计算机视觉任务汇总(超全)
目录
(5)细粒度图像分类(fine-grained image classification)
(4) 零样本目标检测(Zero Shot Detection,ZSD),通用目标检测器
(2) 实例分割(instance segmentation)
(2) 视频目标检测 Video Object Detection
(3)?视频分类(Video Classification)?编辑
6、网络可视化(visualizing)和网络理解(understanding)/视觉注意力和显著性
7.2 人脸验证/识别(face verification/recognition)
8.1 纹理生成(texture synthesis)和风格迁移(style transform)
8.3 图像描述(image captioning)(视频描述)
8.4 视觉问答(visual question answering)
9、OCR,Optical Character Recognition,中文是:光学字符识别。
本文是本人花费大量时间和精力的总结。
主要介绍一些任务概念的区分和大致的发展历程、常见任务、应用场景。
计算机视觉(Computer Vision,CV)是一门研究如何使机器“看”的学科,换句话说,就是用计算机实现人的视觉功能——对客观世界的三维场景的感知、识别和理解!!!
机器视觉通常涉及对图像或视频的评估,英国机器视觉协会(BMVA)将机器视觉定义为“对单张图像或一系列图像的有用信息进行自动提取、分析和理解”。计算机视觉任务用一句话概括就是:Visual problem solving:“What is where?“.是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等。
计算机视觉涵盖的内容丰富,需要完成的任务也非常多,但其中最基本的任务包含四项:分类、定位、检测和分割;可以说其他关键任务都是在四项基本任务的基础上延伸开来的。
四大基本任务
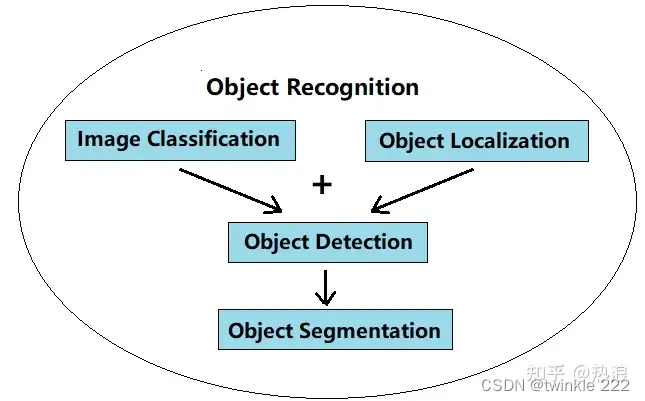
图来源:计算机视觉中的object detection 与object recognition有什么区别吗? - 知乎 (zhihu.com)
1、分类(解决"what")

分类(Classification):解决“是什么?”的问题,即给定一张图或一段视频,判断里面包含什么类别的目标。
在图像分类任务中,最流行的网络架构是卷积神经网络(CNN),但Transformer很可能会作为一个例外,本来在NLP领域的常用网络结构,却在近几年被广泛应用到CV领域,并且表现SOTA,大杀四方,颇有取代CNN之势。在这里先不过多介绍,在之后文章中会详细介绍Transformer的精彩战绩!
CNN网络结构基本是由卷积层、池化层以及全连接层组成。通过卷积层进行特征提取,之后通过池化层过滤细节(一般采用最大池化、平均池化),最后在全连接层进行特征展开,再送入到相应的分类器得到最终的分类结果。
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过CNN构建的深度学习网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引了众多研究者的注意。在其之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩。同时,也是在2012这一年,以AlexNet为分界线,在之前为传统算法,之后则为深度学习算法。
给定一张输入图像,图像分类任务旨在判断该图像所属类别。一张图像中是否包含某种物体,对图像进行特征描述是物体分类的主要研究内容
(1) 图像分类常用数据集
以下是几种常用分类数据集,难度依次递增。rodrigob.github.io/are_列举了各算法在各数据集上的性能排名。
MNIST 60k
50k训练图像、10k测试图像、10个类别、图像大小1×28×28、内容是0-9手写数字。
CIFAR-10
50k训练图像、10k测试图像、10个类别、图像大小3×32×32。
CIFAR-100
50k训练图像、10k测试图像、100个类别、图像大小3×32×32。
ImageNet
李飞飞,1.2M训练图像、50k验证图像、1k个类别。2017年及之前,每年会举行基于ImageNet数据集的ILSVRC竞赛,这相当于计算机视觉界奥林匹克。
(2) 图像分类经典网络结构(分类模型的解读)
总结图像分类任务经典的网络结构如下:
· LeNet-5:60k参数。一般作为广大计算机视觉从业者的Hello world入门级网络结构。当时,被成功用于ATM以对支票中的手写数字进行识别。
· AlexNet:60M参数,ILSVRC2012年的ox冠军网络。
· VGG-16/VGG-19:138M参数,ILSVRC2014的亚军网络。由于VGG-16网络结构十分简单,并且很适合迁移学习,因此VGG-16至今仍在各大关键任务中被广泛使用。
· GoogLeNet:5M参数,ILSVRC2014的冠军网络。
· Inception-v3/v4:在GoogLeNet的基础上进一步降低参数。
· ResNet:ILSVRC2015年的冠军网络。ResNet旨在解决网络加深后训练难度增大的现象。
· preResNet:基于ResNet的改进。
· ResNeXt:基于ResNet的另一种改进。
· DenseNet:其目的也是避免梯度消失。与残差(residual)模块不同,dense模块中任意两层之间均有短路连接。
· SENet:ILSVRC2017的冠军网络。
......
