Python—使用LangCahin调用千帆大模型
文章目录
前言
LangChain就是一个 LLM 编程框架,你想开发一个基于 LLM 应用,需要什么组件它都有,直接使用就行;甚至针对常规的应用流程,它利用链(LangChain中Chain的由来)这个概念已经内置标准化方案了。
LangChain是一个用于开发由语言模型提供支持的应用程序的框架。它使应用程序能够:
- 数据感知:将语言模型连接到其他数据源
- 具有代理性质:允许语言模型与其环境交互
| 名称 | 网址 |
|---|---|
| LangChain中文网 | https://www.langchain.com.cn/ |
| LangChain官网 | https://www.langchain.com/ |
| LangChain API文档地址 | https://api.python.langchain.com/en/latest/langchain_api_reference.html# |
环境:
| 名称 | 版本 |
|---|---|
| Python | 3.9 |
| LangChain | 0.1.0 |
一、安装LangChain
此次我安装的最新版为:0.1.0
pip install langchain
#安装qianfan
pip install qianfan
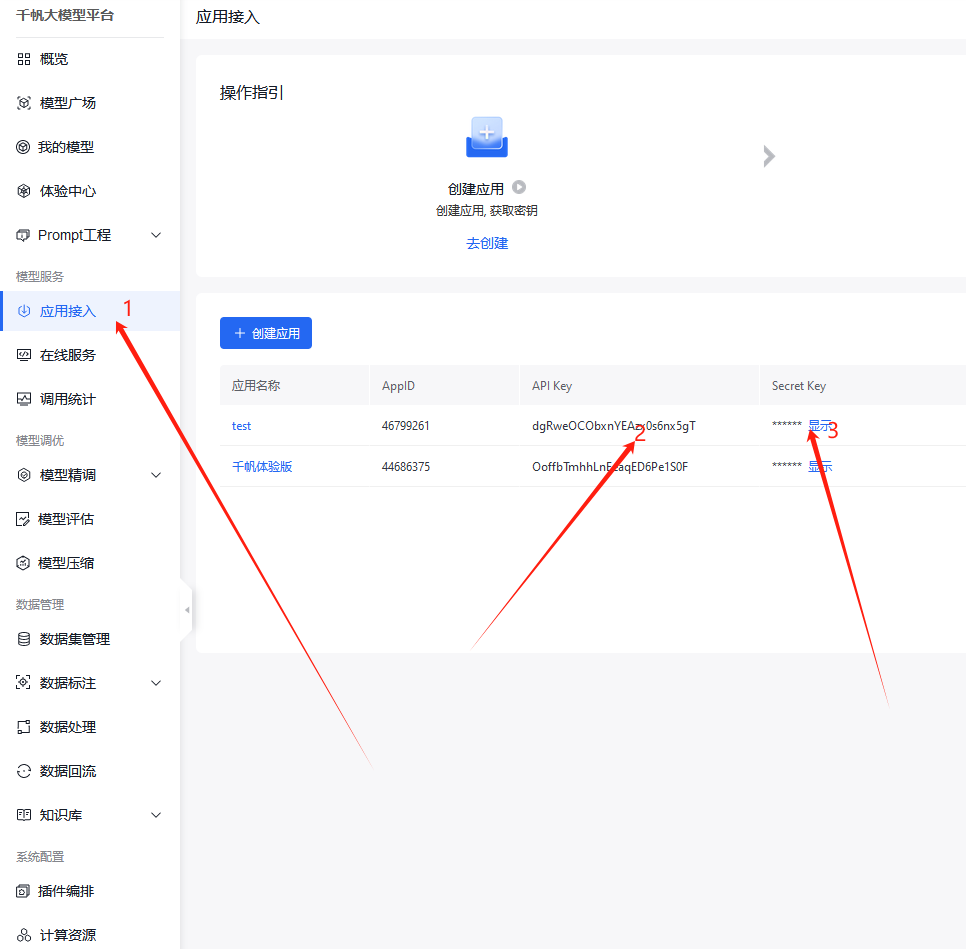
二、获取千帆API Key、Secret Key
- 登录百度云搜索进入千帆大模型控制台
- 没有应用则创建应用
- 获取APIKey、SecretKey
三、简单对话案例实现
调用千帆大模型,实现让大模型讲个故事
"""For basic init and call"""
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
chat = QianfanChatEndpoint(
streaming=True,
)
res = chat([HumanMessage(content="讲一个故事")])
print(res.content)
输出结果如下:

到此最简单的案例就已经实现了。
四、构建语言模型应用程序:LLM
LangChain 最基本的构建块是对某些输入调用 LLM。
让我们来看一个简单的例子。
我们假设我们正在构建一个基于公司产品生成公司名称的服务。
1.初始化模型
from langchain_community.llms import QianfanLLMEndpoint
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
llm = QianfanLLMEndpoint(temperature=0.9)
2.LLM初始化和调用
import os
from langchain_community.llms import QianfanLLMEndpoint
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
llm = QianfanLLMEndpoint(temperature=0.9)
text = "对于一家生产彩色袜子的公司来说,什么是一个好的公司名称?"
