DALL-E 2: Hierarchical Text-Conditional Image Generation with CLIP Latents
发布时间:2023年12月25日
DALL-E 2
方法
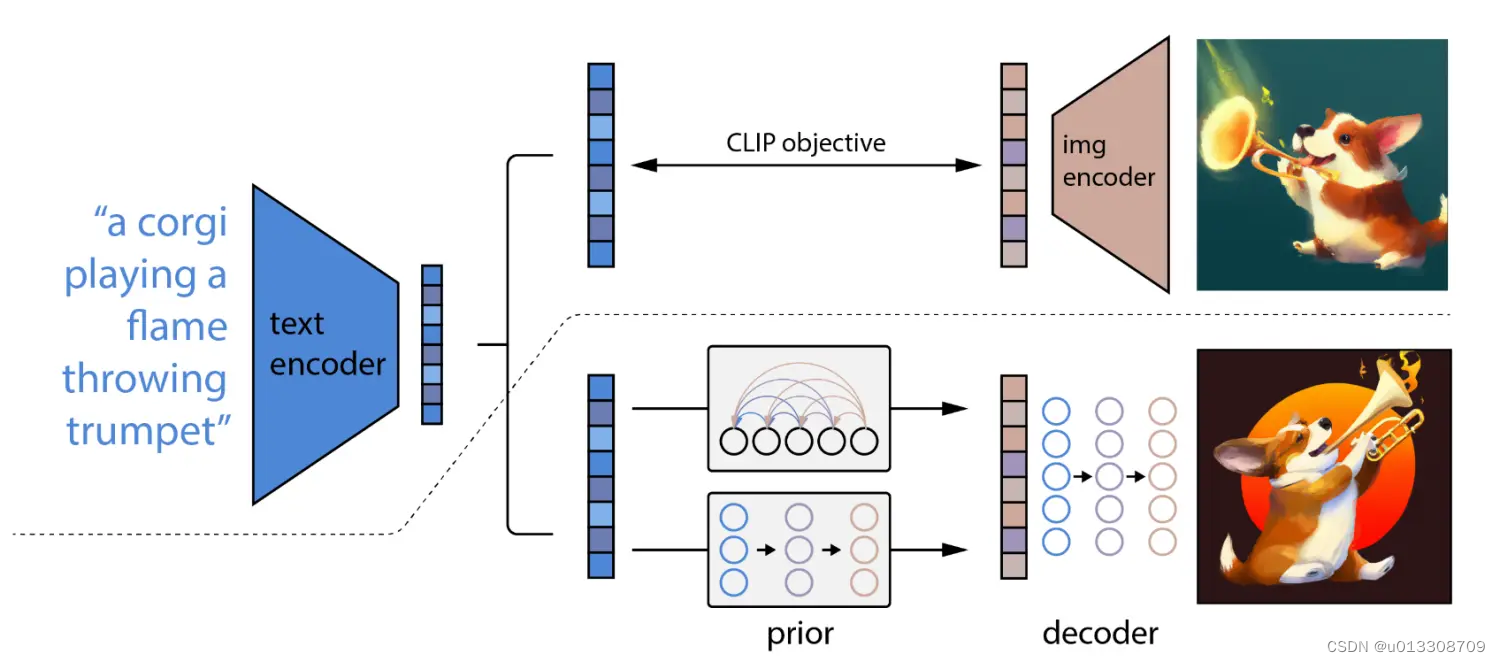
- 上图中,虚线的上半部分是CLIP的训练过程,虚线的下半部分描述的DALL-E 2的训练过程。
CLIP训练
- 在训练时,将文本以及对应的图像分别输入到CLIP的文本编码器和图像编码器,然后得到输出的文本特征和图像特征,这两个特征就是一个正样本,该文本特征与其他图像生成的图像特征就是负样本,通过对比学习,训练文本编码器和图像编码器,将图像和文本合并为一个多模态的特征空间。CLIP模型训练结束,文本编码器和图像编码器就的参数就被冻结。在DALL-E 2的训练过程中,CLIP模型的参数处于冻结状态,不进行
文章来源:https://blog.csdn.net/u013308709/article/details/135168063
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Multimodal Prototypical Networks for Few-shot Learning
- vue3 vue-route4跳转新页面无法获取params参数
- 九河云的AWS云服务器资源对智能零售的解决方案
- H264/AVC的句法和语义
- three.js 学习笔记(学习中1.7更新) |
- MES数据采集在制造业的应用
- Redis学习——入门篇②
- springboot写一个添加aop日志的自定义注解实例(入门)
- 【遥感数字图像处理(朱文泉)】第五章 辐射校正
- react中refs的作用是什么?有几种用法?