统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
发布时间:2023年12月19日
统一大语言模型和知识图谱:如何解决医学大模型问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
?
医学大模型问题
问诊。偏离主诉和没抓住核心。
- 解决方案:建立抗干扰的能力,使得发现用户问题会一追到底。
检查。大模型最大的问题就是它的模糊和宽泛,给出的检查方案经常有缺失和缺漏。
- 解决方案:检查项目和诊断做关联,结合相应检查证据的类型和证据等级,给患者设计更加精准和高效的检查辅助方案
诊断。之前大模型只能给出一个方向性的诊断。在真实世界的临床应用实践上,最后要给出具体疾病的临床分型和分期。
- 解决方案:从教科书和临床指南中提炼
治疗。大模型给出的治疗方案往往也是偏方向性的。
- 解决方案:从教科书和临床指南中把治疗方案和治疗手段与诊断进行关联,以及在不同的疾病分期、分型下诊断方法和诊断的适用条件等综合考虑,辅助设计一个更加精准的治疗方案
医学大模型相当于一个模式识别系统,能迅速反应出 XX 特征 是 XX 疾病。
但是 ta 做不到完备的、全流程的医生治疗过程。
我们需要给 ta 引入结构化的完备能力。
从结构的角度出发,利用整体和部分的关系,有序地思考,正确决策,更有助于深度分析思考。
实现方式是,构建:
- 指南上的知识点结构化(知识图谱1)
- 临床上的解题思路结构化(知识图谱2)
