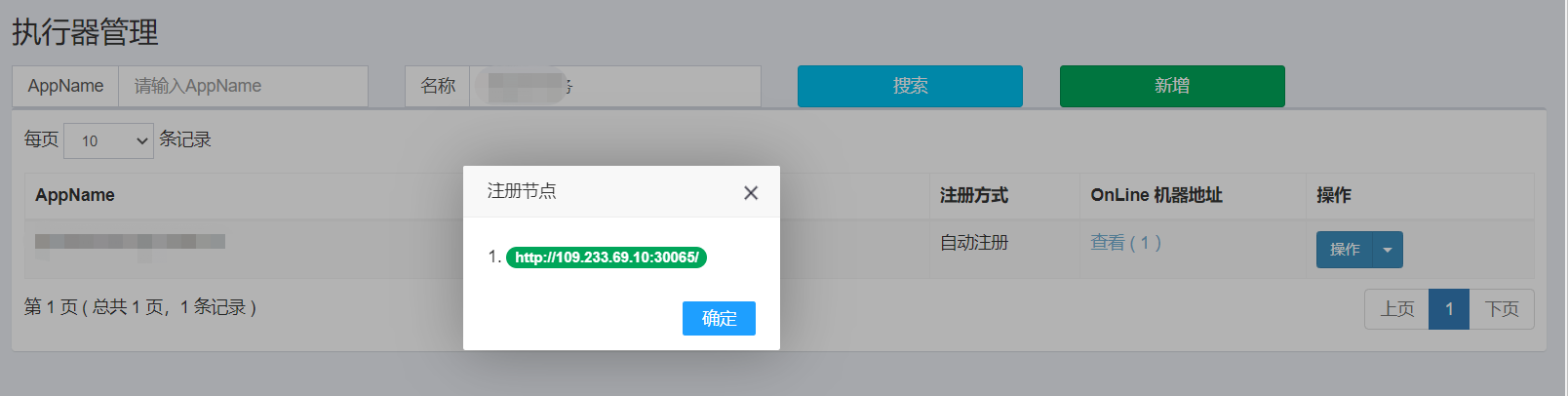
那么该如果解决这个问题呢?
阅读XXL-Job源码可以深入了解XXL-Job框架的实现细节和内部机制。在XXL-Job源码中,可以找到一些关键方法,帮助我们了解IP和port的获取规则。
具体来说,这些方法位于com.xxl.job.core.executor.XxlJobExecuto类中的initEmbedServer方法。当执行器启动时,会优先使用配置文件中的IP和端口,如果配置文件未指定,则通过NetUtils获取本地主机地址和默认端口。在注册成功后,执行器就可以通过该IP和端口与注册中心进行正常通信。部分源码如下:
port = port > 0 ? port : NetUtil.findAvailablePort(9999);
ip = ip != null && ip.trim().length() > 0 ? ip : IpUtil.getIp();
由此可见,为了解决这个问题,我们有两种方法可以尝试。
- 我们可以直接将配置文件中的 xxl.job.executor.ip 指定为正确的IP地址,这样XXL-Job就可以正确地找到执行器并与之通信了。
- 在XXL-Job的管理页面上将执行器的注册方式改为手动录入,并直接填写正确的IP地址。
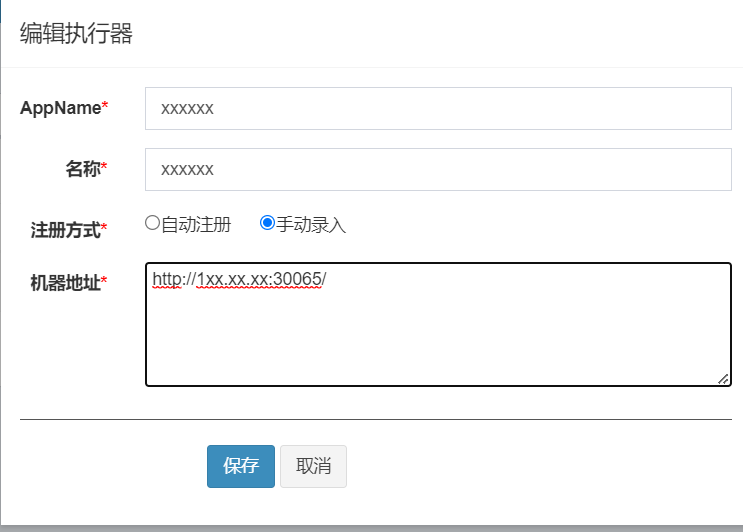
无论使用哪种方法,唯一的要求就是确保与执行器实际运行的IP地址匹配。这样就可以使XXL-Job正常工作了。
实现动态注册IP
无论采用前面提到的两种方式中的哪一种,均存在一个xxl-job配置写死IP地址的问题,而无法实现IP的动态获取,这对于后期的维护和动态扩缩容都是不利的。那么如何在保证获取到的IP正确的前提下实现自动获取呢?