(3)?模型设计领域热点回顾
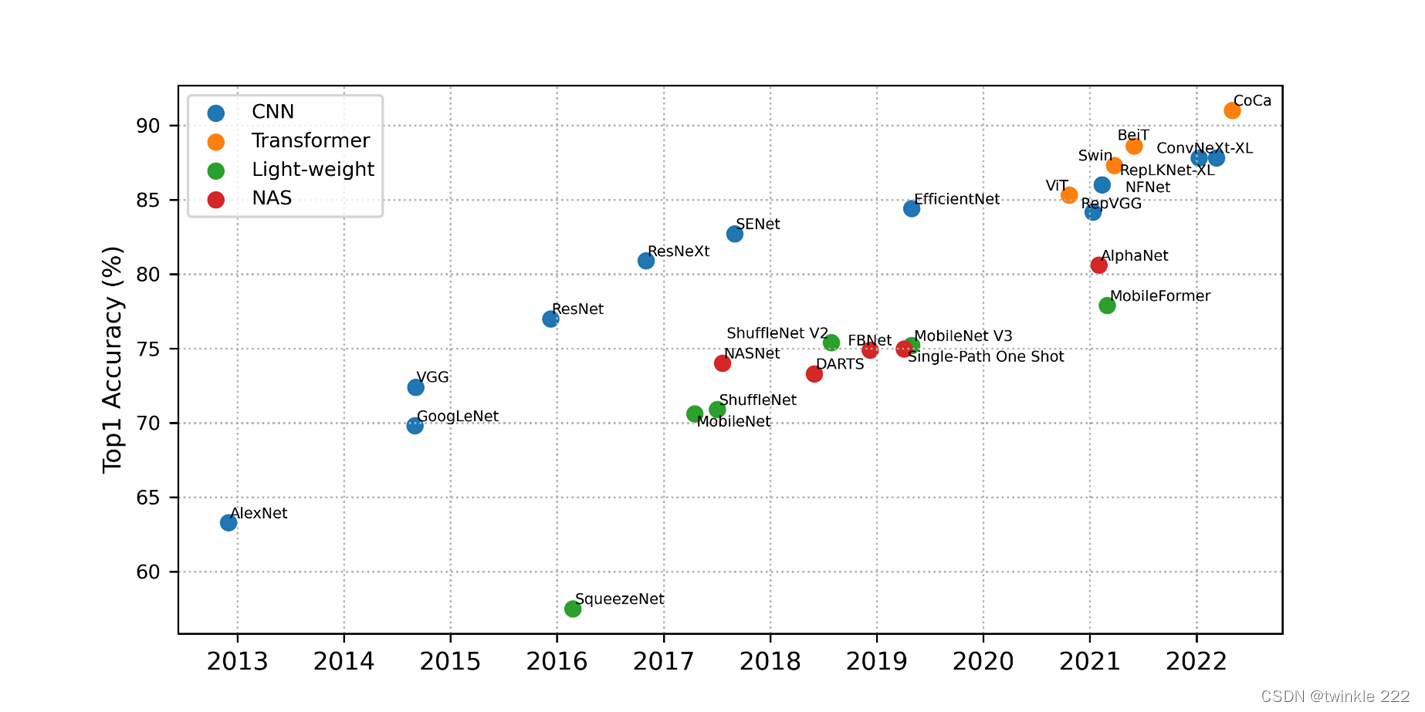
(旷视科技-张祥雨)
o层数更深、性能更强的架构
o轻量级架构、高推理效率
o自动化模型设计、神经网络架构搜索(NAS)
o动态模型
oVision Transformers (ViTs)
o大模型、多模态模型
(4) 模型上下游任务
简单来说,上游任务是训练一个用于特征提取的预训练模型,比如这几年很火的CLIP[1],GPT[2],下游任务是具体部署。
下游上游的取名就在于下游任务往往是先用上游任务得到的模型(一般会称为backbone,主干网络)提取图像特征,然后再从这些特征中得到我们想要的结果。
上游任务:
预训练模型。一般就是利用上游数据进行预训练,以生成一个包含视觉表征能力的模型。
比如,我们想要的是一个能够提取图片特征能力的卷积神经网络或者Transformer,我们会用大量图片用图片分类这个下游任务或者其他比如自监督的方法(可以参考CLIP)去进行训练,得到一个权重合适的模型(能够很好地提取出图像的特征),那么最后我们把得到的这个模型最后一层的FC层(原本用于图片分类输出类别)去掉,这个模型就成为了一个很好的预训练模型,输入一张图,就能够提取出图像的特征,就可以用于我们的下游任务(在这个模型后面加一些诸如检测头之类的模块,处理我们想要的下游任务,或者修改下FC层,用于另外一堆类别的图像分类)。
下游任务:
下游任务是计算机视觉应用程序,用于评估通过自监督学习学习到的特征的质量。当训练数据稀缺时,这些应用程序可以极大地受益于预训练模型。
下游任务更多的是评估任务,相当于项目落地,需要去做具体任务来评价模型好坏。
如图像分类,目标检测、语义分割等具体任务。
(5)细粒度图像分类(fine-grained image classification)
相比(通用)图像分类,细粒度图像分类需要判断的图像类别更加精细。比如,我们需要判断该目标具体是哪一种鸟、哪一款的车、或哪一个型号的飞机。通常,这些子类之间的差异十分微小。比如,波音737-300和波音737-400的外观可见的区别只是窗户的个数不同。因此,细粒度图像分类是比(通用)图像分类更具有挑战性的任务。
细粒度图像分类的经典做法是先定位出目标的不同部位,例如鸟的头、脚、翅膀等,之后分别对这些部位提取特征,最后融合这些特征进行分类。这类方法的准确率较高,但这需要对数据集人工标注部位信息。目前细粒度分类的一大研究趋势是不借助额外监督信息,只利用图像标记进行学习,其以基于双线性CNN的方法为代表。
2、定位(解决"where")
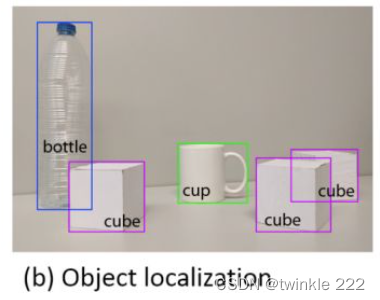
在图像分类的基础上,我们还想知道图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。
基本思路?多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
