第六章 TensorRT模型优化部署(六)--Quantization量化基础(一)
系列文章目录
第一章 TensorRT优化部署(一)–TensorRT和ONNX基础
第二章 TensorRT优化部署(二)–剖析ONNX架构
第三章 TensorRT优化部署(三)–ONNX注册算子
第四章 TensorRT模型优化部署(四)–Roofline model
第五章 TensorRT模型优化部署(五)–模型优化部署重点注意
第六章 TensorRT模型优化部署(六)–Quantization量化基础(一)
第七章 TensorRT模型优化模型部署(七)–Quantization量化(PTQ and QAT)(二)
文章目录
前言
学习笔记
- 理解什么叫量化
- PTQ量化和QAT的区别
- calibration种类
- Per-tensor量化与Per-layer量化
- 量化的技巧
- 掉精度时需要做的事情(一般控制精度掉点在2%以内)
- 量化与融合优化以及多余算子
一、量化(quantization)
模型量化是通过减少模型中计算精度从而减少模型整体的计算量的的一种方法。计算精度可以分为FP32, FP16, FP8, INT8, INT32, TF32。
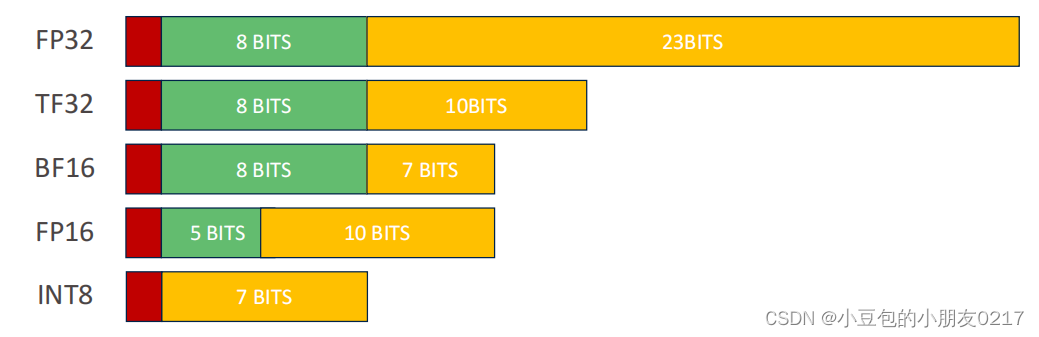
存储FP32需要4个字节,但存储INT8只需要一个字节。因为训练的时候,想训练到非常细节的部分,所以使用FP32。使用INT8量化即可只用8个bit就把FP32的数据给表现出来,那么就可以减少计算量以及能源消耗。
量化针对的是
? activation value
? weight
所以一般来说会对conv或者linear这些计算密集型算子进行量化
二、量化的基本原理
2.1 映射和偏移
