new和delete表达式的工作步骤
new表达式工作步骤
delete表达式工作步骤
- 调用相应类型的析构函数,但析构函数并不能删除对象所在的空间,而是释放对象申请的资源
- 调用operator delete库函数回收对象所在的空间 *void operator delete (void )
结论:调用析构函数,并不是回收对象所在的空间。
情况1:
class Student{
public:
Student(const char * name,int id)
: _name(new char[strlen(name)+1]())
,_id(id)
{
cout<<"Student(const char *name,int id)"<<endl;
strcpy(_name,name);
}
~Student()
{
if(_name)
{
delete[] _name;
_name = nullptr;
}
cout<<"~Student()"<<endl;
}
//开辟一个未类型化的空间
//参数n代表的就是Student类型占据的空间大小
//不需要关心n是如何传过去的,系统已经写好了
//该函数专属于student类
void * operator new (size_t n)
{
cout<<"void *operator new (size_t)"<<endl;
return malloc(n);
}
void operator delete(void *p)
{
cout<<"void operator delete (void *)"<<endl;
free(p);
}
void print()
{
cout<<"name:"<<_name<<endl;
cout<<"id:"<<_id<<endl;
}
private:
char *_name;
int _id;
};
void test(){
Student *pstu = new Student("Xiaoming",100);
pstu->print();
delete pstu;
}
int main()
{
test();
return 0;
}
效果:
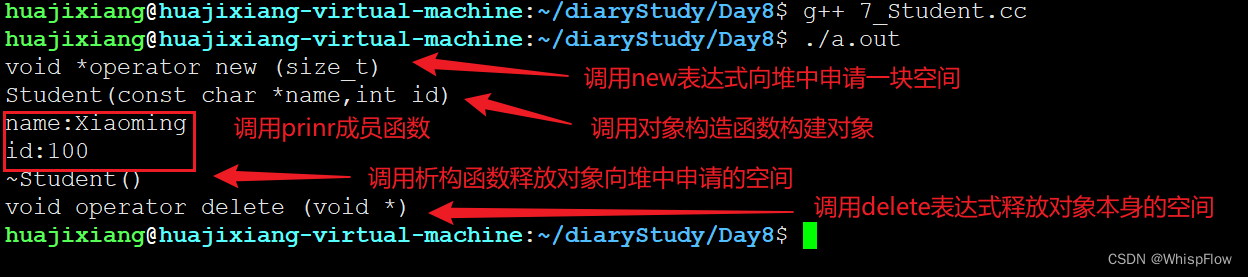
首先输出了重新定义的 new 运算符,在使用 new 进行对象创建时使用,随后执行了构造函数用于初始化对象,输出了 name 和 id 的值。在对象使用完毕后,执行了析构函数用于释放对象的内存空间,最后执行了重载的 delete 运算符用于释放申请的内存空间。
Q:为什么这里的operator new函数只调用了一次而不是两次,代码中不是有两个new么?
