【深度学习】优化器介绍
前言
深度学习优化器的主要作用是通过调整模型的参数,使模型在训练数据上能够更好地拟合目标函数(损失函数)并收敛到最优解。在深度学习中,优化器的任务是最小化损失函数,即模型预测的输出与真实标签之间的差异。
作用:
1.参数更新:优化器根据损失函数的梯度信息来更新模型的参数。梯度表示了损失函数在参数空间中的变化方向,优化器使用这一信息来调整参数,使得损失函数逐渐减少。
2.模型收敛:通过迭代过程,优化器帮助模型逐渐收敛到损失函数的局部最小值或全局最小值,从而提高模型的性能。
3.处理局部极小值:优化器的一些变种,如动量法和自适应学习率法,有助于处理梯度下降过程中可能遇到的局部极小值问题,提高模型训练的稳定性。
4.加速收敛:通过引入动量项或自适应学习率等机制,优化器可以加速模型的收敛过程,减少训练时间。
5.处理非凸优化问题:在深度学习中,损失函数通常高度非凸的,有多个局部最小值。优化器的设计考虑到这些问题,以在参数空间中找到良好的解。
6.适应学习率:自适应学习率优化器可以根据参数更新的情况自动调整学习率,使得在不同参数处使用不同的学习率,提高训练的效率。
7.处理梯度消失或爆炸:一些优化器设计考虑了深度神经网络中可能出现的梯度消失或梯度爆炸问题,通过合理的参数更新策略有助于缓解这些问题。
不同的优化器采用不同的策略来更新模型的权重,直接影响了模型的收敛速度和性能。
一、梯度下降法(Gradient Descent)
梯度下降算法是深度学习中常用的优化算法,分为以下三种:
1、批量梯度下降算法(Batch Gradient Descent):将整个训练集上的梯度进行累加,然后更新模型参数。使用该方法充分利用了并行运行,极大提高了运行效率,但是对计算机要求高。
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2*x*(x*w-y)
return grad/len(xs)
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
梯度下降算法示意图如下:
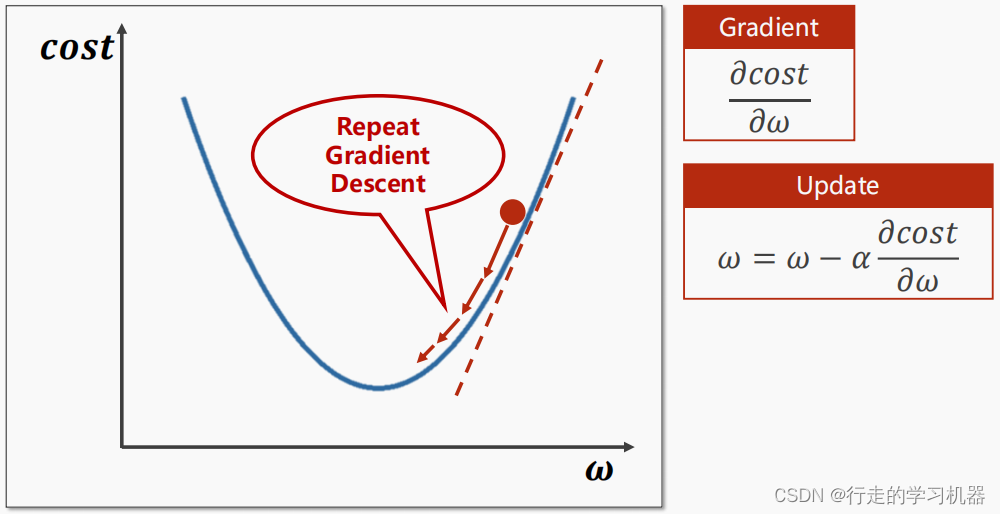
2、随机梯度下降法(Stochastic Gradient Descent,SGD):每次迭代只使用一个训练样本来计算梯度和更新参数,这样可以更快地进行模型更新。此方法没有利用计算机的并行运算,计算效率低下。
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad
print("\tgrad: ", x, y, grad)
l = loss(x, y)
3、小批量梯度下降算法(Mini-batch Gradient Descent):该方法权衡了批量梯度下降算法和随机梯度下降算法的优缺点,是深度学习中最常用的方法。
二、动量优化器(Momentum)
由于计算机性能的限制,使用整个样本集进行求解是不现实的。但小批量梯度下降算法容易陷入局部最优解,故引入动量项,模拟物体在梯度场中的运动惯性,考虑了上一次计算的梯度,有助于克服梯度下降中的震荡问题。
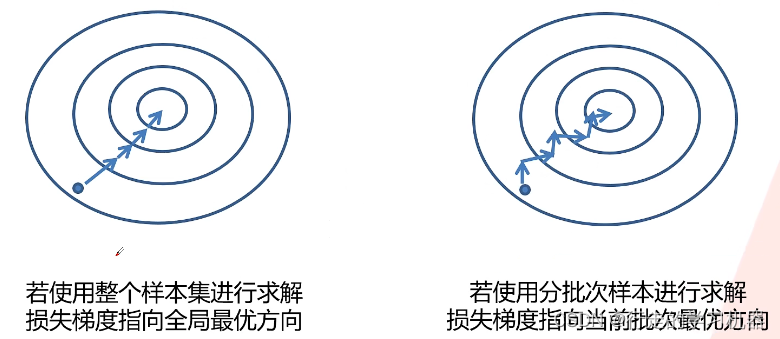
计算公式如下:

