KNN算法实战-健康医疗
发布时间:2023年12月17日
健康医疗
算法建模
- knn 算法建模构建微观数据和疾病之间的关系
- knn 调整超参数,准确率提升
- 数据归一化、标准化,提升更加明显
算法实战
导入包
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
加载数据
data = pd.read_csv('./cancer.csv', sep='\t')
data.head()

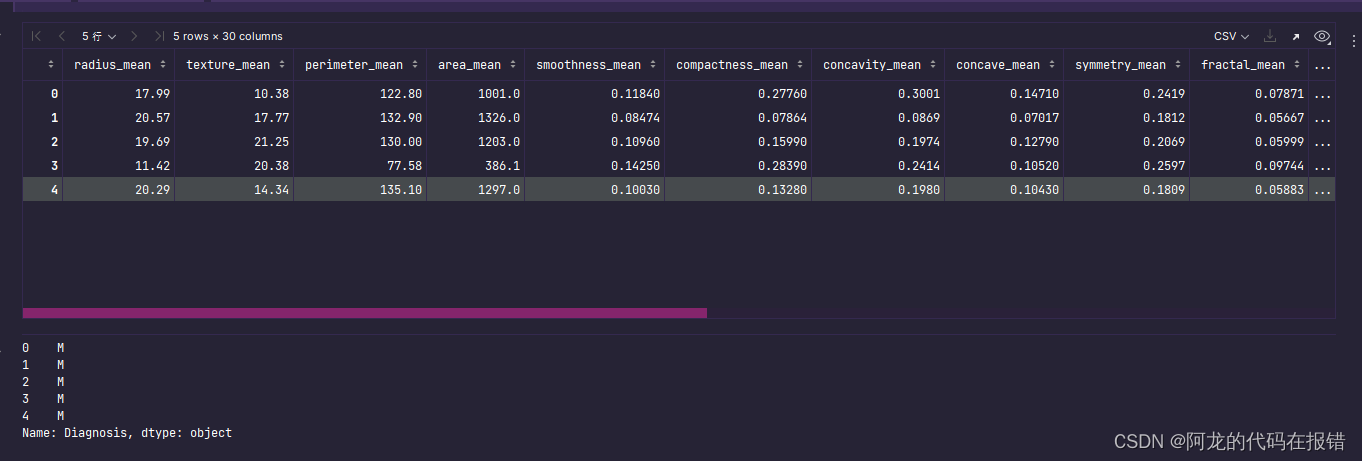
获取有用的数据
# 返回值
y = data['Diagnosis']
X = data.iloc[:, 2:]
display(X.head(), y.head())
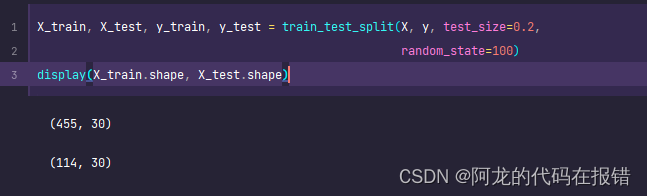
拆分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=100)
display(X_train.shape, X_test.shape)
网格搜索超参数
estimator = KNeighborsClassifier()
params = dict(n_neighbors=np.arange(1, 30),
weights=['uniform', 'distance'],
p=[1, 2])
Gcv = GridSearchCV(estimator, params, cv=6, scoring='accuracy')
Gcv.fit(X_train, y_train)
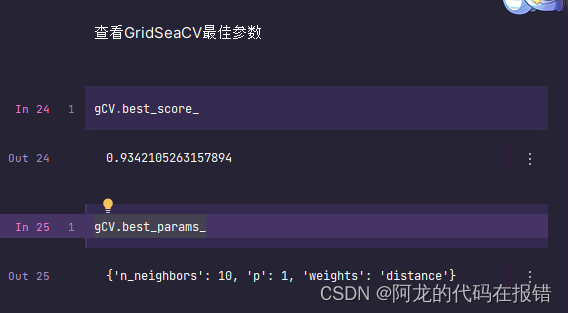
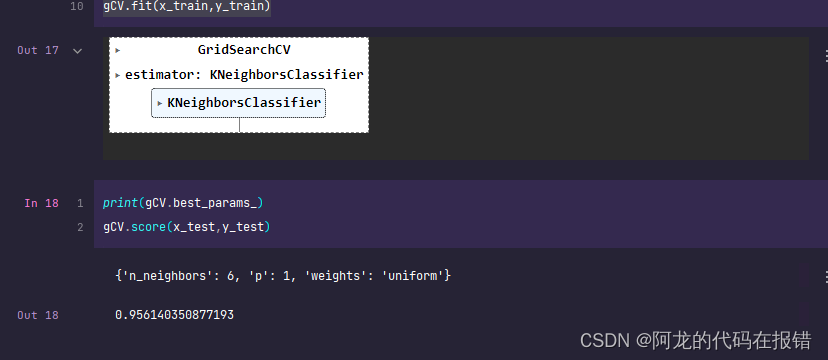
获取超参数:
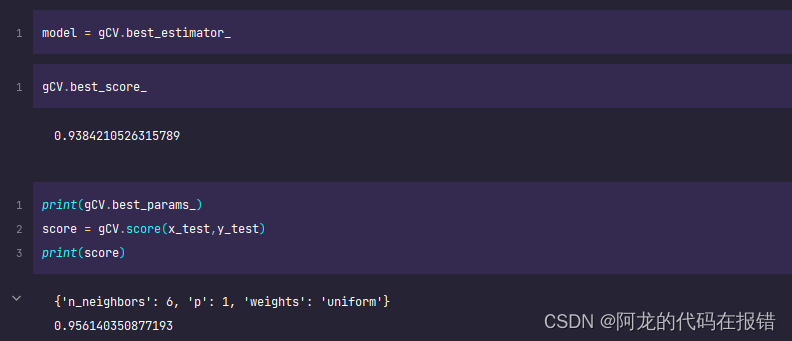
Gcv.best_params_
获取最好模型的参数
Gcv.score(X_test,y_test)
gCV.best_score_
gCV.best_params_
模型预测
# 获取最佳的模型
model = gCV.best_estimator_
y_pred = model.predict(x_test)
print('算法预测值:',y_pred[:20])
print('真实值',y_test[:20].values)