答:在这段代码中,虽然使用了两个 new 运算符,但实际上只调用了一次 operator new 表达式函数。这是因为在 C++ 中,每个类只需要定义一个 operator new 函数来实现内存分配即可,该函数会被用于为该类的所有对象分配内存空间。类似地,同样只需要定义一个 operator delete 函数来释放该类的所有对象申请的内存空间。在本例中,由于 Student 类只定义了其中一个 operator new 函数和一个 operator delete 函数,因此实际上只调用了一次 operator new 函数,用于为 pstu 分配内存空间。
Q:因为void * operator new (size_t n)和void * operator new (size_t n)函数是放在Student类中的,这次我们将这两个函数放在全局中,看看会出现什么结果
放在全局就不再专属于Student这个类了,因此对所有的类型都会起作用
#include <iostream>
#include<string.h>
using std::cout;
using std::endl;
void * operator new (size_t n)
{
cout<<"void *operator new (size_t)"<<endl;
return malloc(n);
}
void operator delete(void *p)
{
cout<<"void operator delete (void *)"<<endl;
free(p);
}
class Student{
public:
Student(const char * name,int id)
: _name(new char[strlen(name)+1]())
,_id(id)
{
cout<<"Student(const char *name,int id)"<<endl;
strcpy(_name,name);
}
~Student()
{
if(_name)
{
delete[] _name;
_name = nullptr;
}
cout<<"~Student()"<<endl;
}
//开辟一个未类型化的空间
//参数n代表的就是Student类型占据的空间大小
//不需要关心n是如何传过去的,系统已经写好了
//该函数专属于student类
void print()
{
/* /1* Student stu1 = new Student("XiaoLan",300); *1/ */
/* Student *stu1 = new Student("XiaoLan",300); */
/* stu1->print(); */
cout<<"name:"<<_name<<endl;
cout<<"id:"<<_id<<endl;
}
private:
char *_name;
int _id;
};
void test(){
Student *pstu = new Student("Xiaoming",100);
pstu->print();
cout<<"----------------------------"<<endl;;
/* Student *pstu1 = new Student("XiaoHong",200); */
/* pstu1->print(); */
delete pstu;
/* delete pstu1; */
}
int main()
{
test();
return 0;
}
效果:
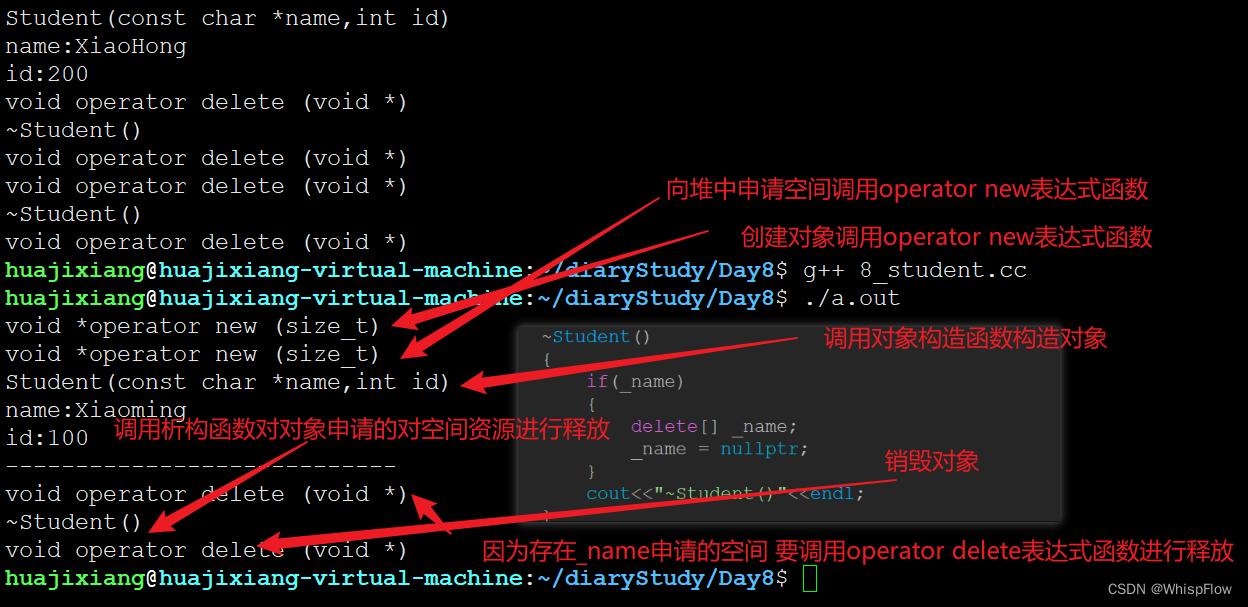
通过这个例子再次验证了析构函数并不是要去回收对象本身所占据的空间
应用:
要求:一个类只能生成栈对象
意思就是该类的对象只能在栈上创建,而不能使用 new 运算符在堆上创建,或者说一个类只能创建在栈上的对象,不能生成堆对象
当说一个类只能生成栈对象时,意思是该类的对象只能在栈上创建,而不能使用 new 运算符在堆上创建。
这种限制可以通过将构造函数声明为 private 或 protected 来实现。这样,类的对象只能在类的成员函数或友元函数中创建,而不能直接通过 new 运算符在堆上创建。
有时候需要限制对象只能在栈上创建的原因包括:
-
简化内存管理:栈对象的生命周期是与其所在的作用域一致的,当对象离开作用域时,会自动调用析构函数释放对象所占用的内存。这样,可以避免手动管理堆上对象的内存,减少内存泄漏的风险。
