菜鸟网络Java实习一面面经
自我介绍,做过的项目
巴拉巴拉
你项目中用到redis,可以介绍一下为什么使用它吗?
基于内存操作,内存读写速度快。
支持多种数据类型,包括String、Hash、List、Set、ZSet等。
支持持久化。Redis支持RDB和AOF两种持久化机制,持久化功能可以有效地避免数据丢失问题。
支持事务。Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
支持主从复制。主节点会自动将数据同步到从节点,可以进行读写分离。
Redis命令的处理是单线程的。Redis6.0引入了多线程,需要注意的是,多线程用于处理网络数据的读写和协议解析,Redis命令执行还是单线程的。
redis为什么性能好
- 基于内存:
Redis是使用内存存储,没有磁盘IO上的开销。数据存在内存中,读写速度快。
- IO多路复用模型:
Redis 采用 IO 多路复用技术。
I/O :网络 I/O;多路:多个 TCP 连接;复用:共用一个线程或进程。
生产环境中的使用,通常是多个客户端连接 Redis,然后各自发送命令至 Redis 服务器,最后服务端处理这些请求返回结果。应对大量的请求,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后逐个被执行。最终将结果返回给客户端。
- 单线程
redis是单线程的,避免了上下文切换
- 高效的数据结构:
Redis 每种数据类型底层做了优化,有高效的数据结构和合理的编码
redis如何处理分布式任务
1. 主从模式(读写分离)
redis单节点虽然有通过RDB和AOF持久化机制能将数据持久化到硬盘上,但数据是存储在一台服务器上的,如果服务器出现硬盘故障等问题,会导致数据不可用,而且读写无法分离,读写都在同一台服务器上,请求量大时会出现I/O瓶颈。
为了避免单点故障 和 读写不分离,Redis 提供了复制(replication)功能实现master数据库中的数据更新后,会自动将更新的数据同步到其他slave数据库上。
2. 哨兵模式
哨兵模式核心还是主从复制,只不过在相对于主从模式在主节点宕机导致不可写的情况下,多了一个竞选机制:从所有的从节点竞选出新的主节点。竞选机制的实现,是依赖于在系统中启动一个sentinel进程。
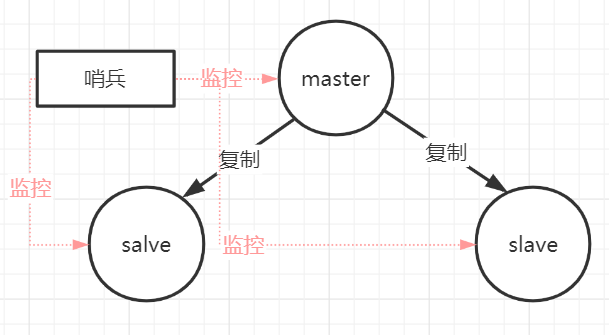
但是哨兵本身也可能遇到单点故障的问题,所以在一个一主多从的Redis系统中,可以使用多个哨兵进行监控,哨兵不仅会监控主数据库和从数据库,哨兵之间也会相互监控。
3. Redis集群方案 (cluster模式)
Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
节点的fail是通过集群中超过半数的节点检测失效时才生效
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
Cluster模式的具体工作机制:
在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
redis如何实现一个队列和栈
栈
用LPUSH创建名为“stack”的key并放入元素,使用LRANGE查看放入的元素,使用LPOP取出放入的元素;可以发现取出的顺序与放入的顺序相反(先进后出)
LPUSH stack q w e r t y u i o p
LRANGE stack 0 -1
LPOP stack
队列
LPUSH queue q w e r t y u i o p
LRANGE queue 0 -1
RPOP queue
redis有哪几种类型,可以介绍一下吗?