人体位姿定位/人脸定位?目标定位的思路也可以用于人体位姿定位或人脸定位。这两者都需要我们对一系列的人体关节或人脸关键点进行回归。
弱监督定位?由于目标定位是相对比较简单的任务,近期的研究热点是在只有标记信息的条件下进行目标定位。其基本思路是从卷积结果中找到一些较高响应的显著性区域,认为这个区域对应图像中的目标。
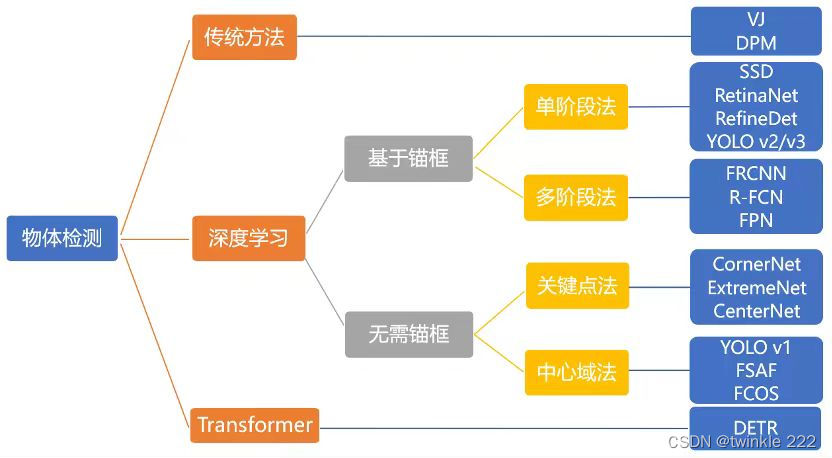
3、检测(解决"what"和"where")
在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。因此,目标检测是比目标定位更具挑战性的任务,通常是特定物体目标检测
在计算机视觉众多的技术领域中,目标检测是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于目标检测。目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,要同时确定物体的类别和位置。由于深度学习的广泛运用,目标检测算法得到了较为快速的发展,本报告主要介绍基于深度学习的两种目标检测算法思路,分别为One-Stage目标检测算法和Two-Stage目标检测算法。
有挑战的难题:外观、形状、姿态、光照、所占图形比例的大小、多尺度、拥挤物体检测(自/被遮挡)

(1) 目标检测常用数据集
PASCAL VOC?包含20个类别。通常是用VOC07和VOC12的trainval并集作为训练,用VOC07的测试集作为测试。
MS COCO?COCO比VOC更困难。COCO包含80k训练图像、40k验证图像、和20k没有公开标记的测试图像(test-dev),80个类别,平均每张图7.2个目标。通常是用80k训练和35k验证图像的并集作为训练,其余5k图像作为验证,20k测试图像用于线上测试。
(2) 基于候选区域的目标检测算法
基本思路?使用不同大小的窗口在图像上滑动,在每个区域,对窗口内的区域进行目标定位。即,将每个窗口内的区域前馈网络,其分类分支用于判断该区域的类别,回归分支用于输出包围盒。基于滑动窗的目标检测动机是,尽管原图中可能包含多个目标,但滑动窗对应的图像局部区域内通常只会有一个目标(或没有)。因此,我们可以沿用目标定位的思路对窗口内区域逐个进行处理。但是,由于该方法要把图像所有区域都滑动一遍,而且滑动窗大小不一,这会带来很大的计算开销。
(3) 基于直接回归的目标检测算法
基本思路?基于候选区域的方法由于有两步操作,虽然检测性能比较好,但速度上离实时仍有一些差距。基于直接回归的方法不需要候选区域,直接输出分类/回归结果。这类方法由于图像只需前馈网络一次,速度通常更快,可以达到实时。
DETR系列 | 端到端Transformer目标检测算法汇总!
(4) 零样本目标检测(Zero Shot Detection,ZSD),通用目标检测器
检测一切
4、分割(实例分割、语义分割等像素级别的处理)
数据集怎么标注?
语义分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。
