乱码问题汇总
写在前面
在工作中经常会碰到各种莫名其妙的乱码问题,但通过之前的学习:字符集&字符编码-CSDN博客 ,可以知道乱码的根本原因就是使用和数据源编码不一样的编码解码导致。
如:BIG5解码GB2312编码内容,编解码不一致,必定会乱码。这时就需要进行字符编码的转换来使数据内容正常显示,之前的文章:字符编码转换-CSDN博客 里有详细介绍、实现了各种方式的字符编码转换的接口,可按实际情况找到相应的接口转换。
这里也记录下常见的乱码问题及解决方案供参考借鉴。
IDE(集成开发环境)软件显示乱码
IDE(集成开发环境)软件显示乱码,大多是因为文件编码格式和IDE打开文件使用的默认编码不一致,导致的显示乱码。
还原乱码
以VS为例,对于非UTF-8、UTF-16、UTF-32编码的文件,即ANSI编码的文件,VS会以系统本地默认(简体系统为GB2312,繁体系统为BIG5)编码打开文件,且不能更改-即不能指定使用何种编码打开文件。
现有一个GB2312编码的cpp文件:
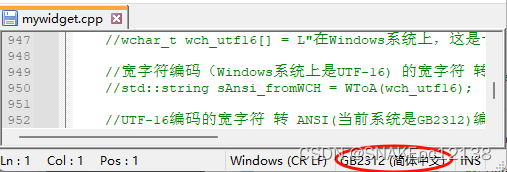
现在在简体系统上,VS2019会以GB2312编码打开(解码)该GB2312编码的cpp文件,能够正常显示:

vs右下角显示当前打开文件编码,需在扩展安装FileEncoding插件:

当在繁体系统上,再用vs打开时,vs会自动以BIG5编码打开GB2312编码的文件(编码、解码格式不一致),从而发生乱码:

该文件的编码还是GB2312,只是VS以系统本地编码(BIG5)打开而已。
用notepad++打开,可以看到源文件编码还是GB2312:

因为微软没有提供修改vs文本编辑器打开文件的编码格式,因此要解决这种情况的乱码,只能修改文件本身的编码以适配vs文本编辑器的编码。将文件编码转换成通用的UTF-8或Unicode(UTF-16)编码即可。
这里也有多种方式转换文件编码如下:
解决方案一:使用VS转换文件编码
借助VS文件菜单栏 -> 高级保存选项转换:

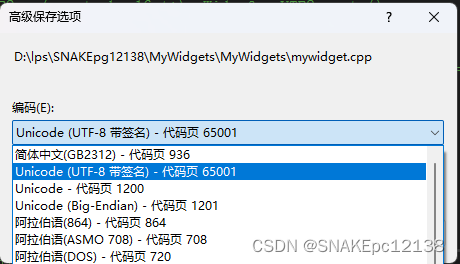

解决方案二:使用Notepad++转换文件编码
借助Notepad++进行转换:
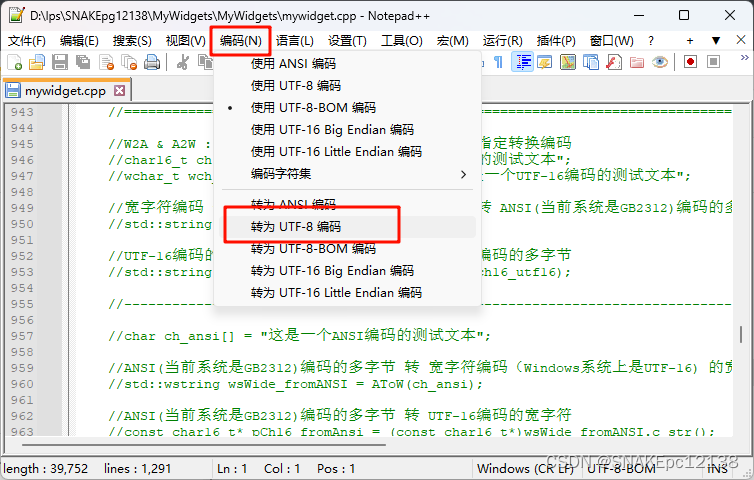
解决方案三:使用Windows记事本转换文件编码
使用Windows自带记事本转换:
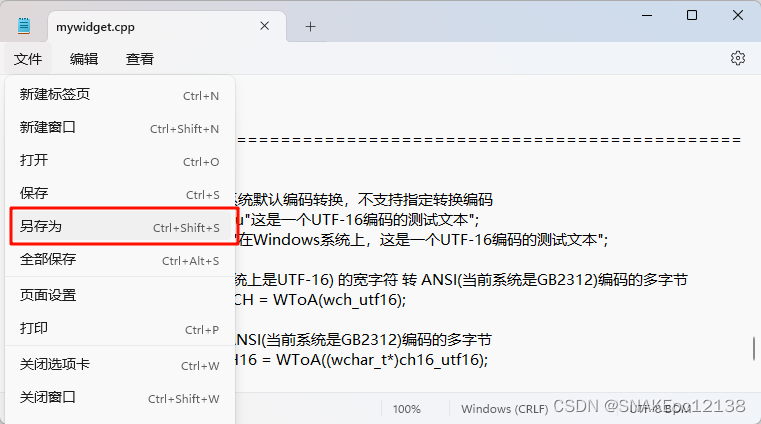