-
性能考虑:在栈上创建对象比在堆上创建对象更高效。栈上的对象分配和释放内存只涉及栈指针的移动,而堆上对象需要通过动态内存分配来完成,这可能涉及较大的开销。
-
线程安全性:栈上的对象只能在所在的线程中访问,这可以简化对象的线程同步问题。而在多线程环境下,管理堆上对象的并发访问可能会更复杂。
需要注意的是,如果一个类只能生成栈对象,那么在使用该类时需要遵循这个规定,不能通过 new 运算符在堆上创建对象。否则,编译器将会报错。
总结起来,限制一个类只能生成栈对象可以简化内存管理,提高性能,以及简化线程同步,但也需要在使用时遵循这个限制。
对象要放在栈上需要哪些条件:
对构造函数和析构函数都有要求
- 必须要确保构造函数和析构函数都放在public区
- 将类中的operator new库函数放在private区域
代码:
类声明
class Student{
public:
Student(const char * name,int id)
: _name(new char[strlen(name)+1]())
,_id(id)
{
cout<<"Student(const char *name,int id)"<<endl;
strcpy(_name,name);
}
~Student()
{
if(_name)
{
delete[] _name;
_name = nullptr;
}
cout<<"~Student()"<<endl;
}
void print()
{
cout<<"name:"<<_name<<endl;
cout<<"id:"<<_id<<endl;
}
private:
void * operator new (size_t n)
{
cout<<"void *operator new (size_t)"<<endl;
return malloc(n);
}
void operator delete(void *p)
{
cout<<"void operator delete (void *)"<<endl;
free(p);
}
private:
char *_name;
int _id;
};
void test1()
{
//生成栈对象的要求:
//必须要将构造函数和析构函数都放在public区域
Student s1("XiaoHong",101);
s1.print();
}
int main()
{
test1();
return 0;
}
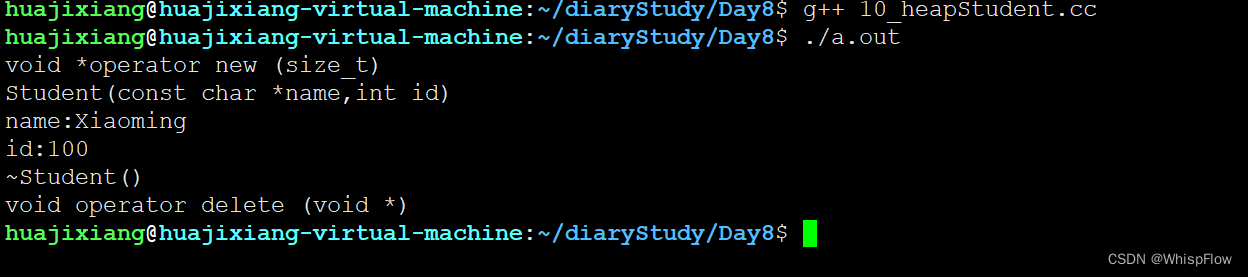
效果:

因为我们没有用到operator new 和operaotr delete表达式函数,故只需要在private区域声明即可,无需定义出来。栈对象的生命周期是与其所在的作用域一致的,当对象离开作用域时,会自动调用析构函数释放对象所占用的内存。这样,可以避免手动管理堆上对象的内存,减少内存泄漏的风险。
故最终代码如下:
#include <iostream>
#include<string.h>
using std::cout;
using std::endl;
class Student{
public:
Student(const char * name,int id)
: _name(new char[strlen(name)+1]())
,_id(id)
{
cout<<"Student(const char *name,int id)"<<endl;
strcpy(_name,name);
}
~Student()
{
if(_name)
{
delete[] _name;
_name = nullptr;
}
cout<<"~Student()"<<endl;
}
void print()
{
cout<<"name:"<<_name<<endl;
cout<<"id:"<<_id<<endl;
}
private:
void * operator new (size_t n);
void operator delete(void *p);
private:
char *_name;
int _id;
};
void test1()
{
//生成栈对象的要求:
//必须要将构造函数和析构函数都放在public区域
Student s1("XiaoHong",101);
s1.print();
}
int main()
{
test1();
return 0;
}
效果如上述图片所示
