【机器学习】常见算法详解第1篇:K近邻 KNN和API使用(已分享,附代码)

本系列文章md笔记(已分享)主要讨论机器学习算法相关知识。机器学习算法文章笔记以算法、案例为驱动的学习,伴随浅显易懂的数学知识,让大家掌握机器学习常见算法原理,应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题。包括K-近邻算法,线性回归,逻辑回归,决策树算法,集成学习,聚类算法。K-近邻算法的距离公式,应用LinearRegression或SGDRegressor实现回归预测,应用LogisticRegression实现逻辑回归预测,应用DecisionTreeClassifier实现决策树分类,应用RandomForestClassifie实现随机森林算法,应用Kmeans实现聚类任务。
全套笔记和代码自取地址: https://gitee.com/yinuo112/Technology/tree/master/机器学习/机器学习(算法篇)/1.md
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
共 7 章,44 子模块,总字数:52595


机器学习算法本文定位、目标
定位
- 本文以算法、案例为驱动的学习,伴随浅显易懂的数学知识
- 作为人工智能领域的提升本文,掌握更深更有效的解决问题技能
目标
- 掌握机器学习常见算法原理
- 应用Scikit-learn实现机器学习算法的应用,
- 结合场景解决实际问题
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.1 K-近邻算法简介
1 什么是K-近邻算法
- 根据你的“邻居”来推断出你的类别
1.1 K-近邻算法(KNN)概念
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法
- 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
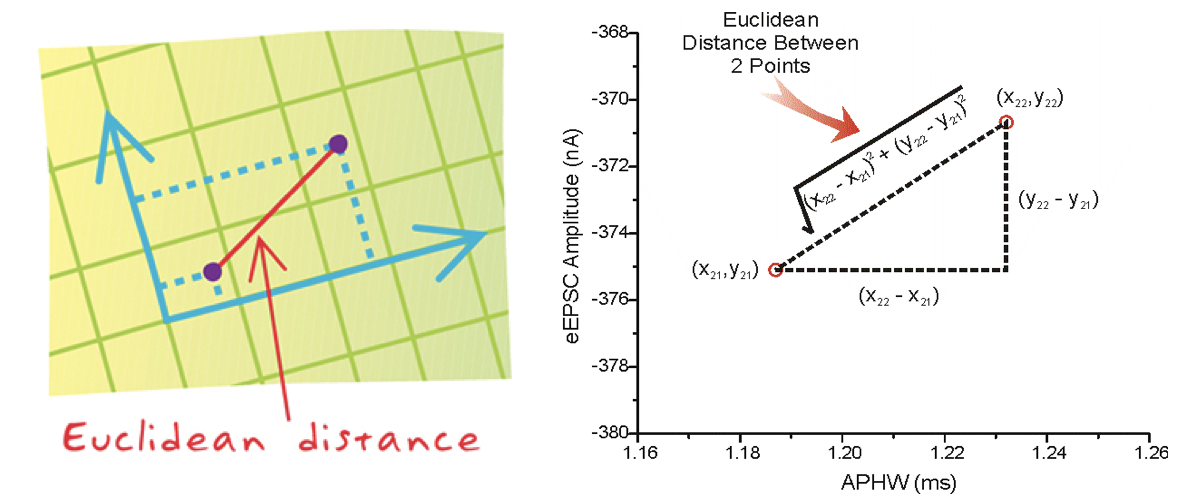
- 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离 ,关于距离公式会在后面进行讨论

