IC入门必备!数字IC中后端设计实现全流程解析(1.3万字长文)
吾爱IC社区自2018年2月份开始在公众号上开始分享数字IC后端设计实现相关基础理论和实战项目经验,累计输出文字超1000万字。全部是小编一个个字敲出来的,绝对没有复制粘贴的情况,此处小编自己得给自己鼓鼓掌鼓励下自己。人生不要给自己设限,只要敢想敢做就一定能做成。今天回首来看这近6年持续的内容输出,小编都不得不佩服今天的自己!如果你也想给小编鼓励下,请在文章末尾点个免费的赞,好让小编知道下各位看官的心声。
这6年以来主要分享的是小编自己从事数字IC后端设计实现工作12年以来的项目经验总结以及经常遇到的项目案例。最近受读者邀请,特地把数字IC后端工程师所有工作内容,按照数字IC设计流程全面做了一个盘点。
限于篇幅,IC后端设计实现流程中更多细节,可以访问小编的后端知识库(知识星球)进行查看。如果对某个环节有任何疑问或困惑,都可以跟小编做进一步的交流和讨论。本文共有1.2万字,所以建议大家收藏起来慢慢看。
一.逻辑综合
这步是把前端编写的RTL代码转换成基于Foundary 标准单元的gate level netlist 。这里说的netlist其实就是一张电路原理图,只不过显示的形式是verilog语法的netlist。当然这个转换过程需要考虑我们所施加的时序约束和物理约束。正常逻辑综合只做逻辑的优化。目前大部分高频电路的设计,普遍采用物理综合。物理综合主要有genus的iSpatial Flow和DCG Flow。

上图描述的计数器counter的RTL代码经过逻辑综合后就会变成如下所示的netlist。

【作业】大家可以尝试把上面的netlist对应的电路原理图画出来。
逻辑综合的流程大体如下图所示。


Genus的iSpatial Flow流程和它的feature如下图所示。
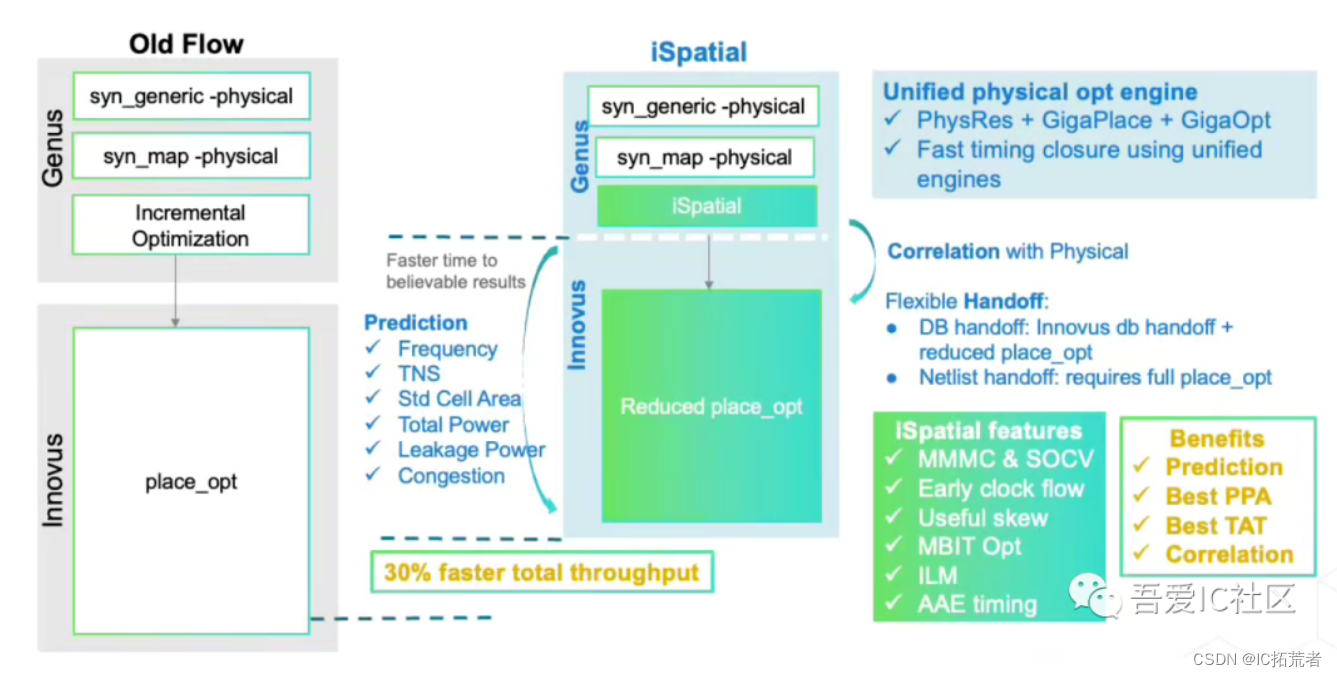
物理综合需要读入后端的floorplan def。
物理综合后有两种输出设计的方式:
1)DB handoff (大白话就是直接生成innovus的初始数据,已经完成corase placement的数据)
2)Netlist handoff (只提供经过优化后的设计netlist)
需要说明的是稍微大点的公司一般逻辑综合都是属于IC前端或者IC中端工程师的工作内容。小公司芯片规模很小的design,通常会要求一个人把前端,中端,后端的工作都包揽掉。
二.数字后端APR (Auto-Place &Route)
整个数字IC后端APR实现过程,我们也称为Physical Implementation,是属于physical design最重要的一个大步骤。它主要包含以下几方面内容。
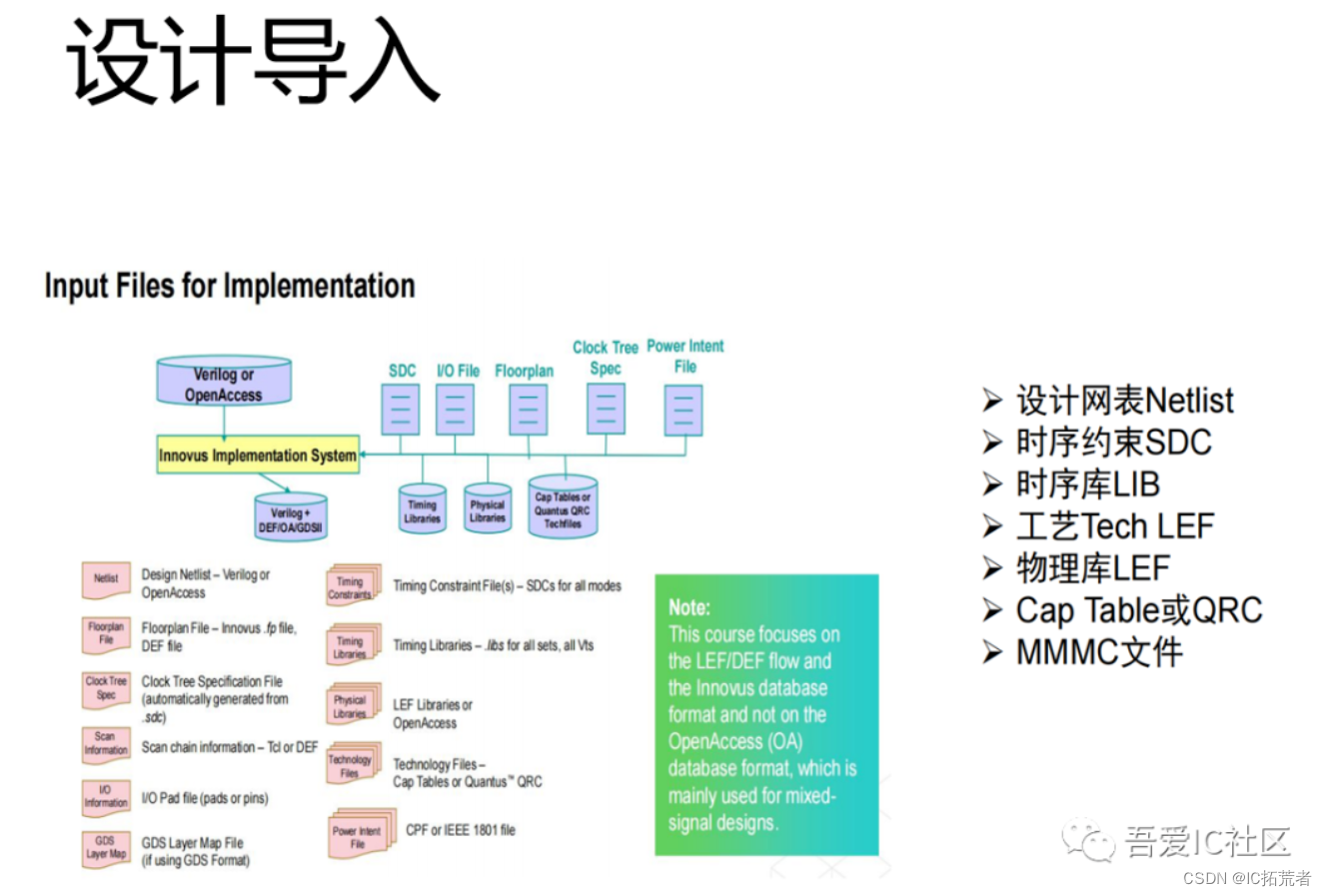
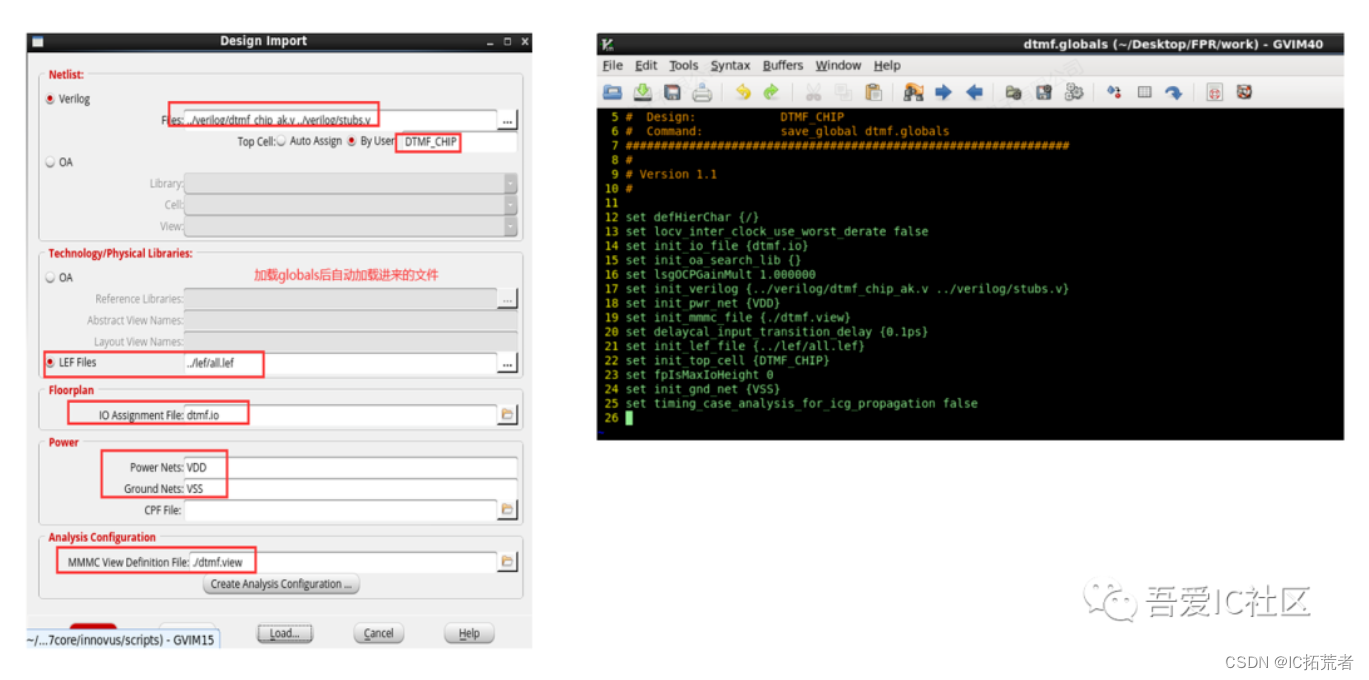
1)Design Import(设计导入)
拿到综合后的netlist后就需要把design读入PR工具。目前业界主流的两大PR工具是ICC2和Innovus。
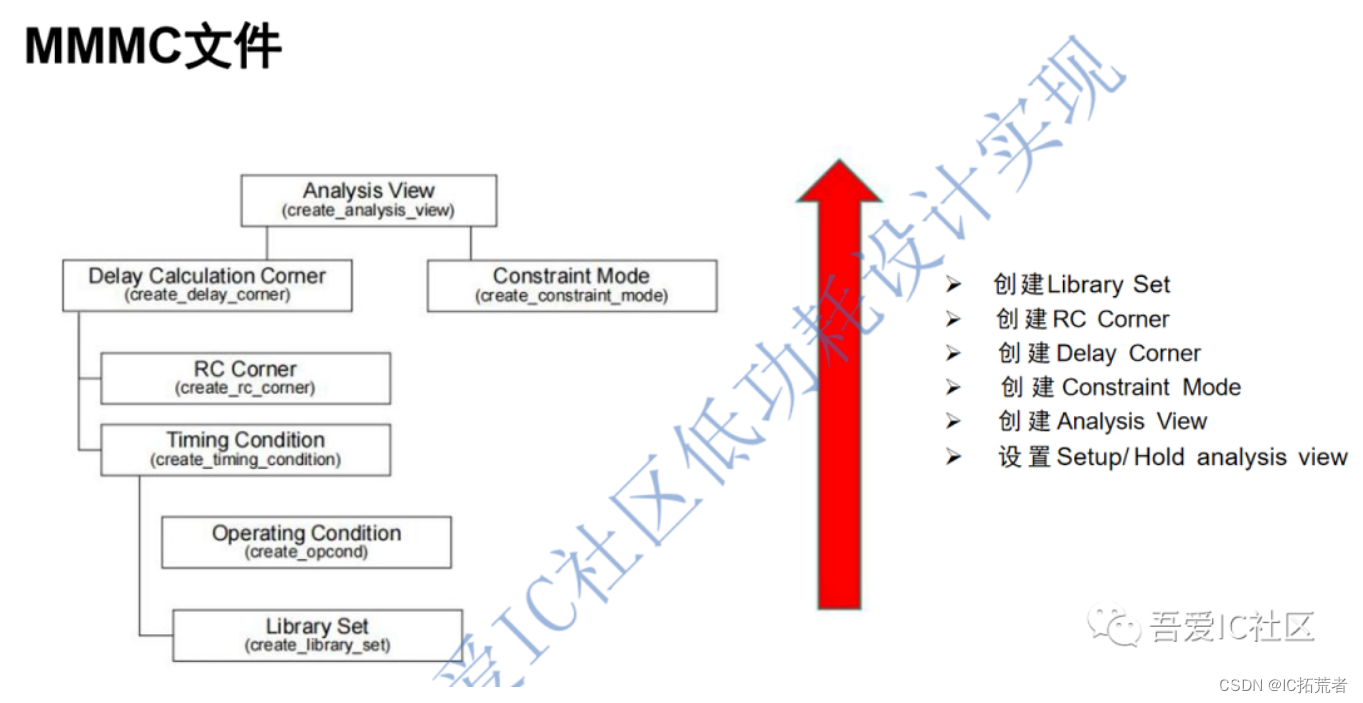
这个阶段需要用到的文件有设计网表netlist,时序约束sdc,工艺技术库tech lef (ICC2使用tech file tf文件),物理库LEF,时序库lib,Captable /QRC文件以及MMMC(Multi- Mode -Multi -Corner)文件。
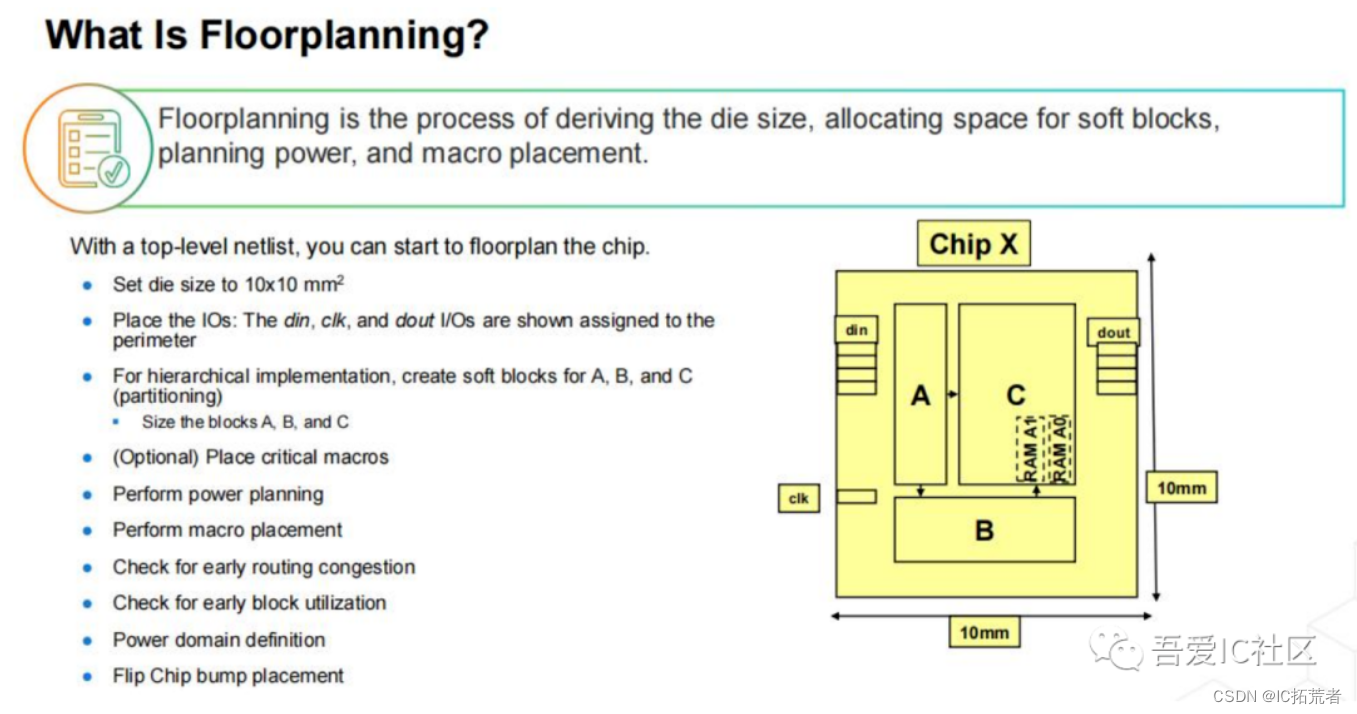
2)Floorplan (版图布局规划)
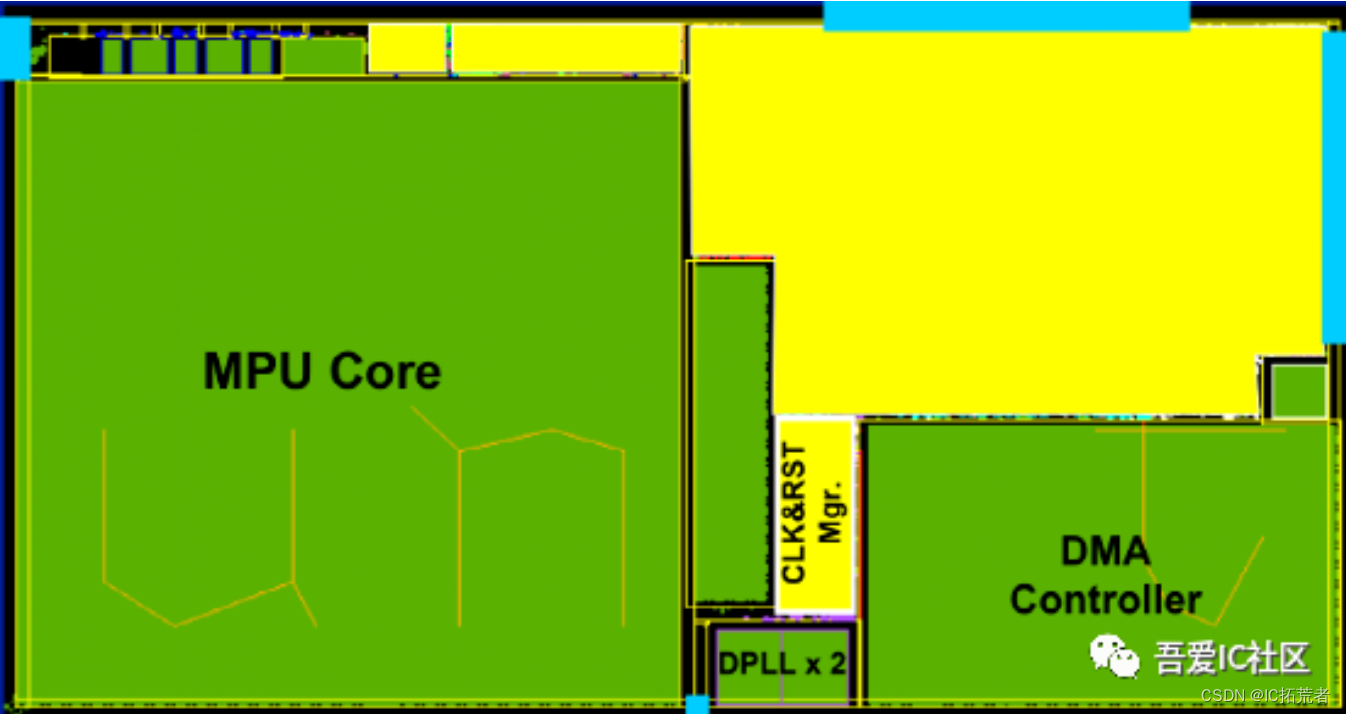
Floorplan的主要工作就是规划好芯片/子模块的大小,形状,io port摆放,memory,子模块,ip的摆放,endcap cell和tapcell的添加等工作。
Macro的摆放和IO port的摆放方法如下图所示。
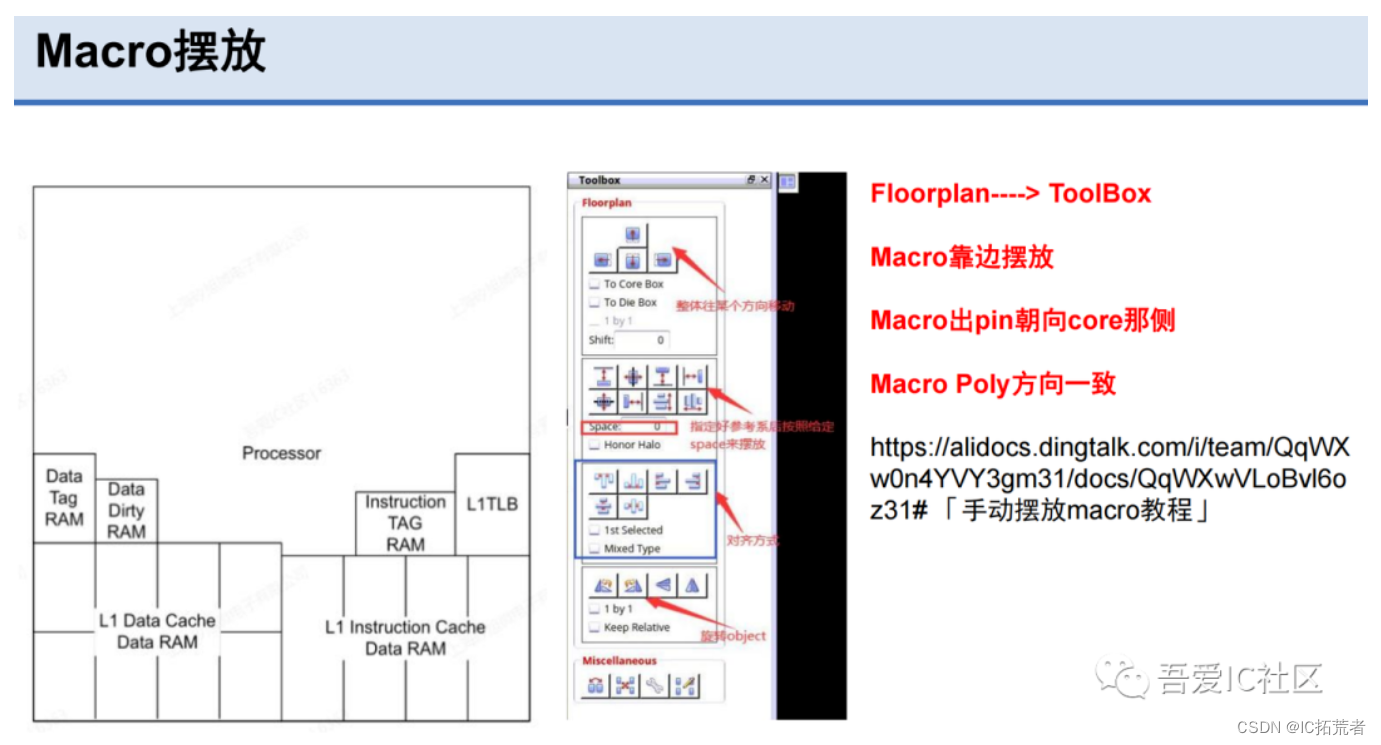
在floorplan阶段还需要添加physical only cell,比如endcap cell,tapcell,decap cell等。甚至有时候还会在这个阶段添加spare cell,这类cell用于后续的function eco。

