MNIST 数据集详析:使用残差网络RESNET识别手写数字(文末送书)
MNIST 数据集已经是一个几乎每个初学者都会接触的数据集, 很多实验、很多模型都会以MNIST 数据集作为训练对象, 不过有些人可能对它还不是很了解, 那么今天我们一起来学习一下MNIST 数据集,同时构建残差网络来识别手写数字。
1.MNIST 介绍
MNIST手写数字数据库具有60,000个示例的训练集和10,000个示例的测试集,MNIST的图像,每张图片是包含28 像素× 28 像素的灰度图像(1 通道),各个像素的取值在0 到255 之间。每张图片都由一个28 ×28 的矩阵表示,每张图片都由一个784 维的向量表示(28*28=784)。

Size: 28×28 灰度手写数字图像
Num: 训练集 60000 和 测试集 10000,一共70000张图片
Classes: 0,1,2,3,4,5,6,7,8,9
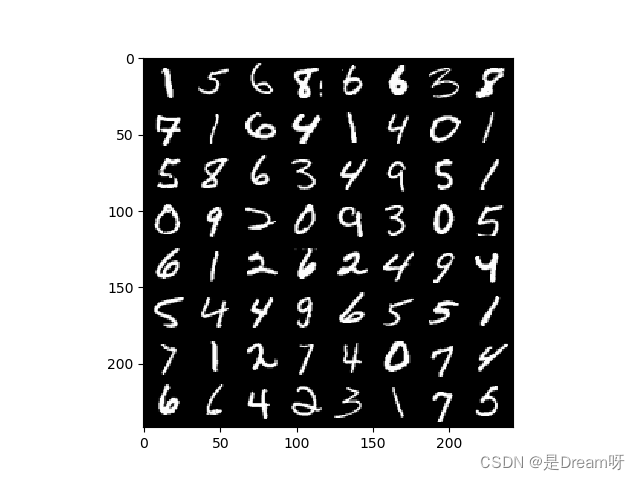
MNIST 数据集来自美国国家标准与技术研究所, 训练集 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自工作人员. 测试集也是同样比例的手写数字数据.
MNIST 数据集包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
训练集标签文件 :

训练集映像文件:
像素按行组织。像素值为 0 到 255。0 表示背景(白色),255 表示前景(黑色)。
测试集标签文件:

测试集映像文件:
像素按行组织。像素值为 0 到 255。0 表示背景(白色),255 表示前景(黑色)。
2.数据集读取
2.1官网下载MNIST 数据集
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取
注意:不要直接点连接,复制连接粘贴到新的浏览器标签页搜索,就不需要账号密码了!!!
2.2 博主分享
同时:博主已将MNIST公开数据集上传至百度网盘,大家可以直接下载学习:
链接: https://pan.baidu.com/s/1-rurbkWdv_veQD8QcQWcRw 提取码: 0213
2.3 直接下载
如果数据集没有下载,修改参数:download=True,直接去下载数据集:
from torchvision import datasets, transforms
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=True)
print(train_data)
print(test_data)
如果出现这种错误:
SyntaxError: Non-UTF-8 code starting with \xca in fileD:\PycharmProjects\model-fuxian\data set\MNIST t.py on line 2, but noencoding declared; see http://python.org/dev/peps/pep-0263/ fordetails
大概率是你没加:# coding:gbk,为什么呢?由于 Python 默认使用 ASCII 编码来解析源代码,因此如果源文件中包含了非 ASCII 编码的字符(比如中文字符),那么解释器就可能会抛出 SyntaxError 异常。加上# -- coding: gbk --这样的注释语句可以告诉解释器当前源文件的字符编码格式是 GBK,从而避免源文件中文字符被错误地解析。
如果成功运行会出现这种结果,表示已经开始下载了:
输出结果:
Dataset MNIST
Number of datapoints: 60000