计算模型的分数
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_pred)
(y_test==y_pred).mean()
gCV.score(x_test,y_test)
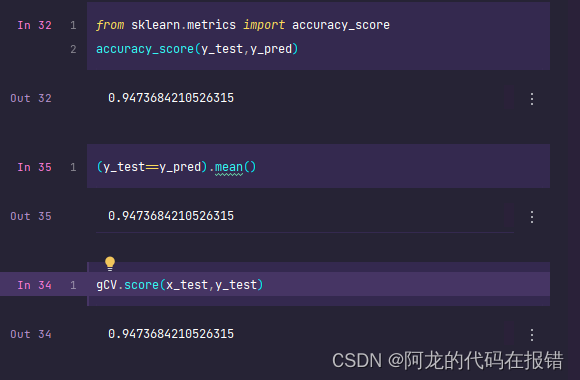
以上的方法获取的模型分数是一样
归一化处理
归一化:是一种数据处理方法,用于将数据缩放到一个统一的范围,通常是[0,1]或[-1,1]:以下是最常用的两种归一化处理的方式:
方式一,min-max归一化(线性缩放):min_max归一化将数据线性缩放到[0-1]的范围,对于给定的一组数据x,min-max归一化的计算公式为:
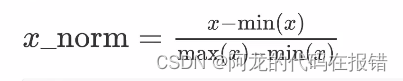
from sklearn.preprocessing import MinMaxScaler
mss = MinMaxScaler()
x_normal = mss.fit_transform(x)
x_normal
数据拆分建模并且进行训练
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=100)
estimator = KNeighborsClassifier()
params = dict(n_neighbors=np.arange(1,30),
weights=['uniform','distance'],
p = [1,2])
gCV = GridSearchCV(estimator,params,cv=6,scoring='accuracy')
gCV.fit(x_train,y_train)
获取当前模型的分数
方式二:Z-Score归一化(标准化):Z-Score 归一化将原始数据转换为均值为0,标准方差为1的标准正态分布。对于给定的一组数据X,Z-Score归一化的计算公式为:

其中,x表示数据集的均值
表示数据集中的标准差
from sklearn.preprocessing import StandardScaler
sd = StandardScaler()
x_norm = sd.fit_transform(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=100)
estimator = KNeighborsClassifier()
params = dict(n_neighbors=np.arange(1,30),
weights=['uniform','distance'],
p = [1,2])
gCV = GridSearchCV(estimator,params,cv=6,scoring='accuracy')
gCV.fit(x_train,y_train)
坚持学习,整理复盘

文章来源:https://blog.csdn.net/yujinlong2002/article/details/134779297
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章