如果是chip level的floorplan,它的主要内容就比较多了。主要涉及IO Ring(Pad Ring)的规划设计,IO cell的摆放,SSO的计算,power cut的规划摆放,IP,子模块的摆放等等。
对于一个IO/PAD Limitted的芯片,它的面积受限于IO/PAD的数量。因为芯片中IO的数量太多,导致芯片的长宽拉的比较大。对于这种情况,可以考虑对IO进行精简,比如去掉一些不太重要的IO或对IO进行复用等。
对于一个CORE Limitted的芯片,它的面积受限于芯片中各个子模块的面积大小。对于这种情况,各个子模块的数字后端实现就必须加大火力进行抠面积,将利用率最到最高,从而将芯片做小。
IO Ring的设计
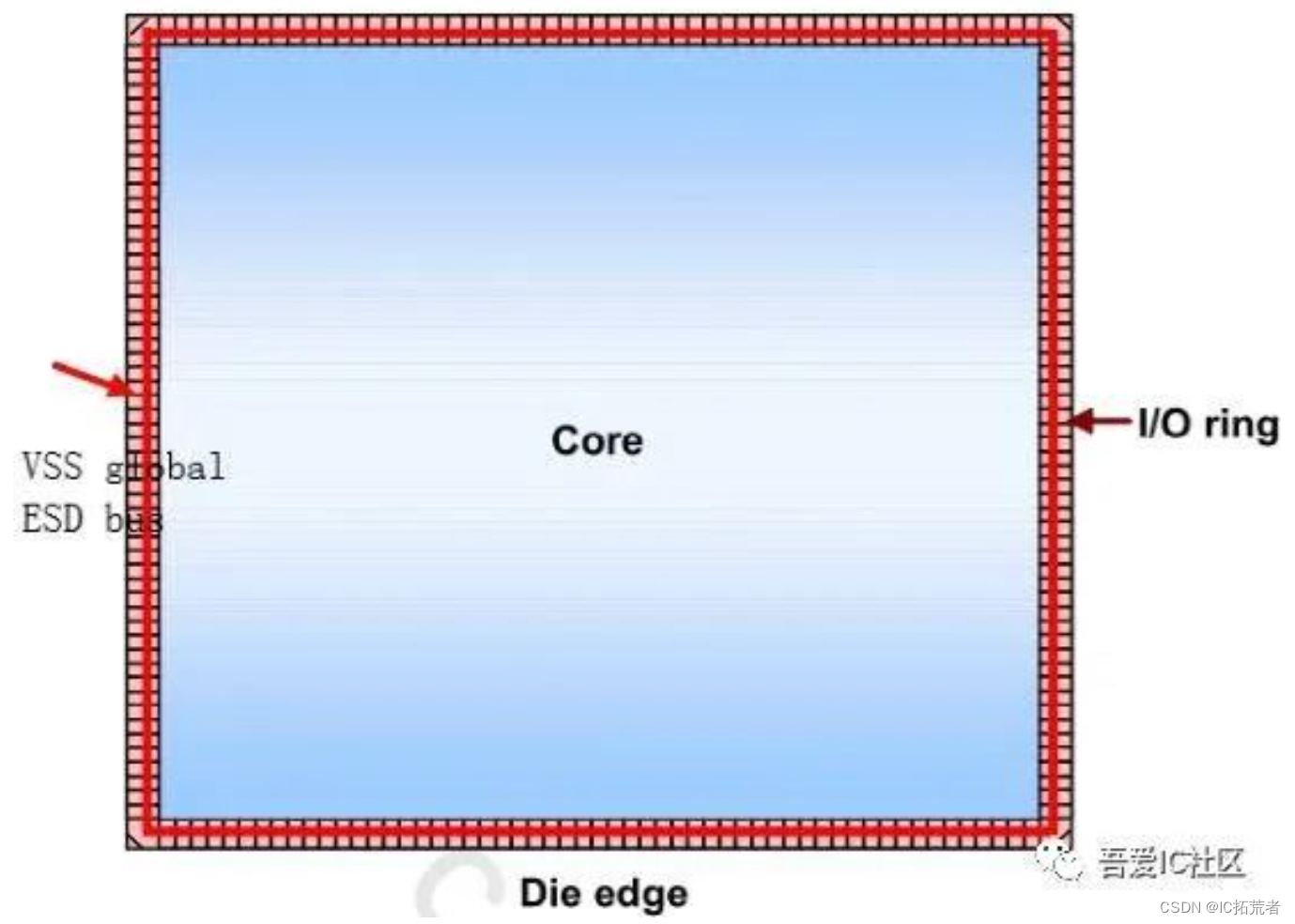
IO Ring的设计会直接影响芯片的面积大小。这步对于负责SOC顶层top的数字IC后端工程师来说非常重要。因此,小编觉得有必要单独拿出来做一个介绍。明年咱们社区会开一个SoC chip level的数字后端课程,大家到时候就可以接触到整个IO Ring的规划和设计的实操。
Power/Ground CELL添加
大部分情况下,前端集成设计时只会例化GPIO,并不会例化physical only的cell,比如power&ground cell。因此,拿到前端提供的netlist,首先要确定添加PG CELL的数量。
这里涉及到给core供电的power/ground cell和给IO供电的power/ground cell。前者要根据芯片的Total power来估算需要的power/ground cell数量。后者则需要根据各个IO Domain 的IO数量来计算SSO(Simultaneously Switching Output),最终确定对应的power/ground cell数量。
关于SSO的详细计算,请移步小编的知识星球,小编之前在星球上分享了TSMC和SMIC两大主流工艺的io application note文档。
Power Cut等cell添加
除了添加power/ground cell外,还需要根据vendor要求添加一系列的physical only的cell,比如power cut cell,power on controll cell,corner cell等。以power cut cell为例,一般在两个不同IO domain之间需要添加这类cell。
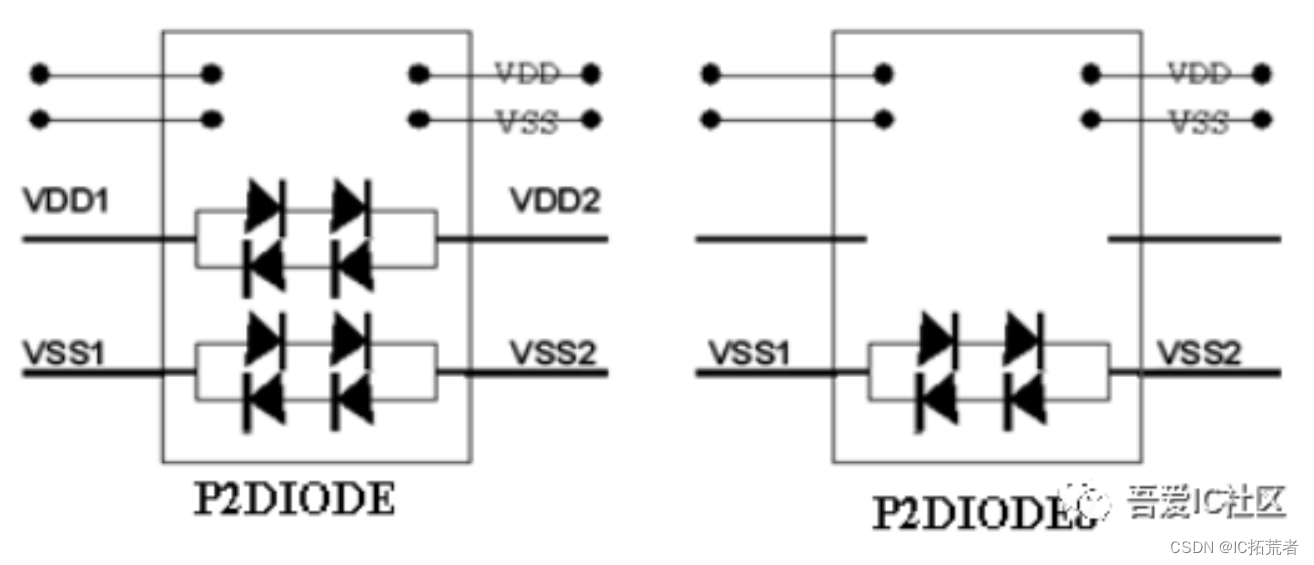
大部分foundary会提供几种不同类型的power cut cell,每种结构稍有不同,有的类型是Noise隔离好一点,有的类型是ESD保护会强一些。这个需要根据设计应用需求,进行抉择。
IO Placement
IO的摆放需要根据硬件PCB的布局来摆放。对于高速接口的IO,它的摆放位置显得更加重要。
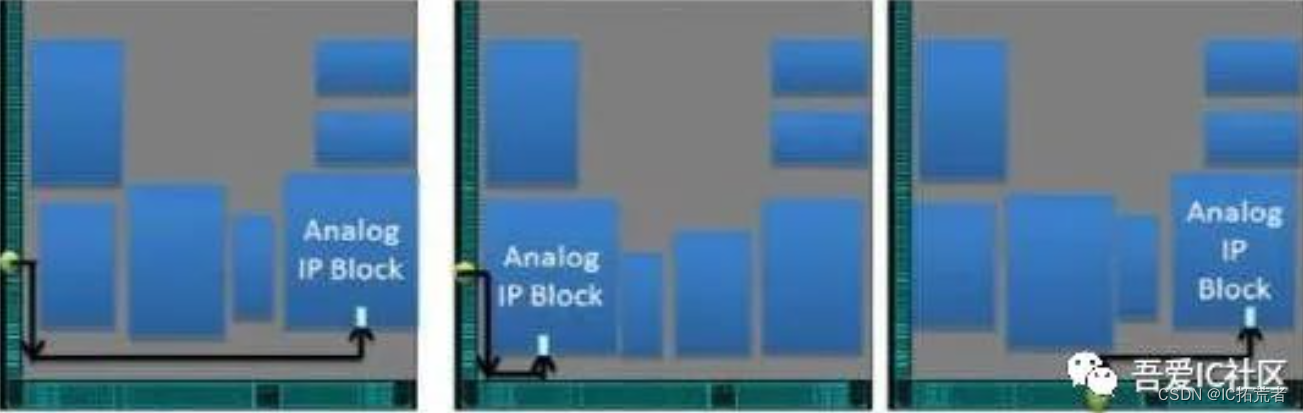
以上图最左侧示例,如果黄色部分IO属于高速接口的IO,那么它与Analog IP的path的时序一定有问题。
如果前期的IO placement是按照最左侧图示摆放,没有意识到接口时序问题,那么后期改动会非常大,基本上等于整个芯片(包括block)的实现都要重新来一遍。
如果前期能够意识到这个风险,那么完全可以将黄色的IO摆放在最下边那条边的中间位置。当然如果硬件PCB允许的情况下,还可以将Analog IP挪到最左侧。
IP摆放
IP摆放需要遵循以下原则:
符合时钟/数据流走向
比如PLL的摆放,需要靠近destination,使得时钟路径最短。
Poly Orientation
对于28nm甚至更先进工艺节点,摆放IP时需要特别注意POLY方向问题。因此在这样的工艺节点,是不允许90度翻转的。一旦方位出错,后期的floorplan就需要全面改一遍,项目的schedule就完全不受控制。
IR Drop Aware摆放法
有些IP内部抽出来的PG PIN,分布比较不好,如下图所示。如果该IP这样摆放,而且top powerplan用的最高层也是众向的layer,那么这个IP的供电将是个大问题。
