随机森林算法
发布时间:2023年12月18日
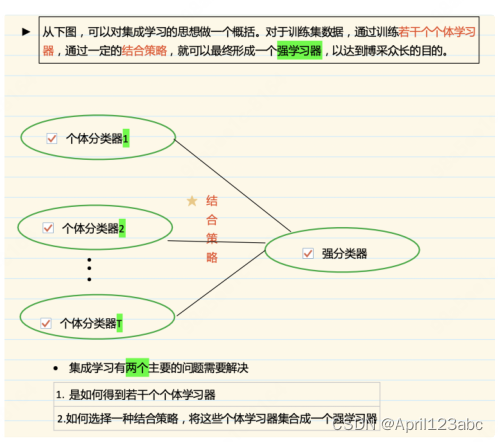
随机森林是?种利?多棵树对样本进?训练并预测的分类器,属于Bagging的
并?式集成学习?法。它通过有放回的采样?式添加样本扰动,同时引?属性扰
动,在基决策树的训练过程中,先从候选属性集中随机挑选出?个包含K个属性的
?集,再从这个?集中选择最优划分属性。随机森林中基学习器的多样性不仅来?
样本扰动,还来?属性扰动,从?进?步提升了基学习器之间的差异度。
Bootstraping/?助法
- Bootstraping的名称来?成语“pull up by your own bootstraps”,意思是依靠你??的资源,称为?助法,它是?种有放回的重抽样?法。
- 附录:Bootstrap本义是指?靴??后?的悬挂物、?环、 带?,是穿靴?时??向上拉的?具,“pull up by your own bootstraps”即“通过拉靴?让??上升”,意思是 “不可能发?的事情”。后来意思发?了转变,隐喻 “不需要外界帮助,仅依靠?身?量让??变得更好”。
Bagging/套袋法
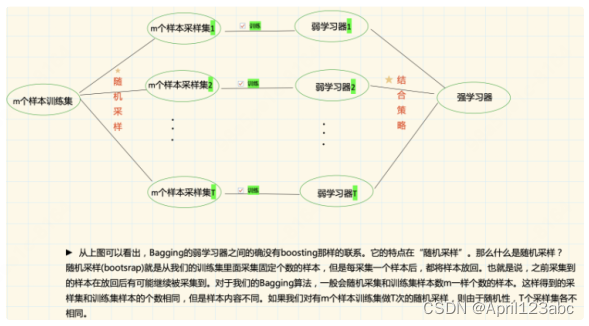
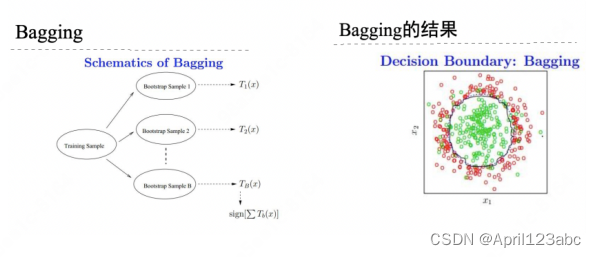
bootstrap aggregation
- 从样本集中重采样(有重复的)选出n个样本
- 在所有属性上,对这n个样本建?分类器 (ID3、C4.5、SVM、Logistic回归等)
- 重复以上两步m次,即获得了m个分类器
- 将数据放在这m个分类器上,最后根据这m个分类器的投票结果,决定数据属于哪?类
集成学习之结合策略
-
投票法
-
平均法
-
学习法/Stacking

import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['font.size'] = 15
plt.rcParams['axes.unicode_minus'] = False
X,y = make_moons(n_samples=500,noise=0.30,random_state=43)
# print(X)
# print(y)
X_train, X_test,y_train,y_test = train_test_split(X, y, random_state=43)
plt.figure(figsize=(10,6))
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha=0.5,label='类别0')
plt.plot(X[:,0][y==1],X[:,1][y==1],'gs',alpha=0.6,label='类别1')
plt.legend()
plt.show()运行结果

硬投票代码