动态范围如下:

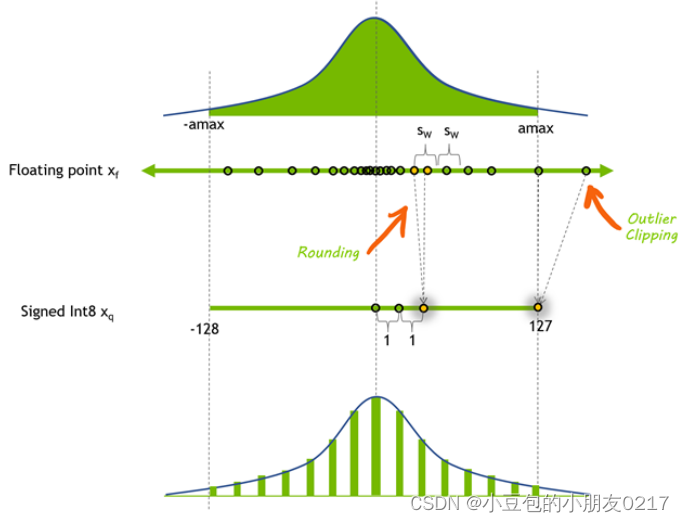
仅仅用256种数据去表现FP32的所有可能出现的数据,有可能会造成表现力下降。如果能够比较完美的用这256个数据去最大限度的表现FP32的原始数据分布,是量化的一个很大挑战。换句话说,就是如何合理的设计这个dynamic range是量化的重点。
- R是一组FP32的数据,能够表现的数据种类有很多,大约是2^32种(4亿),
? 范围是: ?1.2 ? 10?38 ~ 3.4 ? 1038 - Q是一组INT8的数据,只能够表现2^8种数据(256)。
? 范围是:-128 ~128 or 0 ~ 255 - R到Q的映射的缩放因子scale的计算公式为:
? scale =(𝑅𝑚𝑎𝑥?𝑅𝑚𝑖𝑛)/(𝑄𝑚𝑎𝑥?𝑄𝑚𝑖𝑛) - R缩放之后映射到Q时,所需要的偏移量z为:
? 𝑧 = (𝑄𝑚𝑖𝑛 ?𝑅𝑚𝑖𝑛)/𝑟𝑎𝑡𝑖𝑜 - 这样R中每一个元素转移到Q的过程称为量化(Quantization),公式是
? 𝑄𝑖 =𝑅𝑖/𝑠𝑐𝑎𝑙𝑒+ 𝑧 - 将Q空间中一个元素转换回R的空间的过程为反量化(Dequantization),公式是
? 𝑅𝑖 = (𝑄𝑖 ? 𝑧) ? 𝑠𝑐𝑎𝑙e
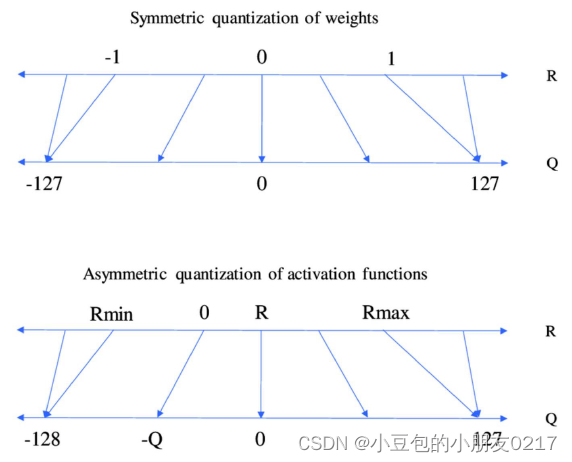
2.2 对称映射,非对称映射
根据R和Q的dynamic range的选择以及mapping的方式,可以分为对称映射(symmetric quantization)以及非对称映射(asymmetricquantization)。
对称量化中量化前后的0是对齐的,所以不会有偏移量(z, shift)的存在,这个可以让量化过程的计算简单。NVIDIA默认的mapping就是对称量化,因为快!
