面试题-【消息队列】
消息队列
问题1 如何进行消息队列的技术选型
为什么使用消息队列?消息队列的优点和缺点?kafka,activeMQ,rabbitMQ、rocketMQ的优点和缺点,都有什么区别以及适用那些场景?
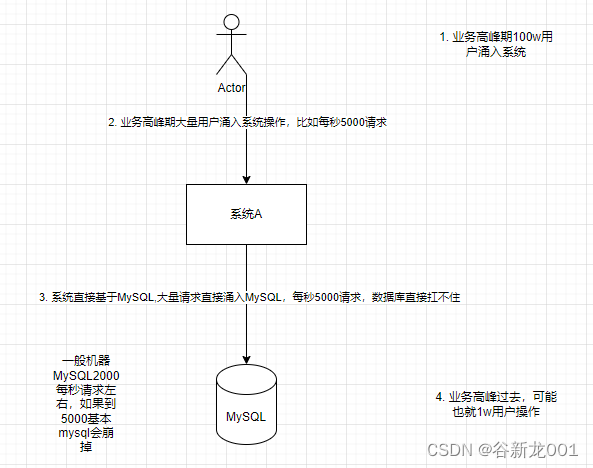
消息队列应用场景有很多,但是主要目的是的解耦,异步,削峰
优点
解耦 (pub/sub模型)
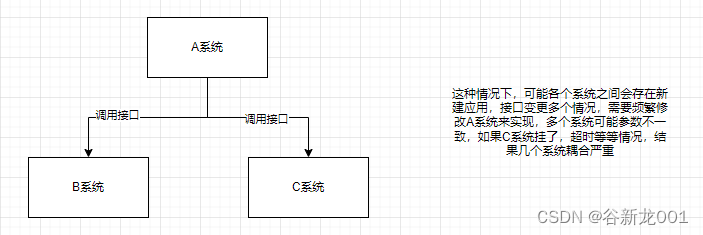
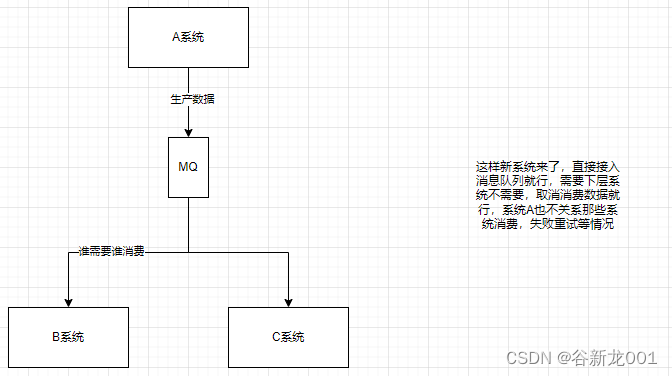
异步(异步接口性能优化)
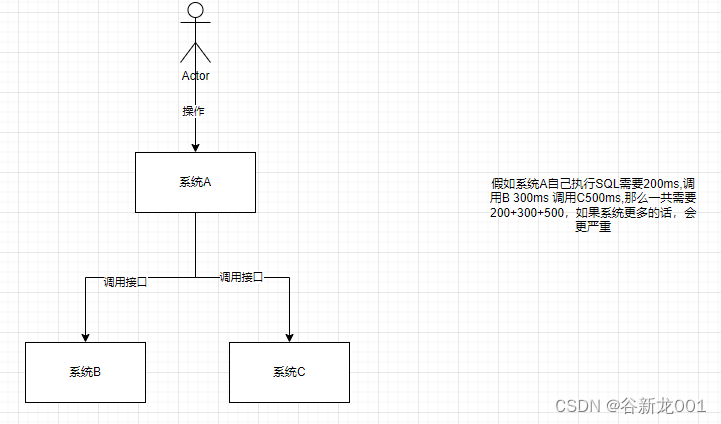
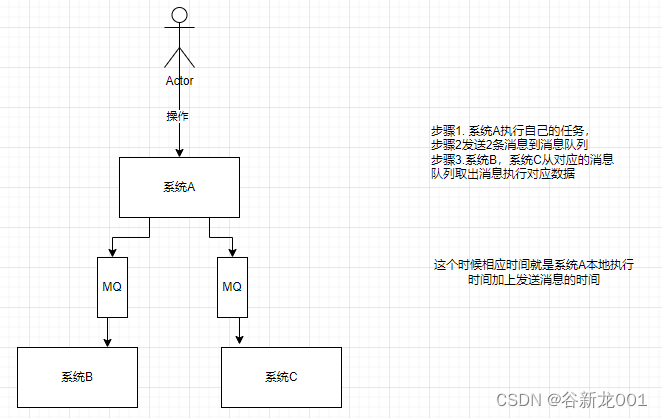
削峰
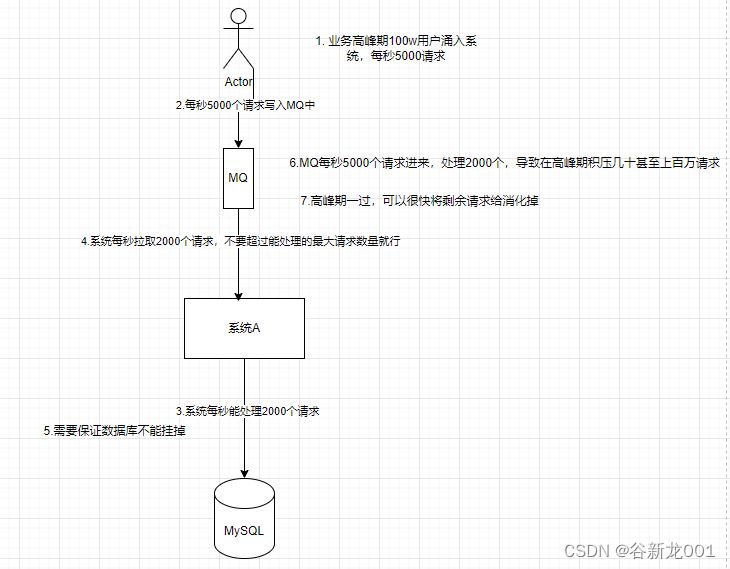
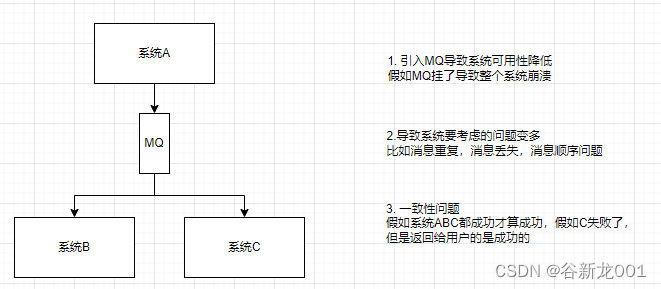
使用消息队列的缺点
- 可用性降低
- 系统复杂性提高,比如消息重复,消息丢失,消息顺序
- 一致性问题
几种消息队列的特性