(1) 语义分割
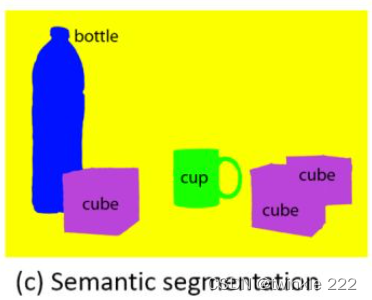
(1) 语义分割常用数据集
PASCAL VOC 2012?1.5k训练图像,1.5k验证图像,20个类别(包含背景)。
MS COCO?COCO比VOC更困难。有83k训练图像,41k验证图像,80k测试图像,80个类别。
(2) 语义分割基本思路
基本思路?逐像素进行图像分类。我们将整张图像输入网络,使输出的空间大小和输入一致,通道数等于类别数,分别代表了各空间位置属于各类别的概率,即可以逐像素地进行分类。
(2) 实例分割(instance segmentation)
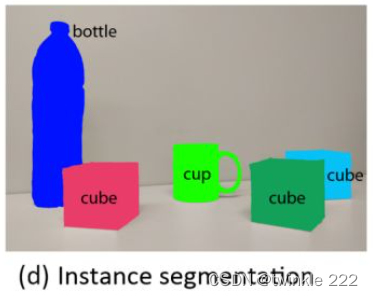
语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫。
基本思路?目标检测+语义分割。先用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同包围盒内进行逐像素标记。
(3) 大模型
SAM跟以往研究的不同点:
-
可以迁移到不同的分布、不同的任务,不再是针对特定物体的分割模型,而是针对所有,都能分割;
-
通过提示实现
-
SAM 已经学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』即开即用,无需额外的训练
其他任务
5、视频相关任务
(1) 目标追踪 Object tracking
如果视频帧中有多个目标,如何知道一帧中的目标和上一帧是同一个对象?这就是目标跟踪的工作,应用检测来识别特定目标随时间的变化,实现目标跟踪。
”相当于先检测,后用bytetrack对每一帧进行特征提取然后匹配不同帧的同一目标“
【多目标跟踪-YOLOv8-Qt-智能交通路况监控系统】多目标跟踪-YOLOv8-Qt-智能交通路况监控系统_哔哩哔哩_bilibili评论区
大模型参数很多,很吃显存,一般的显卡的话建议用n和s这种,大模型一般是拿来用在云服务器上推理然后把推理结果传到各个使用端。如果要加快模型的边缘推理速度,建议tensorrt框架把模型转换为trt或者engine文件,用c++进行多端边缘部署,tensorrt加速后的模型在英伟达jetson agx orin上能有100-200的fps
模型的偏见来自数据的偏见,数据集得找好,可以在roboflow上找数据集,其次就是数据的量,用旋转,加噪声等数据增强技术扩充原有数据集,然后就是炼丹调参得调好,关注map和loss变化趋势,试试多early stop然后反复调整超参数或者换优化函数
目标跟踪旨在跟踪一段视频中的目标的运动情况。通常,视频第一帧中目标的位置会以包围盒的形式给出,我们需要预测其他帧中该目标的包围盒。目标跟踪类似于目标检测,但目标跟踪的难点在于事先不知道要跟踪的目标具体是什么,因此无法事先收集足够的训练数据以训练一个专门的检测器。
目标跟踪是指在给定场景中跟踪感兴趣的具体对象或多个对象的过程。简单来说,给出目标在跟踪视频第一帧中的初始状态(如位置、尺寸),自动估计目标物体在后续帧中的状态。