为了实现xxl-job自动获取注册IP的目的,在获取IP的过程中,我们可以结合Dubbo框架的获取IP逻辑,改造获取IP的顺序。按照以下顺序获取IP:
-
首先根据环境变量获取IP,如果环境变量中存在,则获取环境变量中的IP地址。
-
如果环境变量中不存在,则根据配置文件获取IP,如果配置文件中存在,则获取配置文件中的IP地址。
-
如果配置文件中不存在,则获取本地IP地址。
这样的优先级顺序可以确保我们始终能够获得一个可用的注册IP。通过这种方式会让获取IP更加智能化和可靠。以下是具体改造步骤:
- 在 deploy.yaml 文件中添加环境变量。
spec:
template:
spec:
containers:
- env:
- name: XXLJOB_IP_TO_REGISTRY
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- 使用Java代码中的注释@Configuration和@Bean注释来替代使用XML文件进行Bean的注册和配置。
@Slf4j
@Configuration
public class XxlJobConfiguration {
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init start...");
// 获取ip规则优先级, 环境变量(此值为deploy.yaml中配置)>配置文件>默认(本地)
String ip = System.getenv("XXLJOB_IP_TO_REGISTRY");
ip = StringUtils.isBlank(ip) ? PropertiesCacheUtil.getConfigValue("xxl.job.executor.ip") : ip;
String port = PropertiesCacheUtil.getConfigValue("xxl.job.executor.port");
String logRetentionDays = PropertiesCacheUtil.getConfigValue("xxl.job.executor.logretentiondays");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.admin.addresses")));
xxlJobSpringExecutor.setAppname(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.appname")));
xxlJobSpringExecutor.setIp(ip);
if (StringUtils.isNotBlank(port)) {
xxlJobSpringExecutor.setPort(Integer.parseInt(port));
}
xxlJobSpringExecutor.setAccessToken(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.accessToken")));
xxlJobSpringExecutor.setLogPath(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.logpath")));
if (StringUtils.isNotBlank(logRetentionDays)) {
xxlJobSpringExecutor.setLogRetentionDays(Integer.parseInt(logRetentionDays));
}
log.info(">>>>>>>>>>> xxl-job config init end...");
return xxlJobSpringExecutor;
}
}
通过这样的改造,我们可以更加智能可靠地获取注册IP,实现了xxl-job自动获取IP地址的目的。
解决分片问题
无论使用上面提到的写死配置方式还是实现动态注册IP,都是仅适用于单机的情况,如果需要部署多台任务调度组件,那么又该如何配置才能保证每个服务都可以被调度,以达到实现分片处理的目的呢?