Root location: ./MNIST
Split: Train
StandardTransform
Transform: ToTensor()
Dataset MNIST
Number of datapoints: 10000
Root location: ./MNIST
Split: Test
StandardTransform
Transform: ToTensor()
3.数据集可视化
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
train_data = datasets.MNIST(root="model-fuxian/data set/MNIST/MNIST/raw/MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
for num, (image, label) in enumerate(train_loader):
image_batch = torchvision.utils.make_grid(image, padding=2)
plt.imshow(np.transpose(image_batch.numpy(), (1, 2, 0)), vmin=0, vmax=255)
plt.show()
print(label)
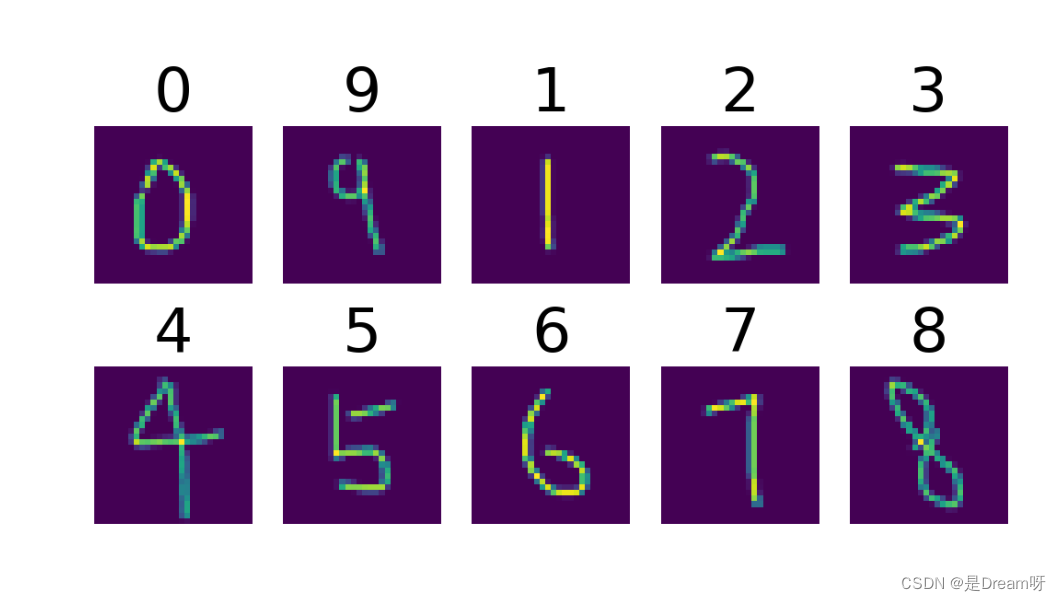
得到图片:


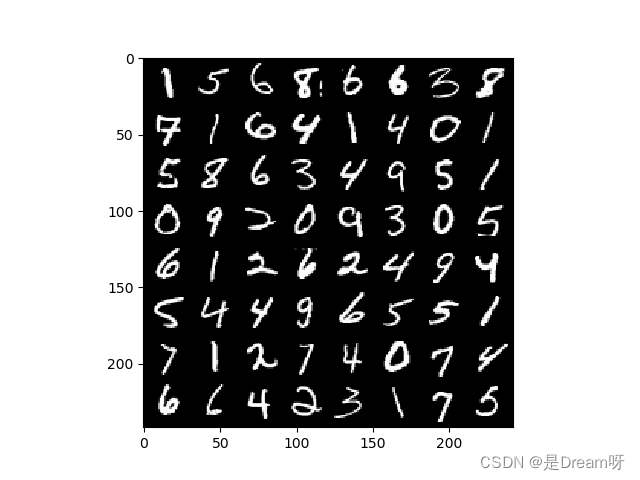
这是标签:
tensor([2, 1, 7, 7, 2, 4, 2, 2, 0, 1, 7, 1, 5, 7, 9, 0, 2, 7, 4, 7, 0, 2, 7, 1,
6, 9, 1, 1, 1, 5, 4, 3, 8, 0, 1, 0, 1, 3, 8, 0, 1, 4, 5, 1, 8, 4, 7, 3,
8, 3, 2, 2, 0, 0, 4, 0, 2, 9, 7, 1, 8, 3, 2, 3])
tensor([6, 6, 7, 2, 5, 4, 0, 3, 4, 6, 1, 4, 1, 9, 2, 2, 8, 7, 5, 7, 9, 6, 6, 7,
1, 9, 9, 5, 5, 6, 9, 6, 8, 5, 5, 7, 8, 9, 8, 3, 1, 0, 1, 4, 6, 1, 8, 6,
1, 4, 6, 7, 1, 9, 5, 4, 3, 4, 6, 1, 7, 3, 7, 6])
tensor([7, 1, 5, 1, 4, 0, 9, 2, 2, 0, 1, 5, 2, 3, 6, 4, 6, 9, 3, 3, 2, 8, 1, 5,
8, 0, 1, 4, 5, 6, 2, 6, 4, 9, 2, 0, 7, 2, 0, 1, 2, 4, 4, 6, 5, 9, 1, 2,
5, 3, 3, 8, 8, 3, 4, 5, 2, 6, 0, 0, 8, 7, 1, 7])
4.使用残差网络RESNET识别手写数字
残差网络:
残差网络(Residual Network,ResNet)是在神经网络模型中给非线性层增加直连边的方式来缓解梯度消失问题,从而使训练深度神经网络变得更加容易。在残差网络中,最基本的单位为残差单元。
算子ResBlock:
首先实现一个算子ResBlock来构建残差单元,其中定义了use_residual参数,用于在后续实验中控制是否使用残差连接:
class ResBlk(nn.Module): # 定义Resnet Block模块
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu
return out
ResNet18结构及六个模块:
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络。ResNet18 的网络结构如图所示:
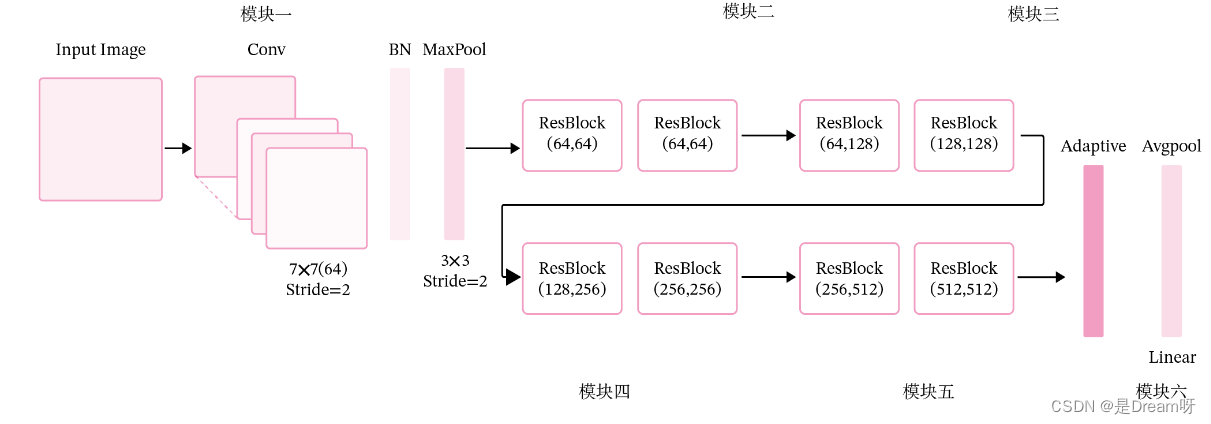
其中为了便于理解,可以将ResNet18网络划分为6个模块:
第一模块:包含了一个步长为2,大小为7 × 7 7 \times 77×7的卷积层,卷积层的输出通道数为64,卷积层的输出经过批量归一化、ReLU激活函数的处理后,接了一个步长为2的3 × 3 3 \times 33×3的最大汇聚层;
第二模块:包含了两个残差单元,经过运算后,输出通道数为64,特征图的尺寸保持不变;
第三模块:包含了两个残差单元,经过运算后,输出通道数为128,特征图的尺寸缩小一半;
第四模块:包含了两个残差单元,经过运算后,输出通道数为256,特征图的尺寸缩小一半;
第五模块:包含了两个残差单元,经过运算后,输出通道数为512,特征图的尺寸缩小一半;
第六模块:包含了一个全局平均汇聚层,将特征图变为1 × 1 1 \times 11×1的大小,最终经过全连接层计算出最后的输出。
定义完整网络:
class ResNet18(nn.Module): # 构建resnet18层
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
self.blk1 = ResBlk(32, 64, stride=1)
self.blk2 = ResBlk(64, 128, stride=1)
self.blk3 = ResBlk(128, 256, stride=1)
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 * 1 * 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
x = F.relu(self.conv1(x)) # 先经过第一层卷积
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
完整代码:
# coding=gbk
# 1.加载必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import argparse
# 2.超参数
BATCH_SIZE = 32#每批处理的数据 一次性多少个
DEVICE = torch.device("cuda")#使用GPU
# DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")#使用GPU
EPOCHS =4 #训练数据集的轮次
# 3.图像处理
pipeline = transforms.Compose([transforms.ToTensor(), #将图片转换为Tensor
])
# 4.下载,加载数据
from torch.utils.data import DataLoader
#下载
train_set = datasets.MNIST("data",train=True,download=True,transform=pipeline)
test_set = datasets.MNIST("data",train=False,download=True,transform=pipeline)
#加载 一次性加载BATCH_SIZE个打乱顺序的数据
train_loader = DataLoader(train_set,batch_size=BATCH_SIZE,shuffle=True)
test_loader = DataLoader(test_set,batch_size=BATCH_SIZE,shuffle=True)
