爬虫工作量由小到大的思维转变---<第二十八章 Scrapy中间件说明书>
爬虫工作量由小到大的思维转变---<第二十六章 Scrapy通一通中间件的问题>-CSDN博客
前言:
(书接上面链接)自定义中间件玩不明白? 好吧,写个翻译的文档+点笔记,让中间件更通俗一点!!!
正文:
全局图: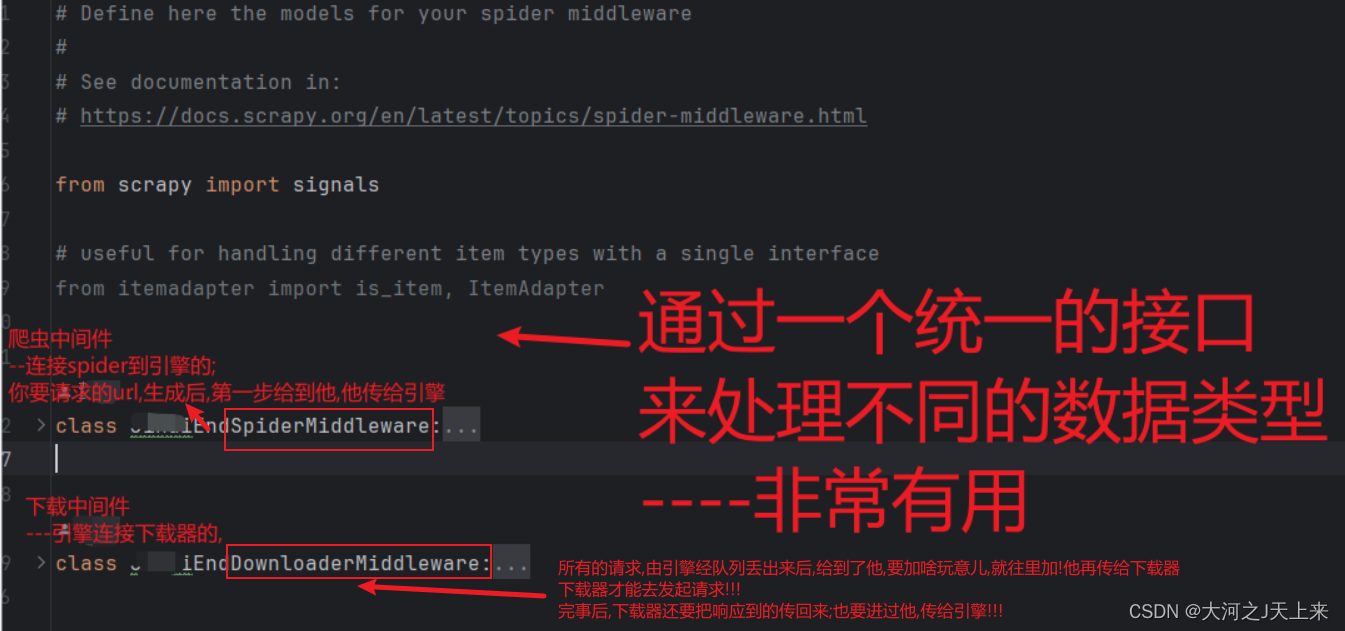
爬虫中间件--->翻译+笔记:
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class XXXSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
#--翻译-># 并非所有方法都需要被定义。如果某个方法没有被定义,
# Scrapy 将会假设蜘蛛中间件不会修改传递的对象。
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
#这个方法被用于创建你的Scrapy蜘蛛。
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
# --翻译--># 这个方法由Scrapy用于创建你的蜘蛛。
# 对于每个通过蜘蛛中间件到达蜘蛛的响应,会被调用。
# 应该返回None或引发异常。
# --->笔记:可以用它
# 预处理响应数据,例如解析、提取信息、清洗数据等;
# 对响应进行过滤或过程控制;
# 处理错误或异常情况;
# 添加自定义的功能或逻辑。
# 如果你不希望对响应进行任何修改或处理,你可以简单地返回None。
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
#---翻译-->该方法在蜘蛛处理响应并返回结果后被调用。
# 必须返回一个可迭代的Request对象或item对象。
'''
笔记:
这个方法允许你从蜘蛛处理的结果中进一步操作和处理数据。你可以修改结果,添加、
删除或筛选特定的数据,或者在结果中创建新的Request对象来进行进一步的爬取。你
可以通过yield语句将处理后的结果返回。
总之,process_spider_output方法提供了一个在蜘蛛处理响应结果后对结果进行额外处理的机会,用于进一步定制和控制爬取过程。
'''
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
'''
翻译:当蜘蛛或 process_spider_input() 方法(来自其他爬虫中间件)引发异常时调用。
应该返回 None 或者一个可迭代的 Request 或 item 对象。
笔记:
1.用于处理当蜘蛛或其他爬虫中间件的 process_spider_input() 方法引发异常时的情况
2.你可以针对异常情况进行任何处理。可以根据具体需求进行错误处理、记录日志、重新发送请求等操作。
-->通俗地说,这个方法允许你在蜘蛛或其他爬虫中间件的输入方法引发异常时进行自定义处理。
你可以根据具体的异常情况进行相应的处理操作,如重新发送请求、记录日志等。
'''
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
'''
翻译: 在蜘蛛开始请求时被调用,与 process_spider_output() 方法相似,
不同之处在于它没有与之关联的响应。
笔记:
这个方法允许你在蜘蛛开始请求之前对初始请求进行自定义处理。你可以修改请求对象的属性,
添加额外的请求,或者根据需求生成新的请求对象
--->在爬虫开始请求之前提供了一个自定义处理初始请求的机会,用于修改请求参数或生成新的请求对象。
'''
for r in start_requests:
yield r
def spider_opened(self, spider):
'''
翻译:在爬虫开始运行时被调用;
笔记:你可以用它
1.初始化一些资源或状态;
2.打开数据库连接或文件;
3.设置爬虫的日志输出。..等
--->可以在这里进行一些准备工作,以确保爬虫在运行时具备必要的环境和配置
'''
spider.logger.info("Spider opened: %s" % spider.name)下载中间件--->翻译+笔记:
class JihaiEndDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
# -->翻译:# 并非所有方法都需要被定义。如果某个方法没有被定义,
# # Scrapy 将会假设下载中间件不会修改传递的对象。
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
# 该方法由Scrapy用于创建你的爬虫。
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
'''
# 对每个通过下载中间件的请求进行处理。
# 必须返回以下之一:
# - 返回 None:继续处理该请求
# - 或返回一个 Response 对象
# - 或返回一个 Request 对象
# - 或引发 IgnoreRequest:将调用已安装的下载中间件的 process_exception() 方法
'''
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
# print(f'中间件接收:{response.text}')
'''
# 对从下载器返回的响应进行处理。
# 必须返回以下之一:
# - 返回一个 Response 对象
# - 或返回一个 Request 对象
# - 或引发 IgnoreRequest
# print(f'中间件接收:{response.text}')
'''
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
'''
# 当下载处理程序或 process_request() 方法(来自其他下载中间件)引发异常时调用。
# 必须返回以下之一:
# - 返回 None:继续处理该异常
# - 返回一个 Response 对象:停止 process_exception() 链
# - 返回一个 Request 对象:停止 process_exception() 链
'''
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)from_crawler(cls, crawler) 方法:
- 该方法被 Scrapy 用于创建下载中间件实例。
- 通常用于进行初始化操作和设置信号(Signal)。
- 推荐用于在下载中间件创建时进行一些必要的准备工作或设置。
process_request(self, request, spider) 方法:
- 对每个经过下载中间件的请求进行处理。
- 必须返回以下之一:
-
返回 None:继续处理该请求
-1.继续处理该请求,将会继续传递给后续的下载中间件处理,直到请求被发送到下载器。
-2.后续的下载中间件将有机会进一步处理请求或对请求进行修改。
-
或返回一个 Response 对象
-1.将会终止后续的下载中间件的处理,并将该响应传递回爬虫进行处理(即交给响应处理函数)。
-2.后续的下载中间件的 process_request 和 process_response 方法不会再被调用。
-
或返回一个 Request 对象
-1.将会终止后续的下载中间件的处理,并将该请求重新发送到引擎进行处理。
-2.该请求会经过中间件的处理流程,包括其他的下载中间件。
-3.可以用于对请求进行修改或生成新的请求来重新发起爬取。
-
或引发 IgnoreRequest,将调用已安装的下载中间件的 process_exception() 方法。
-1.将会停止处理该请求,并调用已安装的其他下载中间件的 process_exception 方法。
-2.这是一个特殊情况,用于处理特定的异常情况或错误。
-3.通常用于处理某个请求无法继续处理的情况,可以选择忽略该请求,或者在 process_exception 方法中进行处理。
- 用于自定义处理请求的行为,例如添加通用的请求信息、修改请求参数等。
--->补充:? ?(如果请求有问题)你想让一个request彻底从队列中消失,减少他接下来的生命周期;最直接的办法是引发异常; 如果返回了None他还是会传给spider的;关键取决于你怎么处理你的异常(要不要记录,在哪里记录); 最直接的还是给他引发异常~这样他就直接用日志记录了,不用再脱了裤子放屁跑spider里面去报异常!