使用SAE方法进行目标跟踪的最经典深层网络是Deep Learning Tracker(DLT),提出了离线预训练和在线微调。
基于CNN完成目标跟踪的典型算法是FCNT和MD Net。
track anything
(2) 视频目标检测 Video Object Detection
-
视频目标检测作为在无人驾驶、视频监控和物联网等领域中一项重要的任务,与静态图像的目标检测相比更具挑战性和实用性。
-
弊端:与静态图像目标检测不同的是,目标在视频中是动态变化的,即其自身属性诸如外观、形状、尺寸会动态地改变,检测过程中视频序列需要在时间和空间维度保持一致以防检测目标丢失成为了视频目标检测任务的研究难点。
-
好处:由于视频比二维图像多了时间维度,有很多算法通过利用时间维度的信息来提升检测性能。
(3)?视频分类(Video Classification)
怎么做数据标注的?
视频分类指将一段视频分类到预先制定类别集合中的某一个或多个。视频由空间维度和时间维度组成。包括静态图像特征,运动特征,音频特征,外部特征等。目前主要的方法有:双流网络,静态图像特征聚合,3D卷积以及基于transformer的视频分类。前三种方法前人已经做了很全面的总结不再赘述。
前面介绍的大部分任务也可以用于视频数据,这里仅以视频分类任务为例,简要介绍处理视频数据的基本方法。
多帧图像特征汇合?这类方法将视频看成一系列帧的图像组合。网络同时接收属于一个视频片段的若干帧图像(例如15帧),并分别提取其深度特征,之后融合这些图像特征得到该视频片段的特征,最后进行分类。实验发现,使用"slow fusion"效果最好。此外,独立使用单帧图像进行分类即可得到很有竞争力的结果,这说明单帧图像已经包含很多的信息。
三维卷积?将经典的二维卷积扩展到三维卷积,使之在时间维度也局部连接。例如,可以将VGG的3×3卷积扩展为3×3×3卷积,2×2汇合扩展为2×2×2汇合。
图像+时序两分支结构?这类方法用两个独立的网络分别捕获视频中的图像信息和随时间运动信息。其中,图像信息从单帧静止图像中得到,是经典的图像分类问题。运动信息则通过光流(optical flow)得到,其捕获了目标在相邻帧之间的运动情况。
CNN+RNN捕获远距离依赖?之前的方法只能捕获几帧图像之间的依赖关系,这类方法旨在用CNN提取单帧图像特征,之后用RNN捕获帧之间的依赖。
此外,有研究工作试图将CNN和RNN合二为一,使每个卷积层都能捕获远距离依赖。
6、网络可视化(visualizing)和网络理解(understanding)/视觉注意力和显著性
这些方法旨在提供一些可视化的手段以理解深度卷积神经网络。
降维可视化
-
例如PCA、t-SNE、UMAP等
对图像的fc7或pool5特征进行低维嵌入,比如降维到2维使得可以在二维平面画出。具有相近语义信息的图像应该在t-SNE结果中距离相近。和PCA不同的是,t-SNE是一种非线性降维方法,保留了局部之间的距离。下图是直接对MNIST原始图像进行t-SNE的结果。可以看出,MNIST是比较容易的数据集,属于不同类别的图像聚类十分明显。
