MySQL 索引数据结构 - 对比
发布时间:2023年12月26日
一 前言
- 索引 ( index)是帮助MysqL 高效获取数据 的 排好序的数据结构 。
- 通过索引查找数据,在维护的索引数据结构上,通过比大小的方式,查找对应数据,数据结构排好序,可以加快查找。
- 接下来我们就从排好序、数据结构两方面,对比不同类型的索引数据结构。
二 MySQL索引数据结构
| 索引结构 | 描述 |
|---|---|
| BTREE索引 | 一般指B+Tree,最常见的索引类型,大部分引擎都支持B+Tree索引。 |
| HASH | 底层结构用哈希表实现的,只有精确匹配索引列的查询才有效,步子好吃范围查询。 |
| R-Tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES。 |
三 常见的数据结构对比
- 在树上查找,实际上查找次数,和树的高度有很大关系,树高度越小,查询越快。
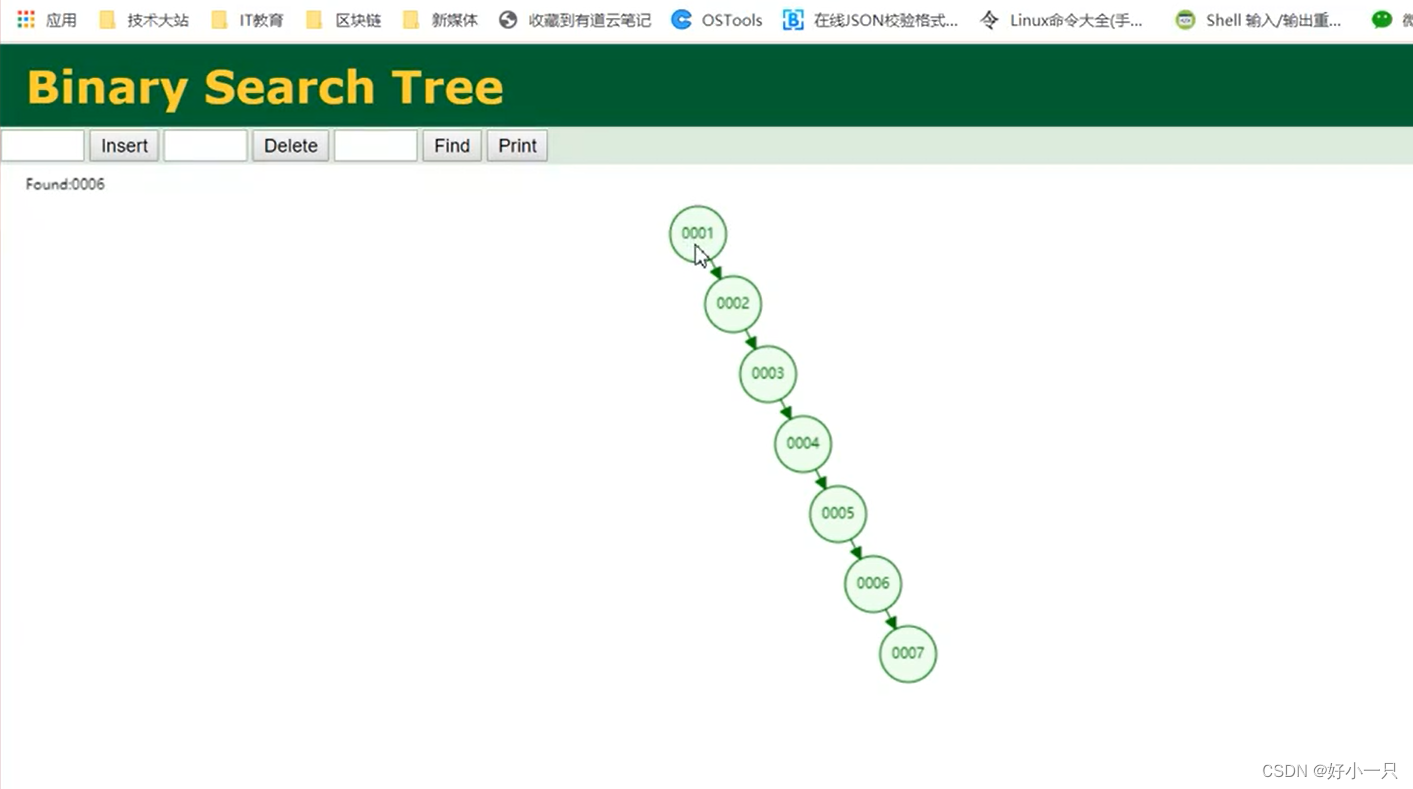
1 二叉树
1 对于单边增长的数据链,二叉树维护的是一条线,树的高度很高,对查询效率没有提升。
2 二叉树:是按照从左到右排好序的,但树高度过高。
2 红黑树
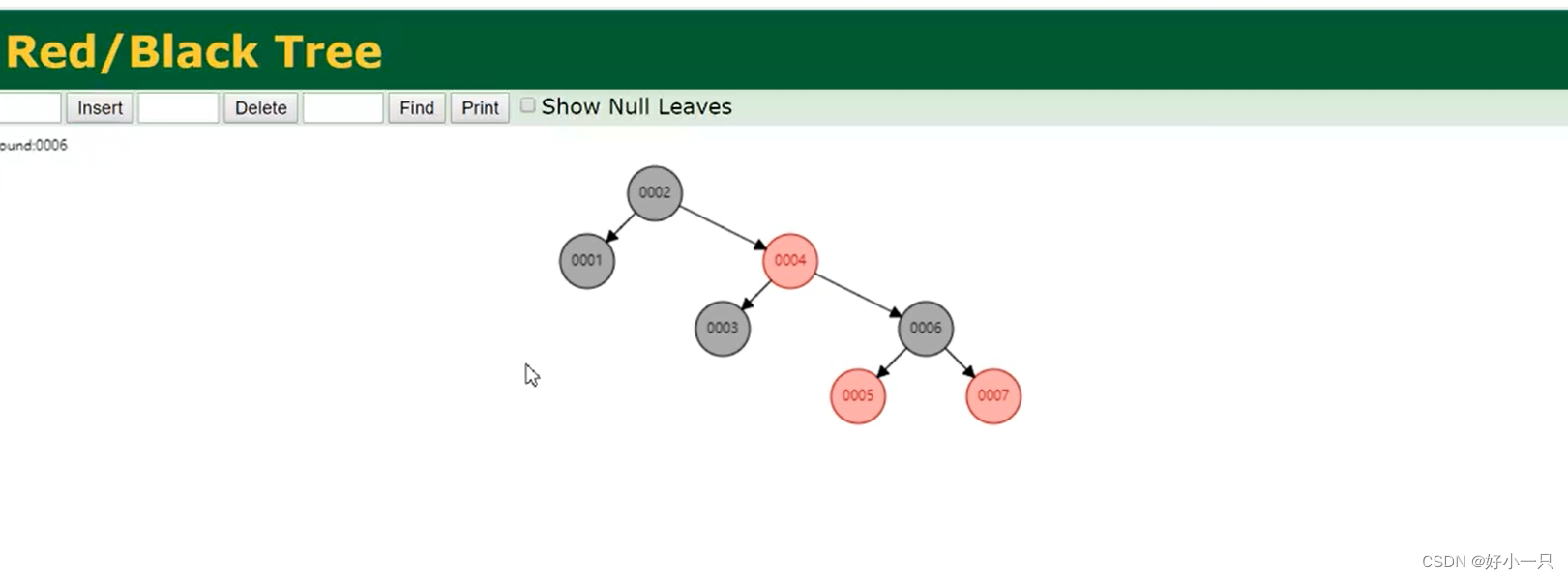
1 对于单边增长的数据链,会自动做一次平衡,是二叉平衡树的一种。
2 虽然会做自平衡,但是数据量大时,树的高度不可控。