如果IP能做90翻转,那也可以解决IR Drop的问题。如果不能翻转,那么就需要调整top powerplan的规划。因此,摆放IP的时候也要充分考虑IP供电问题,否则性能可能完全达不到预期。
3)Powerplan (电源网络设计)
这步的工作是为芯片指定好供电的PAD,并创建好整个芯片的供电网络,确保每个instance和每个device都能够获取到电。这里需要注意每个cell能拿到电是基础条件,我们还需要确保每个instance的供电足够充足,符合power signoff的要求。
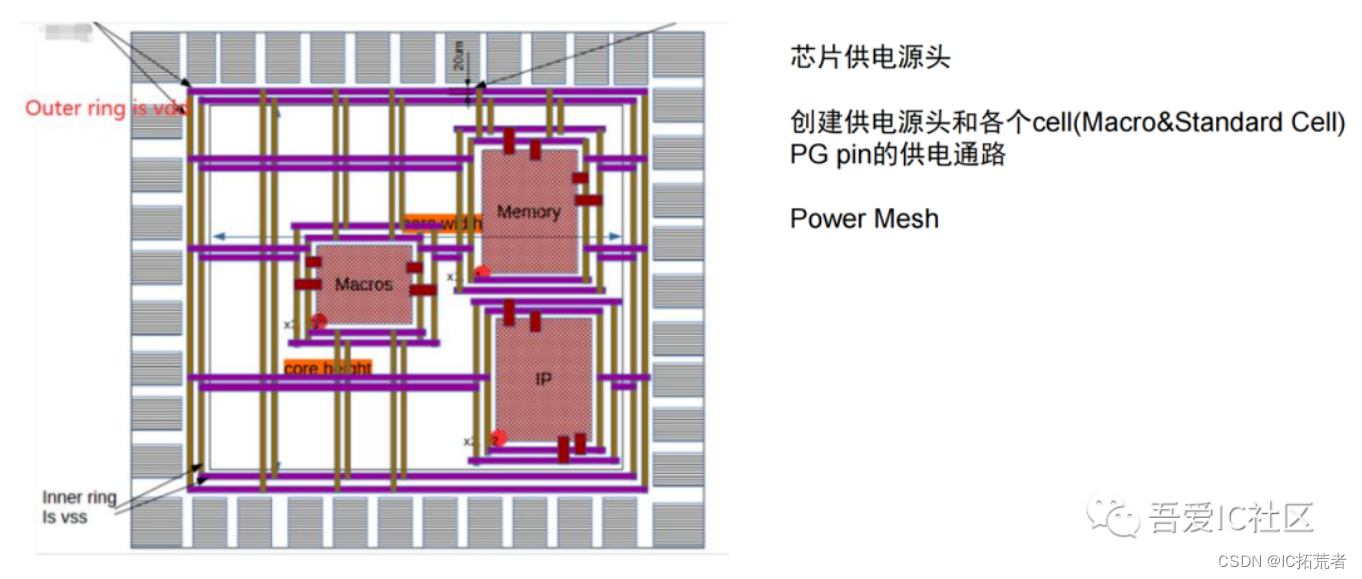
做完powerplan设计后,需要做一系列的QA检查。主要有检查pg是否存在floating,short,pg drc violation以及power signoff相关的检查,比如IR Drop分析和EM(Electromigration)电迁移的分析。

4) Placement(标准单元摆放)
这步就是把设计中的标准单元都摆放到芯片的core区域,确保所有的标准单元都摆放到它们对应的site row上。
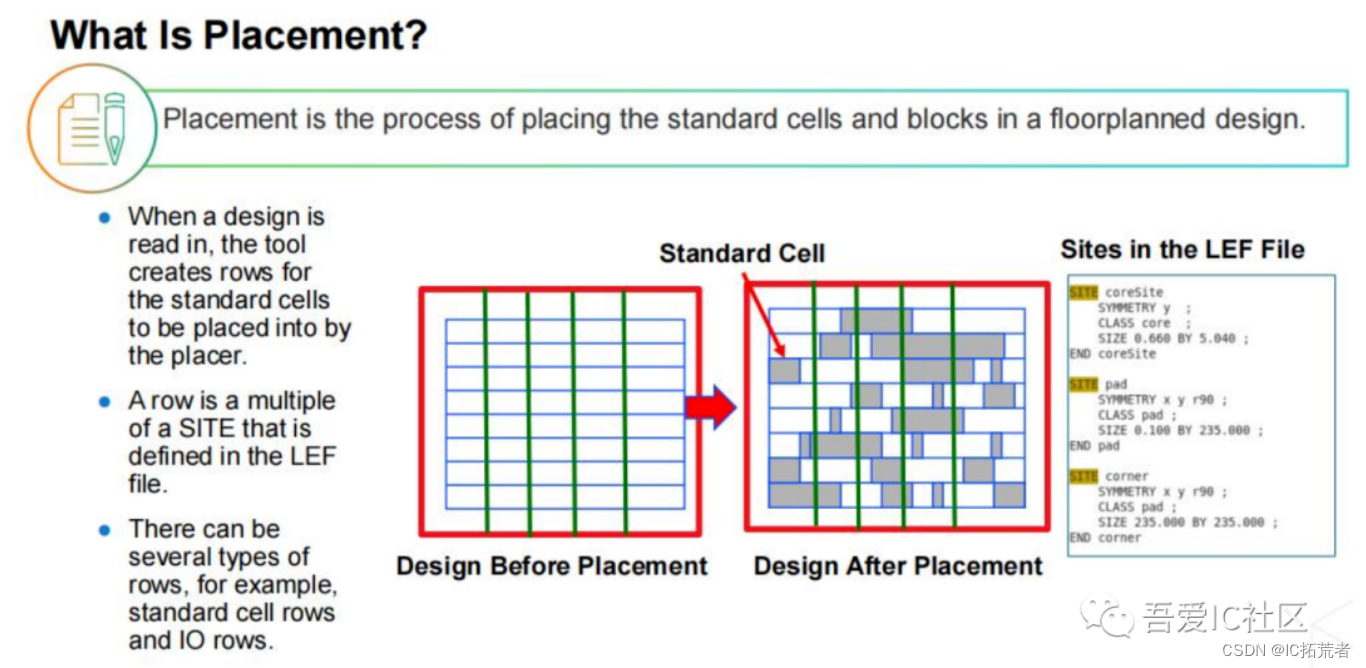
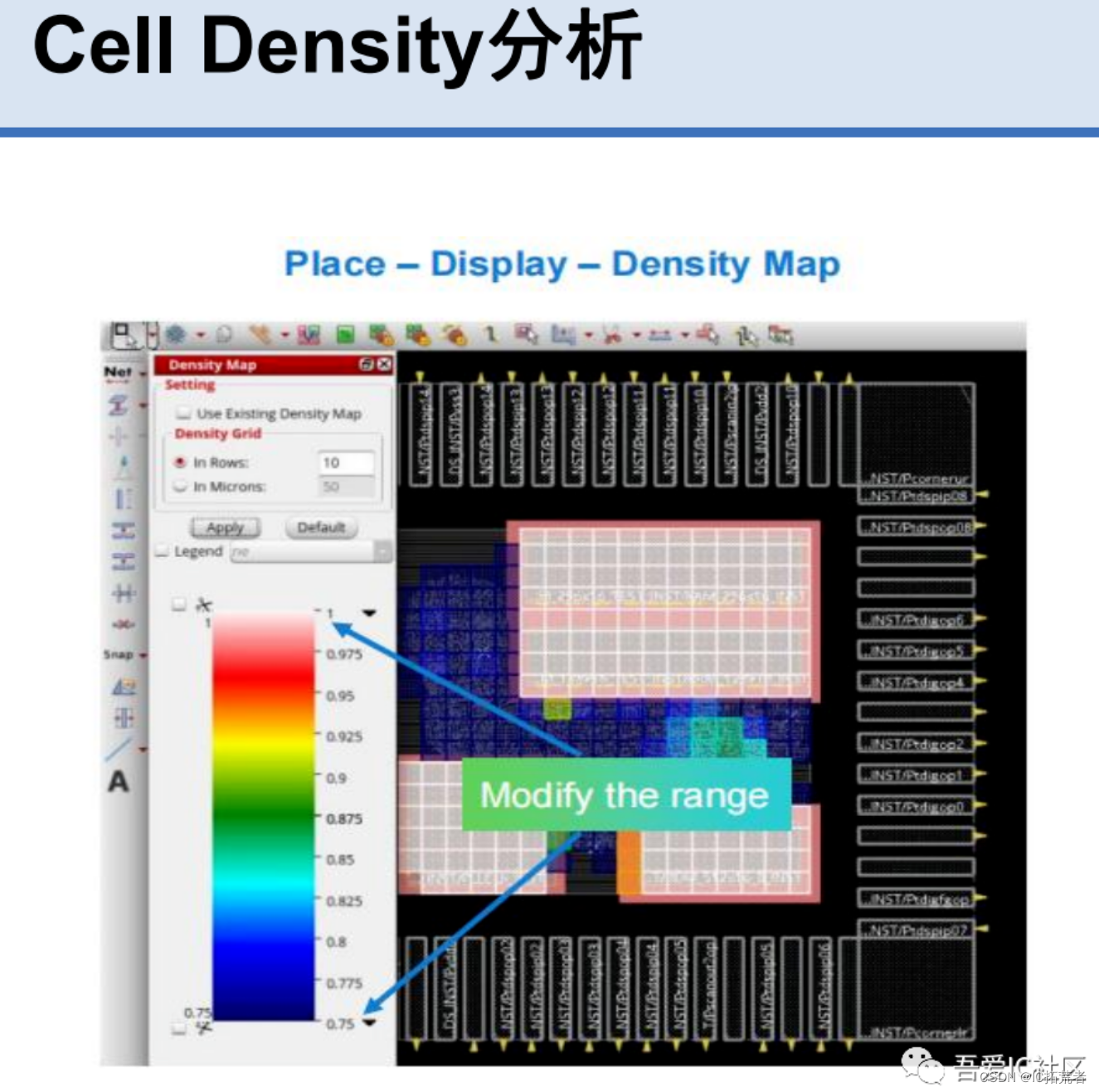
Placement做完我们需要检查timing和physical 方面的质量。比如setup,max transition,max cap,max fanout是否有violation。而且还需要检查设计的congestion和density是否在合理的范围内。


5) Clock Tree Synthesis (时钟树综合)
时钟树综合这个阶段主要任务是对每个clock 长出一颗clock tree出来。这棵树会从时钟的起点一直长到终点。这里的起点通常就是时钟定义的点,终点通常也被称之为sink点,一般默认的sink点有寄存器的CK,memory的CK,IP,子模块的CK时钟pin。
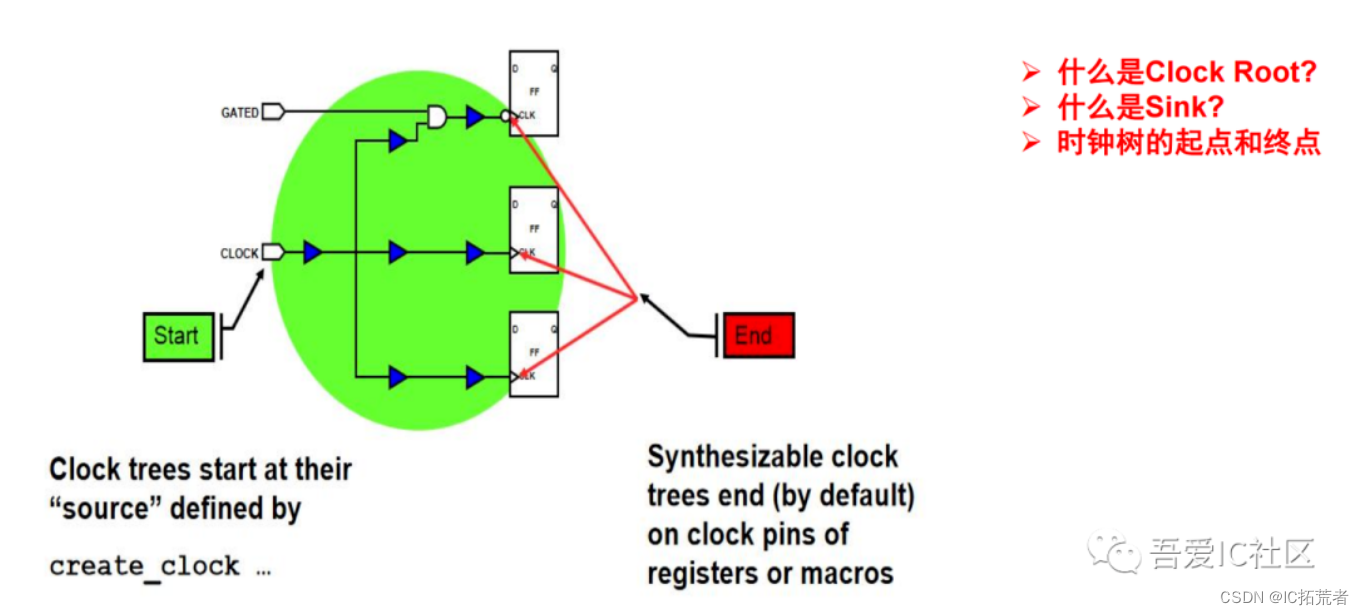
这个阶段需要大家紧紧围绕3W和1H来思考,即What,Why,When和How。这些词是小编自己总结的,可能你们都没听说过。那么它们分别是指什么呢?
What----什么是CTS?
Why-----为什么要做CTS?
When-----什么时候做CTS?
How------怎么做CTS?怎么QA CTS结果?
数字IC后端时钟树综合专题(OCC电路案例分享)
时钟树综合Clock Tree Synthesis专家必备技能(当年年薪百万就靠它)
上面这几个问题,看似很简单,但能真正回答得比较好的工程师不多。CTS这块是数字IC后端岗位招聘时面试官比较喜欢问的一块,因为从应聘者回答问题的广度和深度,就能看出大体上知道候选人的水准了。
Clock Insertion Delay (Clock Tree Latency)最短
Clock tree越长,意味着clock tree级数越长,级数长了,tree上的power就越大。同时,受OCV效应影响,timing就越难meet。
造成Clock tree latency太长的原因有很多。有的是因为Constraint不合理导致的,有的是因为floorplan对CTS不友好导致的。时钟树相关topic之前也分享过好几篇文章,不懂的可以再去查阅下。

以上图为例,如果PLL摆放在右下角,有一个Flop放置在左上角,那么从physical上讲该Flop的clock tree latency将会是最长的一个。由于它要与别的Flop做balance,那么别的寄存器也会被拖长。
【思考题】假设在core中间区域有一堆Flop的tree被拖长后,请问会造成什么影响?
如果将PLL摆放中间位置,并且把左上角的一部分区域打上soft blockage,如下图所示,那么整条clock tree latency将会减少不少。
所以有一个对CTS友好的Floorplan和Placement是非常重要的,它直接决定CTS的Quality。
Clock skew最小
Clock Skew的概念请看这篇文章。为什么要关注Clock Skew? 如何做小CLock Skew? Clock Skew对setup和hold有何影响?
