Java的HashMap源码解析和实现原理如下:(具体解释了put方法)
发布时间:2023年12月20日
1、HashMap是基于哈希表实现的Map接口,它使用哈希函数将键(key)映射到数组的索引位置。当需要存储或检索一个键值对时,首先计算键的哈希值,然后根据哈希值找到对应的数组索引。如果该索引位置为空,则直接存储键值对;如果该索引位置已经有其他键值对,则使用链表来处理冲突。
?2、HashMap的初始化过程包括以下几个步骤:
- 计算初始容量(initialCapacity):默认情况下,HashMap的初始容量为16。如果实际存储的元素数量超过初始容量的75%,则将容量扩大为原来的两倍。
- 创建哈希表(table):使用数组来存储键值对。数组的长度等于初始容量。
- 初始化每个桶(bucket)中的链表头节点(headNode):用于处理哈希冲突。
3、HashMap的put方法用于向HashMap中添加键值对。具体实现过程如下:
- 计算键的哈希值。
- 根据哈希值找到对应的数组索引。
- 如果该索引位置为空,则直接存储键值对;如果该索引位置已经有其他键值对,则使用链表来处理冲突。

这是HashMap的主要方法之一,用于向HashMap中添加键值对。它首先计算键的哈希值,然后在哈希表中查找该索引位置。如果该位置为空,则创建一个新的节点并将其添加到哈希表中。如果该位置已经有其他节点,则遍历链表,直到找到合适的位置插入新节点。最后,更新modCount和size变量。
?

这是HashMap内部实现的一个辅助方法,用于实际执行插入操作。它首先检查是否需要调整哈希表的大小,然后根据键的哈希值在哈希表中查找或创建节点。如果找到了现有的节点,并且onlyIfAbsent参数为false,或者现有节点的值与要插入的值不同,则更新节点的值。最后,调用afterNodeAccess和afterNodeInsertion方法进行一些后续操作。
?
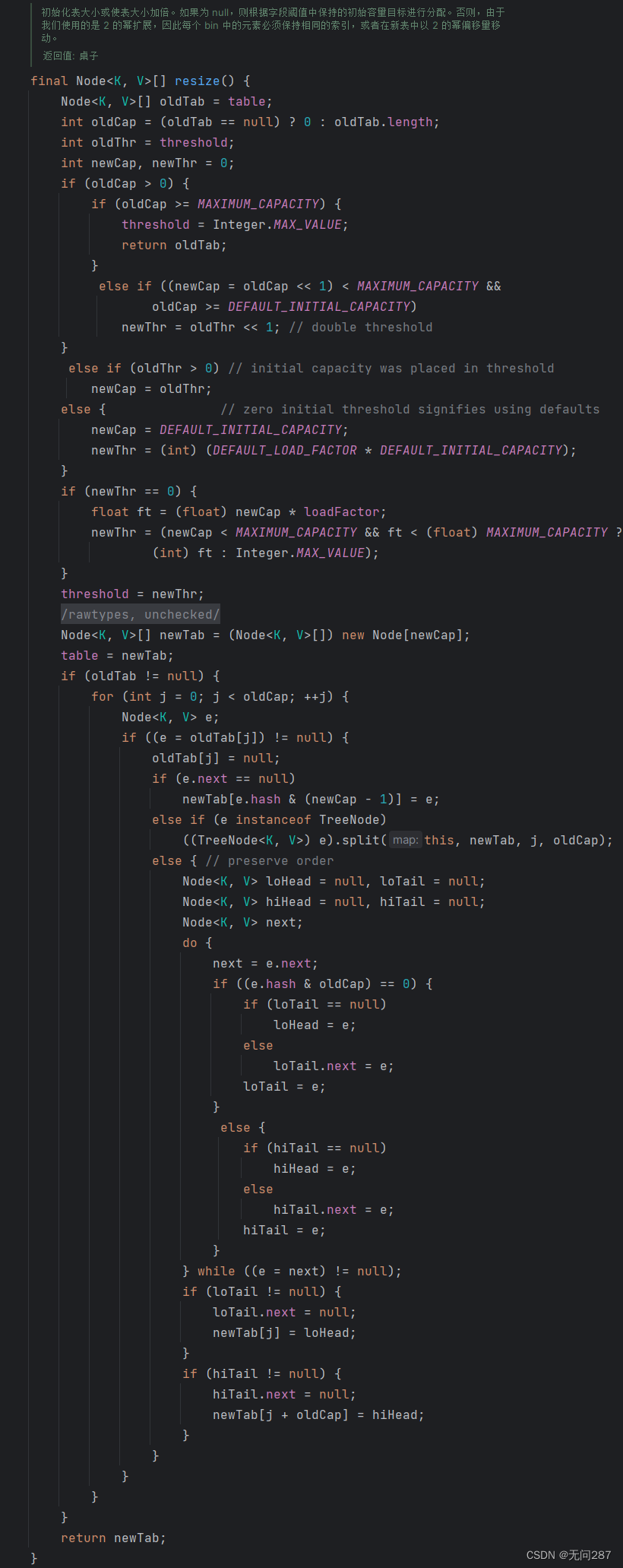
?这个方法用于调整哈希表的大小。它首先计算新的容量和新阈值,然后创建一个新的哈希表,并将旧哈希表中的元素复制到新哈希表中。如果新哈希表的大小超过了阈值,则将其大小加倍。最后,返回新的哈希表。
?

这个方法用于将链表转换为红黑树。它首先检查是否需要调整哈希表的大小,然后根据给定的哈希值在哈希表中查找节点。如果找到了节点,则将其转换为红黑树。?
4、HashMap的get方法用于从HashMap中获取指定键的值。具体实现过程如下:
- 计算键的哈希值。
- 根据哈希值找到对应的数组索引。
- 如果该索引位置为空,则返回null;如果该索引位置有其他键值对,则遍历链表查找指定的键。
?
5、HashMap的remove方法用于从HashMap中删除指定键及其对应的值。具体实现过程如下:
- 计算键的哈希值。
- 根据哈希值找到对应的数组索引。
- 如果该索引位置为空,则直接返回false;如果该索引位置有其他键值对,则遍历链表查找指定的键,并删除对应的键值对。
?
6、HashMap的其他方法如size、isEmpty、containsKey、containsValue等都是基于上述基本操作实现的。
文章来源:https://blog.csdn.net/weixin_62988359/article/details/135089427
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 杨中科 .NET Core 第一部分.NET Standard
- 【第四课课后作业】XTuner大模型单卡低成本微调实战
- 访问者模式
- 粒子群算法优化支持向量SVM的供热量预测,粒子群优化支持向量机SVM回归分析
- 电话号码信息收集工具:PhoneInfoga | 开源日报 No.137
- Docker——1. 快速入门
- 修改vscode内置Vue VSCode Snippets(代码片段)
- 如何通过 useMemo 和 useCallback 提升你的 React 应用性能
- 基于SSM框架的安全教育平台论文
- SpringBoot全局配置Long转String丢失精度的问题解决