Langchain-Chatchat开源库使用的随笔记(一)
发布时间:2023年12月31日
笔者最近在研究Langchain-Chatchat,所以本篇作为随笔记进行记录。
最近核心探索的是知识库的使用,其中关于文档如何进行分块的详细,可以参考笔者的另几篇文章:
原项目地址:
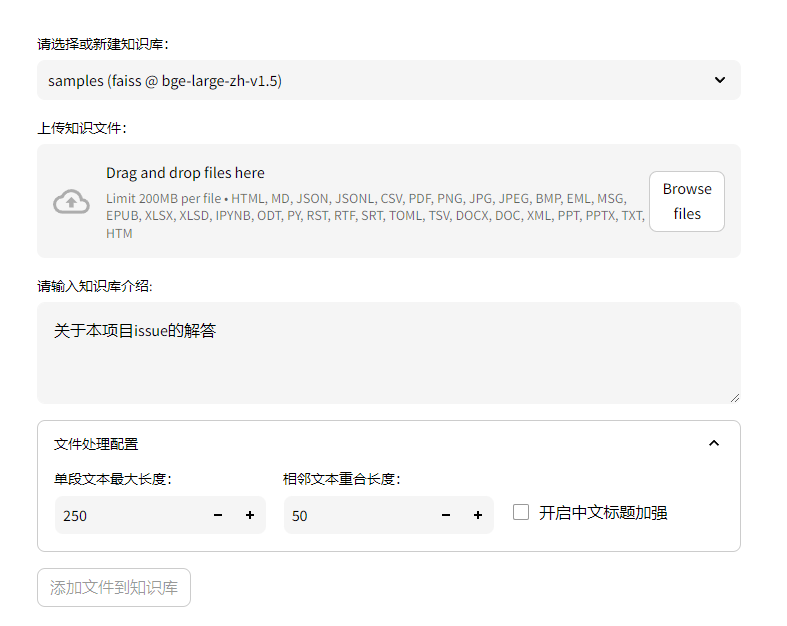
1 Chatchat项目结构
整个结构是server 启动API,然后项目内自行调用API。
API详情可见:http://xxx:7861/docs ,整个代码架构还是蛮适合深入学习
2 Chatchat一些代码学习
2.1 12个分块函数统一使用
截止 20231231 笔者看到chatchat一共有12个分chunk的函数:
CharacterTextSplitter
LatexTextSplitter
MarkdownHeaderTextSplitter
MarkdownTextSplitter
NLTKTextSplitter
PythonCodeTextSplitter
RecursiveCharacterTextSplitter
SentenceTransformersTokenTextSplitter
SpacyTextSplitter
AliTextSplitter
ChineseRecursiveTextSplitter
ChineseTextSplitter
借用chatchat项目中的test/custom_splitter/test_different_splitter.py来看看一起调用make_text_splitter函数:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter
# 使用DocumentLoader读取文件
filepath = "knowledge_base/samples/content/test_files/test.txt"
loader = document_loaders.UnstructuredFileLoader(filepath, autodetect_encoding=True)
docs = loader.load()
CHUNK_SIZE = 250
OVERLAP_SIZE = 50
splitter_name = 'AliTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":
docs = text_splitter.split_text(docs[0].page_content)
for doc in docs:
if doc.metadata:
doc.metadata["source"] = os.path.basename(filepath)
else:
docs = text_splitter.split_documents(docs)
for doc in docs:
print(doc)
3 知识库相关实践问题
3.1 .md格式的文件 支持非常差
我们在configs/kb_config.py可以看到:
# TextSplitter配置项,如果你不明白其中的含义,就不要修改。
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source": "huggingface", # 选择tiktoken则使用openai的方法
"tokenizer_name_or_path": "",
},
"SpacyTextSplitter": {
"source": "huggingface",
"tokenizer_name_or_path": "gpt2",
},
"RecursiveCharacterTextSplitter": {
"source": "tiktoken",
"tokenizer_name_or_path": "cl100k_base",
},
"MarkdownHeaderTextSplitter": {
"headers_to_split_on":
[
("#", "head1"),
("##", "head2"),
("###", "head3"),
("####", "head4"),
]
},
}
# TEXT_SPLITTER 名称
TEXT_SPLITTER_NAME = "ChineseRecursiveTextSplitter"
chatchat看上去创建新知识库的时候,仅支持一个知识库一个TEXT_SPLITTER_NAME 的方法,并不能做到不同的文件,使用不同的切块模型。
所以如果要一个知识库内,不同文件使用不同的切分方式,需要自己改整个结构代码;然后重启项目
同时,chatchat项目对markdown的源文件,支持非常差,我们来看看:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter
# 载入
filepath = "matt/智能XXX.md"
loader = document_loaders.UnstructuredFileLoader(filepath,autodetect_encoding=True)
docs = loader.load()
# 切分
splitter_name = 'ChineseRecursiveTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":
docs = text_splitter.split_text(docs[0].page_content)
for doc in docs:
if doc.metadata:
doc.metadata["source"] = os.path.basename(filepath)
else:
docs = text_splitter.split_documents(docs)
for doc in docs:
print(doc)
首先chatchat对.md文件读入使用的是UnstructuredFileLoader,但是没有加mode="elements"(参考:LangChain:万能的非结构化文档载入详解(一))
所以,你可以认为,读入后,#会出现丢失,于是你即使选择了MarkdownHeaderTextSplitter,也还是无法使用。
目前来看,不建议上传.md格式的文档,比较好的方法是:
- 文件改成 doc,可以带
#/##/### - 更改
configs/kb_config.py当中的TEXT_SPLITTER_NAME = "MarkdownHeaderTextSplitter"
文章来源:https://blog.csdn.net/sinat_26917383/article/details/135317522
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Vulnhub 靶场】【ContainMe: 1】【简单-中等】【20210729】
- 【Leetcode】83. 删除排序链表中的重复元素
- Linux Kernel 4.14--EOF
- java开发需要掌握的TypeScript相关的知识点,细致简洁版。
- Springboot常见报错及解决方案
- 补码转原码,[Y]补转[-Y]补
- 外卖点单配送管理系统(JSP+java+springmvc+mysql+MyBatis)
- 基于Java SSM框架实现游戏账号交易系统项目【项目源码+论文说明】计算机毕业设计
- 从零开始的OpenGL光栅化渲染器构建2-冯式光照
- JMeter 性能测试实例分析