print(llm.invoke(text))
五、提示词模板(PromptTemplate): 管理 LLM 的提示
调用 LLM 是很好的第一步,但这仅仅是个开始。
通常在应用程序中使用 LLM 时,不会将用户输入直接发送到 LLM。
相反,您可能接受用户输入并构造一个提示符,然后将其发送给 LLM。
例如,在前一个示例中,我们传入的文本被硬编码为询问一家生产彩色袜子的公司的名称。在这个虚构的服务中,我们希望只获取描述公司业务的用户输入,然后用这些信息格式化提示符。
1.定义提示模板
- ChatPromptTemplate:是聊天提示词模板
ChatPromptTemplate文档地址
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[
("user","我想去{location}旅游,能帮我简单介绍一下吗?")
]
)
2.组合 LLM 和提示词
import os
from langchain_community.llms import QianfanLLMEndpoint
from langchain_core.prompts import ChatPromptTemplate
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
llm = QianfanLLMEndpoint(temperature=0.9)
prompt = ChatPromptTemplate.from_messages(
[
("user","我想去{location}旅游,能帮我简单介绍一下吗?")
]
)
chat = prompt | llm
result = chat.invoke({"location": "海南"})
print(result)
3.组合输出解析器
ChatModel(因此,此链)的输出是一条消息。但是,使用字符串通常要方便得多。让我们添加一个简单的输出解析器,将聊天消息转换为字符串。
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
我们现在可以将其添加到上一个链中:
chain = prompt | llm | output_parser
我们现在可以调用它并提出相同的问题。答案现在将是一个字符串(而不是 ChatMessage)。
六、信息检索链(Retrieval Chain)
实现目标:
提供一份文档,提出问题,在文档中检索出答案。我这里是提供了一个知乎-中国古代史-明朝的网址。
我们将从检索器中查找相关文档,然后将它们传递到提示中。 Retriever 可以由任何东西支持——SQL 表、互联网等——但在本例中,我们将填充一个向量存储并将其用作检索器。
1.加载索引数据
首先,我们需要加载要索引的数据:
from langchain_community.document_loaders import WebBaseLoader
WEB_URL = "https://zhuanlan.zhihu.com/p/85289282"
# 使用WebBaseLoader加载HTML
loader = WebBaseLoader(WEB_URL)
docs = loader.load()
2.存储向量数据
接下来,我们需要将其索引到向量存储中。
下载向量数据库Chroma
pip install chromadb
根据版本问题可能出现的问题:
问题:
Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0.解决方案:
根据自己的操作系统在 SQLite Download Page 下载最新的sqlite包,解压后是"sqlite3.def"和"sqlite3.dll"两个文件。将这两个文件覆盖到 "python安装目录/DLLs"下即可。
然后我们可以构建我们的索引:
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入千帆向量模型
embeddings = QianfanEmbeddingsEndpoint()
# 导入递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 384, chunk_overlap = 0, separators=["\n\n", "\n", " ", "", "。", ","])
# 导入文本
documents = text_splitter.split_documents(docs)
# 存入向量数据库
vector = Chroma.from_documents(documents, embeddings)
3.创建检索链传入问题
我们设置一个链,该链接受一个问题和检索到的文档并生成一个答案。
from langchain.chains.combine_documents import create_stuff_documents_chain
# 创建提示词模板
prompt = ChatPromptTemplate.from_template("""使用下面的语料来回答本模板最末尾的问题。如果你不知道问题的答案,直接回答 "我不知道",禁止随意编造答案。
为了保证答案尽可能简洁,你的回答必须不超过三句话,你的回答中不可以带有星号。
请注意!在每次回答结束之后,你都必须接上 "感谢你的提问" 作为结束语
以下是一对问题和答案的样例:
请问:秦始皇的原名是什么
秦始皇原名嬴政。感谢你的提问。
以下是语料:
<context>
{context}
</context>
Question: {input}""")
#创建千帆LLM模型
llm = QianfanLLMEndpoint()
#创建检索链
document_chain = create_stuff_documents_chain(llm, prompt)
4.使用检索器动态选择最相关的文档并将其传递
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
5.完整代码及调用
import os
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import QianfanLLMEndpoint
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
