NLP论文阅读记录 - 2021 | WOS 03 带有语义附加奖励的强化抽象文本摘要
文章目录
前言

Reinforced Abstractive Text Summarization With Semantic Added Reward(21)
0、论文摘要
文本摘要是自然语言处理(NLP)中的一项重要任务。神经摘要模型通过编码器解码器结构理解和重写文档来总结信息。最近的研究试图通过基于强化学习(RL)的学习方法来克服基于交叉熵的学习方法可能存在的偏差或无法针对指标进行优化学习的问题。然而,仅具有 n 元匹配的 ROUGE 度量并不是完美的解决方案。
本研究的目的是通过提出一种基于强化学习的文本摘要奖励函数来提高摘要陈述的质量。我们提出了ROUGE-SIM和ROUGE-WMD,这是ROUGE函数的修改函数。
与 ROUGE-L 相比,ROUGE-SIM 可以实现有意义的相似单词。 ROUGE-WMD是为ROUGE-L添加语义相似性的函数。文章和摘要文本之间的语义相似度是使用 Word Mover 距离 (WMD) 方法计算的。我们提出的两个奖励函数模型在 ROUGE-1、ROUGE-2 和 ROUGE_L 上表现出了比 ROUGE-L 作为奖励函数更优越的性能。
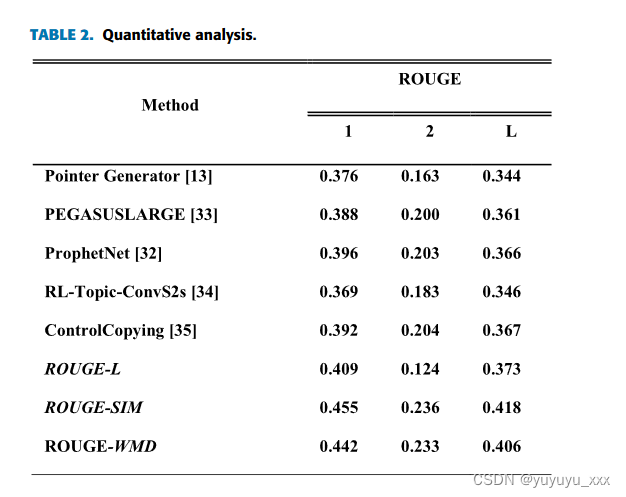
我们的两个模型 ROUGE-SIM 和 ROUGE-WMD 在 Gigaword 数据集上的 ROUGE-L 得分分别为 0.418 和 0.406。即使在抽象性和语法方面,这两个奖励函数也优于 ROUGE-L。
一、Introduction
1.1目标问题
文本摘要是自然语言处理(NLP)中的一项重要任务。减少包含信息的文本量对于各种 NLP 任务很有帮助。文本摘要分为抽取式摘要和抽象式摘要两种方法。对于提取式摘要,仅从输入文本 [1]–[4] 中复制必要的单词。相比之下,抽象文本摘要是基于文档核心思想的重写任务。它使用类似人类的过程来生成文本,使其更有可能生成流畅的文本并使用输入文本中未包含的新单词[10]。
最近的抽象摘要模型基于序列到序列神经网络[5]、[7]、[8]、[10]、[33]、[34]、[35]。它们由用于理解输入序列的编码器和用于生成输出序列的解码器组成。他们表现出比以前的研究更高的性能。但是使用序列到序列神经网络生成好的文本存在四个主要问题:(1)词汇外(OOV)问题(2)重复生成特定单词或短语,(3)测试时的暴露偏差,(4)文本摘要和机器翻译等领域的模型使用的评估指标[14]的非优化学习。
1.2相关的尝试
为了解决这些问题,人们进行了许多研究来改进模型的结构,以提高摘要的质量。指针机制在解码过程中复制输入序列的一些元素来解决OOV问题[11]-[13]。覆盖损失[13]和内部注意力[15]是针对重复生成相同语法的问题提出的。在我们的实验中,我们尝试使用 Paulus 等人提出的解码器内注意力来减少迭代问题。 [15]。在优化方法方面也进行了各种研究。交叉熵方法可能存在偏差,并且在学习不优化性能指标时会遇到问题。作为对此问题的答案,人们提出了一种使用强化学习的方法来以有限的方式解决这两个问题。使用ROUGE-L作为奖励函数[15]不能完全摆脱偏差问题,因为ROUGE必须使用与参考摘要和生成摘要相同的词汇以相同的顺序才能产生高分。参考摘要数据会影响模型的稳健性,因为使用 ROUGE-L 等不反映语义值的指标进行训练存在限制。
1.3本文贡献
我们通过提出两个建议来解决这些问题为 ROUGE-L 添加语义值的奖励函数,用于基于 RL 的抽象文本摘要。 1) ROUGE-SIM:基于n-gram匹配修改ROUGE度量的度量。在求最长公共子序列的长度时,利用词嵌入的相似性来允许相似词的匹配。 2)ROUGE-WMD:混合了WordMover的距离(WMD)[16]和ROUGE-L的奖励功能。与 ROUGE-L 相比,我们提出的奖励函数帮助我们在生成过程中选择更多样化的词汇,例如缩写或相似的单词。该模型的鲁棒性很高,因为重复减少了,并且使用 GRAMMARLY 手动评估的语法错误更少 - 即使在替换内容时选择与参考不同的单词,也有可能获得较低的惩罚作为奖励。大多数语法错误是由重复性问题引起的,无需后期处理即可显着改善。
总之,我们的贡献如下:
二.相关工作