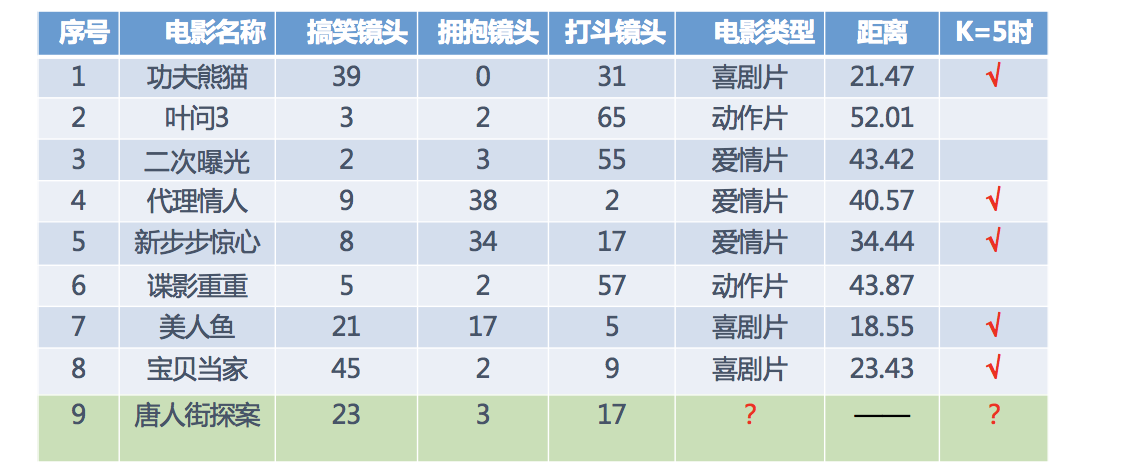
1.2 电影类型分析
假设我们现在有几部电影
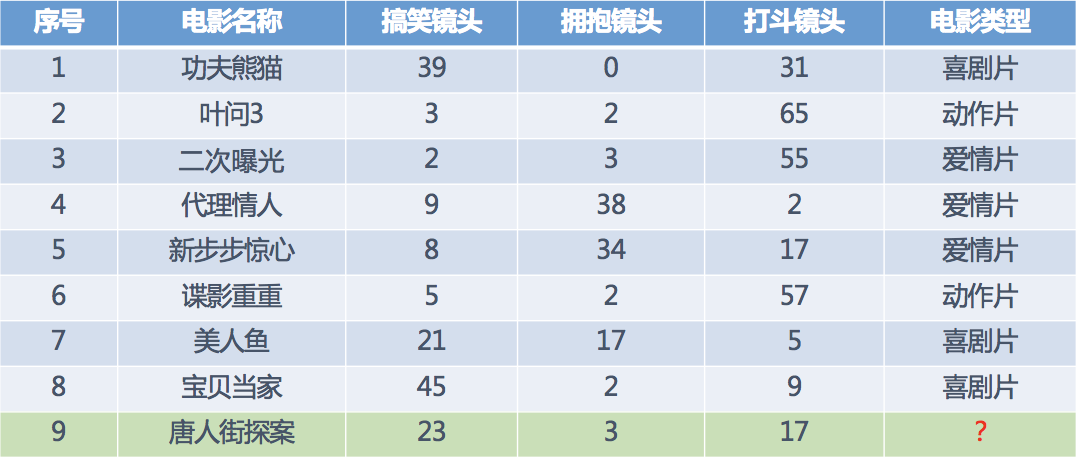
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
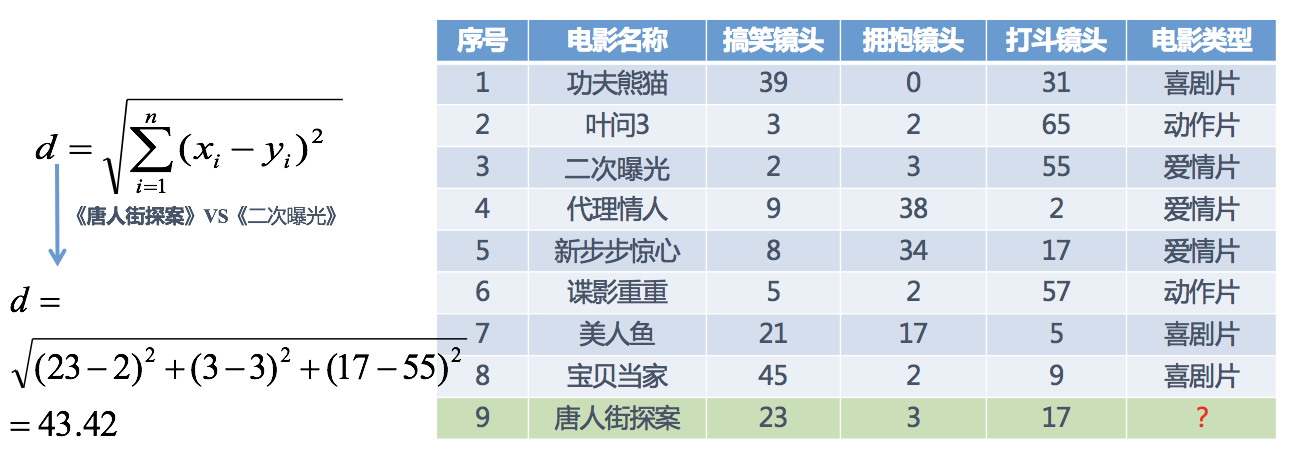
分别计算每个电影和被预测电影的距离,然后求解
1.2 k近邻算法api初步使用
机器学习流程复习:

- 1.数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习
- 5.模型评估
1 Scikit-learn工具介绍

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
1.1 安装
pip3 install scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
- 注:安装scikit-learn需要Numpy, Scipy等库
1.2 Scikit-learn包含的内容

- 分类、聚类、回归
- 特征工程
- 模型选择、调优
2 K-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
3 案例
3.1 步骤分析
- 1.数据集
- 2.数据基本处理(该案例中省略)
- 3.特征工程(该案例中省略)
- 4.机器学习
- 5.模型评估(该案例中省略)
3.2 代码过程
- 导入模块
from sklearn.neighbors import KNeighborsClassifier
- 构造数据集
x = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
- 机器学习 – 模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=2)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])
4 小结
-
最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,
-
1968年由 Cover 和 Hart 提出,应用场景有字符识别、文本分类、图像识别等领域。
-
该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别.
-
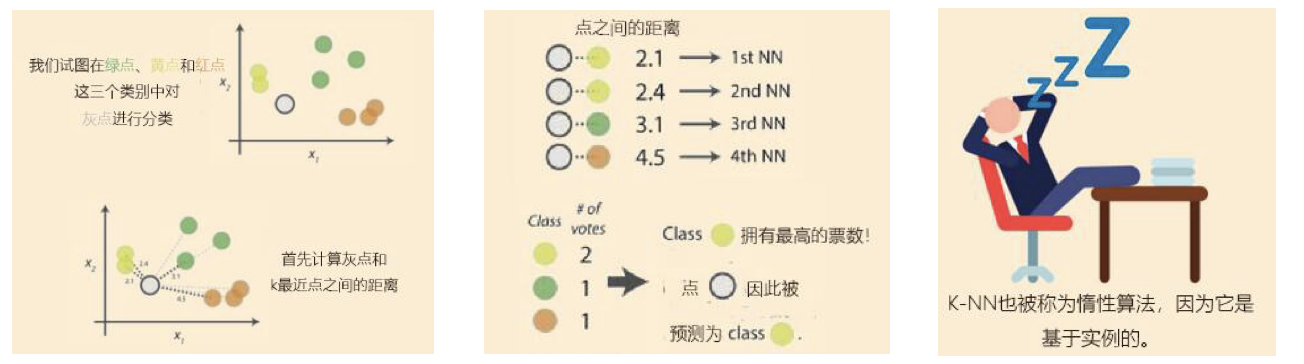
实现流程
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类
1.距离公式,除了欧式距离,还有哪些距离公式可以使用?
2.选取K值的大小?
3.api中其他参数的具体含义?
未完待续, 同学们请等待下一期
全套笔记和代码自取地址: 请移步这里
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类
[外链图片转存中…(img-6BRYcl4J-1704287974676)]
1.距离公式,除了欧式距离,还有哪些距离公式可以使用?
2.选取K值的大小?
3.api中其他参数的具体含义?
未完待续, 同学们请等待下一期
全套笔记和代码自取地址: 请移步这里
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!