# 定义URL
WEB_URL = "https://zhuanlan.zhihu.com/p/85289282"
# 使用WebBaseLoader加载HTML
loader = WebBaseLoader(WEB_URL)
docs = loader.load()
# 导入千帆向量模型
embeddings = QianfanEmbeddingsEndpoint()
# 导入递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 384, chunk_overlap = 0, separators=["\n\n", "\n", " ", "", "。", ","])
# 导入文本
documents = text_splitter.split_documents(docs)
# 存入向量数据库
vector = Chroma.from_documents(documents, embeddings)
# 创建提示词模板
prompt = ChatPromptTemplate.from_template("""使用下面的语料来回答本模板最末尾的问题。如果你不知道问题的答案,直接回答 "我不知道",禁止随意编造答案。
为了保证答案尽可能简洁,你的回答必须不超过三句话,你的回答中不可以带有星号。
请注意!在每次回答结束之后,你都必须接上 "感谢你的提问" 作为结束语
以下是一对问题和答案的样例:
请问:秦始皇的原名是什么
秦始皇原名嬴政。感谢你的提问。
以下是语料:
<context>
{context}
</context>
Question: {input}""")
#创建千帆LLM模型
llm = QianfanLLMEndpoint()
#我们设置一个链,该链接受一个问题和检索到的文档并生成一个答案。
document_chain = create_stuff_documents_chain(llm, prompt)
#使用检索器动态选择最相关的文档并将其传递。
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
#调用这个链了。这将返回一个字典 - 来自 LLM 的响应在键中answer
response = retrieval_chain.invoke({
"input": "朱元璋时期中国多少人口?"
})
print(response["answer"])
结果示例:
抱歉,我无法得知朱元璋时期中国具体的人口数量。不过,我可以告诉你,在明朝时期,中国的人口数量在历史上经历了巨大的变化。明朝初年,由于元朝末年的战乱和瘟疫,人口数量相对较少。然而,随着时间的推移,明朝政府实行了一系列轻徭薄赋的政策,促进了社会经济的恢复和发展,人口数量也逐渐增加。在明朝中后期,由于农业、手工业和商业的繁荣,中国的人口数量达到了历史高峰。
七、实现简单的聊天机器人
使用普通聊天模型,我们可以通过传递一个消息或使用ChatModel发送更多消息。
1.聊天模型将使用消息进行响应。
import os
from langchain.schema import HumanMessage, SystemMessage
from langchain_community.chat_models import QianfanChatEndpoint
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
chat = QianfanChatEndpoint()
res = chat.invoke([
HumanMessage(
content="把这句话从中文翻译成英语:我喜欢编程。"
)
])
print(res.content)
输出结果:I enjoy programming.
2.传入一个消息列表:
import os
from langchain.schema import HumanMessage, SystemMessage
from langchain_community.chat_models import QianfanChatEndpoint
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
#使用默认的模型回答不正确,所以切换至模型:ERNIE-Bot-4
chat = QianfanChatEndpoint(model='ERNIE-Bot-4',temperature=0.8)
res = chat.invoke([
SystemMessage(
content="你是把中文翻译成英文的得力助手。"
),
HumanMessage(content="我喜欢编程。"),
])
print(res.content)
输出结果:I enjoy programming.
3.使用ConversationChain记住过去的用户输入和模型输出
然后,我们可以将聊天模型包装在ConversationChain中,它有内置内存,用于记住过去的用户输入和模型输出。
import os
from langchain.schema import HumanMessage, SystemMessage
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.chains import ConversationChain
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
chat = QianfanChatEndpoint(model='ERNIE-Bot-4',temperature=0.8)
conversation = ConversationChain(llm=chat)
res = conversation.invoke({"input":"你是把中文翻译成英文的得力助手:我喜欢编程"})
print(res['response'])
#结果为: to English. Your sentence "我喜欢编程" translates to "I enjoy programming."
res2=conversation.invoke({"input":"把他翻译成德语"})
print(res2)
#结果为:将其翻译成德语为 "Ich genie?e das Programmieren.