Seliency map(显著图)
对给定输入图像,计算某一特定神经元对输入图像的偏导数。其表达了输入图像不同像素对该神经元响应的影响,即输入图像的不同像素的变化会带来怎样的神经元响应值的变化。Guided backprop只反向传播正的梯度值,即只关注对神经元正向的影响,这会产生比标准反向传播更好的可视化效果。
Class Activation Map
7、人体识别/度量学习
度量学习也称作距离度量学习、相似度学习,通过学习对象之间的距离,度量学习能够用于分析对象时间的关联、比较关系,在实际问题中应用较为广泛,可应用于辅助分类、聚类问题,也广泛用于图像检索、人脸识别等领域。
以往,针对不同的任务,需要选择合适的特征并手动构建距离函数,而度量学习可根据不同的任务来自主学习出针对特定任务的度量距离函数。度量学习和深度学习的结合,在人脸识别/验证、行人再识别(human Re-ID)、图像检索等领域均取得较好的性能,在这个任务中我们主要介绍基于Fluid的深度度量学习模型,包含了三元组、四元组等损失函数。
7.1 图像检索(image retrieval)
给定一个包含特定实例(例如特定目标、场景、建筑等)的查询图像,图像检索旨在从数据库图像中找到包含相同实例的图像。但由于不同图像的拍摄视角、光照、或遮挡情况不同,如何设计出能应对这些类内差异的有效且高效的图像检索算法仍是一项研究难题。
图像检索的典型流程?首先,设法从图像中提取一个合适的图像的表示向量。其次,对这些表示向量用欧式距离或余弦距离进行最近邻搜索以找到相似的图像。最后,可以使用一些后处理技术对检索结果进行微调。可以看出,决定一个图像检索算法性能的关键在于提取的图像表示的好坏。
7.2 人脸验证/识别(face verification/recognition)
人脸验证/识别可以认为是一种更加精细的细粒度图像识别任务。人脸验证是给定两张图像、判断其是否属于同一个人,而人脸识别是回答图像中的人是谁。
一个人脸验证/识别系统通常包括三大步:检测图像中的人脸,特征点定位、及对人脸进行验证/识别。人脸验证/识别的难题在于需要进行小样本学习。通常情况下,数据集中每人只有对应的一张图像,这称为一次学习(one-shot learning)。
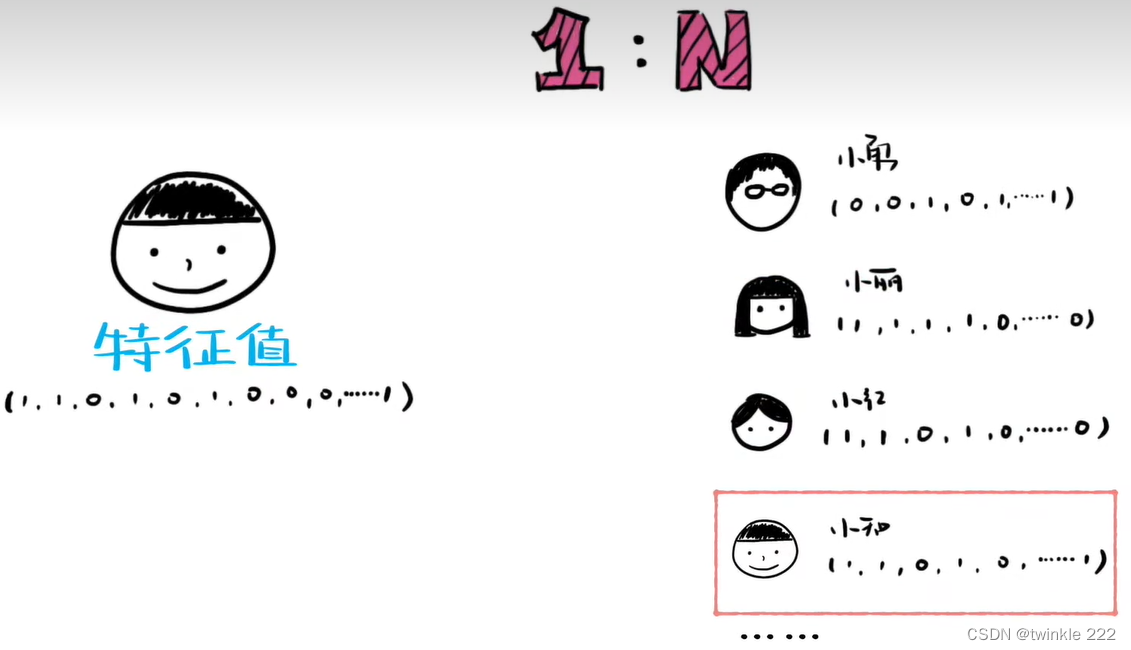
两种基本思路?当作分类问题(需要面对非常多的类别数),或者当作度量学习问题。如果两张图像属于同一个人,我们希望它们的深度特征比较接近,否则,我们希望它们不接近。之后,根据深度特征之间的距离进行验证(对特征距离设定阈值以判断是否是同一个人),或识别(k近邻分类)。
7.3 行为识别
【行为识别简介】行为识别简介_哔哩哔哩_bilibili
行为识别的任务是指在给定的视频帧内动作的分类,以及最近才出现的,用算法预测在动作发生之前几帧的可能的相互作用的结果。
7.4 人体姿势估计
人体姿势估计试图找出人体部位的方向和构型。 2D人体姿势估计或关键点检测一般是指定人体的身体部位,例如寻找膝盖,眼睛,脚等的二维位置。