process_response(self, request, response, spider) 方法:
- 对从下载器返回的响应进行处理。
- 必须返回以下之一:
-
返回一个 Response 对象
-1.继续处理该响应,将其传递给后续的下载中间件进行处理。
-2.后续的下载中间件将有机会对响应进行进一步处理或对其进行修改。
-3.当没有其他中间件对响应进行进一步处理时,将会将响应传递给爬虫进行处理(即交给响应处理函数)。
-
或返回一个 Request 对象
-1.将会将该请求重新发送到引擎进行处理,并再次经过下载中间件的处理流程。
-2.可以用于对响应进行处理后生成新的请求,或根据响应内容进行重定向等操作。
补充:重试用它;最好再+一个队列优先级,让这个重试的跑队列前面去,快点消掉关于他附带的(例如item)数据;然后还要注意别让这个请求被重复的url给筛掉了;
案例说明:(`+优先级`和`不去重属性`)
from scrapy import Request
class RetryMiddleware:
def process_response(self, request, response, spider):
# 如果返回的响应状态码不是200,则进行重试
if response.status != 200:
# 修改原始的请求,并设置新的优先级和去重属性
retry_request = request.copy()
retry_request.priority += 1
retry_request.dont_filter = True # 设置不进行去重
return retry_request
return response
- 或引发 IgnoreRequest。
- 用于自定义处理响应的行为,例如解析、提取数据等。
process_exception(self, request, exception, spider) 方法:
- 当下载处理程序或其他下载中间件的 process_request() 方法引发异常时调用。
- 必须返回以下之一:
-
返回 None:继续处理该异常
-1.如果希望继续处理异常并将其传递给其他下载中间件来处理,可以在 process_exception 方法中返回 None,让异常继续传递给后续的处理程序。
补:能给出来异常,这时候最好给他加个记录;然后返回None完事了!
案例:
class CustomDownloaderMiddleware:
def process_exception(self, request, exception, spider):
# 其他处理代码...
# 获取异常的URL
url = request.url
# 使用日志记录器记录异常的URL
spider.logger.error(f"这个鬼url有问题,咱不要了;给他记一笔: {url}")
return None
- 返回一个 Response 对象:停止 process_exception() 链
- 返回一个 Request 对象:停止 process_exception() 链
补:这俩在这方法里,我一般是不搁这处理的;你要自定义玩法,随你...就是用来重试和返回个别的给spider或者队列的
- 用于自定义处理异常情况,例如处理超时、处理错误状态码等。
spider_opened(self, spider) 方法:
补:--->每次请求开一个spider?怕是有病吧.鸡肋的设计;直接去爬虫中间件里面整这玩意,这里直接给他过掉~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 分布式事务的解决方案
- mysql原理---InnoDB统计数据是如何收集的
- 双指针部分典型算法题(二)
- 有什么办法可以解决vcruntime140.dll丢失的问题,vcruntime140.dll文件是什么?
- 关键字:final关键字
- 大创项目推荐 深度学习的视频多目标跟踪实现
- 《动手学深度学习(PyTorch版)》笔记2
- 跨境电商掰腕子:SHEIN、Temu、速卖通各展其长
- Java的HashMap源码解析和实现原理如下:(具体解释了put方法)
- Typescript 类装饰器之 属性装饰器