要求:一个类只能生成堆对象
一个类只能创建在堆上的对象,不能创建位于栈上的对象
结论:只需要将析构函数放在私有的区域就可以
代码:
#include <iostream>
#include<string.h>
using std::cout;
using std::endl;
class Student{
public:
Student(const char * name,int id)
: _name(new char[strlen(name)+1]())
,_id(id)
{
cout<<"Student(const char *name,int id)"<<endl;
strcpy(_name,name);
}
//new表达式
void * operator new (size_t n)
{
cout<<"void *operator new (size_t)"<<endl;
return malloc(n);
}
//delete表达式
void operator delete(void *p)
{
cout<<"void operator delete (void *)"<<endl;
free(p);
}
void print()
{
cout<<"name:"<<_name<<endl;
cout<<"id:"<<_id<<endl;
}
void realse()
{
/* this->~Student(); */
/* operator delete (this); */
//上面两行代码实际上是delete表达式的工作
//故可合并为下面这行代码
delete this;
}
//析构函数私有化
private:
~Student()
{
if(_name)
{
delete[] _name;
_name = nullptr;
}
cout<<"~Student()"<<endl;
}
private:
char *_name;
int _id;
};
void test(){
Student *pstu = new Student("Xiaoming",100);
pstu->print();
/* delete pstu; //无法在类之外回收对象 */
//因为析构函数私有化了
pstu->realse();
}
int main()
{
test();
return 0;
}
效果:
实现了在栈上是无法创建对象的功能。
有时候需要限制对象只能在堆上创建的原因包括:
对象生命周期的灵活性:堆对象的生命周期不受作用域的限制,可以在需要的时候手动管理对象的创建和销毁。这可以用于动态地创建对象,并在需要时将对象传递给其他函数或对象。
对象共享和持久性:堆对象可以被多个函数或对象共享访问,而不受作用域的限制。这使得堆对象可以在多个上下文中传递和使用,从而提供了更大的灵活性。
对象的生存期延长:堆对象的生存期可以延长到其显式释放或删除为止。这可以用于创建长期存在的对象,或者需要跨函数或模块传递的对象。
需要注意的是,如果一个类只能生成堆对象,那么在使用该类时应该遵循这个规定,不应该直接在栈上创建对象。否则,编译器可能会报错。
总结起来,限制一个类只能生成堆对象可以提供灵活的对象生命周期、对象共享和持久性,以及延长对象生存期的能力。但也需要在使用时遵循这个限制,避免在栈上直接创建对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 七八分钟快速用k8s部署springboot前后端分离项目
- 【UE5】物体上显示UI、Widget不在物体上而在地图原点或其他地方的问题
- 【Spring】15 MessageSourceAware 接口
- 基于 InternLM 和 LangChain 搭建你的知识库
- Python爬虫淘宝家用电器爬虫数据可视化分析大屏全屏系统
- <meta name=“Keywords“ content=““ >、<meta name=“Description“ content=““ > 等用法解释
- java SSM体育器材租借管理系统myeclipse开发mysql数据库springMVC模式java编程计算机网页设计
- MYSQL数据库详解(1) -- 数据库概述
- 实验数据:practice15_data.csv,使用循环绘制所有催化剂条件下,物质1转化率与温度关系的6*4的子图(python)
- Mybatis配置-映射器(mappers)