设计一个Key-Value缓存去存储最近的Web Server查询的结果
发布时间:2024年01月20日
1: 定义Use Case和约束
Use Cases
我们可以定义如下 Scope:
- User 发送一个 search request, 缓存命中成功返回Data
- User 发送一个 search request, 缓存未命中,未成功返回Data
- Service 有高可用
约束和假设
状态假设
- Traffic 分布不是均匀的
- 热度高的查询总是被缓存
- 需要去确定怎样去 expire/refresh
- Cache 服务的查询要快
- 在机器之间有低延迟
- 在内存中有受限的内存
- 需要决定神魔时候保留/移除缓存
- 需要缓存数百万Query
- 1千万 user
- 100 亿 query/ 月
计算使用量
- Cache 存储排序后的 key 的 list: query, value: list
- query - 50 bytes
- title - 20 bytes
- snippet - 200 bytes
- Total: 270 bytes
- 2.7 TB 缓存数据 / 月,如果所有 100 亿query 都是独特的,并且都被存储
- 270 bytes / 每个搜索 * 100 亿 搜索 / 每月
- 假设状态受限的内存,需要去决定怎样去 exopire 内容
- 4000 请求 / s
简易转换指南:
- 250 万 s/ 每个月
- 1 request / s = 250 万请求 / 月
- 40 request / s = 1 亿 请求 / 月
- 400 request / s = 10 亿 请求 / 月
2: 创建一个High Level Design
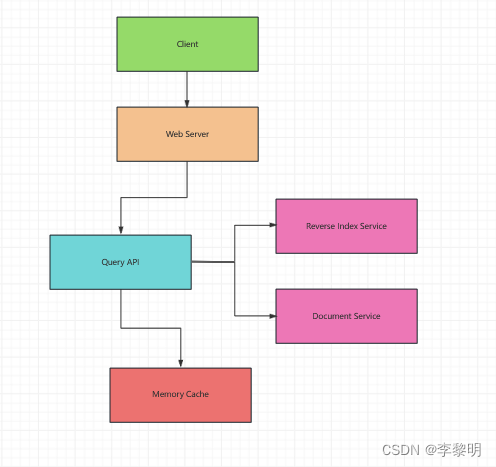
3: 设计核心组件
Use Case: User 发送一个请求,然后缓存命中
由于Cache的容量是固定的,我们将使用 a least recently used(LRU) 方法去过期的老 entiies.
- Client 发送一个请求到 Web Server
- Web Server 转发请求到 Query API Server
- Query API 会做下面的事情
- 解析 query
- 移除 markup
- 分解 text 进 terms
- Fix typos
- 格式化首字母
- 转换 query 去 使用 bool 操作
- 检查缓存中和 query 匹配的 content
- 如果有缓存击中,缓存会做下面的事情
- 更新缓存entry的位置到LRU List的前面
- 返回缓存内容
- 否则,Query API 做下面的事情:
- 使用 Reverse Index Service 去寻找到匹配 query 的 document
- Reverse Index Service 排序搜索结果然后返回Top one
- 使用 Document Service 去返回 title 和 snippets
- 伴随着 content去更新 Memory Cache,放这个 entry 进 LRU list的前面
- 使用 Reverse Index Service 去寻找到匹配 query 的 document
- 如果有缓存击中,缓存会做下面的事情
Cache 实现
cache 使用双向链表:新的 items 会被添加到头节点,当items 过期时会被为尾节点移除,我们可以使用Hash 表来快速查找每一个 linked list node.
Query API Server 实现:
class QueryApi(object):
def __init__(self, memory_cache, reverse_index_service):
self.memory_cache = memory_cache
self.reverse_index_service = reverse_index_service
def parse_query(self, query):
"""Remove markup, break text into terms, deal with typos,
normalize capitalization, convert to use boolean operations.
"""
def process_query(self, query):
query = self.parse_query(query)
results = self.memory_cache.get(query)
if results is None:
results = self.reverse_index_service.process_search(query)
self.memory_cache.set(query, results)
return results
Node 实现:
class Node(object):
def __init__(self, query, results):
self.query = query
self.results = results
LinkedList 实现:
class LinkedList(object):
def __init__(self):
self.head = None
self.tail = None
def move_to_front(self, node):
...
def append_to_front(self, node):
...
def remove_from_tail(self):
...
Cache 实现:
class Cache(object):
def __init__(self, MAX_SIZE):
self.MAX_SIZE = MAX_SIZE
self.size = 0
self.lookup = {}
self.linked_list = LinkedList()
def get(self, query)
""" Get the stored query result from the cache
Accessing a node update its position to the front of the LRU list.
"""
node = self.lookup[query]
if node is None:
return None
self.linked_list.move_to_front(node)
return node.results
def set(self, results, query):
""" Set the result for the given query key in the cache
When updating an entry, updates its position to the front of the LRU list.
If the entry is new and the cache is at capacity, removes the oldest entry
before the new entry is added.
"""
node = self.lookup[query]
if node is not None:
node.results = results
self.linked_list.move_to_front(node)
else:
if self.size == self.MAX_SIZE:
self.loopup.pop(self.linked_list.tail.query, None)
self.linked_list.remove_from_tail()
else:
self.size += 1
new_node = Node(query, results)
self.linked_list.append_to_front(new_node)
self.lookup[query] = new_node
会在如下时间Update Cache:
- Page 的 content 改变
- Page 被移除 或者 新page 被添加
- Page 排名改变
处理这些情况最简单的方法是简单地设置缓存条目在更新之前可以保留在缓存中的最大时间,通常称为生存时间(TTL)。
4:扩展设计
扩展缓存到多台机器
为了处理重负载请求和大量需要的内存,我们需要水品扩展,我们有三个选择关于怎样存储数据进 Memory Cache cluster:
- 每一个在缓存集群中的机器有自己的 Cache - 简单,尽管它会有一个低缓存命中率的结果
- 每一个在缓存集群中的机器有自己的 Cache 复制 - 简单,尽管hi有无效的内存使用
- 缓存集群重的缓存会被分散在所有的机器上 - 复杂,尽管这可能是最好的选项,我们可以使用 Hash去确定哪一个机器会得到针对单个查询的结果,通过使用
machine = hash(query. 我们将想要去使用 持续性 hash.
文章来源:https://blog.csdn.net/weixin_44125071/article/details/135721086
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 视频号小店如何运营?流程跑通就成功了一大半!
- java18
- 字符串倒序输出
- Tarjan-eDcc,边双连通分量问题,eDcc缩点问题
- 基于SpringBoot+Vue实现的在线小说阅读系统
- 安装程序不能创建目录“E:\Microsoft VS Code“ 错误 5 :拒绝访问
- openGauss学习笔记-198 openGauss 数据库运维-常见故障定位案例-分析查询效率异常降低的问题
- QML中加载数据时卡顿怎么处理
- Grounding 模型 + SAM 报错
- @Scheduled注解