方法1:
我们可以通过在deploy.yaml文件中配置Pod的反亲和性,使得单台宿主机上仅能部署一个服务,并且配置在service.yaml中配置代理策略为Local的方式来达到上述目的。具体配置如下:
deploy.yaml改造如下:
spec:
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- 你的APP名称
service.yaml 改造如下:
spec:
## 代理策略:默认Cluster。Cluster表示:流量可以转发到其他节点上的Pod。Local表示:流量只发给本机的Pod
externalTrafficPolicy: Local
经过上面的改造,我们成功的解决了分片问题,但是又带来了新的问题,如下图所示:
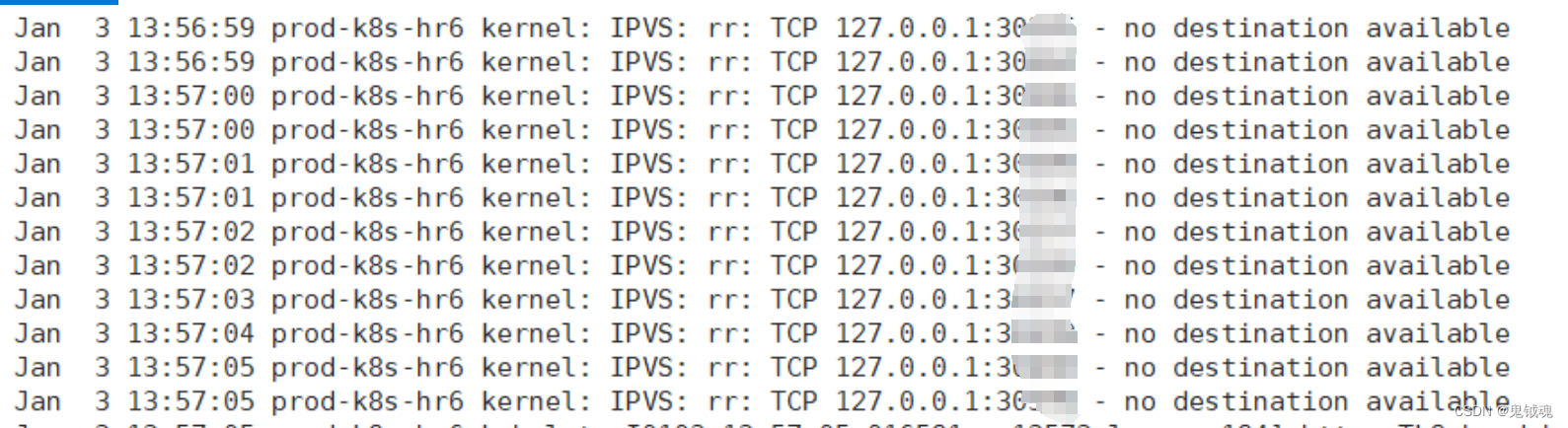
上面的方法都是使用Deployment方式部署的,那么,我们是否可以换下思路使用StatefulSet方式部署呢?这就衍生出了下面的方法。
方法2:
- 改造配置:
## 注册到xxljob的端口,多个使用英文逗号分隔
xxl.job.executor.port = 30065,30066,30067
- 改造代码
@Slf4j
@Configuration
public class XxlJobConfiguration {
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
// 获取ip规则优先级, 配置中心>环境变量(此值为deploy.yml中配置)
String ip = PropertiesCacheUtil.getConfigValue("xxl.job.executor.ip");
ip = StringUtils.isBlank(ip) ? System.getenv("XXLJOB_IP_TO_REGISTRY") : ip;
log.info("==>ip:{}", ip);
String podName = StringUtils.trimToEmpty(System.getenv("POD_NAME"));
log.info("==>POD_NAME:{}", podName);
String[] split = StringUtils.split(podName, "-");
String index = split[split.length - 1];
log.info("==>index:{}", index);
String allPort = PropertiesCacheUtil.getConfigValue("xxl.job.executor.port");
String[] portSplit = StringUtils.split(allPort, ",");
String port = portSplit[Integer.parseInt(index)];
log.info("==>port:{}", port);
String logRetentionDays = PropertiesCacheUtil.getConfigValue("xxl.job.executor.logretentiondays");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.admin.addresses")));
xxlJobSpringExecutor.setAppname(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.appname")));
xxlJobSpringExecutor.setIp(ip);
if (StringUtils.isNotBlank(port)) {
xxlJobSpringExecutor.setPort(Integer.parseInt(port));
}
xxlJobSpringExecutor.setAccessToken(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.accessToken")));
xxlJobSpringExecutor.setLogPath(StringUtils.trimToEmpty(PropertiesCacheUtil.getConfigValue("xxl.job.executor.logpath")));
if (StringUtils.isNotBlank(logRetentionDays)) {
xxlJobSpringExecutor.setLogRetentionDays(Integer.parseInt(logRetentionDays));
}
return xxlJobSpringExecutor;
}
}
@Slf4j
@Component
public class InitNotifyDataFromDBHandler {
@XxlJob("initNotifyDataFromDBHandler")
public void initNotifyDataFromDBHandler(String params) {
// XxlJobHelper.getShardIndex():当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
// XxlJobHelper.getShardTotal():总分片数,执行器集群的总机器数量;
