MySQL中order by是怎么工作的?

在如上图中所示的explain的执行结果中,Extra字段中的“Using filesort”表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
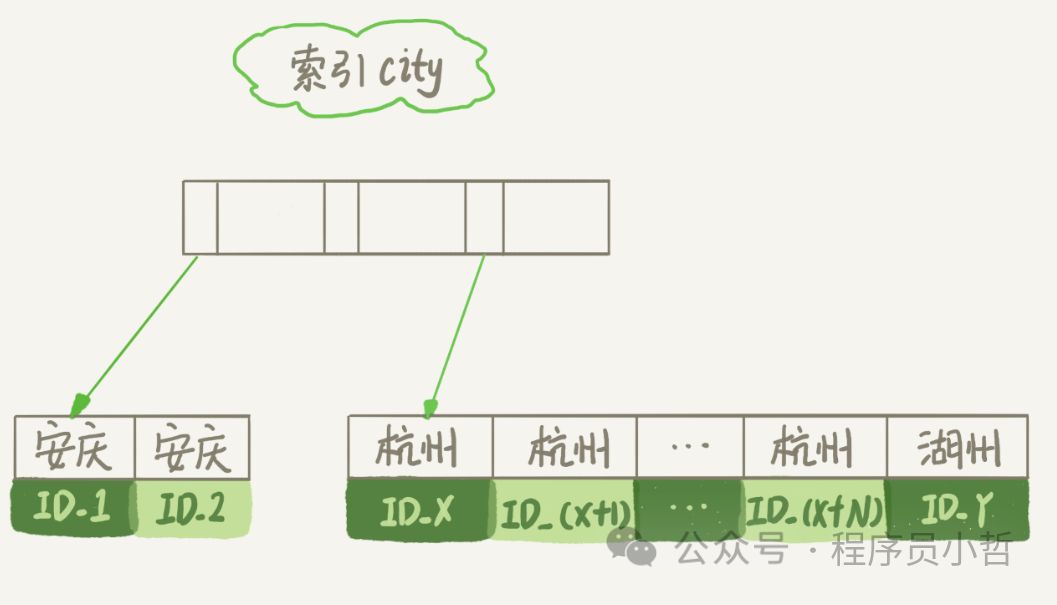
索引city如上图所示
上述语句的执行流程如下:
1、初始化sort_buffer,放入name ?city ?age这三个字段;
2、从索引city中找到第一个满足city='杭州'的主键id,也就是上图中的ID_X;
3、到主键id索引取出整行,取name ?city ?age三个字段的值,放入sort_buffer中;
4、从索引city取下一个记录的主键id;
5、重复步骤3、4直到city值不满足查询条件为止,即上图中的ID_Y;
6、对sort_buffer中的数据按照字段name做快速排序;
7、按照排序结果取前1000行返回给客户端;
上述过程可称之为“全字段排序”
“按name排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。sort_buffer_size是MySQL为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于sort_buffer_size,排序在内存中完成,否则,内存放不下,不得不利用磁盘临时文件辅助排序,称为外部排序,外部排序一般使用归并排序算法。
rowid排序
max_length_for_sort_data参数,是MySQL中专门控制用于排序的行数据长度的一个参数,含意是:如果需要取出来的单行数据的长度超过这个值,MySQL就认为单行太大,要换一个算法。假设city ?name ?age三个字段的定义总长度是36,把max_length_for_sort_data设置为16,则执行过程变为:
1、初始化sort_buffer,确定放入两个字段,即name和id;
2、从索引city找到第一个满足city='杭州’条件的主键id,也就是图中的ID_X;
3、到主键id索引取出整行,取name、id这两个字段,存入sort_buffer中;
4、从索引city取下一个记录的主键id;
5、重复步骤3、4直到不满足city='杭州’条件为止,也就是图中的ID_Y;
6、对sort_buffer中的数据按照字段name进行排序;
7、遍历排序结果,取前1000行,并按照id的值回到原表中取出city、name和age三个字段返回给客户端。
上述流程称之为rowid排序。
全字段排序 VS rowid排序:
综上可得出MySQL的一个设计思想:如果内存足够,就多利用内存,采取全字段排序,尽量减少磁盘访问。
其实,并不是所有的order by语句,都需要排序操作的。比如,如果创建一个city和name的联合索引。
alter table t add index city_user(city, name);则执行流程变为:
1、从索引(city,name)找到第一个满足city='杭州’条件的主键id;
2、到主键id索引取出整行,取name、city、age三个字段的值,作为结果集的一部分直接返回;
3、从索引(city,name)取下一个记录主键id;
4、重复步骤2、3,直到查到第1000条记录,或者是不满足city='杭州’条件时循环结束。

可以看到Extra字段中没有Using filesort了,也就是不需要排序了。
更进一步优化,还可以采用覆盖索引,即索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
alter table t add index city_user_age(city, name, age);则执行流程变为:
1、从索引(city,name,age)找到第一个满足city='杭州’条件的记录,取出其中的city、name和age这三个字段的值,作为结果集的一部分直接返回;
2、从索引(city,name,age)取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
3、重复执行步骤2,直到查到第1000条记录,或者是不满足city='杭州’条件时循环结束。

可以看到,Extra里面多了“Using index”,表示的就是使用了覆盖索引,性能上会快很多。
正文止。
感兴趣的朋友,欢迎关注我的公众号哈,公众号上已经集成了AI大模型,大家可以过来聊天、问问题了

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 开发安全之Dangerous File Inclusion
- 程序设计专业的大学毕业生,怎么样用最快的时间写好文献综述呢?
- Java基础进阶01-类加载器,反射
- C++ 之LeetCode刷题记录(十二)
- 你知道Mysql的架构吗?
- 【OAuth2】:赋予用户控制权的安全通行证--数据库连接篇
- Apache Doris (六十二): Spark Doris Connector - (2)-使用
- css-img图像同比缩小
- MySQL窗口函数(MySQL Window Functions)
- 运维管理平台哪个好?如何挑选合适的运维管理平台?