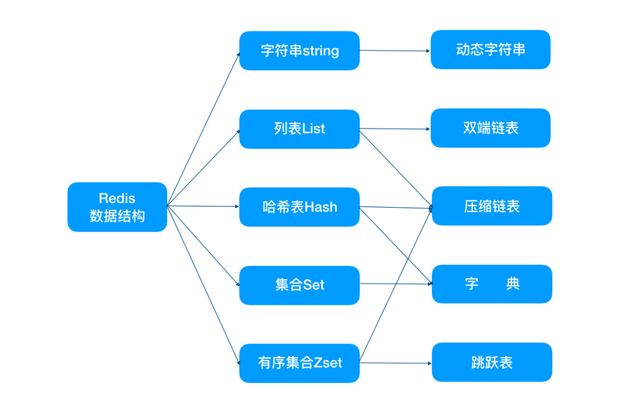
Redis支持5种核心的数据类型,分别是字符串、哈希、列表、集合、有序集合;
Redis还提供了Bitmap、HyperLogLog、Geo类型,但这些类型都是基于上述核心数据类型实现的;
Redis在5.0新增加了Streams数据类型,它是一个功能强大的、支持多播的、可持久化的消息队列。
看你项目中用到了elasticsearch,介绍一下es如何实现数据同步?
同步双写
这是一种比较简单的方式,就是在将数据写入到MySQL的时候,同时将数据写入到ES,实现数据的双写。
异步双写(MQ方式)
针对第一种同步双写的性能和数据丢失问题,可以考虑引入MQ,从而形成异步双写的方案。
由于MQ的性能基本比mysql高出一个数量级,所以性能可以得到显著的提高。
异步双写(Worker方式)
上面方案中都存在硬编码问题,也就是有任何对mysq进行增删改查的地方植入ES代码,代码的侵入性太强。
如果对实时性要求不高的情况下,可以考虑用定时器,比如logstash处理,具体步骤如下:
数据库的相关表中增加一个字段为timestamp的字段,任何crud操作都会导致该字段的时间发生变化;
原来程序中的CURD操作不做任何变化;增加一个定时器程序,让该程序按一定的时间周期扫描指定的表,把该时间段内发生变化的数据提取出来;逐条写入到ES中。
注:
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中
Binlog 同步方式:
上面方案要么有代码侵入,要么有硬编码,要么有时延,第4中方案,可以使用go-mysql-elasticsearch插件实现相关功能,他是利用mysql的binlog来进行同步
具体步骤如下:
1) 读取mysql的binlog日志,获取指定表的日志信息;
2) 将读取的信息转为MQ;
3) 编写一个MQ消费程序;
4) 不断消费MQ,每消费完一条消息,将消息写入到ES中。
说一下选择排序和冒泡排序
冒泡排序
从第一个数开始,依次往后进行相邻两个数之间的比较,如果前面的数比后面的数大就交换这两个数的位置,如果前面的数较小或两者一样大,就不作处理。
选择排序
选择排序法就是从需要排序的数据元素中 选出最小或最大的一个元素,把他和第一个位置的元素进行互换。
来写一段sql吧:有一张表,有id,name,type三个类型,选择每种类型中id最大的数据
假设这张表名为data_table
SELECT type, MAX(id) AS max_id
FROM data_table
GROUP BY type;本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [DevOps-04] Operate阶段工具
- Leetcoder Day3|链表理论基础|203.移除链表元素 |707.设计链表 |206.反转链表
- qt,tooptip鼠标移到控件上,就会出现弹窗,实时显示数据
- 【重点!!!】【栈】394.字符串解码
- 优地科技荣获2023年度小巨人创新奖
- 【问题思考总结】磁盘和内存的映射谁来保存?
- 如何让自己的写的程序在阿里云一直运行
- 前端vue2使用国密SM4进行加密、解密
- Java求解算法题两数之和——两数之和 - 力扣(数组/哈希表/递归/两次for循环)
- 大模型上下文扩展之YaRN解析:从直接外推ALiBi、位置插值、NTK-aware插值、YaRN