一网打尽时钟树综合Clock Skew
大部分情况下,我们是希望Clock Skew越小越好,因为它对setup和hold是有很大的好处。
但是有的时候我们倒希望认为引入一定的clock skew,比如S家工具的CCD,它可以充分利用前后级的timing margin来改善时序。又比如从IR Drop的角度看,并不希望寄存器同时翻转。
时钟树综合阶段想要把clock tree做到最好,即clock tree的长度做到最短,clock skew做到最小,需要后端工程师能够自己来分析时钟树结构,并根据design的spec来编写一个约束文件,引导工具如何长时钟树。
很多SOC中,时钟都有几百个。由于PLL的个数有限,因此很多设计都有时钟选择和切换电路。因此,针对复杂的时钟结构,工具可能很难做到符合我们预期的时钟树(clock skew 和clock latency)。这步非常关键且非常重要,也是衡量一个数字后端工程师能力的重要指标。主要工作如下:
clock tree building constraint的编写
长时钟树需要设置的timing drc等
时钟树用于长tree的buffer或者inverter种类选择
设定clock net 的non-default rule
如何做shielding
为了解决广大工程师仅仅会跑CTS,不会从根源上理解clock tree,做出一个最好的clock tree,社区第一期复杂时钟结构设计的时钟树综合课程将于1月中正式开班,目前已经完成学员招募工作。有兴趣的同学,可以开始预约第二期的课程。
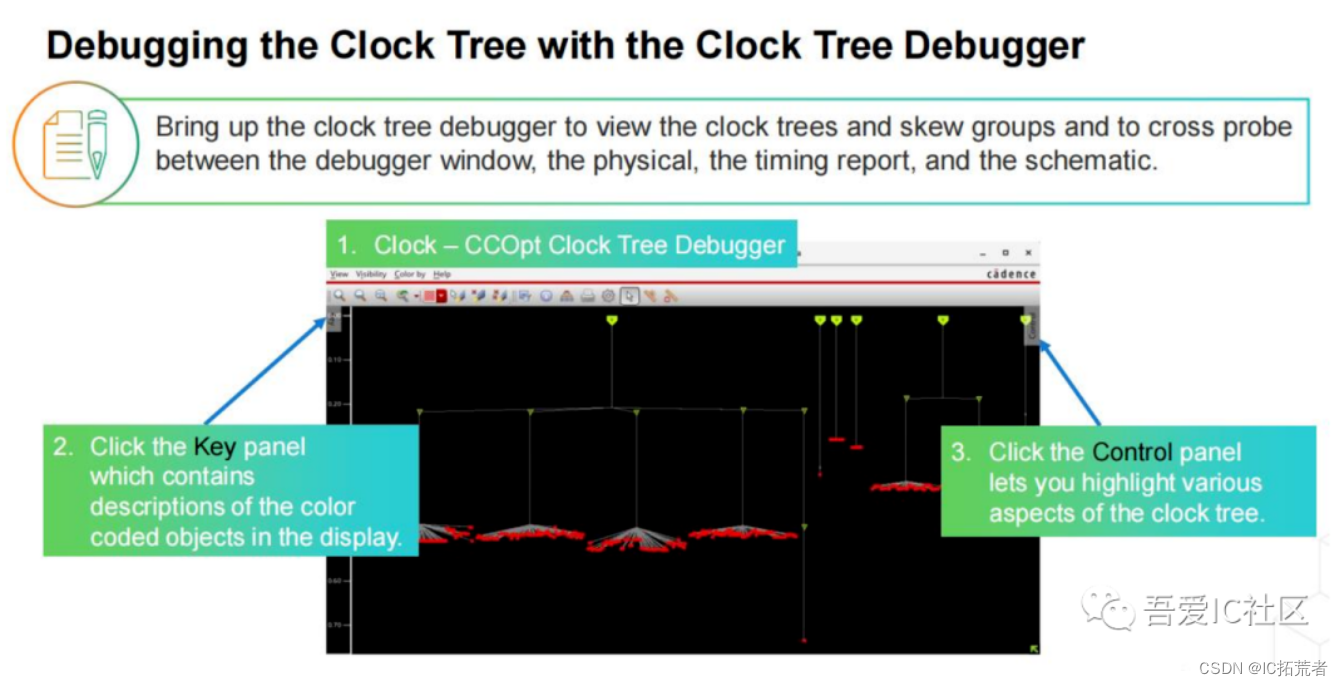
对于初学者,可以使用PR工具Innovus自带的Clock Tree Debugger来分析clock tree的合理性。
6)Post-CTS Timing optimization (时钟树综合后的时序优化)
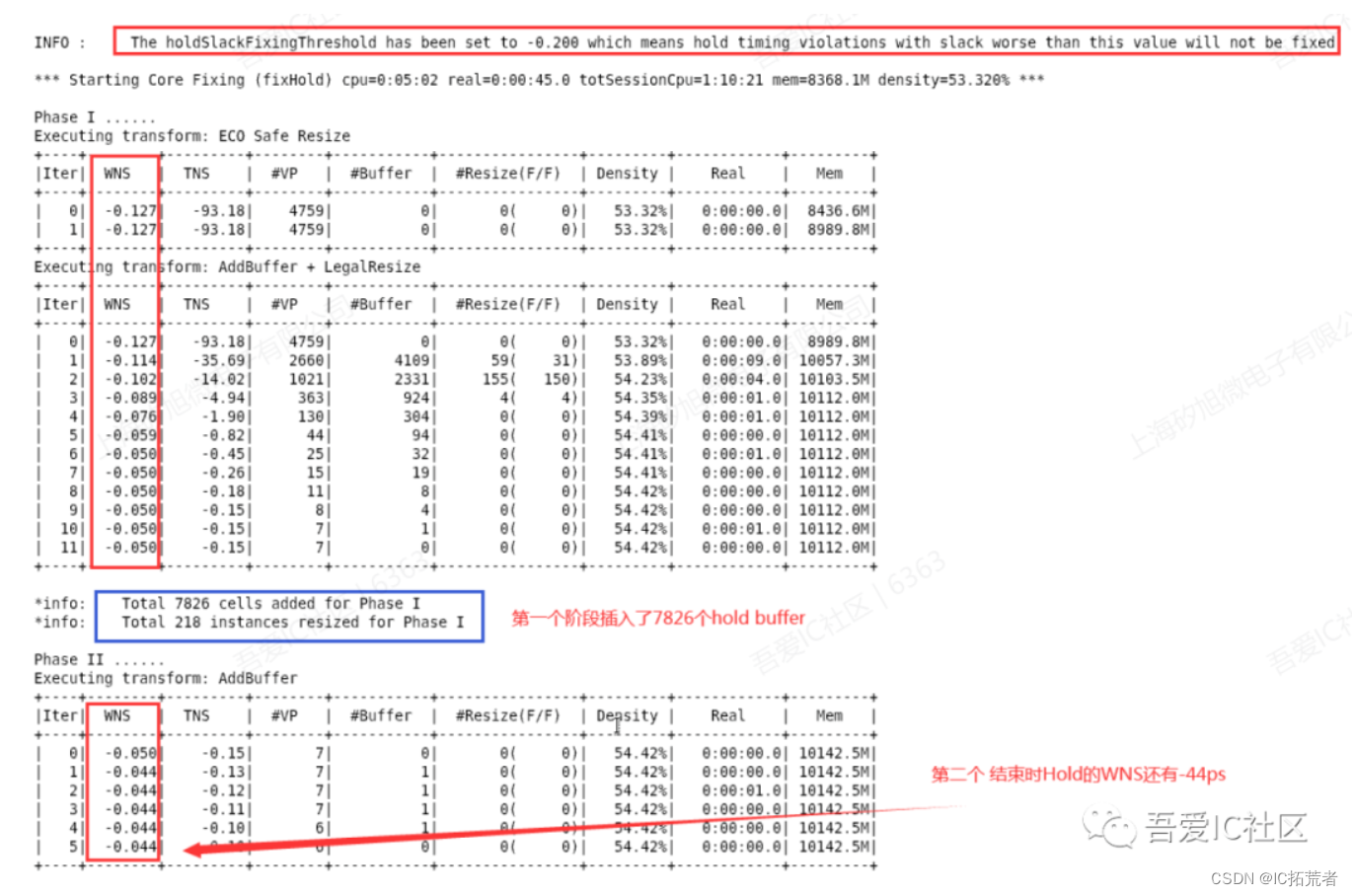
在前面几个步骤工作做的比较好的情况下(data path已经优化到位,clock tree比较balance),这个步骤我们主要就focus on hold time 的时序上了。
对于setup和hold的优化,我们可以使用工具自带的命令来优化。
OptDesign -setup (优化hold就带上-hold选项)
值得注意的是在修复hold time violation前一定要查看hold violation fixing之前的hold time是否合理,避免工具乱插hold buffer引起后续的routing和density问题。

7) Route& Route_opt (绕线和时序优化)
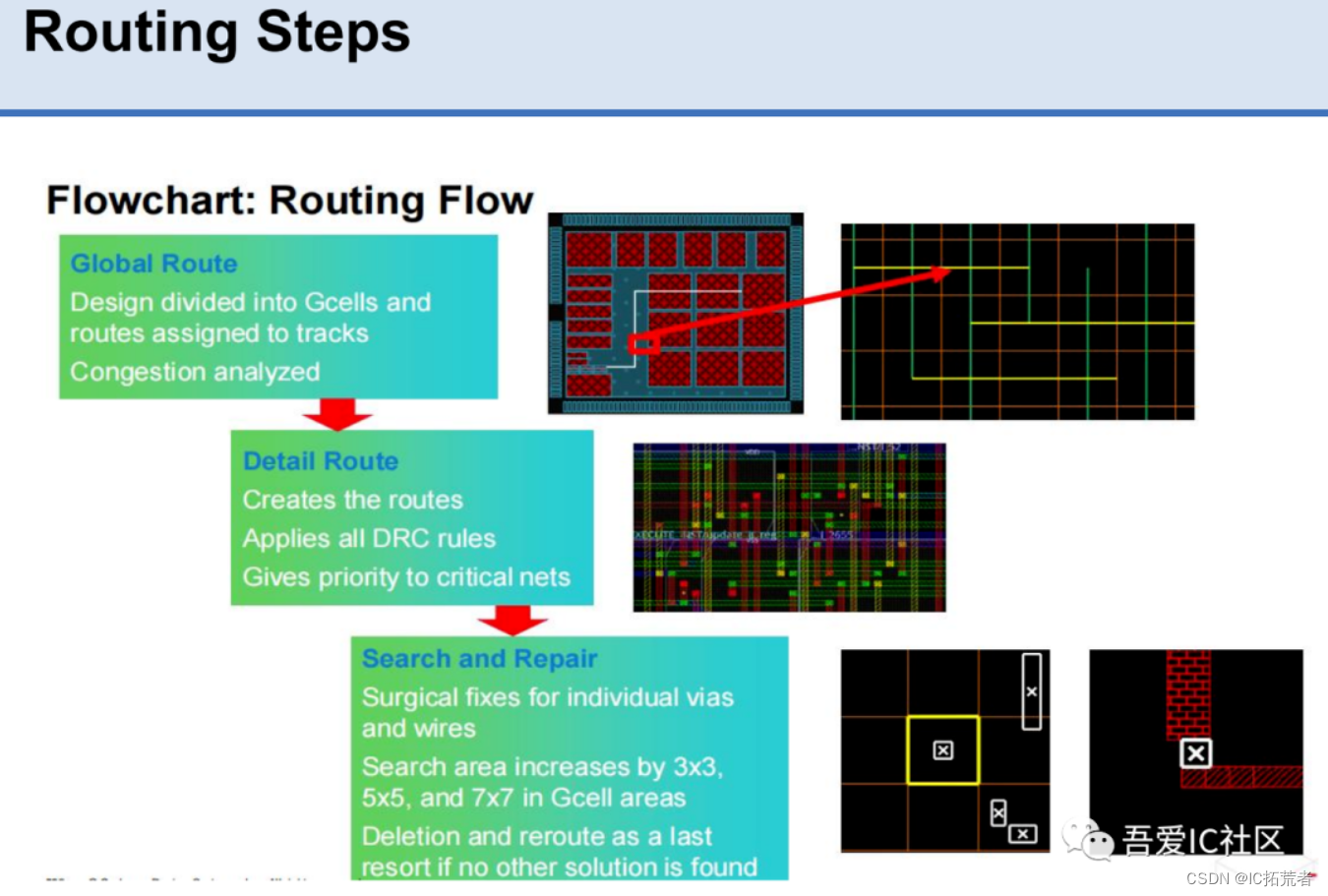
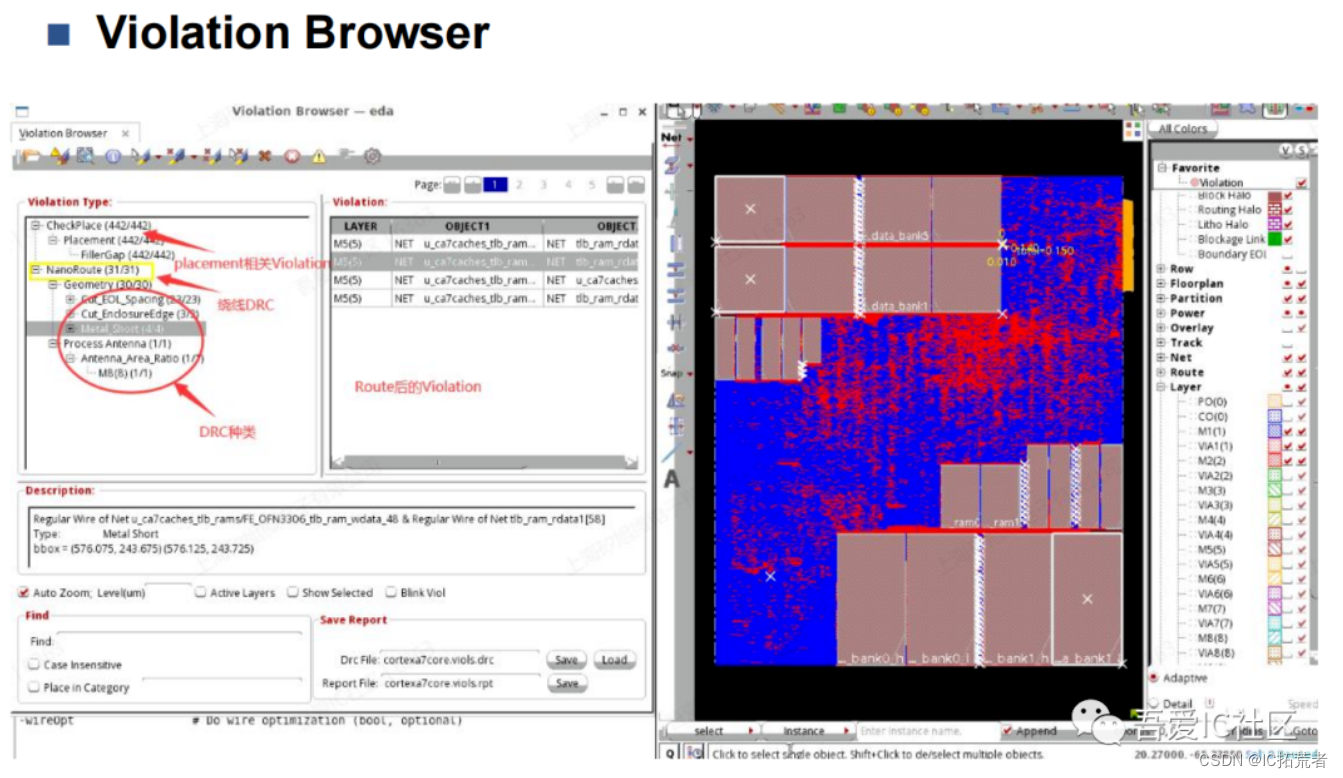
Routing(布线)是集成电路设计流程中的一个关键步骤,它负责实现逻辑元件之间的物理连接。数字IC后端工程师在EDA工具做完route后一定要学会分析DRC violation并能根据工具提示的信息进行DRC Violation的修复。

整个Routing过程可以分成Global Route(包括Track assignment分配),Detail Routing以及search and repair等子步骤。
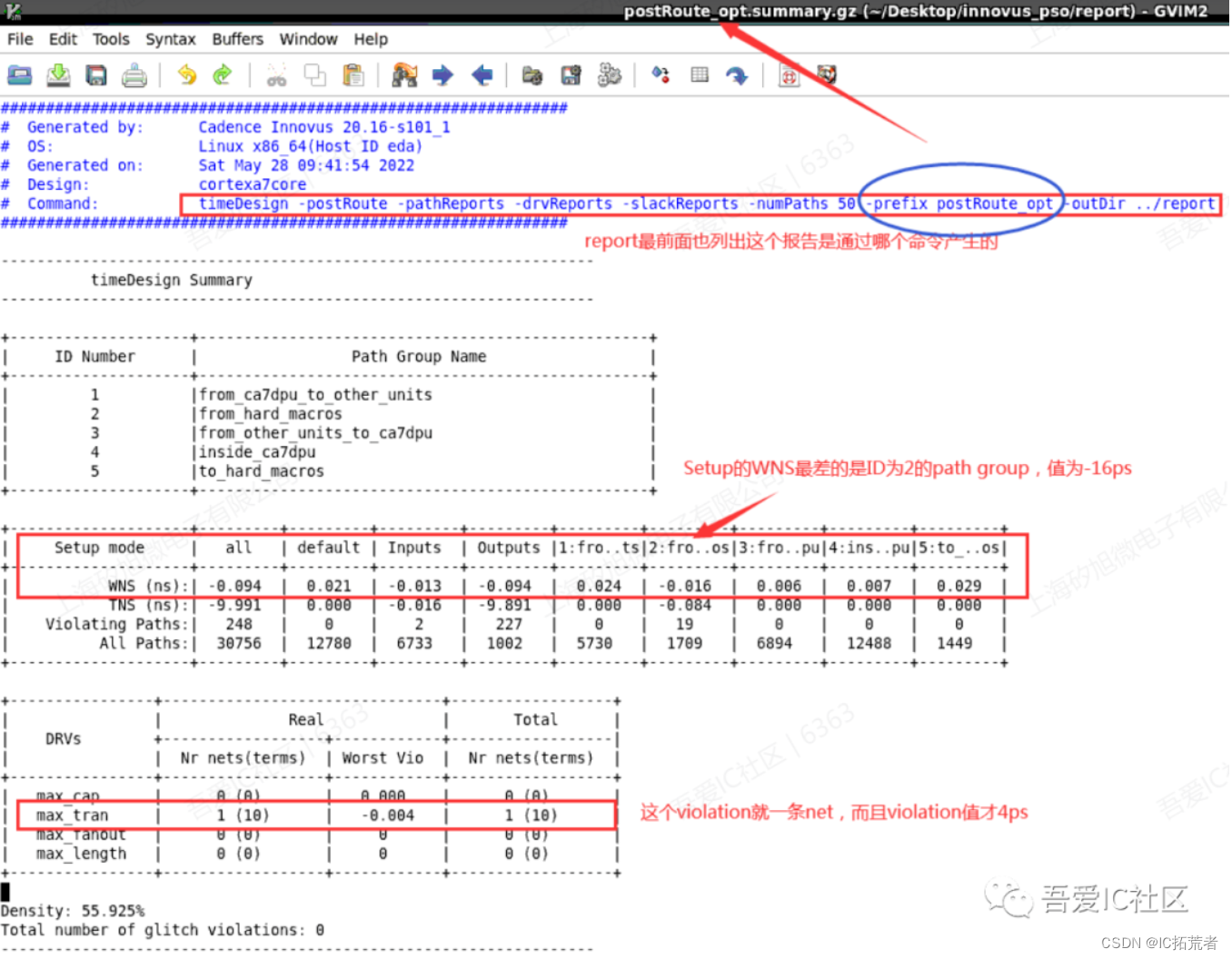
Route结束后我们需要查看验收时序和Routing DRC的情况。timing分析主要分析setup,hold,max transition,max cap, max fanout等。
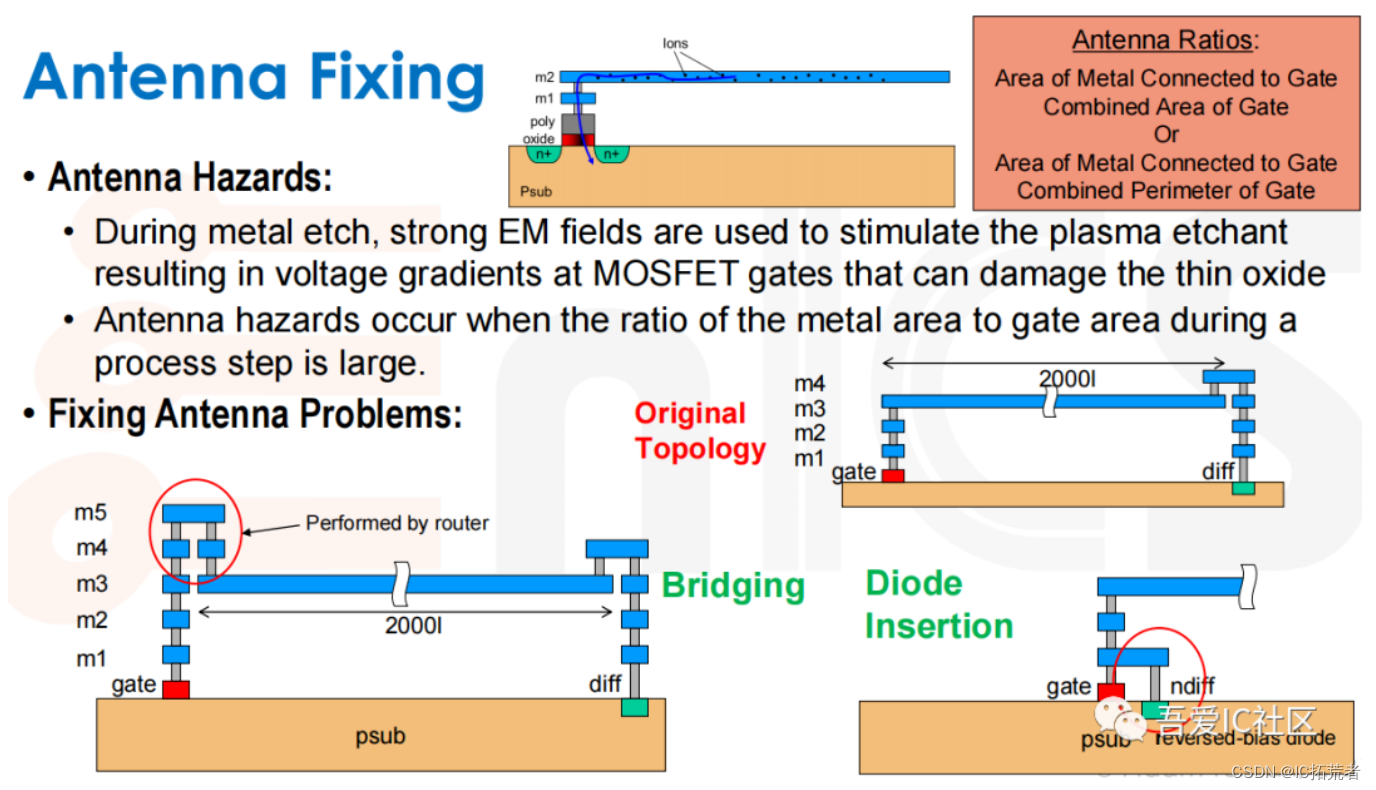
DRC主要看violation browser中的NanoRoute的DRC Violation和Process Antenna violation。
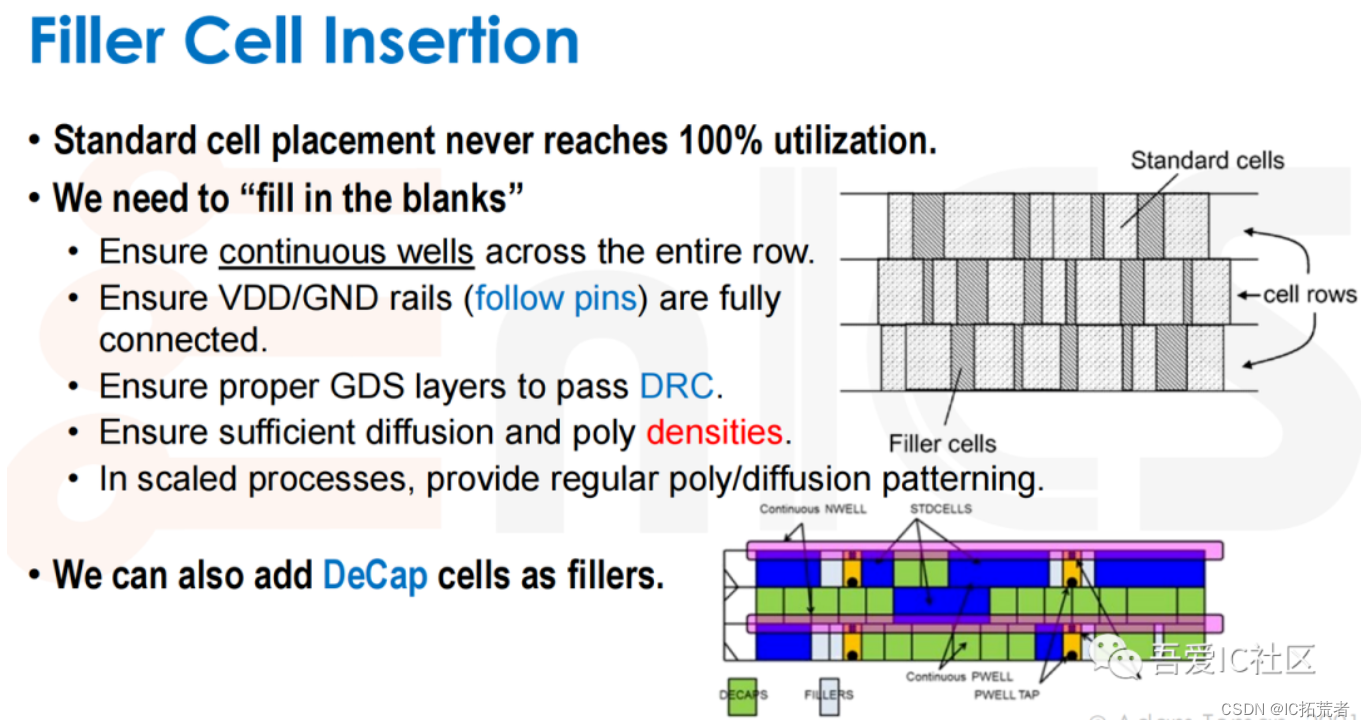
8)ChipFinish (插Filler,ECO Filler,ECO Cell,写出设计相关数据)
绕线结束后我们还需要做一步chipfinish的工作。这步主要任务是插DCAP cell,Filler cell以及绕线后的相关数据输出。这些数据的输出是为了后续的Starrc寄生参数提取,PrimeTime的timing signoff以及Calibre的物理验证。
三.互连线inter-connect net RC Extraction抽取
目前业界公认的寄生参数提取工具就是S家的Starrc。所以咱们训练营项目也是采用Starrc来进行互连线RC的抽取。
很多人可能会觉得PR中不是也抽过RC了,能不能直接在PR工具中直接写出互连线RC的spef文件呢?