# 5.构建网络模型
class ResBlk(nn.Module): # 定义Resnet Block模块
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1): # 进入网络前先得知道传入层数和传出层数的设定
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__() # 初始化
# we add stride support for resbok, which is distinct from tutorials.
# 根据resnet网络结构构建2个(block)块结构 第一层卷积 卷积核大小3*3,步长为1,边缘加1
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 将第一层卷积处理的信息通过BatchNorm2d
self.bn1 = nn.BatchNorm2d(ch_out)
# 第二块卷积接收第一块的输出,操作一样
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# 确保输入维度等于输出维度
self.extra = nn.Sequential() # 先建一个空的extra
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x): # 定义局部向前传播函数
out = F.relu(self.bn1(self.conv1(x))) # 对第一块卷积后的数据再经过relu操作
out = self.bn2(self.conv2(out)) # 第二块卷积后的数据输出
out = self.extra(x) + out # 将x传入extra经过2块(block)输出后与原始值进行相加
out = F.relu(out) # 调用relu
return out
class ResNet18(nn.Module): # 构建resnet18层
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential( # 首先定义一个卷积层
nn.Conv2d(1, 32, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(32)
)
# followed 4 blocks 调用4次resnet网络结构,输出都是输入的2倍
self.blk1 = ResBlk(32, 64, stride=1)
self.blk2 = ResBlk(64, 128, stride=1)
self.blk3 = ResBlk(128, 256, stride=1)
self.blk4 = ResBlk(256, 256, stride=1)
self.outlayer = nn.Linear(256 * 1 * 1, 10) # 最后是全连接层
def forward(self, x): # 定义整个向前传播
x = F.relu(self.conv1(x)) # 先经过第一层卷积
x = self.blk1(x) # 然后通过4次resnet网络结构
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1) # 平铺一维值
x = self.outlayer(x) # 全连接层
return x
# 6.定义优化器
model = ResNet18().to(DEVICE)#创建模型并将模型加载到指定设备上
optimizer = optim.Adam(model.parameters(),lr=0.001)#优化函数
criterion = nn.CrossEntropyLoss()
# 7.训练
def train_model(model,device,train_loader,optimizer,epoch):
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
model.train()#模型训练
for batch_index,(data ,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)#部署到DEVICE上去
optimizer.zero_grad()#梯度初始化为0
output = model(data)#训练后的结果
loss = criterion(output,target)#多分类计算损失
loss.backward()#反向传播 得到参数的梯度值
optimizer.step()#参数优化
if batch_index % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_index * len(data), len(train_loader.dataset),
100. * batch_index / len(train_loader), loss.item()))
if args.dry_run:
break
# 8.测试
def test_model(model,device,text_loader):
model.eval()#模型验证
correct = 0.0#正确率
global Accuracy
text_loss = 0.0
with torch.no_grad():#不会计算梯度,也不会进行反向传播
for data,target in text_loader:
data,target = data.to(device),target.to(device)#部署到device上