| 特性 | activeMQ | RabbiteMQ | RocketMQ | kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级 | 万级 | 10万级,可以支撑高吞吐量 | 10万级别,高吞吐量。适合日志采集,实时计算等场景 |
| topic数量对吞吐量的影响 | – | – | topic可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic topic从几十个到几百个的时候,吞吐量会「大幅度下降」所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 | topic从几十个到几百个的时候,吞吐量会「大幅度下降」所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源 |
| 时效性 | ms级 | 微秒级,这是rabbitmq的一大特点,延迟是最低的 | ms级 | ms级 |
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 非常高,分布式架构 | 非常高,分布式架构 | 非常高,分布式架构 |
| 消息可靠性 | 有比较低的丢消息可能 | – | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,可以做到0丢失 |
| 总结 | 非常成熟,比较早 偶尔丢消息社区活跃度低 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
其实activeMQ、RabbiteMQ更类似单机应用,一个queue的数据不会被拆分成多分分散到多个机器上,RocketMQ、kafka是分布式的,一个topic数据可以被拆分成多个partition,进而分散到多个机器上,摆脱单机容量限制
问题2 引入消息队列之后该如何保证其高可用性
高可用主要是避免单机故障(有副本)以及数据不丢(磁盘)
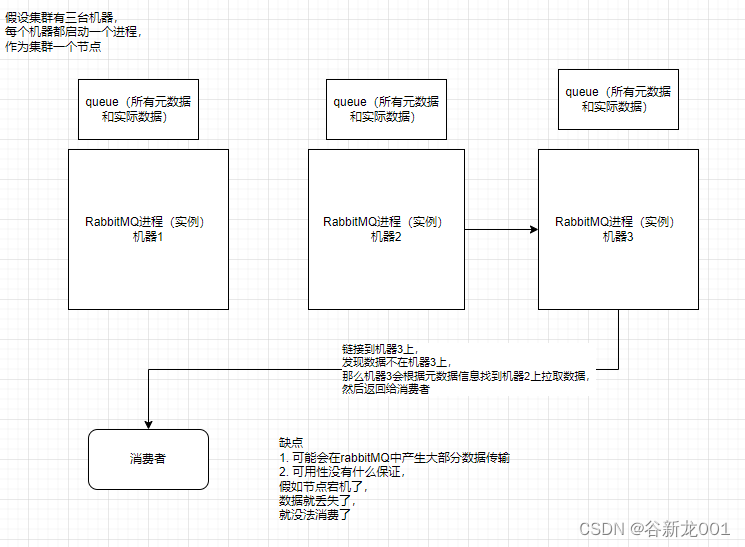
RabbitMQ的高可用
有三种部署模式
- 单机模式 (简单demo)
- 普通集群模式 (不能保证高可用,机器挂了数据就访问不了,但是整个集群的容量是可以超过单个机器的大小)
- 镜像集群模式(所有机器完全相同,但是不能超过单机容量限制)
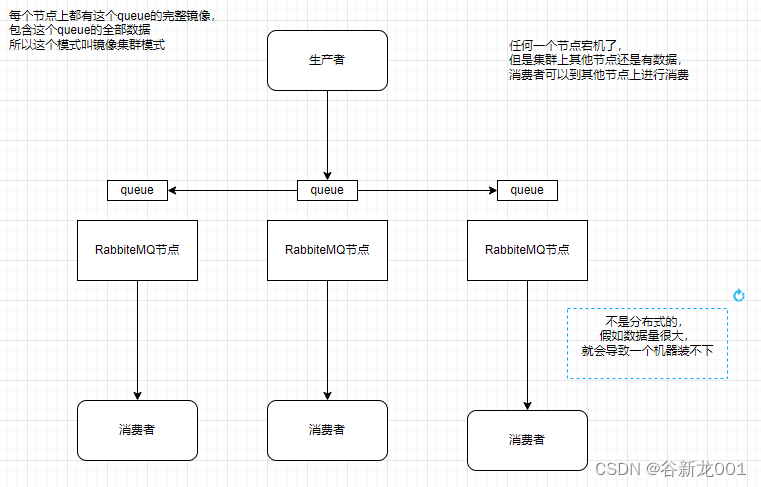
kafka高可用
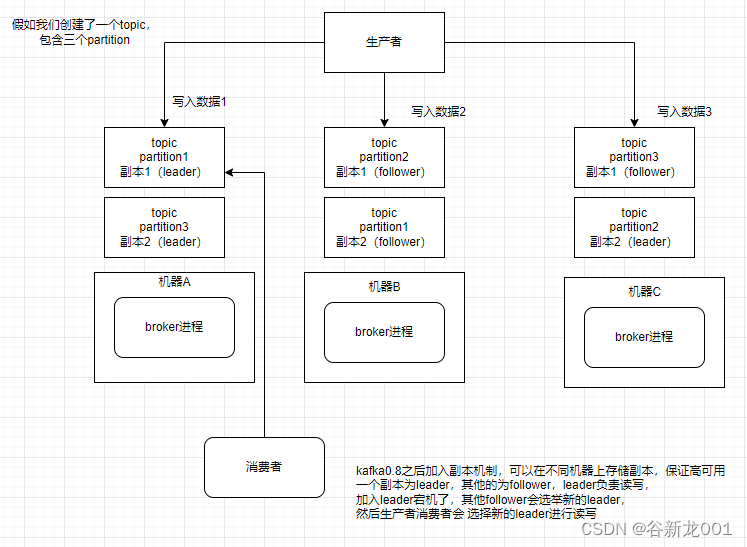
一个topic可以有多个partition,这样就可以把一个topic数据分散到多个机器上(摆脱单机限制),每个partition有leader和follower,这样如果leader挂了,follower可以升级成leader