2.3.Quantization Granularity(量化粒度)
Quantization Granularity(量化粒度)指的是对于一个Tensor,以多大的粒度去共享scale和z,或者dynamic range。
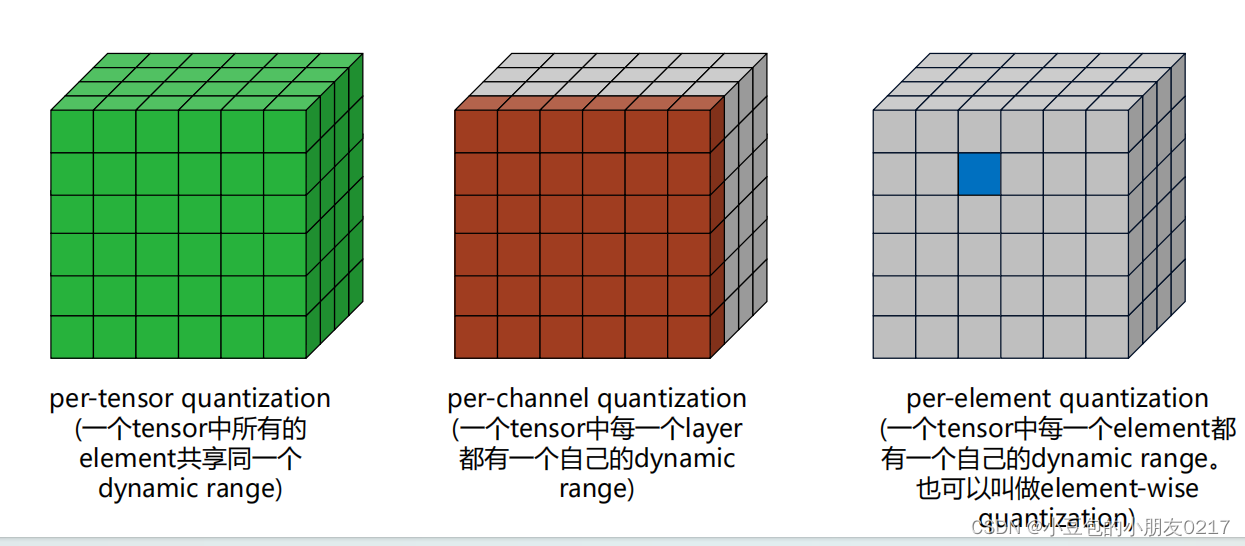
per-tensor的scale一样,存储的东西都一样,所以比较方便,per-element每个element存储的内容不一样,所以计算复杂,一般不用。

左边是Per-tensor量化
- 优点:低延迟,一个tensor共享同一个量化参数
- 缺点:高错误率,一个scale很难覆盖所有的FP32的dynamic range
右边是Per-channel量化
- 优点:低错误率,每一个channel都有自己的scale来体现这个channel中数据的dynamic range
- 缺点:高延迟,需要使用vector来存储每一个channel的scale
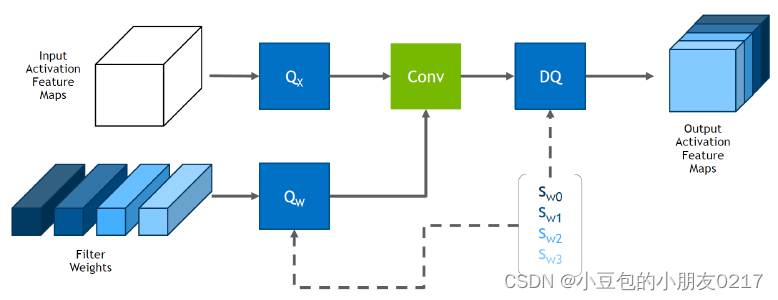
从很多实验结果与测试中,对于weight和activation values的量化方法,一般会选取
? 对于activation values,选取per-tensor量化
? 对于weights,选取per-channel量化
从图中可以看出,Activation feature maps都是使用同一个量化系数,但是Filter Weights中每一个权重都有一个量化系数。
为什么weight需要per-channel呢?