output = model(data)#处理后的结果
text_loss += criterion(output,target).item()#计算测试损失
pred = output.argmax(dim=1)#找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()#累计正确的值
text_loss /= len(test_loader.dataset)#损失和/加载的数据集的总数
Accuracy = 100.0*correct / len(text_loader.dataset)
print("Test__Average loss: {:4f},Accuracy: {:.3f}\n".format(text_loss,Accuracy))
# 9.调用
for epoch in range(1,EPOCHS+1):
train_model(model,DEVICE,train_loader,optimizer,epoch)
test_model(model,DEVICE,test_loader)
torch.save(model.state_dict(),'model.ckpt')
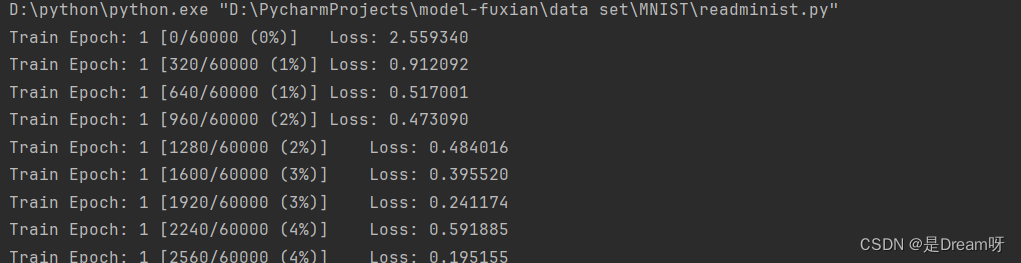
精确度
Test__Average loss: 0.000808,Accuracy: 99.150
最后可以发现准确度达到了99%还高,可以看出来残差网络识别手写数字的准确性还是很高的。
没有GPU的可以使用CPU,不过速度会大打折扣:DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu"),最好是可以使用GPU,这样速度会快很多: torch.device("cuda")#使用GPU
文末免费送书:C语言从入门到精通(第6版)
《C语言从入门到精通(第6版)》从初学者的角度出发,以通俗易懂的语言、丰富多彩的实例,详细介绍了使用C语言进行程序开发需要掌握的各方面知识。全书分为4篇,共20章,内容包括C语言概述、算法、数据类型、运算符与表达式、数据输入/输出、选择结构、循环控制、数组、函数、指针、结构体和共用体、位运算、预处理、文件、内存管理、网络套接字编程、单词背记闯关游戏、学生信息管理系统、单片机基础和GSM短信控制家庭防盗报警系统。书中所有知识都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,读者可以轻松领会C语言程序开发的精髓,快速提高开发技能。

抽奖方式: 评论区随机抽取3位小伙伴免费送出!
参与方式: 关注博主、点赞、收藏、评论区评论“人生苦短,我用Python!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间: 2024-1-30 20:00:00
当当: 购买链接传送门
京东: 购买链接传送门
😄😄😄名单公布方式: 下期活动开始将在评论区和私信一并公布,中奖者请三天内提供信息😄😄😄
“软件开发视频大讲堂”丛书是清华社计算机专业基础类零售图书畅销品牌之一。
(1)2008—2023年,丛书累计修订7次,销售400万册,深受广大程序员喜爱。
(2)4本荣获“全行业优畅销书”奖,1本荣获清华社“专业畅销书”一等奖,多数品种在全国计算机零售图书排行榜排行中名列前茅。
(3)实用、易懂、资源丰富,被数百所高校选为专业课教材。
《C语言从入门到精通(第6版)》介绍主流开发环境Visual C 6.0、Visual Studio 2022和Dev C ,图书特点如下。
- 学通C语言只需要4步:基础知识→核心技术→高级应用→项目实战,符合认知规律。
- 204集同步教学微课 强化实战训练 在线答疑,夯实基础,精准,有效,速练,适合自学。
- 171个应用实例 118个编程训练 110个综合练习 3个项目案例,学习1小时,训练10小时,从入门到项目上线,真正成为C语言高手。
- 根据图书首页说明,扫描书中二维码,打开明日科技账号注册页面,填写注册信息后将自动获取C语言开发资源库一年(自注册之日起)的VIP使用权限。
(1)技术资源库:323个技术要点,系统、全面,随时随地学习。
(2)技巧资源库:300个开发技巧,快速扫除盲区,掌握更多实战技巧,精准避坑。
(3)实例资源库:359个应用实例,含大量热点实例和关键实例,巩固编程技能。
(4)项目资源库:19个实战项目,快速积累项目经验,总有一个你找工作会用到。
(5)源码资源库:378项源代码详细分析,多读源码,快速成长。
(6)视频资源库:451集学习视频,边看视频边学习,提升更快。
(7)面试资源库:C语言企业面试真题,合理职业规划,快速就业。
学会、用好C语言开发资源库,可在短时间内从小白晋升为一名软件工程师。 - 在线解答,高效学习。
(1)关注清大文森学堂公众号,可获取本书的源代码、PPT课件、视频等资源。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大数据Doris(五十二):SQL函数之数学函数
- 基于Android系统的外卖APP的设计与实现04871-计算机毕业设计项目选题推荐(附源码)
- 鸿蒙开发之统一样式, @Styles 复用样式
- Linux目录结构及路径描述方式
- C#Selenium WebDriver备忘录
- 《吐血整理》保姆级系列教程-玩转Fiddler抓包教程(7)-Fiddler状态面板-QuickExec命令行
- 网络面试题总结
- sd-wan跨境网络专线应用场景
- 树莓派连接WiFi完全指南
- 实时数据库迁移