再次强调PR是物理实现,类似于施工队的乙方(以盖房子为例)。一栋房子施工完毕后,肯定会有专门的检测机构以及验收部门来做工程质量以及交付条件的验收。施工队自己肯定无法自己来验收质量。
在数字IC后端实现中,Starrc就是专门负责对设计互连线进行参数提取的第三方工具,PrimeTime就是专门负责验收PR实现Timing的signoff工具。只有在PT中通过验收后,我们才能拿着实现的数据去Tapeout(流片)。
Starrc提供了两种方式做RC的抽取。第一种是Milkyway的Extraction Flow,第二种是LEF+DEF的Extraction Flow。我们训练营项目采用的是第二种flow,这个flow也是实际项目中普遍采用的Flow。
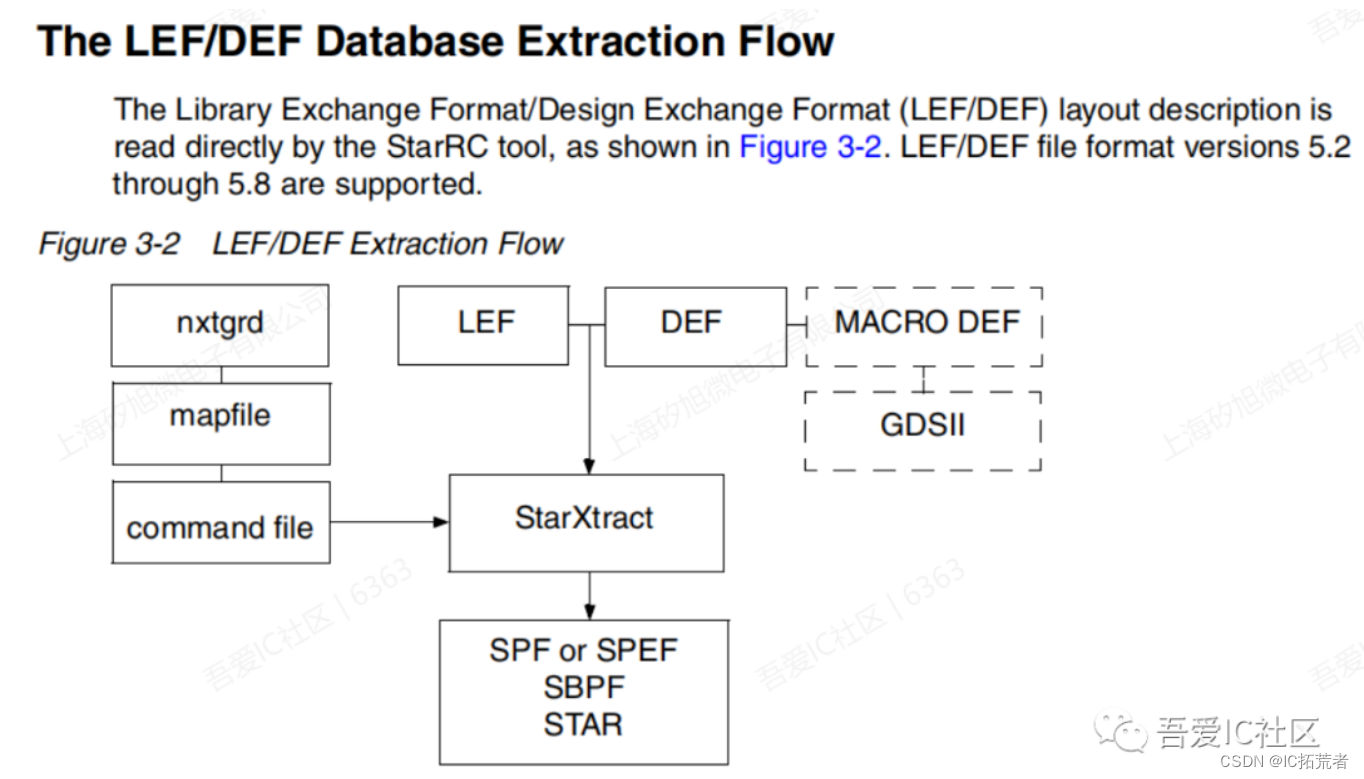


这里需要提醒的是如果是芯片级的RC抽取,还需要带入dummy gds来做RC的抽取。所以当我们希望带着Dummy进行RC抽取,我们需要在METAL_FILL_GDS_FILE这行填入带Dummy的GDS文件。
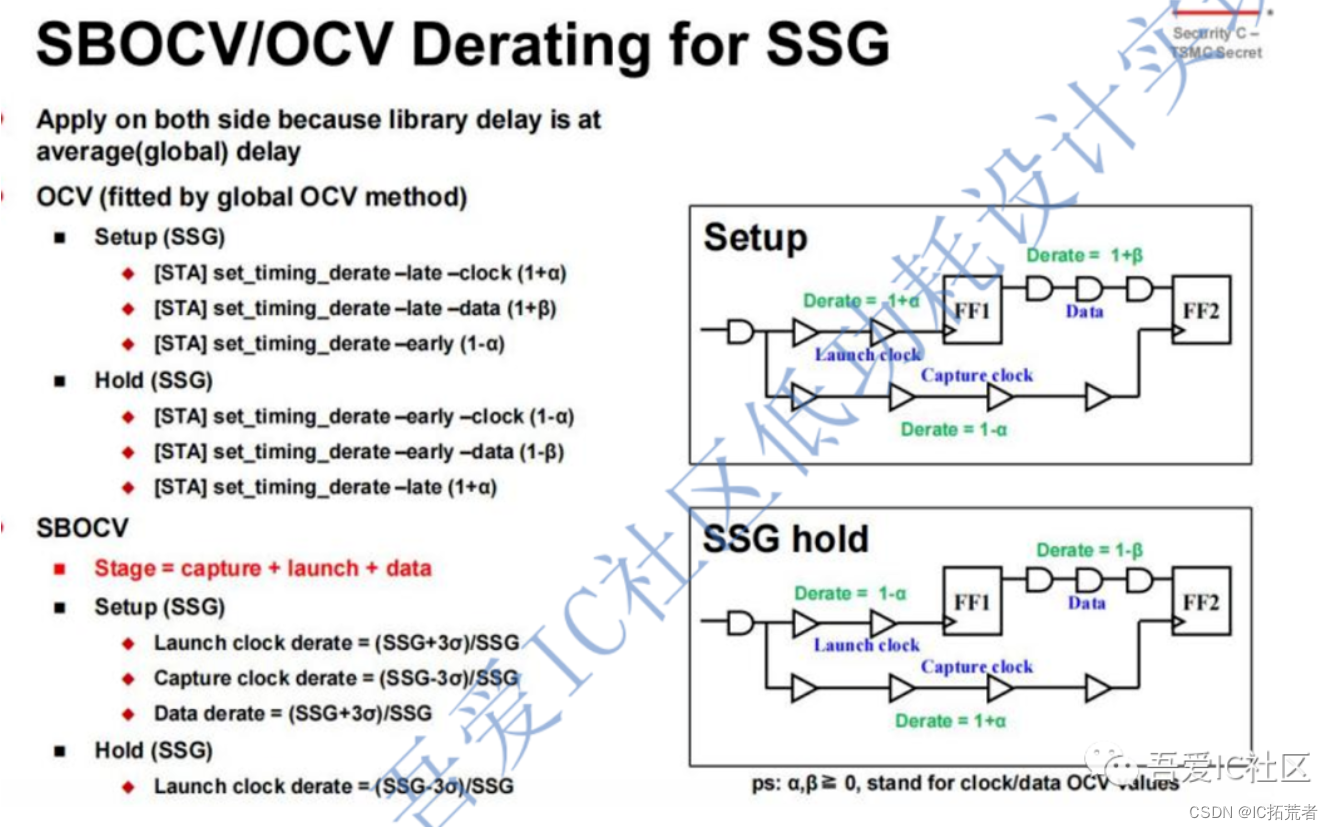
四.Static Timing Analysis (STA Timing Signoff)
芯片Tapeout前的STA分析这个步骤主要工作就是验收PR工具输出的实现结果是否满足时序Timing的验收标准。这里的标准包括setup,hold,timing drv,removal,recovery等timing。当然这个阶段的signoff环境,比如OCV的timing derate,clock uncertainty等参数需要严格按照foundary的signoff建议来设置。
PT检查时序主要是通过加载时序库lib,读入设计绕线后的Netlist,读入Starrc生成的寄生参数spef文件进行互连线的RC反标,读入设计约束,从而让PT来计算设计中所有cell的delay和net delay。
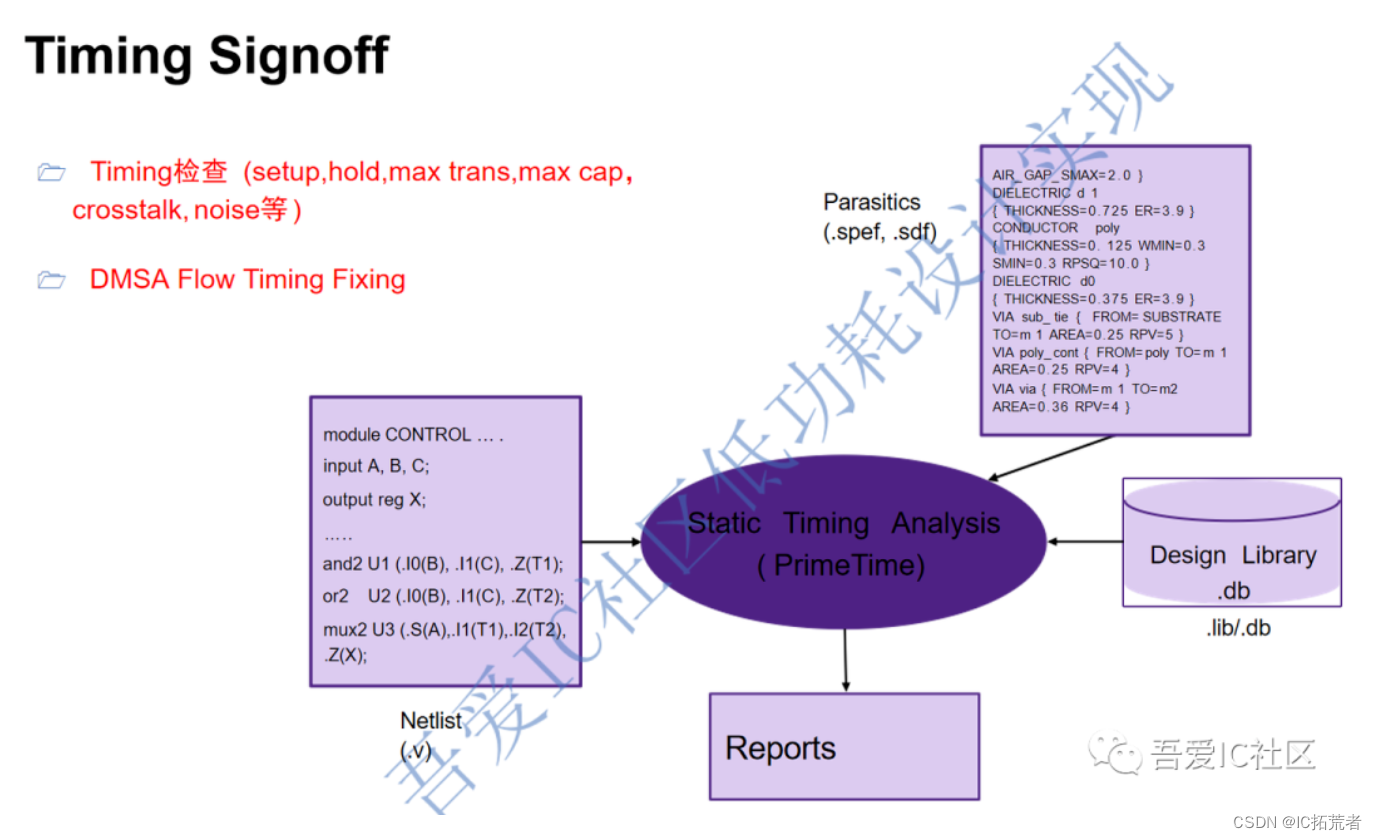
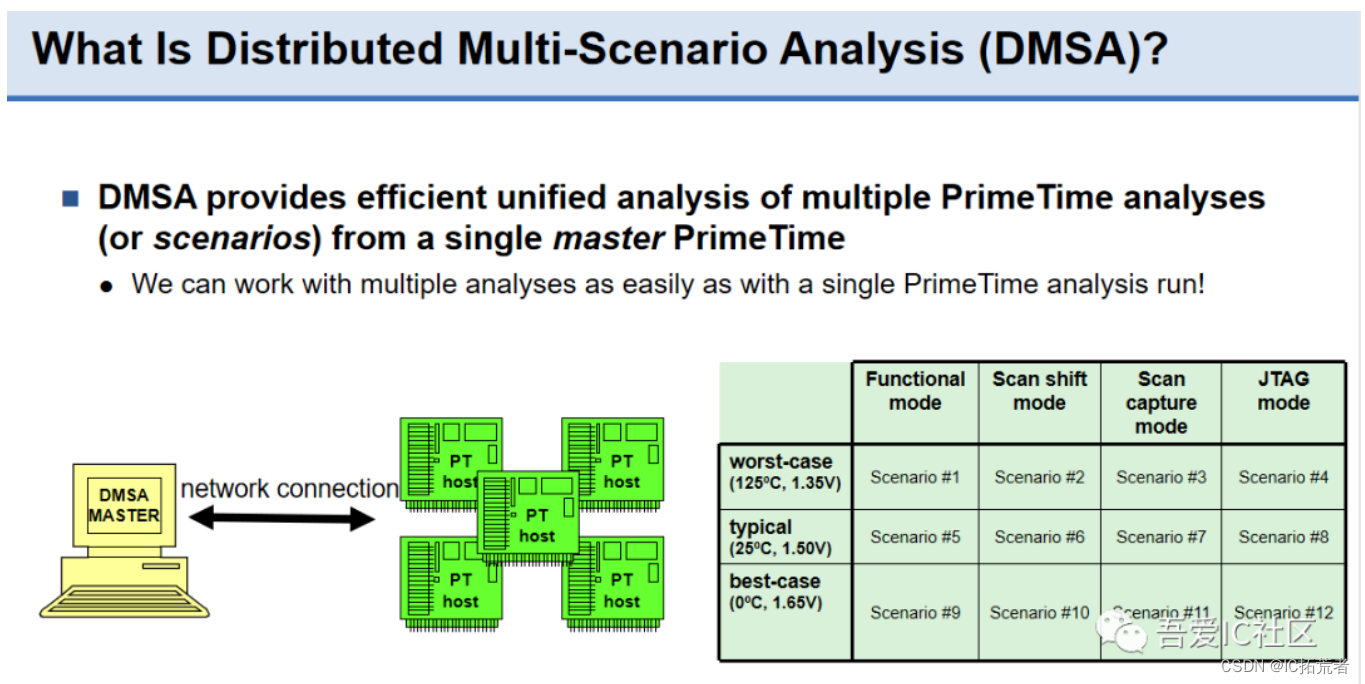
PrimeTime跑完之后一定存在一些setup,hold ,max transition等violation。由于实际项目往往规模比较大,而且需要检查的corner也比较多。我们不可能一条条手工去修复。所以PT提供了DMSA可以根据多个corner的PT session来自动修复timing。
五.Physical Verification (物理验证)
数字IC芯片设计阶段的物理验证这步主要包括DRC检查,ERC检查以及LVS检查等。目前IC业界公认的物理signoff工具为mentor的calibre物理验证工具。

Calibre DRC
Calibre DRC检查修复步骤如下:
1)PR写出设计的GDS(在PR中chipfinish这步完成)
2)Merge GDS
3)Calibre DRC Run
4)Calibre DRC检查
5)将Calibre DRC结果导入PR工具分析并修复
6)修复后PR中保存database
Calibre LVS
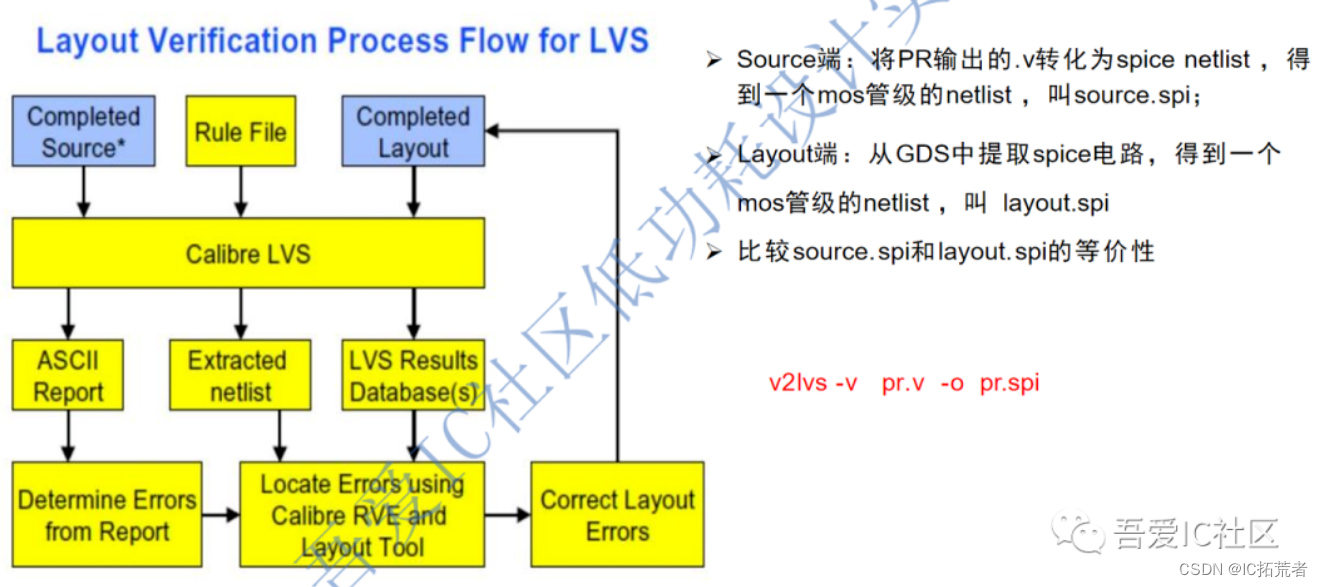
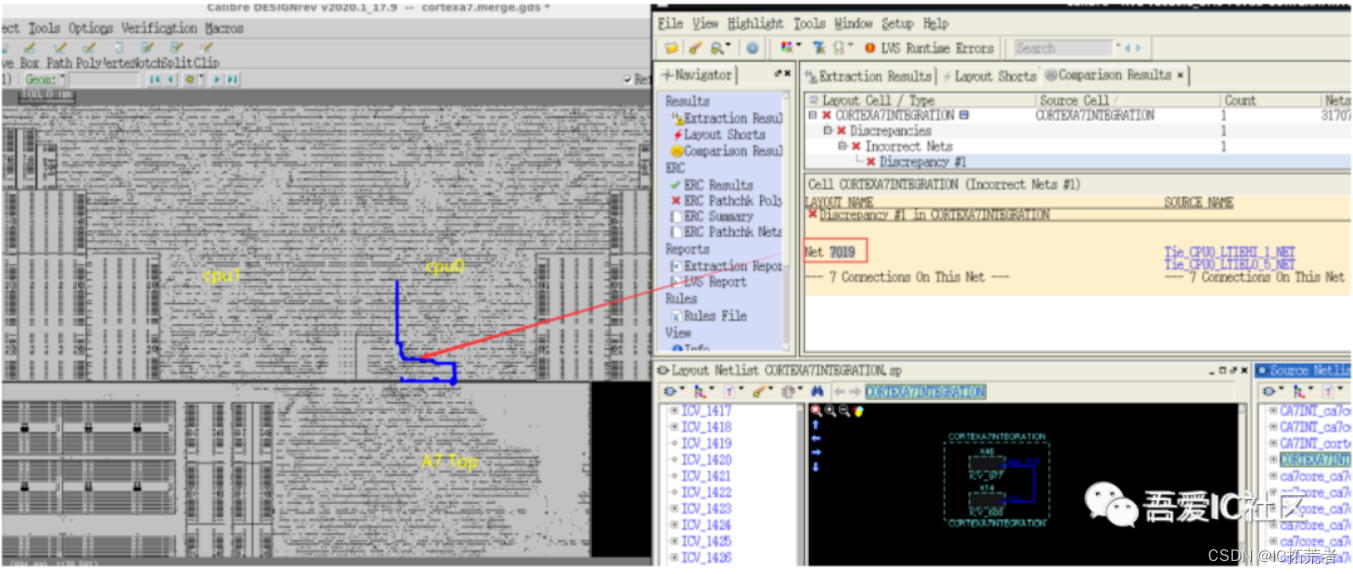
数字IC后端设计实现中的物理验证阶段Calibre LVS是将PR完成后写出来的版图GDS和PR 后的netlist做一个比对的过程。具体的Calibre LVS的流程和详细的步骤如下图所示。
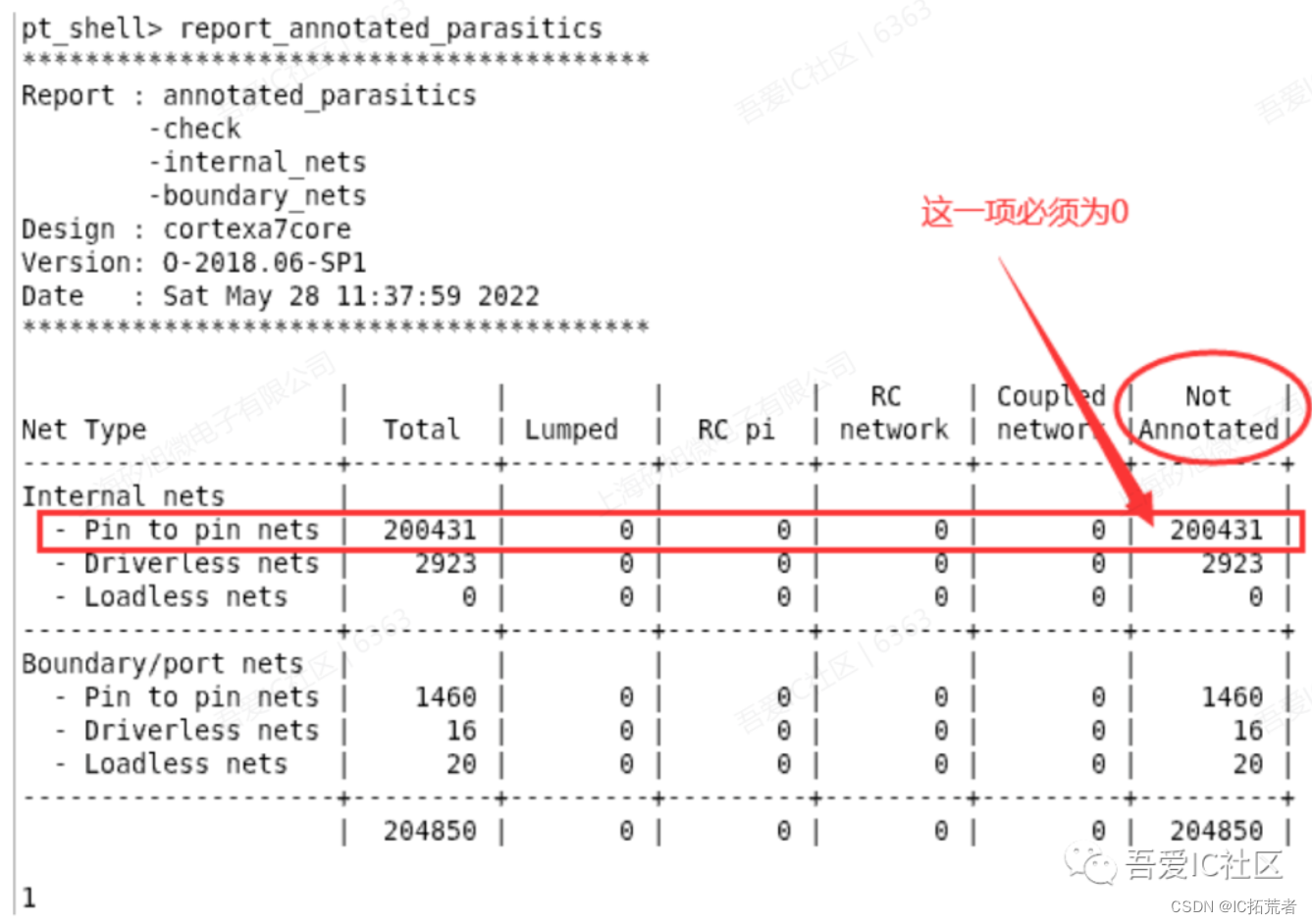
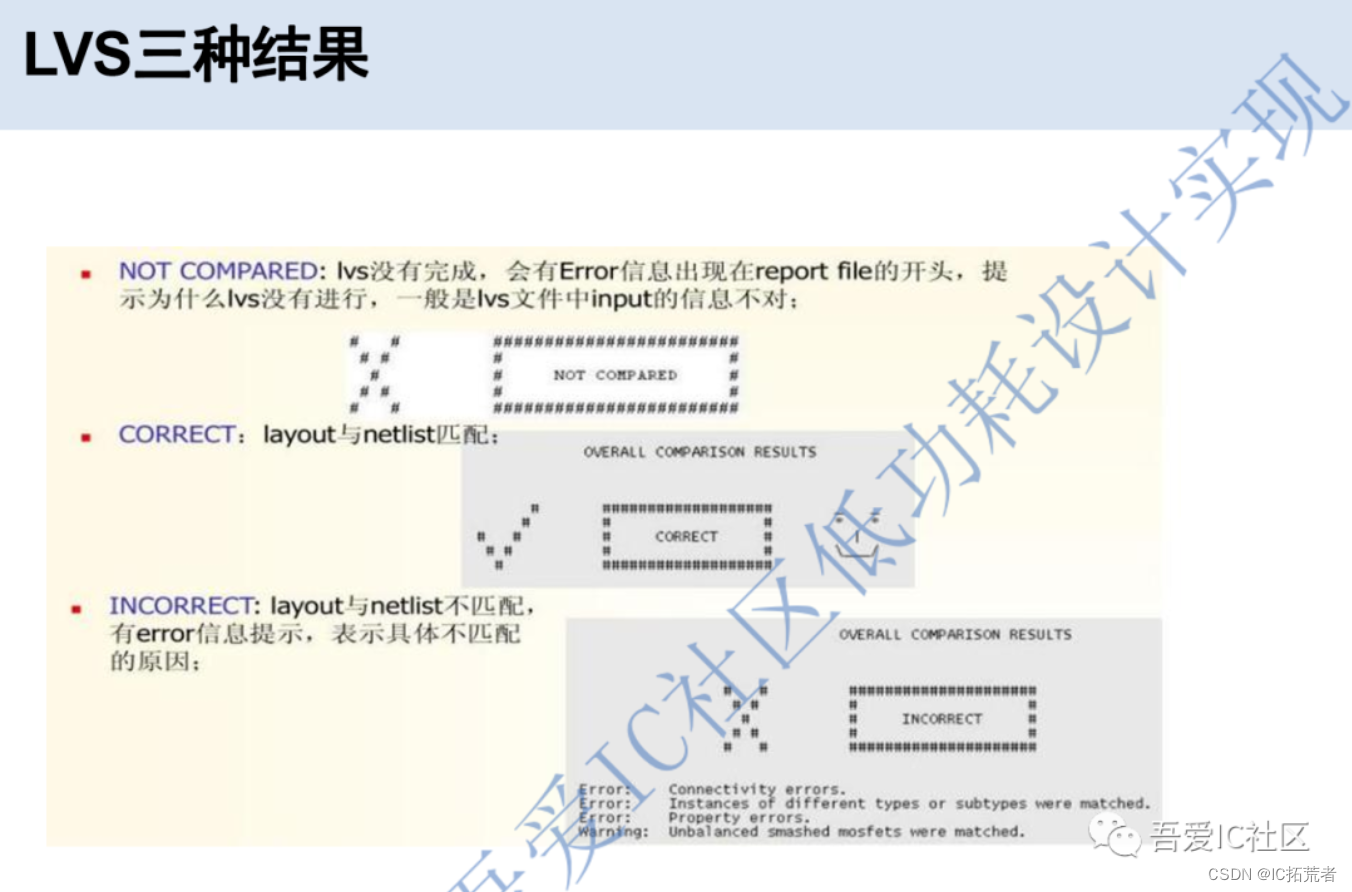
Calibre LVS的结果有三种类型,分别是NOT COMPARED,CORRECT和INCORRECT。第一种是Calibre工具没有完成LVS检查工作,大部分是因为source netlist存在部分没有定义的device。而LVS INCORRECT则需要根据calibre rve分析结果来进一步debug,并最终修复掉LVS错误。
Calibre ERC
Calibre ERC全称为electrical rule checking,翻译为电气规则检查。检测的是GDS版图中是否存在电学连接问题。
1)MOS的gate不能直接连supply
2)MOS的gate不能floating
3)一个cell的driver最多一个(Multi-Driver)
- NWELL,PWELL (P衬底)不能floating
5)NWELL----> Power
6)PWELL-----> Ground
