【AIGC】CLIP
?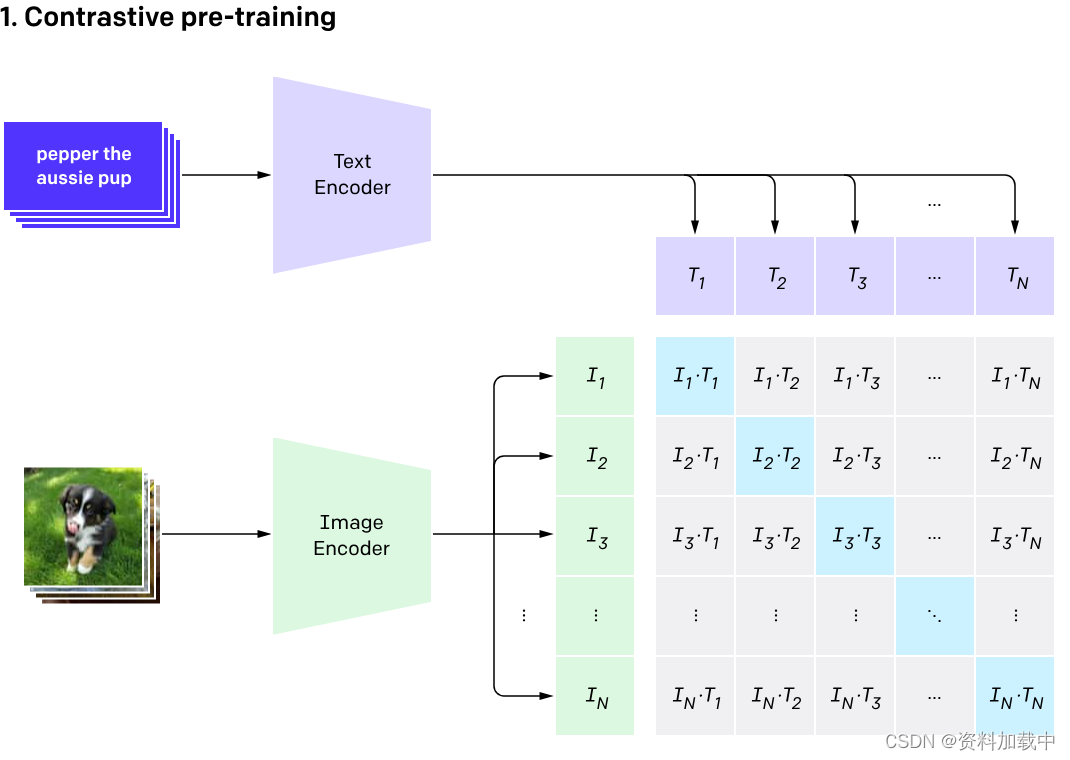
CLIP的基本原理
-
对比学习: Clip使用对比学习来训练模型。对比学习的目标是通过将正样本(相似的图像和文本对)与负样本(不相似的图像和文本对)进行比较,从而使模型学会区分不同样本之间的差异。这有助于模型学到更具泛化性的表示。
-
双向编码器: Clip包括两个部分的编码器,一个用于处理图像输入,另一个用于处理文本输入。这两个编码器都被设计为强大的神经网络,能够将输入数据映射到高维空间的表示。
-
共享嵌入空间: Clip的关键创新之一是共享图像和文本之间的嵌入空间。这意味着图像和文本在模型的表示中存在着一致的嵌入空间,从而使得模型能够直接比较图像和文本的相似性。
-
Contrastive Loss: 在训练中,Clip使用对比损失(Contrastive Loss)来促使模型学会将相似的图像和文本对映射到相邻的区域,而将不相似的对映射到远离的区域。这通过最小化正样本和最大化负样本之间的距离来实现。
-
预训练和微调: Clip首先在大规模的图像和文本数据上进行预训练,然后通过微调在特定任务上进行调整。这种两阶段的训练使得模型能够在不同任务上取得良好的性能。
CLIP的应用场景
-
图像分类和语义理解: Clip可以用于图像分类任务,通过输入一张图像和一个描述文本,模型可以学习如何将图像与相应的语义标签相关联。这使得Clip在理解图像内容的同时能够产生相关的文本描述。
-
文本检索: Clip不仅可以从图像中检索相关文本描述,还可以从文本中检索相关图像。这使得模型可以用于构建更强大的文本检索系统,其中用户可以通过输入文本查询相关的图像信息。
-
零样本学习: Clip的设计允许它在处理新颖的、以前未见过的类别时表现较好。这使得模型适用于零样本学习任务,其中模型需要在没有先验知识的情况下识别新类别的图像。
-
视觉问答: Clip可以用于解决视觉问答问题,其中系统需要理解图像并回答相关的问题。通过融合图像和文本信息,Clip可以更好地理解问题的语境并生成准确的答案。
-
生成式任务: Clip可以用于生成式任务,例如图像和文本的联合生成。模型可以通过对图像和文本的联合理解来生成与输入相关的新图像或文本。
-
半监督学习: Clip可以在半监督学习任务中表现出色,其中模型可以从少量有标签的样本中学习,并利用大量无标签的数据来提高性能。
-
跨模态搜索: Clip的多模态能力使其适用于跨模态搜索任务,例如从图像中搜索相关的文本信息,或从文本中搜索相关的图像信息。
CLIP的基本使用
-
获取CLIP模型: 首先,你需要获取CLIP模型的权重参数。OpenAI提供了预训练的CLIP模型,你可以从官方的代码仓库或其他来源下载。
-
加载模型: 使用深度学习框架(如PyTorch或TensorFlow)加载CLIP模型。确保你使用的框架版本和模型的权重相匹配。
import torch import clip device = "cuda" if torch.cuda.is_available() else "cpu" model, transform = clip.load("ViT-B/32", device=device) -
预处理图像和文本: 对于图像,使用适当的预处理步骤将图像转换为模型所需的格式。对于文本,将文本编码为模型可以理解的格式。
# 图像预处理 image = transform(image).unsqueeze(0).to(device) # 文本编码 text = clip.tokenize(["a description of your image"]).to(device) -
进行推断: 将预处理后的图像和文本输入到CLIP模型中,进行推断并获取模型的输出。
