Mistral AI社区发布SMoE混合专家模型Mixtral 8x7B性能超越ChatGPT
发布时间:2024年01月23日
Mistral AI社区发布了Mixtral 8x7B混合专家模型。这是一种具有开放权重的高质量稀疏专家混合模型 (SMoE)。 根据 Apache 2.0 许可。 Mixtral 在大多数基准测试中都优于 Llama 2 70B模型,推理速度提高了 6 倍。 特别是,它在大多数标准基准测试中优于 GPT3.5。
Mixtral 8x7B混合专家模型具有以下几个强大的功能:
- 上下文token数达到32k。
- 可以处理英语、法语、意大利语、德语和西班牙语。
- 代码生成方面具有强大的表现能力。
- 可以微调为指令跟踪模型,在 MT-Bench 上获得 了8.3 分

Mixtral 是一个稀疏的专家混合网络。 它是一个纯解码器模型,模型设计了8个专家组。 在每一层,对于每个输入token,神经网络模型选择其中的两个“专家”来处理输入token,并相加组合它们的输出。
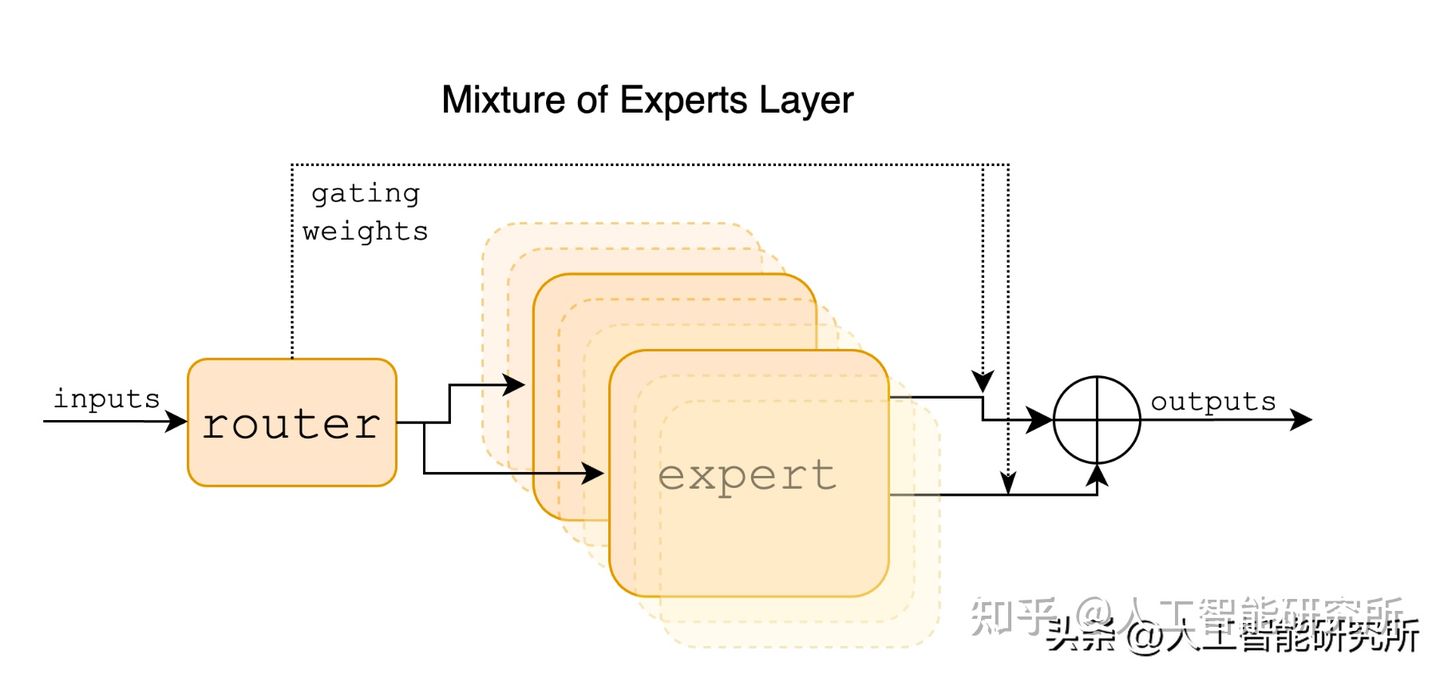
该技术增加了Mixtral模型的参数数量,同时控制了成本和延迟,因为Mixtral模型仅使用每个token总参数集的一小部分。 具体来说,Mixtral 共有 46.7B 个参数,但每个token仅使用 12.9B 个参数。 因此,它以与 12.9B 模型相同的速度和相
文章来源:https://blog.csdn.net/weixin_44782294/article/details/135779498
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!