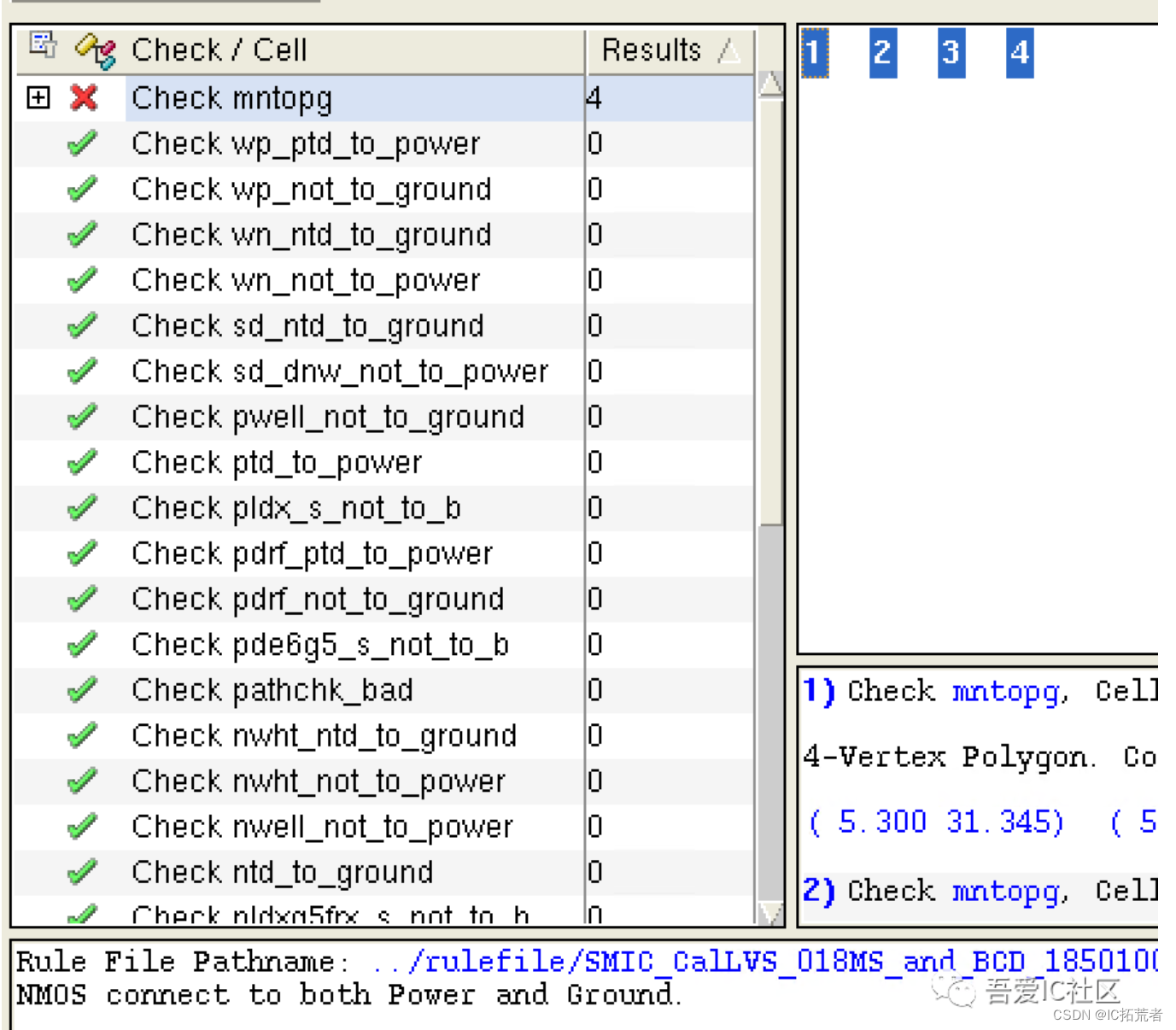
比如下图显示的即为ERC的Violation——NMOS connect to both power and ground。
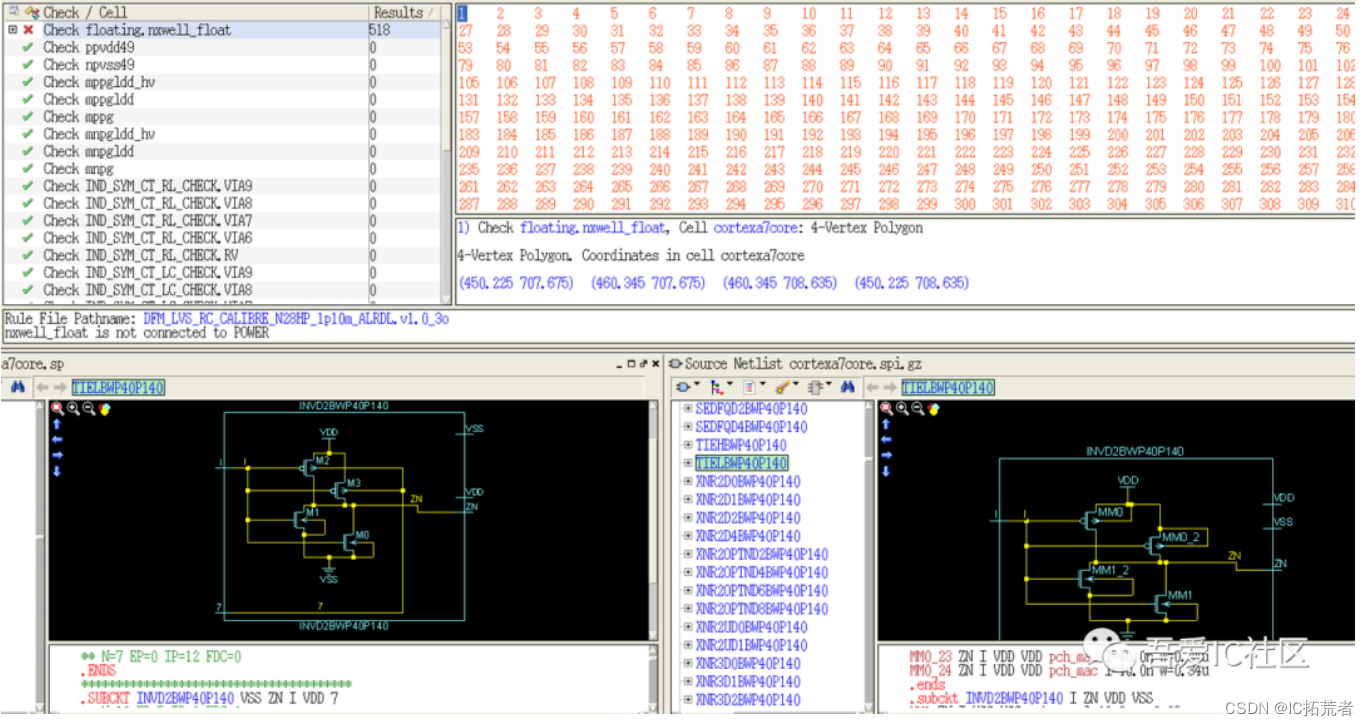
还有数字IC后端物理验证ERC检查时也会经常发现有nwell floating的情况。具体体现在calibre erc report中如下图所示。
Calibre PERC
在tapeout前,我们还会跑full chip的PERC,主要是用来检查整芯片的ESD,LatchUP。一般针对特定工艺,foundary已经定制了一些golden的rule供客户进行通用Perc检查。当然很多大厂还会根据自己的实际需求,额外开发一些perc rule来做更多的检查。
这里重点提下,P2P检查是指Point-to-point resistance,即点对点的电阻检查。比如Power Clamp检查时需要控制点对点的电阻,确保ESD到来时能够及时泄放掉 。

六.Power Signoff (Power Integrity &Reliability)
数字IC设计实现的Power Signoff主要分PTPX的power分析,Redhawk(Voltus)的IR drop分析和EM电迁移分析。
1)PTPX功耗分析
PTPX的Flow如下图所示。它的flow和PrimeTime类似,只不多这里需要读入IC前端工程师提供的VCD波形文件。
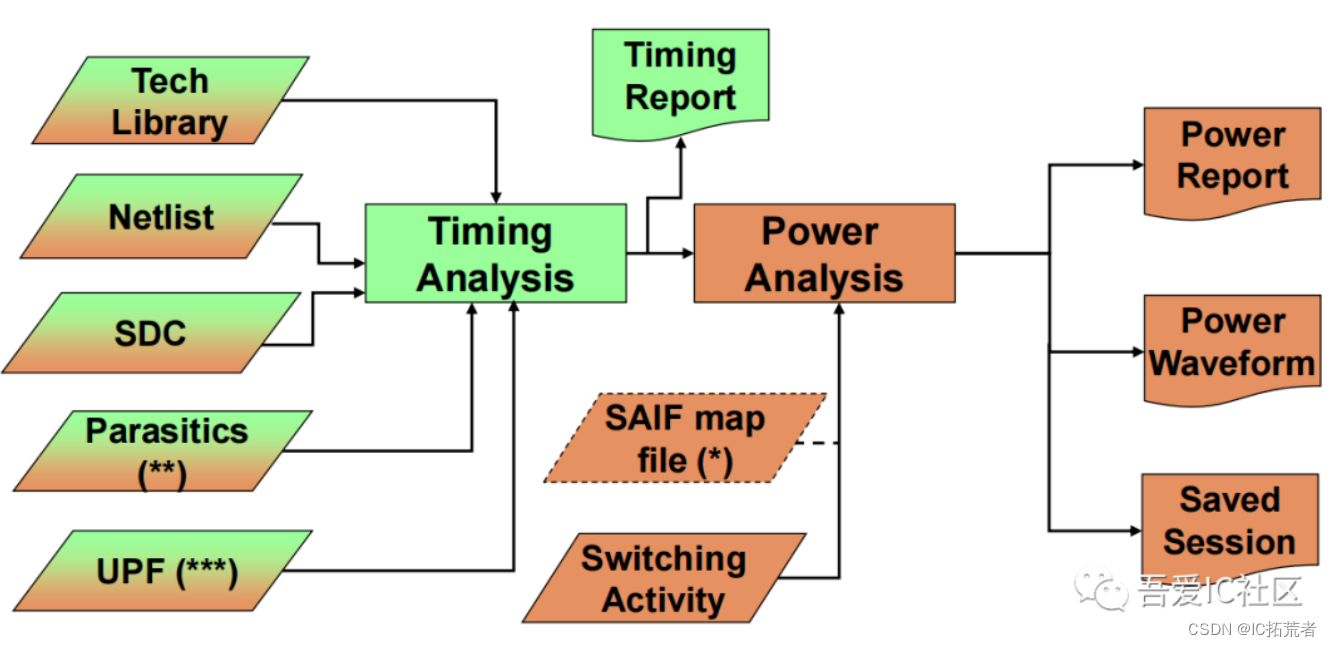
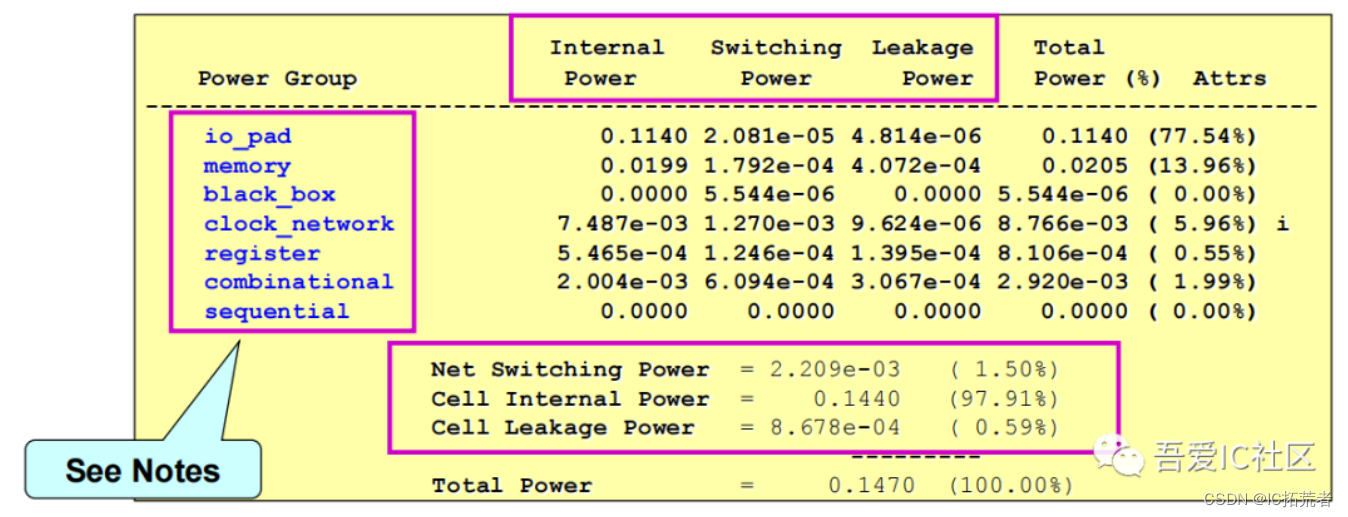
在PTPX中我们可以通过report_power来报告出整个design或芯片的功耗。具体报告如下图所示。在这个报告中我们不仅可以看到总功耗数值,还可以看到各个功耗组成部分所占的功耗占比,比如clock tree和memory的功耗占总功耗的占比。从而我们可以有针对性对占比比较大的部分做功耗的优化。
2)IR Drop分析
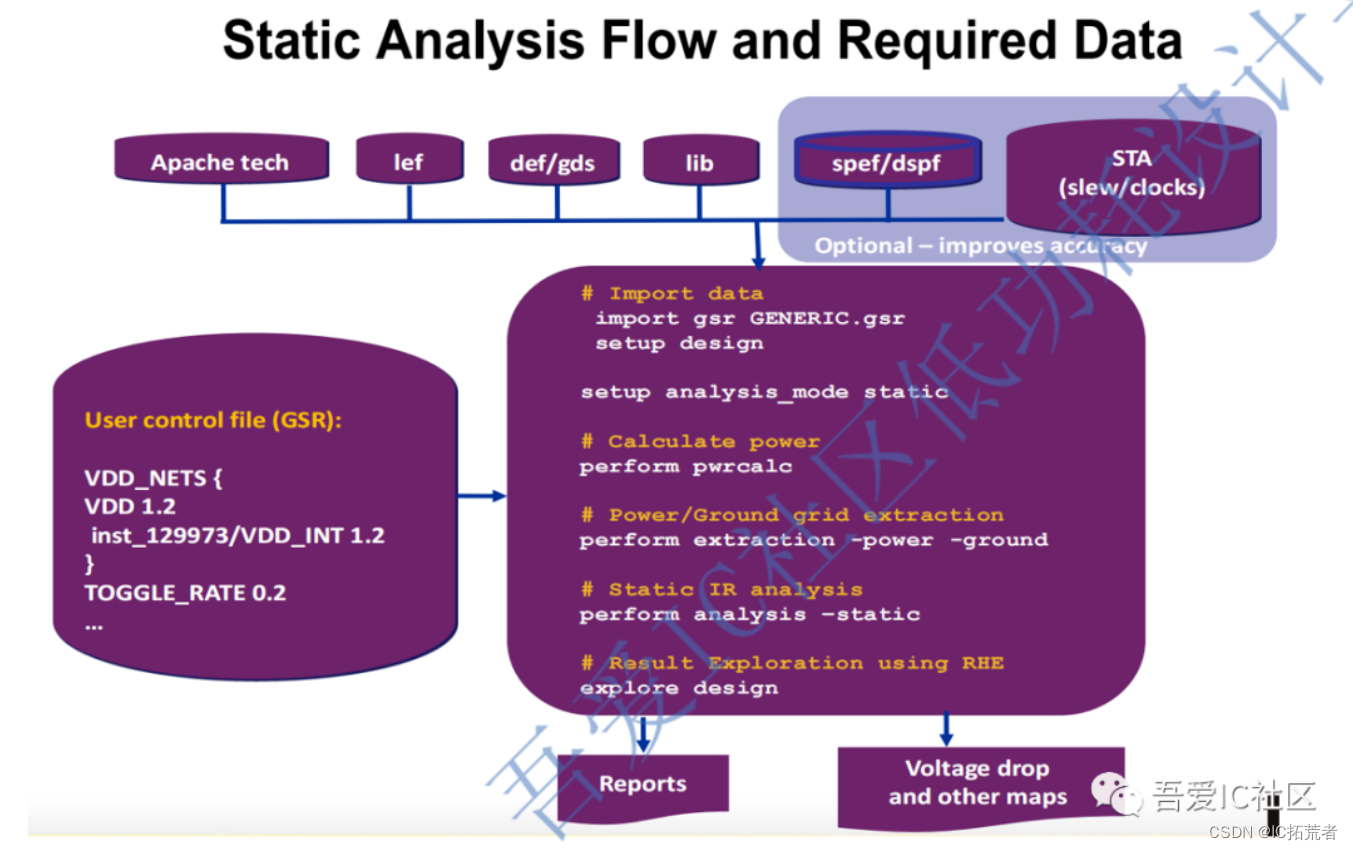
IR Drop分析主要有两种,第一种是静态Static IR Drop分析,第二种事动态Dynmatic IR Drop分析。
静态IR drop现象产生的原因主要是电源网络的金属连线的分压,是由于金属连线的自身电阻分压造成的。电流经过内部电源连线的时候产生电源压降。所以静态IR drop主要跟电源网络的结构和连线细节有关。因此静态IR drop主要考虑电阻效应,分析电阻的影响即可。
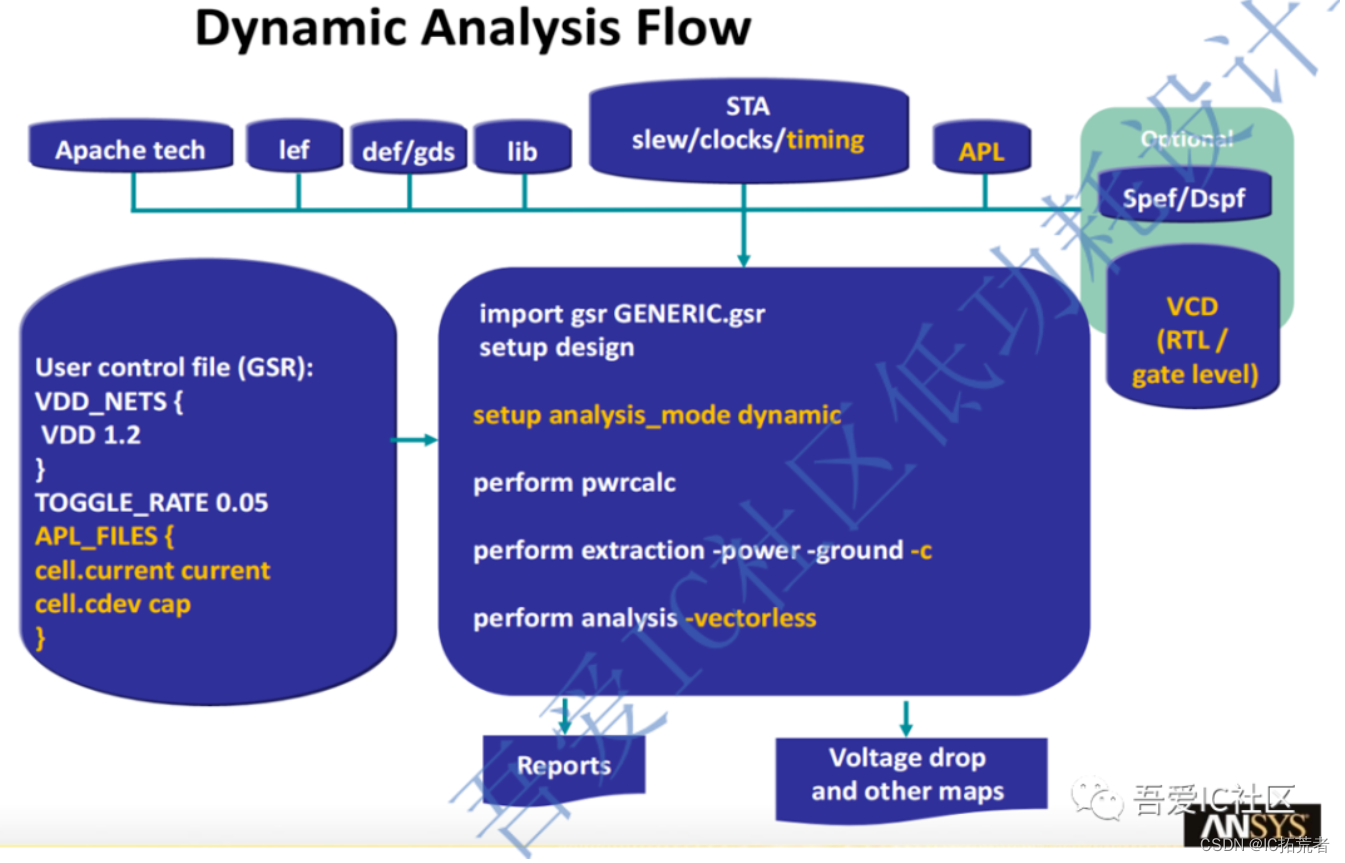
动态IR drop是电源在电路开关切换的时候电流波动引起的电压压降。这种现象产生在时钟的触发沿,时钟沿跳变不仅带来自身的大量晶体管开关,同时带来组合逻辑电路的跳变,往往在短时间内在整个芯片上产生很大的电流,这个瞬间的大电流引起了IR drop现象。同时开关的晶体管数量越多,越容易触发动态IR drop现象。
静态IR Drop分析的流程和所需要的数据如下图所示。
动态IR Drop分析的流程如下图所示。动态IR drop又分成两种,第一种是vectorless ir drop,第二种是base VCD的ir drop分析。
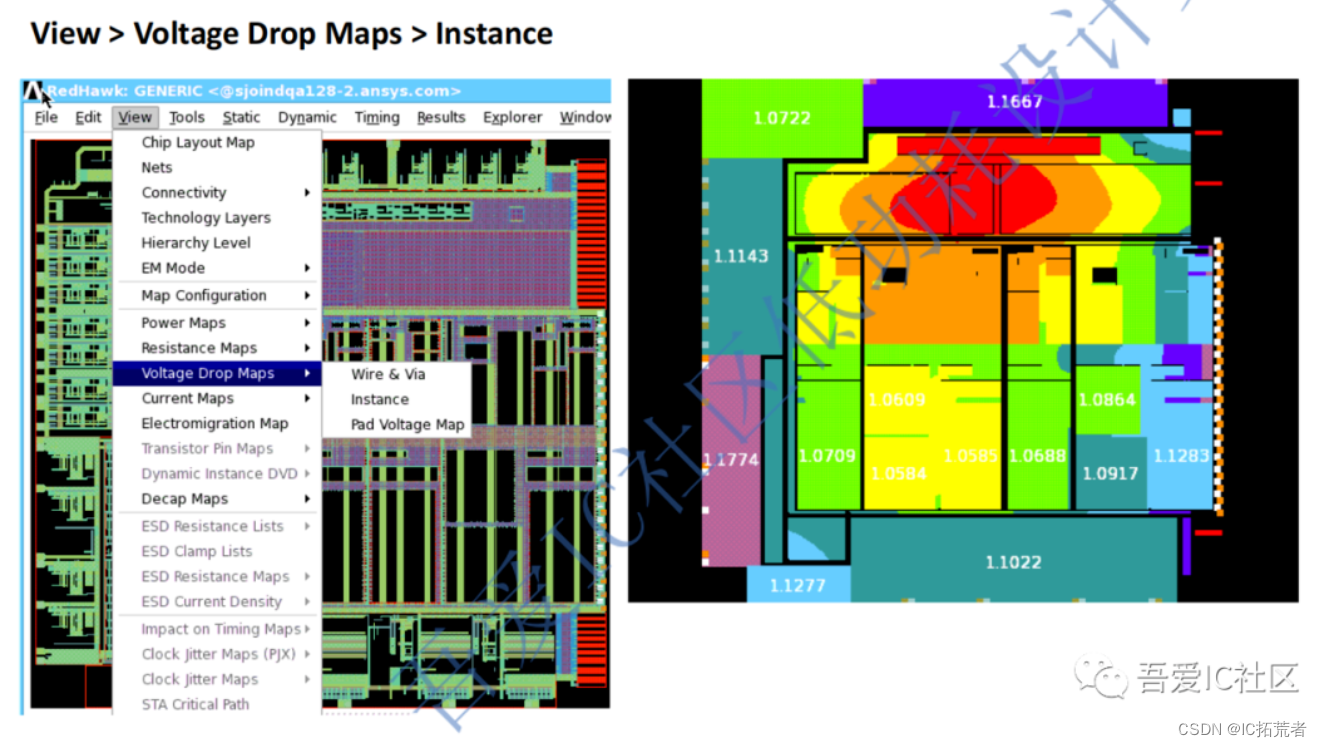
IR Drop跑完后我们可以通过查看Voltage Drop map来查看整个芯片的IR drop情况。然后再通过Minimum Resistance Path Tracing来找到电源网络供电路径的弱点weakness点。

备注:Redhawk的adsRpt下面会有一堆的report,那些report都可以辅助我们找出设计中供电的弱点,电阻偏大的点以及pg pin floating的点等等。
3)EM分析
EM又分成Power EM和Signal EM两种。
EM大小(违例百分比,比如100%)通过计算流过某段金属的实际电流(用上面的公式计算)除以这段电流能够承受电流的极限(用Tech File和Wire Properties)获得。
EM跑完我们可以先看下Redhawk的EM Summary report,具体如下图所示。
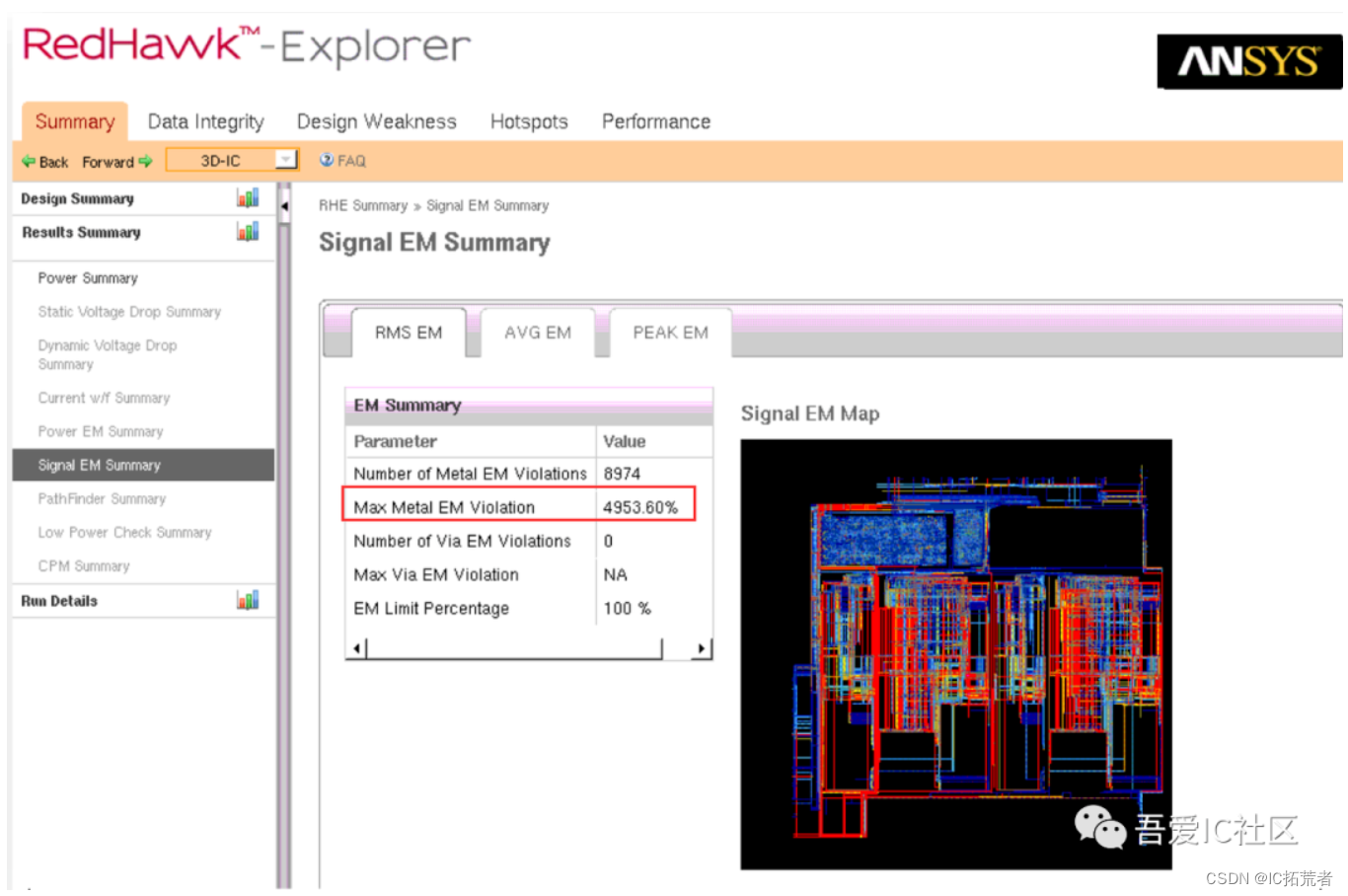
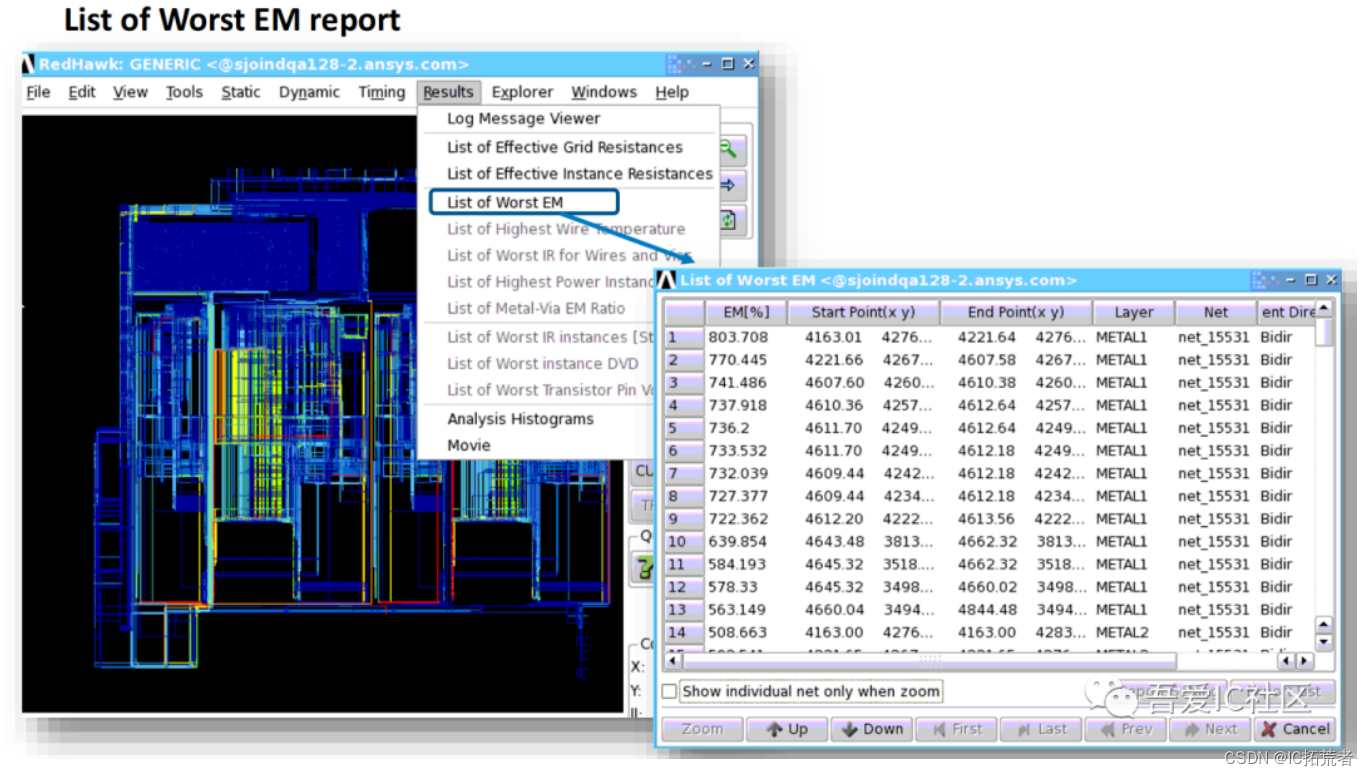

关于Signal EM和PG EM的更多详细教程和修复方法,可以移步小编知识星球查看。
七.Function ECO