过去大多数文本摘要工作都采用提取方法[1]-[4]、[9]。他们通过从输入文本中复制必要的单词或句子或压缩必要的元素来执行任务。
基于编码器-解码器的神经网络是理解输入并生成输出的结构,例如机器翻译 [5] 和文本摘要 [8]、[10] 领域。它们被用于各种 NLP 领域。编码器是获取上下文表示的结构。使用词嵌入将输入序列转换为固定向量。 Word2vec [19] 和 Glove [20] 主要用作词嵌入,将自然语言转换为固定向量。并且固定向量通过长短期记忆(LSTM)[17]、卷积神经网络和Transformer[18]等结构编码在上下文表示中。注意力机制使编码器-解码器模型能够通过解码时间步来查看输入序列的不同部分[6]。人们还对单词重复生成问题进行了各种研究,例如在包括摘要在内的文本生成任务中总体出现的 OOV 问题。参见等人。 [13]试图通过将通过指针生成器复制出现在输入序列中的单词的概率(如提取摘要)添加到解码器的生成概率中来防止未知单词的生成。为了解决重复生成相同单词或短语的问题,人们提出了覆盖损失[13]和内部注意力[15]。
自从 Transformer [18] 提出以来,各种预训练语言模型如 Elmo [21]、Bert [22] 和 Big Bird [23] 已经发布。在大型文本语料库上预训练的大型 Transformer 模型在仅有限监督样本的自然语言处理中表现良好。宋等人。 [35]通过设置可见词和未见词对 BERT 进行了微调。这增强了生成类似于掩蔽的未知单词的能力,提供了良好的结果在 Gigaword 数据集上。预训练的编码器-解码器模型在文本摘要方面也表现出了良好的性能[32]-[34]。与其他屏蔽语言模型不同,PEGASUS [33]提出了一种用于文本摘要的预训练方案,该方案屏蔽输入文档中的句子并预测屏蔽句子。
强化学习训练智能体识别给定的环境并以最大化奖励的方式发挥作用。在序列生成任务中,传统的交叉熵方法无法通过反映评估指标来进行训练,因为 BLEU 和 ROUGE 等指标是不可微的。未针对指标进行优化的传统学习方法可能会产生偏差并影响模型的性能。兰萨托等人。 [14]在序列生成模型中使用REINFORCE算法[24]、[25]来优化度量。雷尼等人。 [26]提出了一种不需要批评者模型的自我批评序列训练方法,并且在图像字幕任务上显示出很大的改进。在抽象概括任务中,Paulus 等人。 [15]训练了针对ROUGE优化的模型,显着提高了模型的ROUGE召回率。王等人。 [34] 在 Gigaword 数据集中作为添加主题信息的指标优化模型显示了良好的结果。
三.本文方法
3.1 总结为两阶段学习
3.1.1 基础系统
3.2 重构文本摘要
四 实验效果
4.1数据集
我们使用 Rush 等人使用的 Gigaword 摘要数据集。 [7]。它由成对的短文章(31.4 个标记)和标题(8.3 个标记)组成。它包含 3.8M 训练、189k 开发和 1,951 个测试实例。编码器和解码器长度分别设置为55和15,这样可以使用总数据的99%以上来考虑数据长度。
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
我们提出了两个奖励函数 ROUGE-SIM 和 ROUGE-WMD,它们将语义值添加到基于传统 n 元匹配的函数中。架构分析部分的实验表明,解码架构与奖励函数相匹配。正如定量分析的结果一样,所提出的使用架构和返回函数的模型比其他实验的偏差更小。我们的模型比基于序列到序列的模型、基于 Transformer 的预学习模型和其他基于强化学习的模型表现得更好。我们还在抽象性分析和语法分析方面展示了更好的结果。尽管抽象性分析中的新表示比人工编写的摘要少,但新表示在使用指针机制的模型中是最常见的。此外,我们还展示了以下方面的改进与语法分析中使用 ROUGE-L 的模型相比,由于语法错误(尤其是迭代)几乎被消除,因此可读性的提高。
然而,这项研究有一些局限性。首先,我们用的是新闻数据,释义问题不大。对于包含行话的文档来说这可能是一个问题,因此需要对来自不同领域的文档进行验证。其次,我们使用可训练权重数量相对较少的单层 LSTM 来验证解码架构和奖励函数。我们需要验证我们的建议是否可以提高基于 Transformer 的大型模型的性能。
思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!