[DL]深度学习_Feature Pyramid Network
一、概念介绍
????????Feature Pyramid Network (FPN)是一种用于目标检测和语义分割的神经网络架构。它的目标是解决在处理不同尺度的图像时,信息丢失和语义细节模糊的问题。
????????FPN的核心思想是通过在网络中添加一组横向连接来构建多尺度特征金字塔。这些横向连接将底层的高分辨率特征与高层的低分辨率特征进行融合,以捕捉不同尺度的语义信息。融合后的特征金字塔可用于检测和分割任务中的多尺度目标识别。
????????具体来说,FPN在主干网络(如ResNet)中的每个阶段添加一个横向连接,以便从高层到底层传递信息。这些连接可以通过上采样或卷积操作来进行特征融合和调整分辨率。最后,通过在FPN上构建特定的任务头部网络(如分类器或分割器),可以实现目标的检测和分割。
????????FPN的优点是能够有效地解决多尺度的问题,提高目标检测和语义分割的性能。它已经在许多计算机视觉任务中取得了显著的成果,并被广泛应用于许多最先进的目标检测和分割算法中。
?二、结构详解
1、对比试验?

? ? ? ? 图(a)是一个特征图像金字塔结构,常用于传统图像处理。?对于要检测不同尺度目标的时候,将图片首先缩放到不同的尺度,针对每个尺度图片,依次通过算法进行预测。此时会面临一个问题,生成多少个尺度就需要预测多少次,效率低下。
? ? ? ? 图(b)是Faster?R-CNN采用的一种方式,将图片通过骨干网络提取得到最终的特征图,在最终的特征图上进行预测,但是这种方式对于小目标检测效果不是很好。
? ? ? ? 图(c)是SSD算法采用的方式,将图片输入到骨干网络,此时会在骨干网络正向传播中得到的不同的特征图上分别进行预测。
? ? ? ? 图(d)为FPN特征金字塔结构,与图(c)进行简单的对比,可以看出,特征金字塔结构并不是简单的在骨干网络得到的不同特征图上进行预测,而是将不同特征图上的特征进行融合,然后再融合之后的特征图上再进行预测。
2、特征图融合
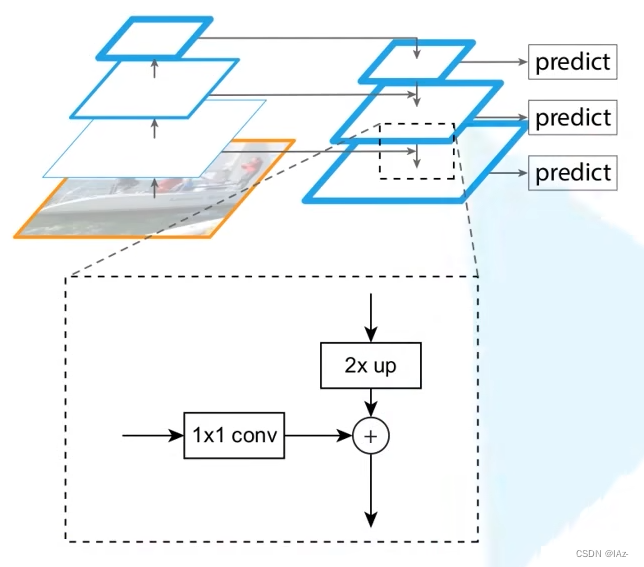
? ? ? ? 需要将不同尺度特征图进行融合,不同的特征图构建时,都是以2的整数倍进行选取,这是因为分类网络中的骨干网络缩放特征图时都是以2的整数倍进行缩放的。
? ? ? ? 针对每一个骨干网络上的特征图都先用1x1的卷积层进行处理,目的是为了之后进行特征图融合,调整骨干网络中不同特征图的通道数。
? ? ? ? 在高层次特征图与低层次特征图进行融合时,因为高层的特征图的大小在骨干网络正向传播时会缩小为低一层特征图的一半,所以在融合之前需要将高层特征图进行2倍上采样,正好与低一层特征图大小相同,低一层特征图又经过1x1卷积之后与高层特征图统一了通道数,可以进行特征图融合操作。
? ? ? ? 2倍上采样通过邻近插值算法。
notes:
????????邻近插值算法是一种简单且常用的上采样方法,它通过复制最近邻像素的值来增加特征图的尺寸。
????????邻近插值算法的基本思想是对于每个新像素,找到与其最接近的原始像素,并将其值赋给新像素。这种方法不涉及任何计算或插值操作,因此计算效率很高,适合用于快速的上采样需求。
具体实现上,邻近插值算法可以通过以下步骤进行:
- 根据上采样的倍数,计算新特征图的尺寸。
- 对于新特征图中的每个像素,找到与其最接近的原始特征图的位置。
- 将原始特征图中最接近的像素值赋给新特征图中的对应像素。
????????例如,假设有一个大小为4x4的低分辨率特征图,需要将其上采样为8x8的高分辨率特征图。那么,对于高分辨率特征图中的每个像素,可以找到最接近的原始特征图像素的位置,并将其值赋给新特征图。这样就完成了邻近插值算法的上采样过程。
????????虽然邻近插值算法简单高效,但它可能会导致一些细节信息的损失,因为它只是简单地复制最接近的像素值。因此,对于一些对细节信息要求较高的任务,如图像分割或图像生成,可能需要使用更复杂的上采样方法,如转置卷积。
3、结构详解?