ECO中文翻译是工程变更(Engineering Change Order)。只要你参与到实际项目了,肯定或多或少都接听过接触到ECO这个事情。因为design的bug无处不在,而且后仿用的case 无法覆盖100%的应用场景,甚至还有后仿无法验证的部分。
ECO主要包括Timing ECO和Function ECO。Timing ECO是指在timing signoff阶段所做的timing方面的优化,这里主要指的上面分享的timing signoff中的DMSA Flow。而Function ECO又可以分为Pre-mask ECO和Post-mask ECO。
Pre-mask ECO是指芯片做Mask前所做的ECO。而Post-mask ECO是指芯片tapeout后或wafer out后的ECO。
1)Pre-mask ECO
很多公司(特别是大公司),他们一般都有规定哪个阶段必须RTL freeze,这个时候不会也不允许再更新新的RTL,即使后面仿真验证有bug。为什么不让更新RTL呢?因为此时数字后端工程师可能都做好布局布线,timing也没什么大问题了,都准备开始修timing了。如果此时release新的RTL,那就意味着需要重新跑整个flow,从综合到PR,再到fixing timing。一方面会严重影响整个项目的Tapeout时间,从而影响Wafer out和芯片上市的时间。另外一方面,数字后端工程师可能有想骂人的冲动。
因此,此时数字前端负责写coding的工程师只能在final RTL的基础上,通过编写ECO脚本的方式来实现功能上的ECO。
当然,如果需要增加部分新feature,而这个feature要引入一个新module,那么此时可能需要重新release RTL。如果你的flow已经调的比较顺,而且还预留了部分margin,那么可能对项目的Schedule影响还可以。
ECO代价:时间成本,相对较小
2)Post-mask ECO (Metal前ECO)
当数字后端实现后的design,timing已经符合signoff 标准,DRC已经clean,LVS已经pass,IR drop,MVRC,Formality,DRCPLUS等都已经pass。但是数字前端设计工程师还没来得及做完大部分case的后仿,而且芯片又面临着Timing-TO-Market的压力。此时,老板可能会说先Tapeout吧(就是开始传GDSII给Foundary)。
为什么敢这么做呢?是在赌博吗?其实肯定有赌博的成分,但是更多的还是自信和满满的底气。因为前一周foundary会先做base layer的加工。只要后期仿真发现的问题,不需要再添加额外的cell,就不耽误之前的Tapeout(此处有点像流水线)。即使发现需要新加几个cell,这个时候仍然可以通过替换后端实现过程中所加的ECO cell或者spare cell来实现。
关于如何预先加ECO CELL和spare cell以及如何在PR中利用它们来做Function ECO 的主题,各位可以移步小编知识星球进行查阅。
3)Tapeout后的ECO
当芯片已经回来,在测试过程中发现的bug,然后又必须fix掉的bug(无法通过软件绕过去或者代价太高)。这个时候需要通过ECO来解决。这个时候做ECO的代价相对前面两种大很多,都是要消耗很多的真金白银,而且有芯片量产的巨大压力。改动少的可能就改几层Metal layer,多的可能就需要动十几层Metal layer,甚至重新流片。
做ECO之前,老板肯定会让数字前端设计工程师出ECO方案,同时让后端工程师进行评估,主要评估需要改动的层数,timing 是否能快速收敛等方面的风险。
ECO代价:时间成本+money 较大
介绍完各种不同类型的ECO后,我们具体来看看Innovus中如何做Function ECO。
4)Innovus ECO Steps
1 读入新netlist
source newchip.globals
init_design
or
source oldchip.globals
set init_verilog “newchip.v”
init_design
2 Load old floorplan/placement/routing data
loadFPlan oldchip.fp
ecoDefIn -postMask -reportFile InDefeco.rpt G1.pr.def
applyGlobalNets
3 Low power related changes (Low Power Flow)
read_power_intent -cpf test.cpf
commit_power_intent -keepRows
对于Low power相关信号的改动,需要读入cpf文件,确保跨power domain信号的正确处理。如果是非low power flow,可以跳过这一步。