7.5 行人重识别
行人重识别(Person Re-identification也称行人再识别,简称为ReID,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术;或者说,行人重识别是指在已有的可能来源与非重叠摄像机视域的视频序列中识别出目标行人。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。在监控视频中,由于相机分辨率和拍摄角度的缘故,通常无法得到质量非常高的人脸图片。当人脸识别失效的情况下,ReID就成为了一个非常重要的替代品技术。ReID有一个非常重要的特性就是跨摄像头,所以学术论文里评价性能的时候,是要检索出不同摄像头下的相同行人图片。
7.6 人体关键点检测
人体关键点检测,通过人体关键节点的组合和追踪来识别人的运动和行为,对于描述人体姿态,预测人体行为至关重要,是诸多计算机视觉任务的基础,例如动作分类,异常行为检测,以及自动驾驶等等,也为游戏、视频等提供新的交互方式。
8、生成式模型(generative models)
这类模型旨在学得数据(图像)的分布,或从该分布中采样得到新的图像。生成式模型可以用于超分辨率重建、图像着色、图像转换、从文字生成图像、学习图像潜在表示、半监督学习等。此外,生成式模型可以和强化学习结合,用于仿真和逆强化学习。
8.1 纹理生成(texture synthesis)和风格迁移(style transform)
给定一小张包含特定纹理的图像,纹理合成旨在生成更大的包含相同纹理的图像。
给定一张普通图像和一张包含特定绘画风格的图像,风格迁移旨在保留原图内容的同时,将给定风格迁移到该图中。
8.2 图像生成
GAN
Stable Fusion
8.3 图像描述(image captioning)(视频描述)
“看图说话”旨在对一张图像产生对其内容一两句话的文字描述。这是视觉和自然语言处理两个领域的交叉任务。
8.4 视觉问答(visual question answering)
给定一张图像和一个关于该图像内容的文字问题,视觉问答旨在从若干候选文字回答中选出正确的答案。其本质是分类任务,也有工作是用RNN解码来生成文字回答。视觉问答也是视觉和自然语言处理两个领域的交叉任务。
基本思路?使用CNN从图像中提取图像特征,用RNN从文字问题中提取文本特征,之后设法融合视觉和文本特征,最后通过全连接层进行分类。该任务的关键是如何融合这两个模态的特征。直接的融合方案是将视觉和文本特征拼成一个向量、或者让视觉和文本特征向量逐元素相加或相乘。
9、OCR,Optical Character Recognition,中文是:光学字符识别。
一般来讲OCR主要分为两部分: 1. 文本检测, 即找出文本所在位置 2. 文本识别, 将文字区域进行识别