# 硬投票
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.ensemble import VotingClassifier # 投票分类器
from sklearn.linear_model import LogisticRegression # 线性回归模型里的逻辑回归
from sklearn.svm import SVC # 支持向量积
log_clf = LogisticRegression(random_state=42)
deci_clf = DecisionTreeClassifier(random_state=42)
svc_clf = SVC(random_state=42)
# 集成
voting_clf = VotingClassifier(estimators=[('lr',log_clf),('deci',deci_clf),('svc', svc_clf)],voting='hard')
# 模型的准确率
from sklearn.metrics import accuracy_score
for clf in (log_clf,deci_clf,svc_clf,voting_clf):
# 拟合
clf.fit(X_train,y_train)
# 进行预测
y_pred = clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test, y_pred))运行结果
LogisticRegression 0.864
DecisionTreeClassifier 0.856
SVC 0.896
VotingClassifier 0.904
软投票代码
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.ensemble import VotingClassifier # 投票分类器
from sklearn.linear_model import LogisticRegression # 线性回归模型里的逻辑回归
from sklearn.svm import SVC # 支持向量积
log_clf = LogisticRegression(random_state=42)
deci_clf = DecisionTreeClassifier(random_state=42)
svc_clf = SVC(probability=True, random_state=42)
# 集成
voting_clf = VotingClassifier(estimators=[('lr',log_clf),('deci',deci_clf),('svc', svc_clf)],voting='soft')
# 模型的准确率
from sklearn.metrics import accuracy_score