注意:使用Windows记事本转换时需确保当前是正确解码打开的,若当前解码(显示)已乱码,后面只会越转越乱。
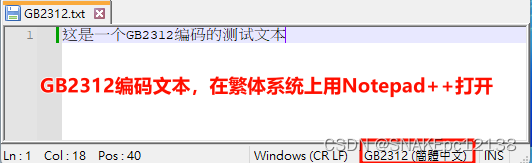
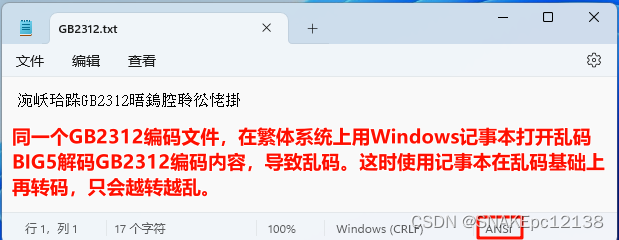
例:文件编码为GB2312,在繁体系统上(系统默认编码为BIG5)用记事本打开显示乱码(BIG5解码GB2312内容),这时再转只会越转越乱:
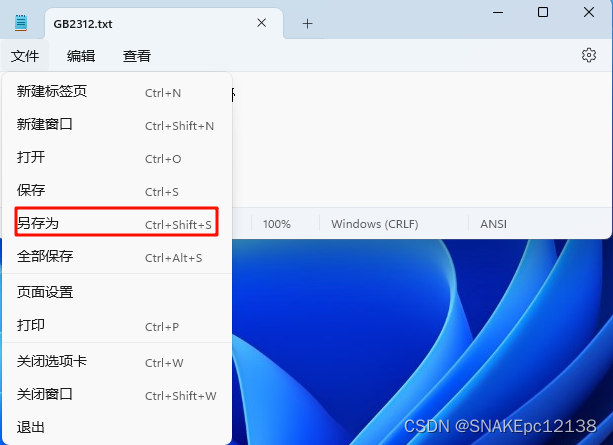
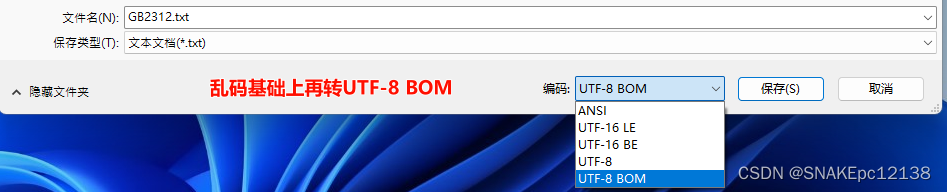
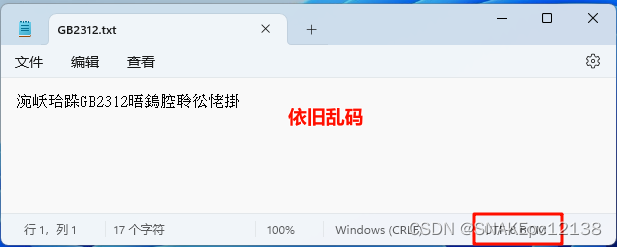
再用Notepad++打开,也无法再还原:
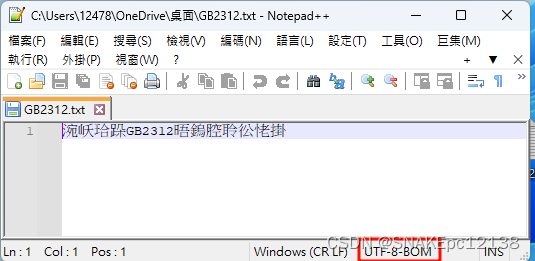