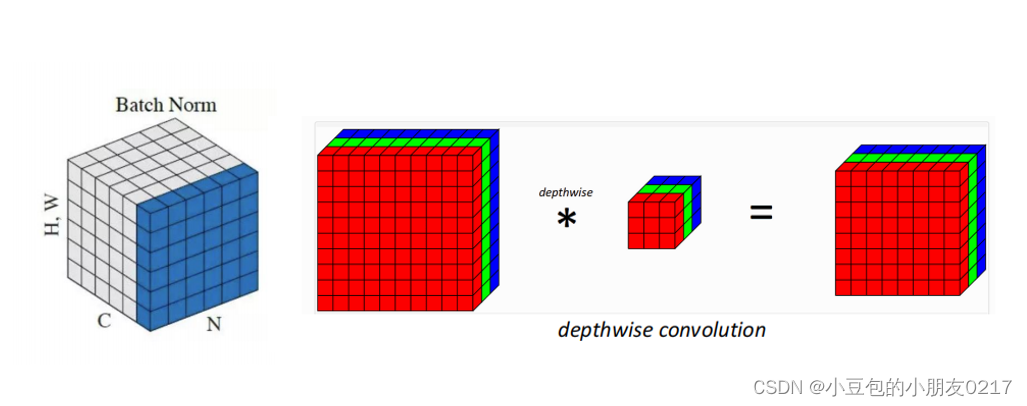
? BN计算与线性计算的融合 (BN folding)
线性变化𝑦 = 𝑤 ? 𝑥的BN folding可以把BN的参数融合在线性计算中。但是BN的可参数是per-channel的。如果weights用per-tensor的话,会掉精度。
? depthwise convolution
depthwise convolution中kernel的channel size是1,每一个kernel针对输入的对应的channel做卷积。所以每一个channel中的参数可能差别会比较大。如果用per-tensor的话容易掉精度比较严重
2.4. Quantization Calibration(校准)
对于一个训练好的模型,权重是固定的,所以可以通过一次计算就可以得到每一层的量化参数。
但是activation value(激活值)是根据输入的改变而改变的。所以需要通过类似于统计的方式去
寻找对于不同类型的输入的不同的dynamic range。这个过程叫做校准,跟量化粒度一样,不同的校准算法的选择会很大程度影响精度!
2.4.1 Calibration dataset
针对不同的输入,各层layer的input activation value都会有不同的分布和取值。大数据集的差别比较大。我们需要通过训练数据集中的一部分数据来尝试表征整个数据集的分布。这个小数据集就是calibration dataset。一般往往很小,但需要尽量有整体的表征(500-1500张图片)。
2.4.2 Calibration algorithm