 ? ? ? ? ?选取ResNet-50作为骨干网络,结合FPN结构。主干网络输入图像尺寸为[640x640x3]。对于C2、C3、C4、C5得到的特征图分别通过1x1的卷积层调整通道数,之后从C5到C2通过上采样操作进行融合。在所得到的新的特征图之后,再分别接上一个3x3卷积层,对融合后的特征图进一步融合,依次得到P2、P3、P4、P5,原论文给的一个描述,会在P5的基础上进行最大池化下采样得到P6。
? ? ? ? ?选取ResNet-50作为骨干网络,结合FPN结构。主干网络输入图像尺寸为[640x640x3]。对于C2、C3、C4、C5得到的特征图分别通过1x1的卷积层调整通道数,之后从C5到C2通过上采样操作进行融合。在所得到的新的特征图之后,再分别接上一个3x3卷积层,对融合后的特征图进一步融合,依次得到P2、P3、P4、P5,原论文给的一个描述,会在P5的基础上进行最大池化下采样得到P6。
notes:
????????需要注意的是P6只用于区域生成网络RPN部分。RPN生成Proposal预选框时候,会在P2、P3、P4、P5、P6特征图上进行预测,但是在Fast R-CNN部分中,只会在P2、P3、P4、P5上进行预测。
? ? ? ? 在Faster R-CNN是在预测特征图上通过RPN网络生成得到一系列的Proposal预选框,然后将Proposal预选框映射到特征图上,然后将映射的这部分特征输入到Fast R-CNN部分得到最终预测结果。
? ? ? ? 在FPN结构中,首先通过RPN结构在P2、P3、P4、P5、P6上进行预测Proposal预选框,然后将预测得到的Proposal预选框映射到P2、P3、P4、P5上,然后通过Fast R-CNN部分得到最终预测结果。
4、不同尺度预测?
? ? ? ? 由于在RPN网络中生成了多个预测特征层,所以可以在不同的预测特征层上,分别针对不同尺度的目标进行预测。在Faster R-CNN上,只有一个预测特征层,所以是在这一个预测特征层上生成不同面积不同比例的anchor。但是在FPN上,不同预测特征层可以针对不同尺度的目标。?
? ? ? ? 随着卷积池化等操作之后,细节信息会丢失。P2相对较为底层的预测特征层,会保留更多的底层细节信息,更适合预测小目标。会将面积为,比例为1:2,1:1,2:1的anchor在P2上生成。针对P3使用面积
,P4使用面积
,P5使用面积
,P6使用面积
,比例都为1:2,1:1,2:1的anchor。这也是与Faster R-CNN不一样的地方。
? ? ? ? 在不同的特征预测层上共用同一个RPN和Fast R-CNN,和分别在不同的特征预测层上用不同的RPN和Fast R-CNN的情况下,检测精度并无差异。所以为了减少网络训练参数,可以在不同特征预测层上共享RPN预测头和Fast R-CNN模块。在RPN部分,P2到P6使用同一个模块,而Fast R-CNN部分,P2到P5使用同一模块。
5、Proposal映射到预测特征层
- k为应该对应的预测特征值的层数,对应P2到P5,数值为2到5
设置为4
- w为RPN预测得到的Proposal在原图上的宽度
- h为RPN预测得到的Proposal在原图上的高度
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年生成式AI支出将翻倍,到2027年将超1500亿美元
- 智能 GPT 图书馆又重生了
- Linux命令_vim的详细用法
- 爬虫抓取链家二手房数据
- Rust 学习
- 部署SD-WAN需要哪些设备和软件?
- 从函数角度看品牌网络推广:短期与长期的博弈
- 使用 Fiddler+Linux 日志 + 数据库,搞懂3个问题,强势回怼开发!
- 服务器宕机怎么办?怎么预防宕机?
- mysql的性能调优,explain的用法,explain各字段的解释