问题3 在消息队列里消费到了重复的数据怎么办
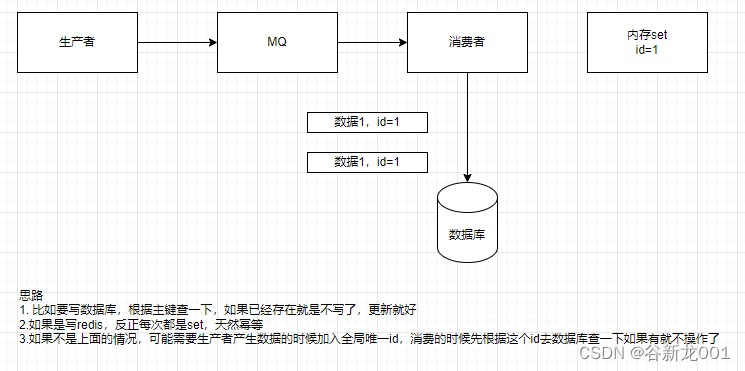
问题:怎么保证消息不被重复消费?或者说怎么保证消息消费时的幂等性
消息队列只保证消息不丢,并不保证消息不会重发,所以需要应用保证幂等
问题:
如何保证系统幂等性
问题4 如何保证消息的可靠性
怎么保障消息不丢
RabbiteMQ可能存在消息丢失的问题
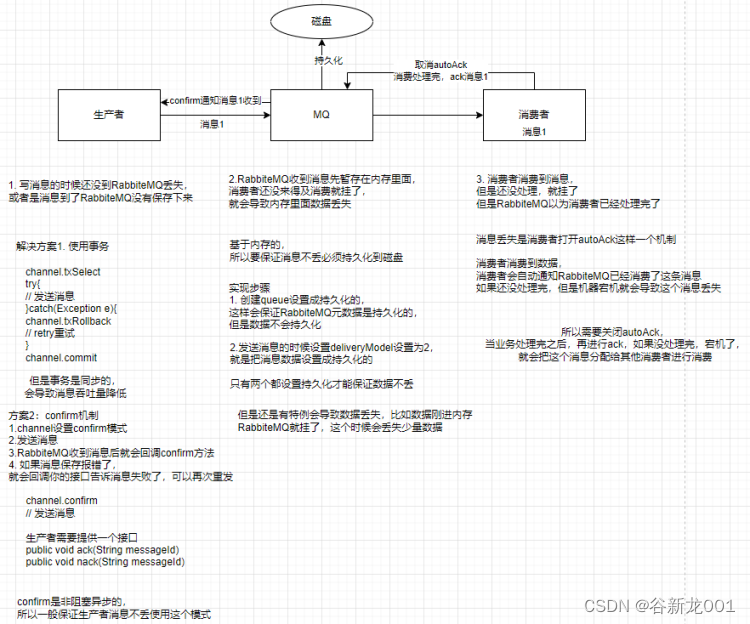
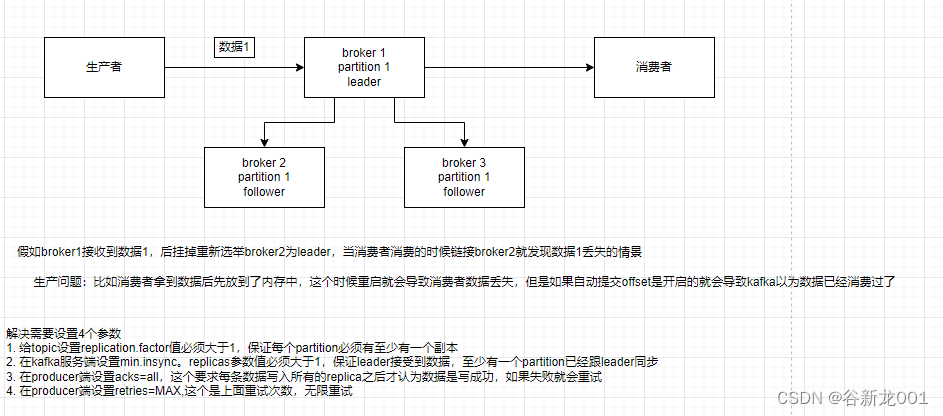
kafka可能消息丢失的问题
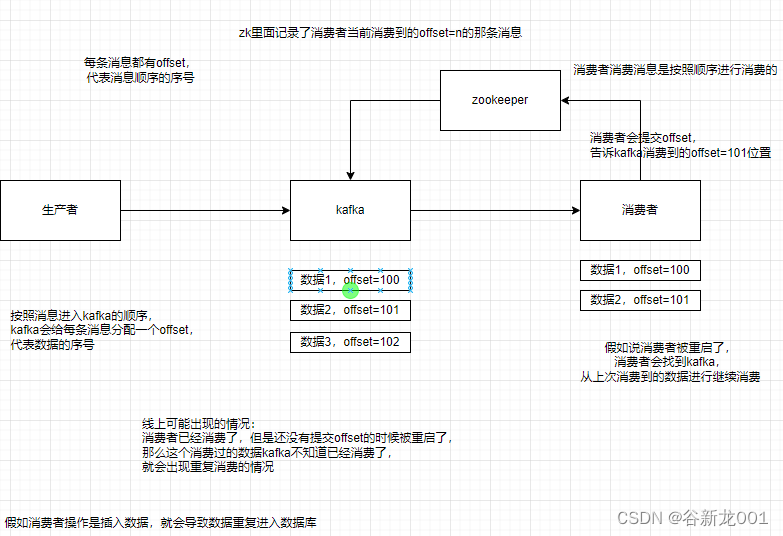
整体上一样的,kafka是自动提交offset,当消费者处理完再提交offset
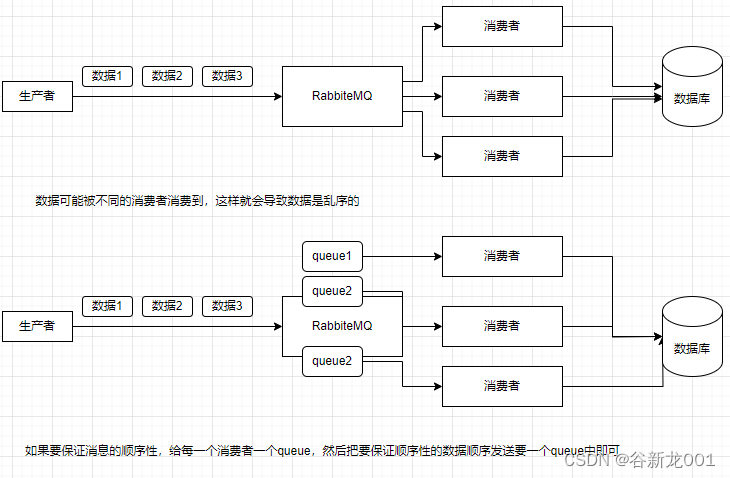
问题5 怎么保证从消息队列里拿到的数据按顺序执行
RabbiteMQ保证消息顺序性
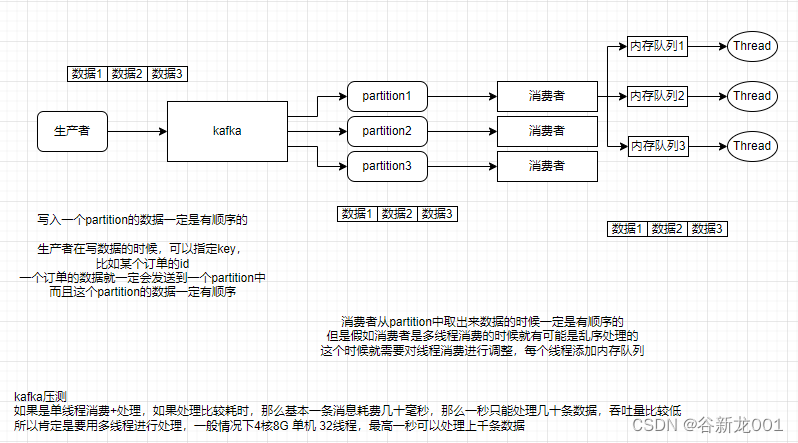
kafka保证消息顺序性