String podName = StringUtils.trimToEmpty(System.getenv("POD_NAME"));
log.info("==>POD_NAME:{}", podName);
XxlJobHelper.log("==>POD_NAME:{}", podName);
String[] split = StringUtils.split(podName, "-");
String index = split[split.length - 1];
log.info("==>index:{}", index);
XxlJobHelper.log("==>index:{}", index);
// 下标0:机器总数目,下标1:当前机器在总机器中的位置下标
String[] args = {XxlJobHelper.getShardTotal() + "", index};
// 其他业务逻辑
}
}
- 重写K8S中yaml部署文件
## 创建StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: your-app
namespace: your-namespace
spec:
serviceName: your-app
replicas: 3
selector:
matchLabels:
app: your-app
template:
metadata:
annotations:
statefulset.kubernetes.io/pod-name: $(POD_NAME)
labels:
app: your-app
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: project.node
operator: In
values:
- your-project-node
volumes:
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
containers:
- env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: DUBBO_IP_TO_REGISTRY
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
- name: XXLJOB_IP_TO_REGISTRY
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.hostIP
image: your-image
imagePullPolicy: Always
name: your-app
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
terminationGracePeriodSeconds: 30
## 创建service
---
apiVersion: v1
kind: Service
metadata:
name: service-your-app-0
namespace: your-namespace
spec:
selector:
statefulset.kubernetes.io/pod-name: your-app-0
type: NodePort
sessionAffinity: None
ports:
- name: xxljob-your-app
port: 30065
targetPort: 30065
nodePort: 30065
---
apiVersion: v1
kind: Service
metadata:
name: service-your-app-1
namespace: your-namespace
spec:
selector:
statefulset.kubernetes.io/pod-name: your-app-1
type: NodePort
sessionAffinity: None
ports:
- name: xxljob-your-app
port: 30066
targetPort: 30066
nodePort: 30066
---
apiVersion: v1
kind: Service
metadata:
name: service-your-app-2
namespace: your-namespace
spec:
selector:
statefulset.kubernetes.io/pod-name: your-app-2
type: NodePort
sessionAffinity: None
ports:
- name: xxljob-your-app
port: 30067
targetPort: 30067
nodePort: 30067
经过上面的改造,我们成功的解决了使用第一种方法带来的问题。但是这个方法同样以下缺点,但是这种缺点相对来说是可以忽略的,因为生产环境不会随便增减副本数量。
- 在K8S的dashboard页面直接新增副本数量无效,需要先新增配置文件中的端口,再新增部署yaml中对应的Service,才能真正实现副本数量的增加。
小结
以上就是今天分享的任务调度上云的相关内容,我们的目标不仅仅是将任务调度程序迁移到云端,更是要通过实现自动注册功能,使任务调度程序能自动加入云端调度集群,从而更方便地进行任务调度,提升运行效率和可扩展性。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!