for clf in (log_clf,deci_clf,svc_clf,voting_clf):
# 拟合
clf.fit(X_train,y_train)
# 进行预测
y_pred = clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test, y_pred))运行结果
LogisticRegression 0.864
DecisionTreeClassifier 0.856
SVC 0.896
VotingClassifier 0.912
随机森林分类算法
参数说明:
- n_estimators:决策树的数量,也就是“森林”的??。
- criterion:决定节点分裂的条件。可以是"gini"(基尼指数)或"entropy"(信息熵)。基尼指数衡量的是样本的不纯度(purity),信息熵衡量的是信息的量。
- max_depth:决策树的最?深度。
- min_samples_split:?个节点在被考虑分裂前必须具有的最?样本数。
- min_samples_leaf:叶?节点(即最终的预测节点)?少需要包含的最?样本数量。
- max_features:在分裂节点时考虑的最?特征数量。设置为'auto'时,通常会根据树的深度动态调整。
- bootstrap:是否使??举样本(bootstrap samples)训练森林。
- oob_score:是否使?Out-of-Bag (OOB)样本进?模型评估。
代码实现:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器实例并设置参数
rf = RandomForestClassifier(n_estimators=100, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, max_features='auto', bootstrap=True, oob_score=True)
# 训练模型
rf.fit(X_train, y_train)
# 预测测试集结果
y_pred = rf.predict(X_test)
# 计算并输出预测准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')随机森林回归算法
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_iris()
X = boston.data
y = boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, r
andom_state=42)
# 创建随机森林回归器实例并设置参数
rf = RandomForestRegressor(n_estimators=100, criterion='squared_error', ma