4 指定Spare cell list或者ECO cell
specifySpareGate -inst SPARE*
5 Incremental placement
ecoPlace -useSpareCells true
这步是告诉工具去找相关功能的spare cell或ECO cell进行替换。当然也可以人工告诉工具你想要换的cell mappin关系,比如下面的命令。
ecoSwapSpareCell i_9649 spare1
6 Tie信号连接
新加进去的cell,有的pin可能是需要接0或1,那么此时innovus是支持自动在附近寻找已有的tie cell进行连接。当然你也可以利用eco cell来create一颗新的tie cell。
addTieHiLo -postMask [-cell “tieHighCellName tieLowCellName”] [-createHierPort {true | false}]
7 ECO Route
将ECO新加入的cell摆好位置,就可以设定需要freeze的layer,然后开始ecoRoute了。
ecoRoute -modifyOnlyLayers 1:2
在innovus中做完eco后,需要写出eco后design的gds做LVL检查,以确保工具ecoRoute后所动用的layer是符合我们的期望。那么,怎么做检查呢?具体的LVL golden 脚本,请移步小编的知识星球查阅下载。
好了,今天的内容分享就到这里。另外,因为公众号更改推送规则,小编分享的每篇干货不一定能及时推送给各位。为了避免错过精彩内容,请关注星标公众号,点击“在看”,点赞并分享到朋友圈,让推送算法知道你是社区的老铁,这样就不会错过任何精彩内容了。
如果你想和小编有更进一步的沟通交流的机会,欢迎加入小编知识星球,让我们一起学习成长,共同进步。相信在这里能让你成就一个更完美的自己。
小编知识星球简介(如果你渴望进步,期望高薪,喜欢交流,欢迎加入):
在这里,目前已经规划并正着手做的事情:
ICC/ICC2 lab的编写
基于ARM CPU的后端实现流程
利用ICC中CCD(Concurrent Clock Data)实现高性能模块的设计实现
基于ARM 四核CPU 数字后端Hierarchical Flow 实现教程
时钟树结构分析
低功耗设计实现
定期将项目中碰到的问题以案例的形式做技术分享
基于90nm项目案例实现教程(ICC和Innovus配套教程)
数字IC行业百科全书
吾爱IC社区知识星球星主为公众号”吾爱IC社区”号主,从事数字ic后端设计实现工作12年,拥有55nm,40nm,28nm,22nm,14nm等先进工艺节点成功流片经验,成功tapeout过三十多颗芯片。
这里是一个数字IC设计实现高度垂直细分领域的知识社群,是数字IC设计实现领域中最大,最高端的知识交流和分享的社区,这里聚集了无数数字ic前端设计,后端实现,模拟layout工程师们。
在这里大家可以多建立连接,多交流,多拓展人脉圈,甚至可以组织线下活动。在这里你可以就数字ic后端设计实现领域的相关问题进行提问,也可以就职业发展规划问题进行咨询,也可以把困扰你的问题拿出来一起讨论交流。对于提问的问题尽量做到有问必答,如遇到不懂的,也会通过查阅资料或者请教专家来解答问题。在这里鼓励大家积极发表主题,提问,从而促进整个知识社群的良性循环。每个月小编会针对活跃用户进行打赏。
最重要的是在这里,能够借助这个知识社群,短期内实现年薪百万的梦想!不管你信不信,反正已经进来的朋友肯定是相信的!相遇是一种缘分,相识更是一种难能可贵的情分!如若有缘你我一定会相遇相识!知识星球二维码如下,可以扫描或者长按识别二维码进入。目前已经有2720位星球成员,感谢这2720位童鞋的支持!欢迎各位渴望进步,期望高薪的铁杆粉丝加入!终极目标是打造实现本知识星球全员年薪百万的宏伟目标。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 45个经典Linux面试题!赶紧收藏!
- 构建公共场景消防安全,基于YOLOv8【n/s/m/l/x】全系列参数模型开发构建公共消防场景下火点烟雾检测识别系统
- 【STM32】STM32学习笔记-USART串口手法HEX和文本数据包(29)
- 某数据库行业Top10:依托CRM实现精细化运营
- 什么是好的FPGA编码风格?(1)--尽量避免组合逻辑环路(Combinational Loops)
- MYSQL索引、事务以及存储引擎
- 【Python百宝箱】离经叛道:探索离群值的科学与艺术
- 第十九章 调用Callout Library函数 - 将 $ZF(-5) 与多个库和许多函数调用一起使用
- ssm畅游义工组织系统(开题+源码)
- Netty实战(待完善)