4.对话
我们通过ConversationBufferMemory可以指定我们的对话记录
此案例是指定对话记录,继续进行对话。
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, SystemMessagePromptTemplate, MessagesPlaceholder, \
HumanMessagePromptTemplate
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
chat = QianfanChatEndpoint(model='ERNIE-Bot-4', temperature=0.8)
prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template(
"你是一个聊天机器人"
),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
memory.save_context({"input": "你好"}, {"output": "你好,请问有什么我可以帮助你的吗?"})
memory.save_context({"input": "把这句话从中文翻译成英语:我喜欢编程。"}, {"output": " I enjoy programming."})
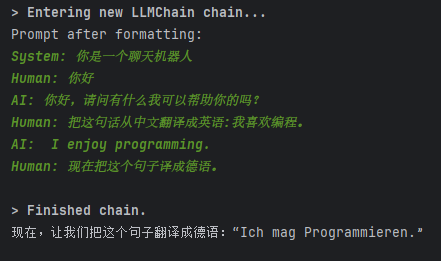
conversation = LLMChain(llm=chat, prompt=prompt, verbose=True, memory=memory)
# 注意,我们只是传入了“question”变量——“chat_history”由内存填充
res = conversation.invoke({"question": "现在把这个句子译成德语。"})
print(res)
输出结果如下:
5.聊天检索
现在,假设我们想要与文档或其他知识来源聊天。
这是一个流行的用例,结合了聊天和文档检索。
它允许我们与模型没有训练过的特定信息进行聊天。
1)加载博客文章。
from langchain_community.document_loaders import WebBaseLoader
# 加载博客文章。
loader = WebBaseLoader("https://zhuanlan.zhihu.com/p/85289282")
data = loader.load()
2)将其拆分并存储在向量中
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
3)创建会话记忆
memory = ConversationSummaryMemory(
llm=llm, memory_key="chat_history", return_messages=True
)
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
4)整体代码示例
# 聊天检索
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.chains import ConversationChain, LLMChain, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ["QIANFAN_AK"] = "API_KEY"
os.environ["QIANFAN_SK"] = "SECRET_KEY"
# 加载博客文章。
loader = WebBaseLoader("https://zhuanlan.zhihu.com/p/85289282")
data = loader.load()
# 将其拆分并存储在向量中。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
# 存储在向量中。
vectorstore = Chroma.from_documents(documents=all_splits, embedding=QianfanEmbeddingsEndpoint())
# 像以前一样创建我们的记忆,但是让我们使用 ConversationSummaryMemory
retriever = vectorstore.as_retriever()
chat = QianfanChatEndpoint(model='ERNIE-Bot-4', temperature=0.8)
memory = ConversationSummaryMemory(
llm=chat, memory_key="chat_history", return_messages=True
)
qa = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever, memory=memory)
res = qa.invoke(
{"question": "请帮我出3个明朝的题目并给出答案"}
)
print(res["answer"])
结果:

总结
LangCahin框架功能非常强大,但是要注意版本问题。在LangChain0.1.0版本之后很多写法就变了。英文官网上也是只有部分更新的新的写法,老写法也依然支持但是已经不推荐使用了。后续还会持续学习,会继续更新更多用法。
存疑:由于是新手python选手,安装python环境直接使用最新的3.12版本装不上LangChain也换电脑试了还是不行被迫改为3.8或3.9。有懂的大佬可以评论讲解一下。
本文很多文案和代码示例都来源于官网(略有修改),有一些文案翻译的不对凑活看吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c#怎么访问 devexpress.xtrabars.barbuttonitem
- JavaScript系列——闭包
- 全面解析MONAI Transforms的用法 视频+教程+代码
- 【react】动态页面转换成html文件下载,解决样式问题
- workspace.xml文件停止被git追踪
- 查找书籍(缓冲区)
- Vert.x学习笔记-什么是事件总线
- vue3引入使用高德地图,不显示地图问题
- 全球企业绿色供应链数据(含CITI指数和CATI指数,2014-2023年)
- 1、Seaborn可视化库