- 疾病上的全流程管理结构化(知识图谱3)
- 错题上的结构化(知识图谱4)
- 多模态的结构化(知识图谱5)
同时使用 5 种知识图谱,才能让医学大模型有完备的诊断能力:
- 从家庭医生,到专科水平
- 从模式识别,到完备的全流程诊断
- 从不可控不稳定不可解释的黑盒,变成可控稳定可解释的
- 能根据反馈,不断修订知识
这种结构化的完备能力,我们能通过 5 种专业的知识图谱实现。
如何使用知识图谱加强和补足专业能力?
大模型结构
现在的 大模型 可以分为:
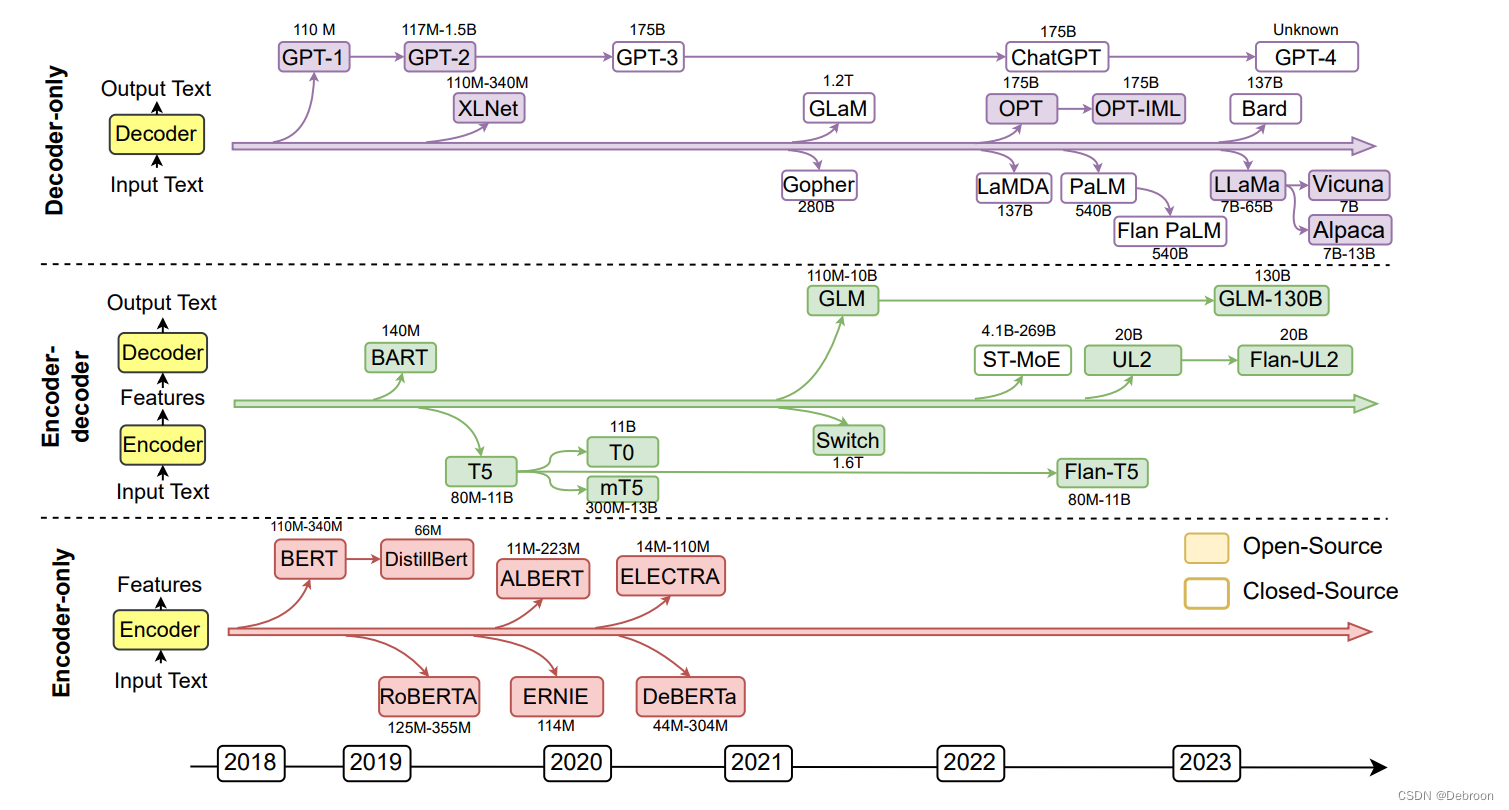
- 1)Decoder-only LLMs:仅采用解码器模块来生成目标输出文本。很多decoder-only的LLMs(如GPT4)通常可以根据少量示例或简单指令执行下游任务,而无需添加预测头或微调。模型的训练范式是预测句子中的下一个单词。
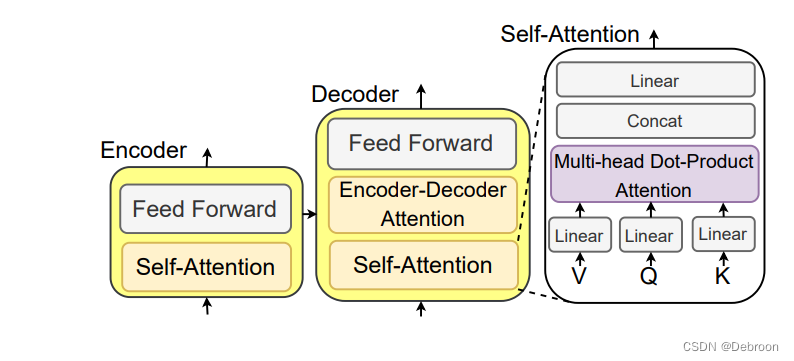
- 2)Encoder-Decoder LLMs:用编码器和解码器模块。编码器模块负责将输入句子进行编码,解码器用于生成目标输出文本。编码器-解码器LLM(如ChatGLM)能够直接解决基于某些上下文生成句子的任务,例如总结、翻译和问答
- 3)Encoder-only LLMs:仅用编码器对句子进行编码并理解单词之间的关系(如BERT),训练模式预测句子中的掩码词语,需要添加额外的预测头来解决下游任务,胜在自然语言理解任务(如文本分类、匹配)
知识图谱增强大模型的方法