kafka只能保证partition内部数据的顺序性,不会处理多个partition,所以如果是业务的一些操作的话可以指定partition,或者通过key计算hash,保证一个业务的数据会到一个partition
问题6 几百万消息在消息队列里积压怎么办
面试:如何处理消息队列延时及过期失效的问题?消息队列满了怎么处理?有几百万消息积压几个小时应该怎么办?
分析:可能是消费端出现问题不消费了或者是消费变慢了,以及可能消息队列中数据快把磁盘堆满了都没人消费,并且在RabbiteMQ中有TTL设置,过期的数据可能就丢失了,常见的例子比如消费端需要把数据写入到数据库,结果mysql挂了,消费就hang住了
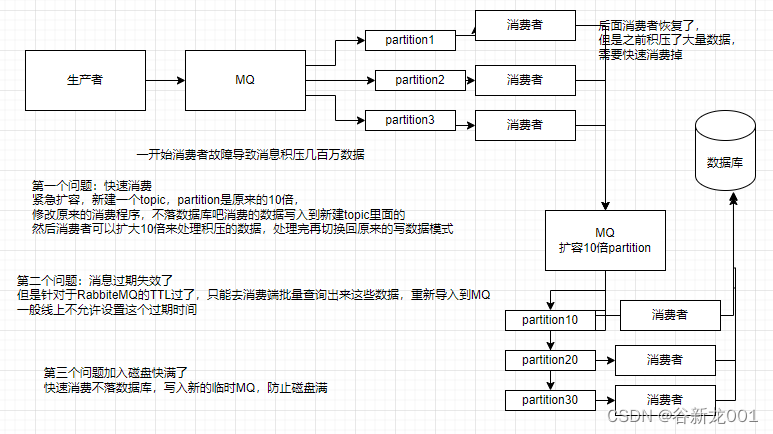
问题7 让你来开发一个消息队列中间件,你会怎么设计架构
主要考察,对于消息队列有没有研究,能不能整体上把握住,给出一些关键点
(1)首先这个 mq得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加香吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic->partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
(2)其次你得考虑一下这个 mg 的数据要不要落地磁盘吧?那肯定要了,落磁盘,才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
(3)其次你考虑一下你的 mq的可用性啊?这个事儿,具体参考我们之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 ->leader & follower ->broker 挂了重新选举 leader即可对外服务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 中东电商平台Noon入驻攻略来了!用Ads浏览器打开中东电商新大陆!
- 深陷制裁风波后,禾赛科技激光雷达再创新纪录 | 百能云芯
- 使用metricbeat 监控多ES集群
- leetcode链表小练(1.反转链表2.链表的中间节点3.合并两个有序链表4.环形链表①5.环形链表②)详解 (??? ? ??)?????? ?
- vue-office 支持多种文件(docx、excel、pdf)预览的vue组件库
- transdata笔记:手机数据处理
- 品牌如何用“仪式感”吸引消费者?媒介盒子告诉你
- 解决 GSYVideoPlayer 连续切换视频 出现黑屏只有声音没有画面的问题
- 解密IP代理池:匿名访问与反爬虫的利器
- 2023年第十四届蓝桥杯软件赛省赛总评