calibration的过程一般是在模型训练以后进行的,所以一般与PTQ(*)搭配使用。
流程如下:
? 在calibration dataset中做一次FP32的推理
? 以histogram的形式去统计每一层的floating point的分布(注意,因为activation value是per-tensor quantization)
? 寻找能够表征当前层的floating point分布的scale
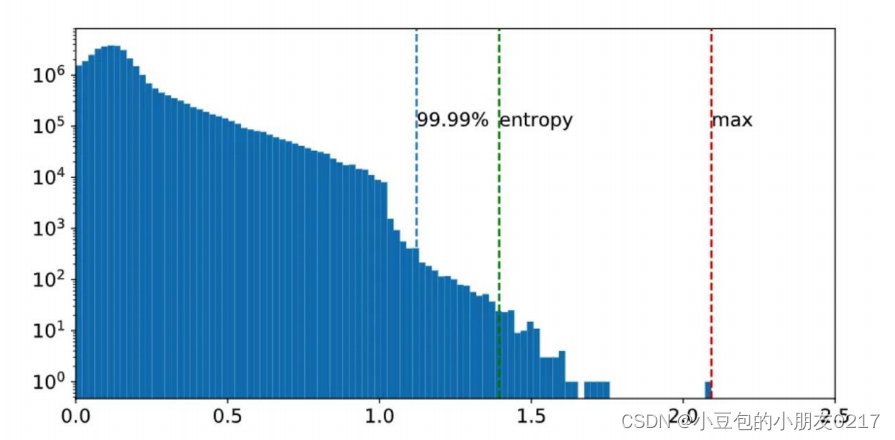
有几种不同的算法:
Minmax calibration(最小最大校准)
Entropy calibration(交叉熵校准)
Percentile calibration(百分比校准)
-
Minmax calibration(最小最大校准)
FP32->INT8的scale需要能够把FP32中的最大最小值都给覆盖住。如果floating point的分布比较离散,各个区间下的分布都比较均匀,minmax是个不错的选择。然而,如果只是极个别数据分布在这种地方的话,会让dynamic range变得比较稀疏,不适合用minmax。
-
Entropy calibration(交叉熵校准)
通过计算KL散度,寻找一种threashold,能够最小化量化前的FP32的浮点数分布于INT8的量化后整型分布。目前TensorRT使用默认的是Entropycalibration。
-
Percentile calibration(百分比校准)
表示的是FP32中占据99.99%的浮点数参与量化。这样可以避免极个别特殊点(误差)参与量化,导出量化出现问题。Percentile有99.9%, 99.99%,99.999%等等。