三、自适应学习率优化器
1、Adagrad优化器:根据参数的历史梯度进行学习率调整,适用于稀疏数据。公式如下:

优点:
(1)自适应学习率: Adagrad可以自适应地为每个参数提供不同的学习率。对于频繁更新的参数,学习率较小;对于不经常更新的参数,学习率较大。这有助于在训练过程中更好地平衡参数的更新。
(2)适用于稀疏数据: Adagrad对于稀疏数据的训练效果较好,因为它可以根据每个参数的历史梯度来调整学习率,对于出现较少的特征有更大的学习率。
(3)简单实现: Adagrad的实现相对简单,不需要手动调整学习率,这使得它在实践中易于使用。
缺点:
(1)学习率衰减过快: Adagrad在迭代过程中会不断累积梯度的平方,并将其用于学习率的调整。这导致了学习率的不断减小,可能会使得训练过早停滞,特别是对于深度神经网络。
(2)对非平稳问题敏感: Adagrad在处理非平稳问题(non-stationary problems)时可能表现不佳。由于它根据历史梯度进行学习率调整,可能在迭代早期就将学习率设得过小,导致性能下降。
(3)内存需求增加: 由于需要维护每个参数的历史梯度平方和,Adagrad需要额外的内存空间。这可能在大规模模型和大型数据集上导致内存需求过大。
2、RMSprop优化器:改进了Adagrad优化器,使用指数加权移动平均来平衡学习率。公式如下:

RMSprop对Adagrad的改进之一是采用了梯度平方的移动平均,而不是直接累积所有历史梯度的平方。这样可以减缓学习率下降的速度,更好地适应不同参数的更新频率,有助于在训练过程中更稳定地收敛。
3、Adam优化器:结合了动量和RMSprop,通过计算梯度的一阶矩和二阶矩估计来自适应地调整学习率。公式如下:
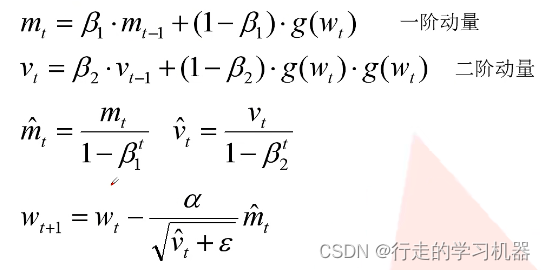
优点:
(1)自适应学习率: Adam使用了每个参数的自适应学习率,通过计算梯度的一阶矩估计(mean)和二阶矩估计(uncentered variance)来调整每个参数的学习率。这允许不同参数具有不同的学习率,更好地适应不同参数的梯度变化。
(2)动量项: Adam引入了动量项,通过计算梯度的一阶矩估计,保留了之前梯度的信息,有助于在优化过程中保持稳定的方向。
(3)偏置修正: Adam通过引入偏置修正(bias correction)来纠正梯度估计的偏差,尤其在训练初期,有助于更准确地估计梯度的动态。
(4)适用于大规模问题: Adam通常表现得很好,特别是在大规模数据集和深度神经网络的训练中。其自适应学习率和动量项的结合使其适用于不同类型的问题。
缺点:
(1)对超参数敏感: Adam有一些超参数,如学习率、β1(动量的衰减率)、β2(二阶矩估计的衰减率)等,对这些超参数的选择相对敏感。不同问题可能需要不同的调优,这使得在一些情况下需要仔细的超参数调整。
(2)可能不适用于非凸问题: 有一些研究表明,Adam可能在处理非凸优化问题时不如其他优化器表现好。在某些情况下,它可能导致模型收敛到局部极小值而不是全局最小值。
(3)内存使用较大: Adam需要存储每个参数的额外信息,如一阶矩估计和二阶矩估计的移动平均。这导致了较大的内存使用,尤其是在处理大规模模型时可能成为一个问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#编程-实现数组
- 学会这三步,让你的营销文案更出彩
- C++系列-第1章顺序结构-6-加法、减法和乘法
- 快速搭建Swagger(knife4j版)
- 如何处理好面试中的“压力测试”?
- 基于springboot+vue的房屋租赁系统(前后端分离)
- 数据结构day4
- StringBuilder、StringBuffer
- 【动态管理日志】Spring Boot 实现 热插拔 AOP,非常实用!
- 深度学习记录--Train/dev/test sets