# 进行推断 image_features = model.encode_image(image) text_features = model.encode_text(text) # 计算相似度分数 similarity_score = (text_features @ image_features.T).squeeze(0)
CLIP实例应用
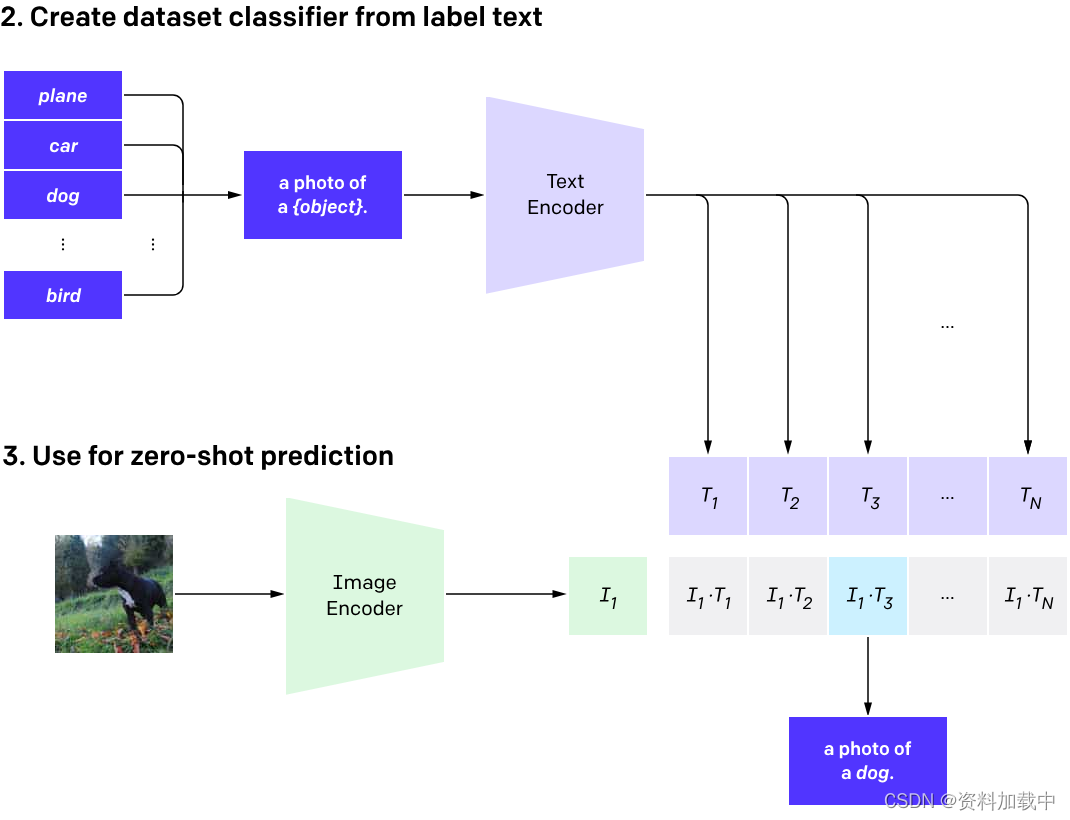
零样本预测
?从 CIFAR-100 数据集中获取图像,并预测数据集中 100 个文本标签中最可能的标签。
import os
import clip
import torch
from torchvision.datasets import CIFAR100
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("./data/"), download=True, train=False)
# Prepare the inputs
image, class_id = cifar100[3637]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
可视化
import os
import pickle
from PIL import Image
import matplotlib.pyplot as plt
# Define the path to the CIFAR-100 dataset
dataset_path = os.path.expanduser('./data/cifar-100-python')
# Load the image
with open(os.path.join(dataset_path, 'test'), 'rb') as f:
cifar100 = pickle.load(f, encoding='latin1')
# Select an image index to visualize
image_index = 3637
# Extract the image and its label
image = cifar100['data'][image_index]
label = cifar100['fine_labels'][image_index]
# Reshape and transpose the image to the correct format
image = image.reshape((3, 32, 32)).transpose((1, 2, 0))
# Create a PIL image from the numpy array
pil_image = Image.fromarray(image)
# Display the image
plt.imshow(pil_image, interpolation='bilinear')
plt.title('Label: ' + str(label))
plt.axis('off')
plt.show()
参考链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vite 创建 react 项目
- Jmeter测试关联接口
- Element ui 改变el-transfer 穿梭框的大小
- 自学黑客(网络安全)技术——2024最新
- 探索LinkedIn:使用TypeScript和jsdom库的高级内容下载器
- python区别与C++的总结
- YOLOv8_测试yolov8n.pt,yolov8m.pt训练的时间和效果、推理一张图片所需时间_解决训练时进程被终止killed
- 编程语言的发展未来?
- 迁移学习的最新进展和挑战
- Vue指令之v-on