许多场景图像中包含着丰富的文本信息,对理解图像信息有着重要作用,能够极大地帮助人们认知和理解场景图像的内容。场景文字识别是在图像背景复杂、分辨率低下、字体多样、分布随意等情况下,将图像信息转化为文字序列的过程,可认为是一种特别的翻译过程:将图像输入翻译为自然语言输出。场景图像文字识别技术的发展也促进了一些新型应用的产生,如通过自动识别路牌中的文字帮助街景应用获取更加准确的地址信息等。
在场景文字识别任务中,我们介绍如何将基于CNN的图像特征提取和基于RNN的序列翻译技术结合,免除人工定义特征,避免字符分割,使用自动学习到的图像特征,完成字符识别。这里主要介绍CRNN-CTC模型和基于注意力机制的序列到序列模型。(计算机视觉学,计算机视觉八大任务全概述)
10、3D视觉
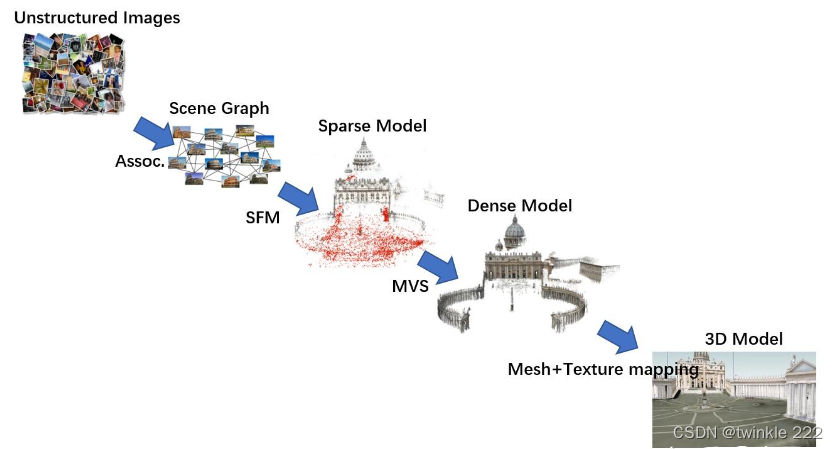
三维重建
较多应用于机器人、自动驾驶、增强现实、无人机
3D理解传统上面临着几个障碍。首先关注“自我和正常遮挡”问题以及适合给定2D表示的众多3D形状。由于无法将相同结构的不同图像映射到相同的3D空间以及处理这些表示的多模态,所以理解问题变得更加复杂。最后,实况3D数据集传统上相当昂贵且难以获得,当与表示3D结构的不同方法结合时,可能导致训练限制。
场景重构,多视点和单视点重建,运动结构(SfM),SLAM等。
-
三维重建技术通过深度数据获取、预处理、点云配准与融合、生成表面等过程,把真实场景刻画成适合计算机表示和处理的数学模型,是在计算机中建立表达客观世界的虚拟现实的关键技术。
-
三维重建技术的重点在于如何获取目标场景或物体的深度信息。
-
根据采集设备是否主动发射测量信号,分为两类:基于主动视觉理论和基于被动视觉的三维重建方法。
-
主动视觉三维重建方法:主要包括结构光法和激光扫描法;
-
被动视觉三维重建方法:被动视觉只使用摄像机采集三维场景得到其投影的二维图像,根据图像的纹理分布等信息恢复深度信息,进而实现三维重建。
-

点云数据
每个点逗含有三维坐标,乃至色彩、反射强度信息;
总结
图片->视频
2D->3D
CNN->Transformer(跨模态)
专门设计->“大”和“统一”
Reference:
(三)计算机视觉其他应用(网络压缩、视觉问答、可视化、风格迁移等)
策略算法工程师之路-图像场景语义分割(一)(有电商应用案例)
计算机视觉领域的六大任务简介(记录了很新的进展)
基于锚框与无需锚框的通用物体检测算法(深蓝AI)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- YOLOv8 Ultralytics:使用Ultralytics框架进行定向边界框对象检测
- 快乐学Python,使用Python为电视剧主演生成词云
- 解决不同请求需要的同一实体类参数不同(分组校验validation)
- 计算机网络-计算机网络的概念 功能 发展阶段 组成 分类
- Mysql创建新用户并赋予权限
- 【python】global
- docker-compose Install spug 3
- 6.1 指针的认识
- logstash
- HarmonyOS引导页登陆页以及tabbar的代码说明 home 界面说明4