x_depth=None, min_samples_split=2, min_samples_leaf=1, max_features='auto'
, bootstrap=True)
# 训练模型
rf.fit(X_train, y_train)
# 预测测试集结果
y_pred = rf.predict(X_test)
# 计算并输出均?误差(MSE)
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')医疗费用预测和评估
# 医疗费用预测和评估
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv('insurance.csv')
df运行结果

# 看下数据的整体情况
df.info()运行结果

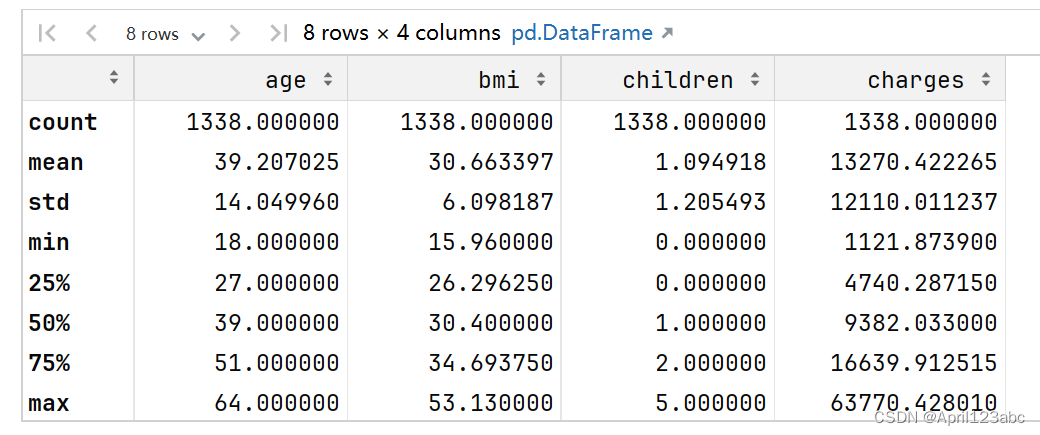
df.describe()运行结果
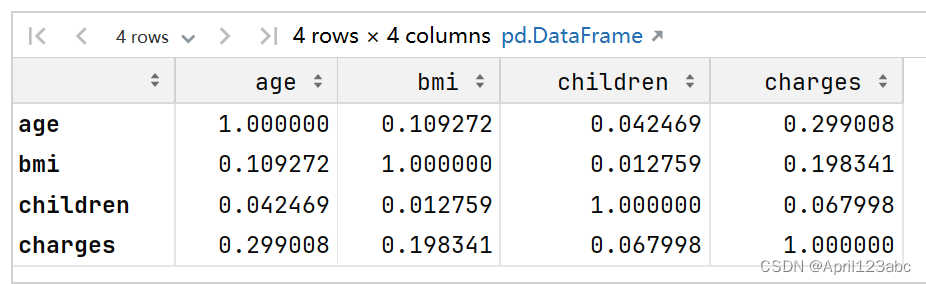
# 查看相关性
df[['age','bmi','children','charges']].corr()运行结果?
# 可视化
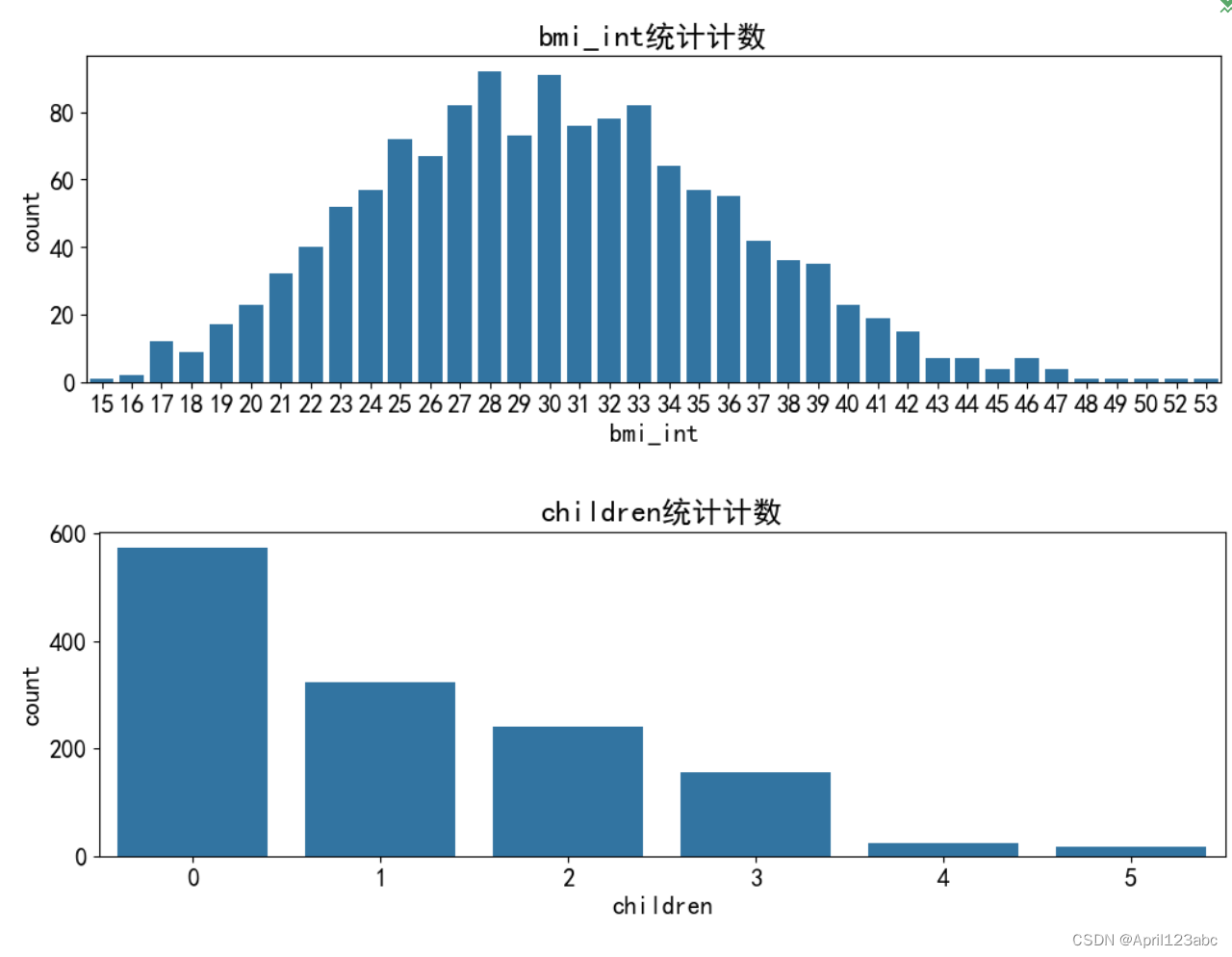
df['bmi_int'] = df['bmi'].astype('int')
import seaborn as sns
variables = ['sex','smoker','region','age','bmi_int','children']
for v in variables:
plt.figure(figsize=(12,3.5))
sns.countplot(data=df,x=v)
plt.title(f'{v}统计计数')
plt.show()运行结果?


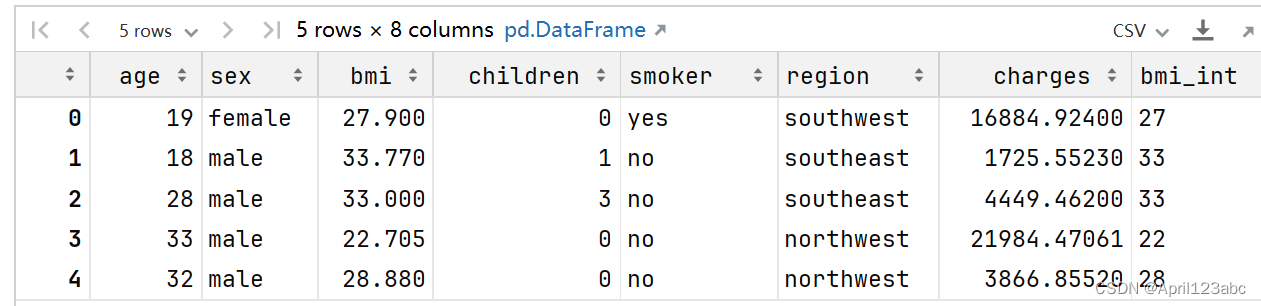
# 数据的预处理
df.head()运行结果
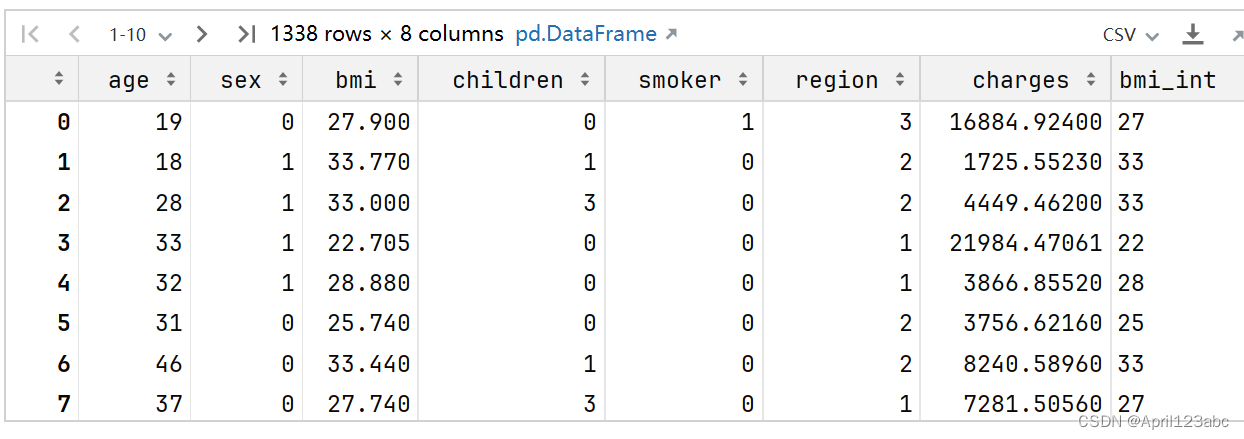
from sklearn.preprocessing import LabelEncoder,StandardScaler
from sklearn.ensemble import RandomForestRegressor
le = LabelEncoder()
df['sex'] = le.fit_transform(df['sex'])
df['smoker'] = le.fit_transform(df['smoker'])
df['region'] = le.fit_transform(df['region'])
df运行结果
df.describe()运行结果?
variables = ['sex','smoker','region','age','bmi','children']