当你问 熊是什么样的动物?:
- 语言模型:熊是一种大型哺乳动物,只能给你一个笼统的答案。
- 知识图谱 + 语言模型可以回答:“熊是一种大型哺乳动物,通常有厚重的毛皮,强壮的身体和大而强壮的爪子。它们喜欢生活在森林中,以植物、鱼和昆虫为食。”
知识图谱增强 分为三部分:
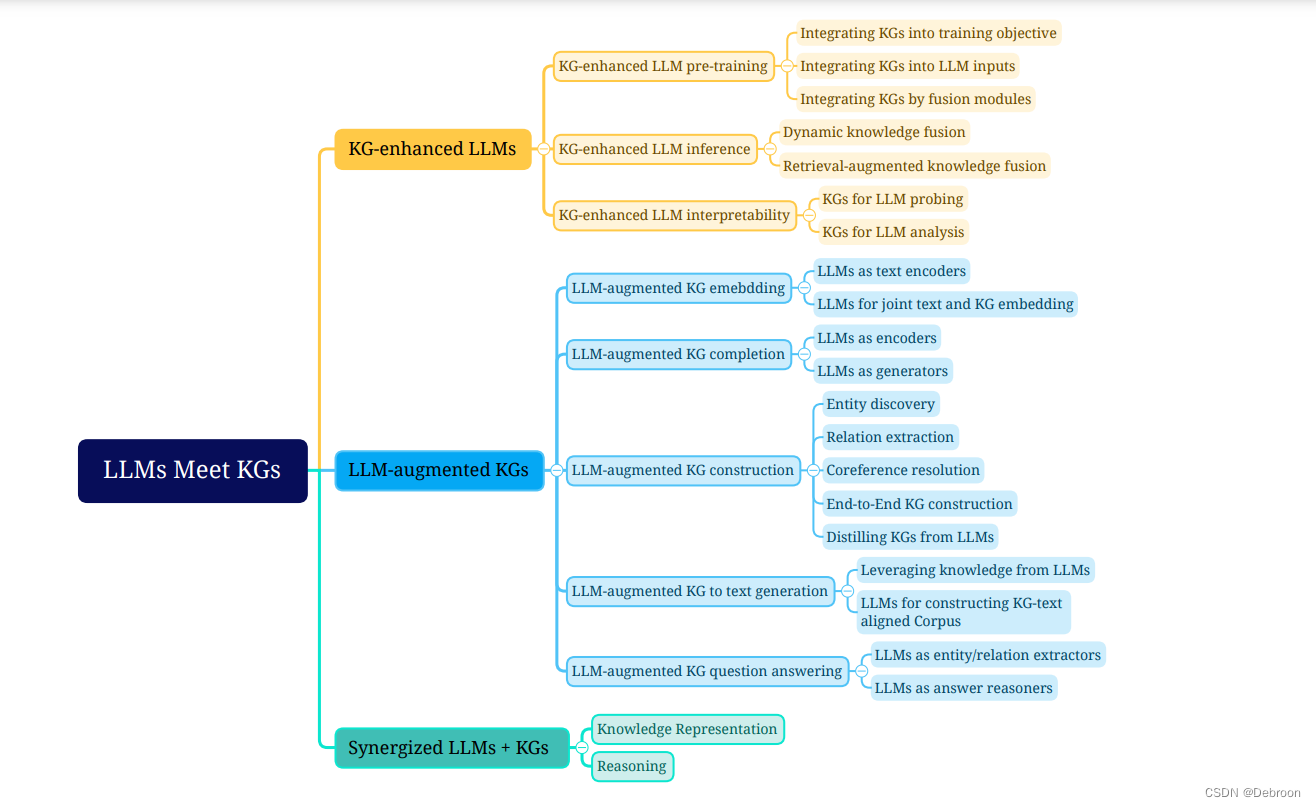
-
增强的LLM预训练
将KGs引入训练目标,设计知识导向的训练目标
将KGs整合到LLM输入中
将KGs纳入到额外的融合模块中,设计单独处理KGs的模块。
-
增强的LLM推理
-
增强的LLM可解释性
正在更新…
文章来源:https://blog.csdn.net/qq_41739364/article/details/135035445
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 教师教育研究的意义有哪些
- 回首2023: 程序员跳出舒适圈
- [FNet]论文实现:FNet:Mixing Tokens with Fourier Transform
- 前端自定义icon的方法(Vue项目)
- 003、一起来玩猜数游戏吧!
- HarmonyOS应用开发者基础认证考试
- Ubuntu及Docker 安装rabbitmq
- 威士忌品鉴:如何体验这美妙的细节与品质
- 2024阿里云服务器可用区选择方法
- 2024年【高处安装、维护、拆除】复审考试及高处安装、维护、拆除证考试