python爬虫——抓取表格pandas当爬虫用超简单
发布时间:2024年01月22日
pandas还能当爬虫用,你敢信吗?而且超级简单,两行代码就趴下来
只要想提取的表格是属于<table 标签内,就可以使用pd.read_html(),它可以将网页上的表格都抓取下来,并以DataFrame的形式装在一个列表中返回。
例子:
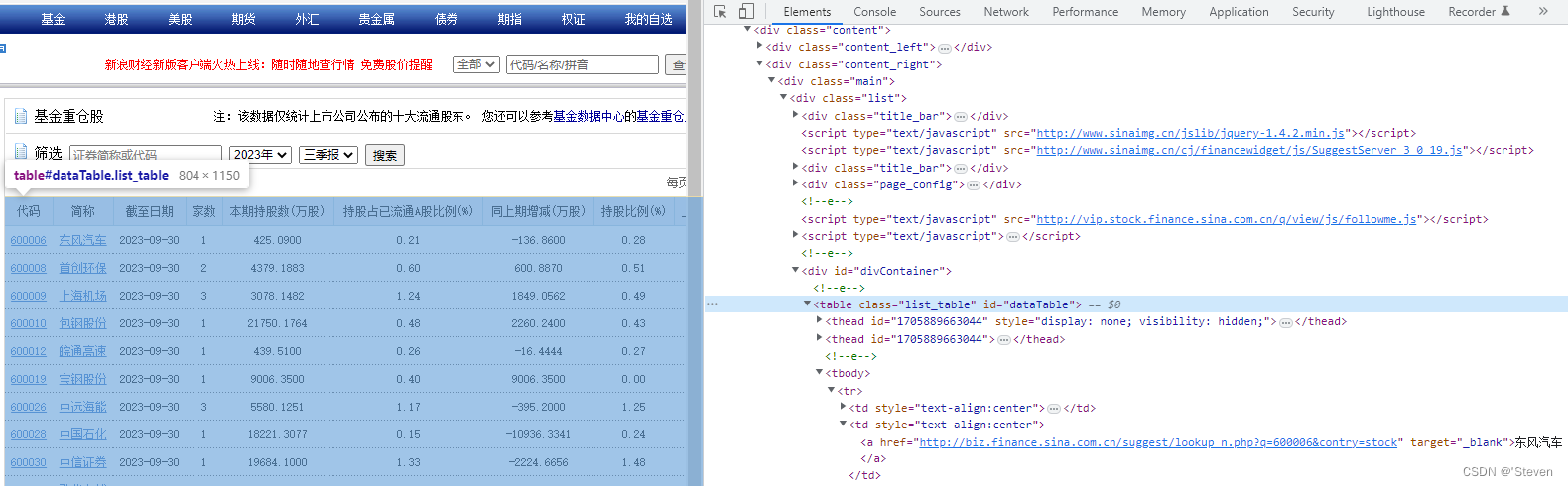
比如这个基金网站,想趴下基金的持仓股表格,
http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml

首先F12,页面元素点击表格内容,发现最上面的层级是<table,那么就可以用pandas直接抓!
代码如下:
import pandas as pd
df = pd.DataFrame()
for i in range(6):
url = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)
df = pd.concat([df,pd.read_html(url)[0]])
print("第{page}页完成~".format(page=i+1))
df.to_csv('D:\\data.csv', encoding=gbk, index=0) #保存地址
就看到保存的CSV文件了
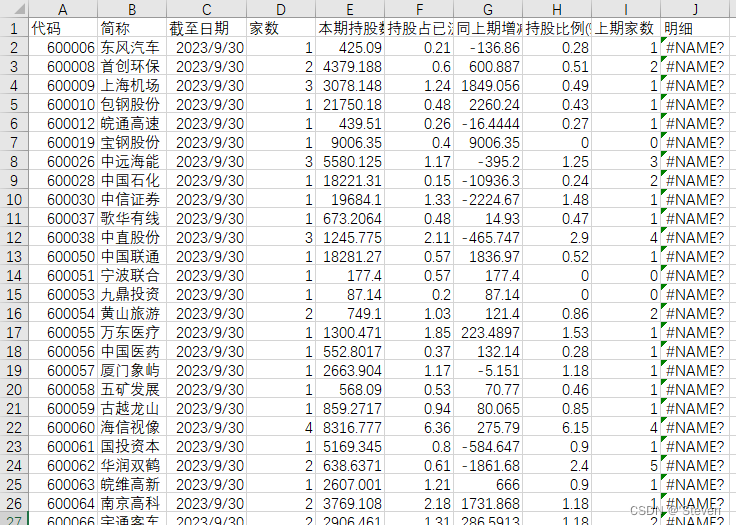
搞定。。!是不是超级简单,记得点个赞哦!
文章来源:https://blog.csdn.net/Sixth5/article/details/135741235
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!