官方文档提供了相应的接口。
官方文档地址:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c
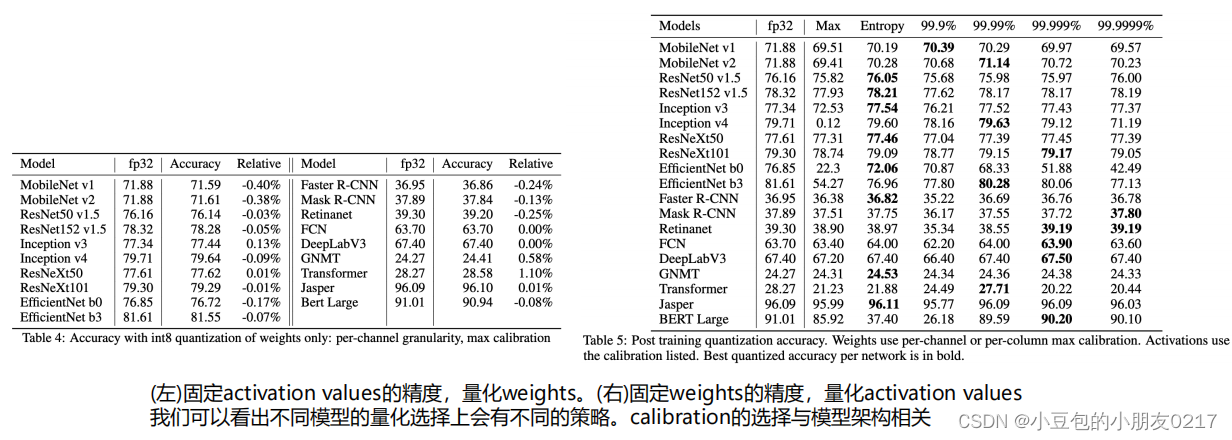
? weight的calibration,选用minmax
? activation的calibration,选用entropy或者percentile
2.4.3 calibration dataset与batch size的关系
在使用calibration dateset中构建histogram是需要注意的一个点:
- calibration时的batch size会影响精度。更准确来说会影响histogram的分布,这个跟TensorRT在构建浮点数的histogram的算法有关。
创建histogram直方图的时候,如果出现了大于当前histogram可以表示的最大值的时候,TensorRT会直接平方当前histogram的最大值,来扩大存储空间
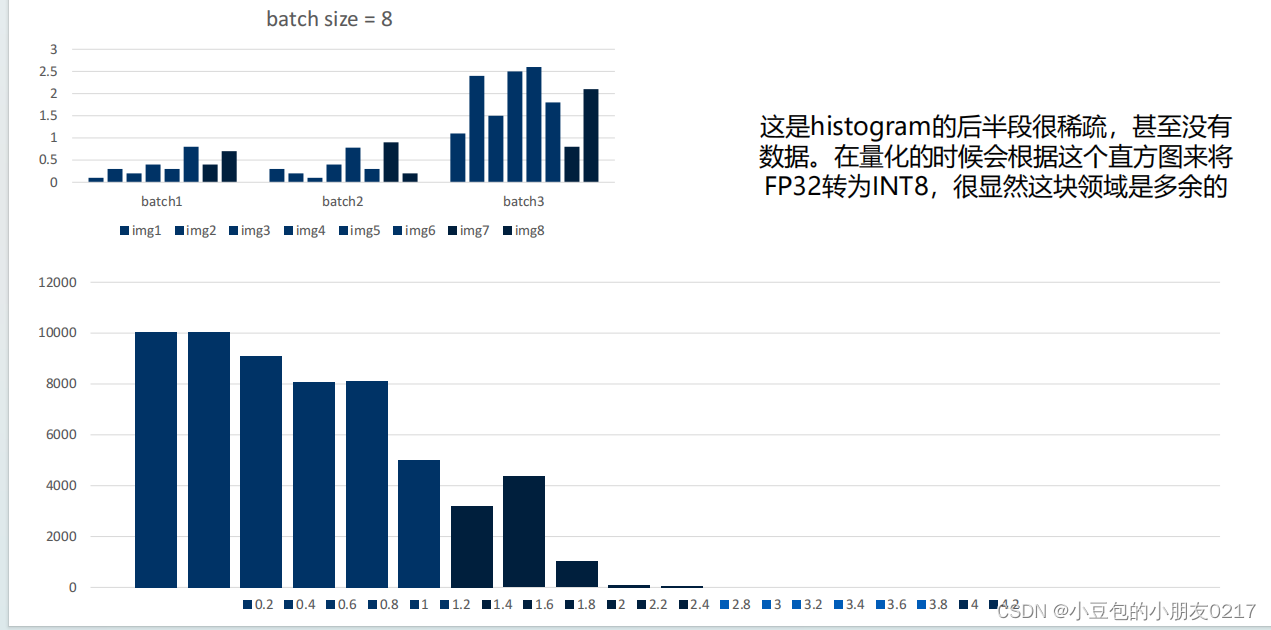
可以看出,每个batch包含8张图片,batch1最大值不到1,batch3最大值为2.5,数据分布不均匀,量化时就会出现后半段稀疏的情况。
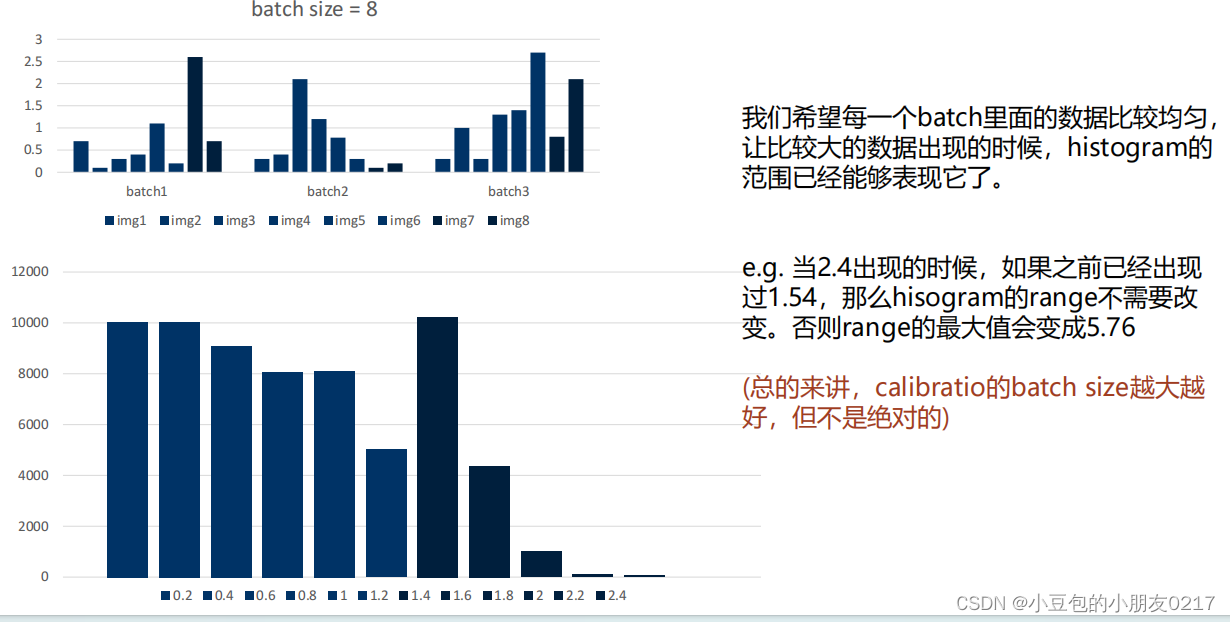
总结
接下来介绍PTQ和QAT
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!