# 标准化处理
X = df[variables]
sc = StandardScaler()
# 特征
X = sc.fit_transform(X)
# 目标值
y = df['charges']
X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.2,random_state=2)
# 建模
rnf_regressor = RandomForestRegressor(n_estimators=200)
rnf_regressor.fit(X_train, y_train)
y_train_pred = rnf_regressor.predict(X_train)
y_test_pred = rnf_regressor.predict(X_test)
from sklearn.metrics import mean_absolute_error,mean_squared_error
# 在训练集上
print(mean_absolute_error(y_train,y_train_pred))
print(mean_squared_error(y_train,y_train_pred))
# 在测试集上
print(mean_absolute_error(y_test,y_test_pred))
print(mean_squared_error(y_test,y_test_pred))
# 用评分的方式看
print(rnf_regressor.score(X_train,y_train))
print(rnf_regressor.score(X_test,y_test))运行结果
987.45084015913
3204045.9140575663
2715.7909218017735
24515377.160285443
0.9779906619847902
0.8367608682373264
文章来源:https://blog.csdn.net/April123abc/article/details/134885169
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 常见LeetCode排序算法
- 【Python_PySide6学习笔记(三十)】基于PySide6实现无边框主窗体框架:可实现主题切换、增加导航栏(2种方式)、窗体大小缩放等功能
- 使用 AlgorithmStar and Spark 实现 词频统计
- Spark内核解析-数据存储5(六)
- “超人练习法”系列10:耶克斯–多德森定律2
- 华为鸿蒙操作系统简介及系统架构分析(2)
- 大创项目推荐 深度学习卫星遥感图像检测与识别 -opencv python 目标检测
- Linux搭建和使用redis
- 卷麻了,00后测试用例写的比我还好,简直无地自容......
- 小团体~抱团学习了!