同样是打开文件乱码,为什么VS文本编辑器就可在乱码基础上转码成功并正常显示?
大概是记事本和VS在处理编码时有所不同造成的。VS有更强大的编码支持,可以识别并转换各种不同的字符编码格式,包括 GB2312 和 UTF-8。然而,记事本可能在处理一些非标准编码或特定类别的编码时会遇到更多的问题。记事本的编码支持可能不如专业的文本编辑器或IDE。
注意这是记事本和VS代码编辑器转码的很大的一个区别!所以尽量还是使用Notepad++这种万国码编辑器进行转码会更为安全。
程序运行后界面显示乱码
软件界面上显示的内容可能来自代码中的字符串常量、从文本获取的内容或者其他方式来源,然后再经由代码里的各种变量中转,最后显示在界面上,因此这里可能会有三种情况导致软件运行后界面显示乱码:
①数据获取时乱码
②数据传递时乱码
③数据显示时乱码
这里通过获取.ini文本,来展示以上三种情况。
测试文本:
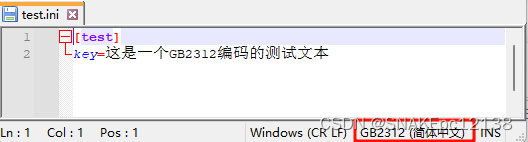
test.ini,内容如下:
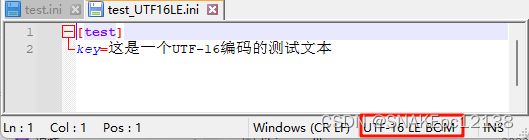
test_UTF16LE.ini,内容如下:
开发系统:Win11简体中文系统
运行系统:Win11繁体中文系统
数据获取时乱码
获取方式(Win API):GetPrivateProfileStringW
QLabel* label = new QLabel(this);
WCHAR wCH[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test.ini");
QString qsShow = QString::fromWCharArray(wCH);
label->setText(qsShow);
简体系统上可正常显示:
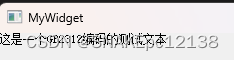
繁体系统上运行乱码:

乱码分析:
主要是因为GetPrivateProfileStringW会根据系统的默认语言设置(也就是你的操作系统的区域设置)去解码ini文件。
在简体中文系统上时,系统的默认编码就是GB2312,因此用GetPrivateProfileStringW去读取GB2312编码的文件时不会有问题,可以正常显示。
然而,当你在繁体中文系统上时,操作系统的默认编码是Big5,这时如果用GetPrivateProfileStringW去读取GB2312编码的文件,由于编码类型的差异,就会导致显示乱码。
当Windows API尝试用Big5去解码GB2312的内容时,由于两种编码之间的字符集不匹配,就产生了乱码。
即获取.ini文本数据时,就已经因为编解码不一致导致获取到的数据就已乱码,因此不管后面如何传递、显示,都是在乱码的基础上进行的,当然也都是乱码的。
那这里使用GetPrivateProfileStringA获取GB2312编码的内容呢?
char ch[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringA("test", "key", NULL, ch, MAX_PATH, "./test.ini");
QString qsShow = QString::fromLocal8Bit(ch);
label->setText(qsShow);
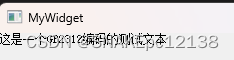
简体系统上可正常显示:
繁体系统上运行乱码:
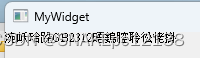
这里乱码的原因就不是:使用GetPrivateProfileStringA获取时乱码了,而是:
QString qsShow = QString::fromLocal8Bit(ch);
这句导致乱码。文本编码为GB2312,在简体系统上QString::fromLocal8Bit,来自本地系统编码GB2312,编码GB2312-解码GB2312,编解码一致,可正常显示。
但在繁体系统上,QString::fromLocal8Bit,来自本地系统编码BIG5,即编码GB2312-解码BIG5,编解码不一致导致乱码。
这应该属于情况③数据显示时乱码 了,在这里提到是想表达尽量使用通用的编码格式(UTF-8、UTF-16),而且也要尽量避免使用受本地系统默认编码的转换接口。
因此对于这种情况:数据获取时乱码,将文本编码转换成UTF-16,使用GetPrivateProfileStringW获取,会更通用一些:
WCHAR wCH[MAX_PATH];
//GetPrivateProfileStringW直接获取UTF-16编码内容,不受本地系统编码影响
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test_UTF16LE.ini");
//wCH存储的是UTF-16编码的内容,避免了使用QString::fromLocal8Bit
QString qsShow = QString::fromWCharArray(wCH);
label->setText(qsShow);
简体系统上可正常显示:
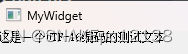
繁体系统上也可正常显示:

同理,使用GetPrivateProfileStringA获取UTF-16编码的test_UTF16LE.ini文本情况同上,可自行试验,这里不再赘述。
数据传递时乱码
上面情况①获取到的是WCHAR,对应的标准类型是std::wstring,大多数项目基本都很少使用这种类型,大都是使用std::string类型变量保存数据。
因此这里就会有std::wstring 到 std::string 的转换需求,这里转换时也会有乱码的风险。
本文中转换接口均来自:字符编码转换-CSDN博客
情况②乱码示例一:
WCHAR wCH[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test_UTF16LE.ini");
std::wstring wsSrc(wCH);
//转换成std::string保存、传递
//注意:这里使用CP_ACP将内容转成本地编码保存到std::string,
//在简体上可正常转换,在繁体上这里转换后的sDest就会乱码
std::string sDest = WideCharToMultiByteWithAcp(wsSrc.c_str(), CP_ACP);
//因为知道上面转成系统本地编码,因此这里使用QString::fromLocal8Bit
QString qsShow = QString::fromLocal8Bit(sDest.c_str());
label->setText(qsShow);
简体系统上可正常显示:
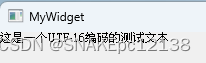
繁体系统上乱码:

通用的做法是,转成通用的字符编码UTF-8保存在代码变量中,后续传递的也是UTF-8编码的std::stirng
WCHAR wCH[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test_UTF16LE.ini");
std::wstring wsSrc(wCH);
try
{
//转换成std::string保存、传递
//这里转成UTF-8后保存到sDest, 65001是UTF-8的代码页标识
std::string sDest = WcsToMbs(wsSrc.c_str(), ".65001");
//避免了使用QString::fromLocal8Bit
QString qsShow = QString::fromUtf8(sDest.c_str());
label->setText(qsShow);
}
catch (...)
{
return;
}
简体系统上可正常显示:

繁体系统上也可正常显示:
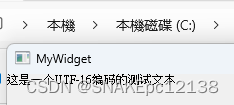
数据显示(解码)时乱码
数据显示(解码)时乱码,这种情况基本上就是不知道数据的原编码,然后使用了和原编码不一致的方式解码导致。
WCHAR wCH[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test_UTF16LE.ini");
std::wstring wsSrc(wCH);
try
{
//转换成std::string保存、传递
std::string sDest = WcsToMbs(wsSrc.c_str(), ".65001");
//原数据编码为UTF-8,却以为是原编码是本地系统编码,即使用QString::fromLocal8Bit
QString qsShow = QString::fromLocal8Bit(sDest.c_str());
label->setText(qsShow);
}
catch (...)
{
return;
}
简体系统上显示乱码:
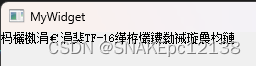
繁体系统上显示乱码:

正确的做法是,解码对应编码:
WCHAR wCH[MAX_PATH];
DWORD dwRet = ::GetPrivateProfileStringW(L"test", L"key", NULL, wCH, MAX_PATH, L"./test_UTF16LE.ini");
std::wstring wsSrc(wCH);
try
{
//转换成std::string保存、传递
std::string sDest = WcsToMbs(wsSrc.c_str(), ".65001");
//原数据编码为UTF-8,却以为是原编码是本地系统编码,即使用QString::fromLocal8Bit
QString qsShow = QString::fromUtf8(sDest.c_str());
label->setText(qsShow);
}
catch (...)
{
return;
}
简繁系统上都可正常显示:
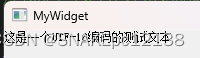
小结:
上面三种情况,要么是不清楚自己管理数据的源编码导致乱码,要么是不知要转换成何种字符编码时乱码。
不管哪种情况,只要知道数据的源编码,并正确使用相应的转码、解码方式,就一定不会有乱码问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 福建省大数据集团数据应用开发大赛全面升级
- 4-高可用-限流详情
- zabbix监控系统
- Golang 线程安全与 sync.Map
- HackTheBox - Medium - Windows - Aero
- Leetcode—19.删除链表的倒数第 N 个结点【中等】
- springboot/java/php/node/python《离散结构》题库系统【计算机毕设】
- JFinal学生信息管理系统
- C语言经典算法之快速排序算法
- 虾皮广告数据:优化广告投放,提升产品销量的关键指南