(若树的高度有20,所查元素在叶子节点,数据查询时,都是从根节点开始查找,通过比大小的方式,至少20次的遍历查找,才能查到。)
3 红黑树:在二叉树的基础上会做自平衡,但是数据量大时,树的高度不可控。
3 B树
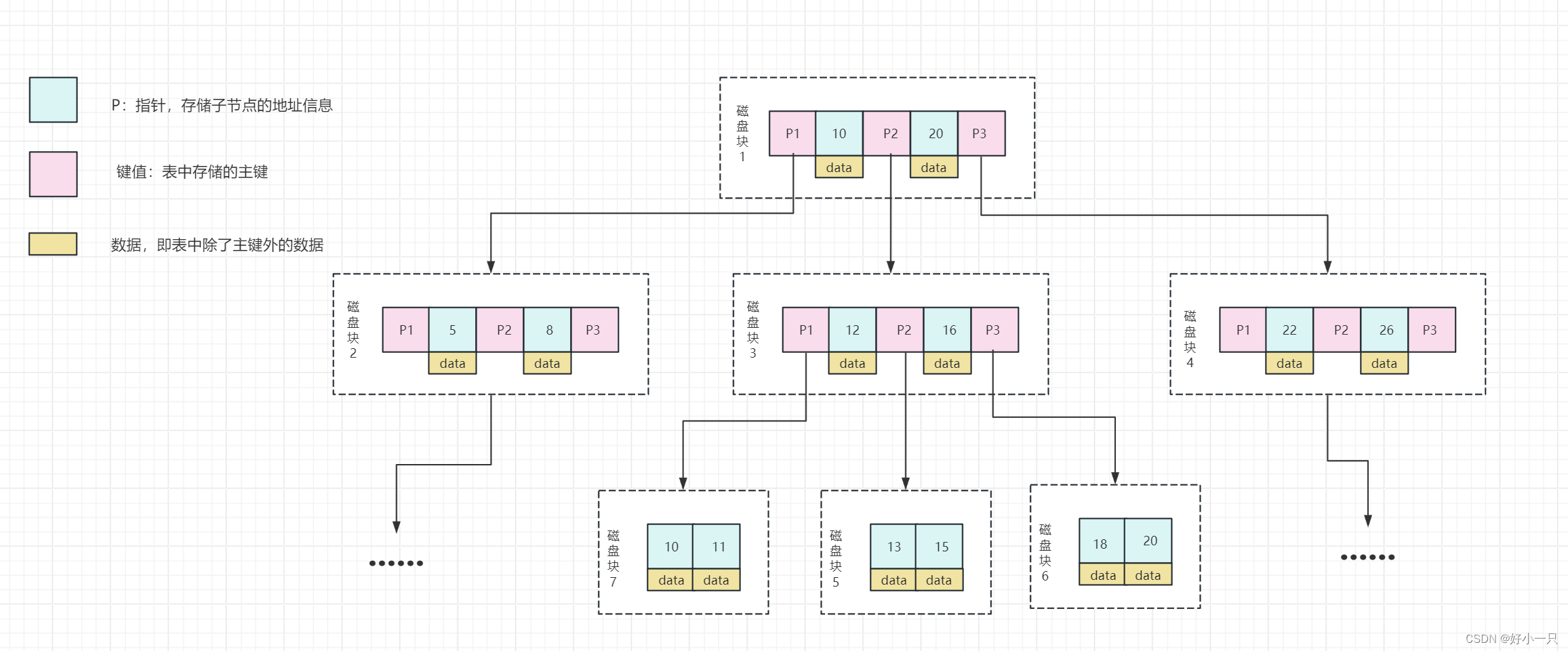
0 红黑树一个节点只放了一个元素,B树把一个节点扩充成多个元素,树的高度会更小。
1 非叶子节点数据包含:指针、键值、数据。
2 叶子节点具有相同的深度,叶子节点的指针为空,只有键值、数据。
3 节点中的数据索引,从左到右递增排列
4 所有索引元素不重复,即没有冗余。如磁盘块1中,有元素10,那么在其他的磁盘块中不会再有10这个元素。
4 B+ 树
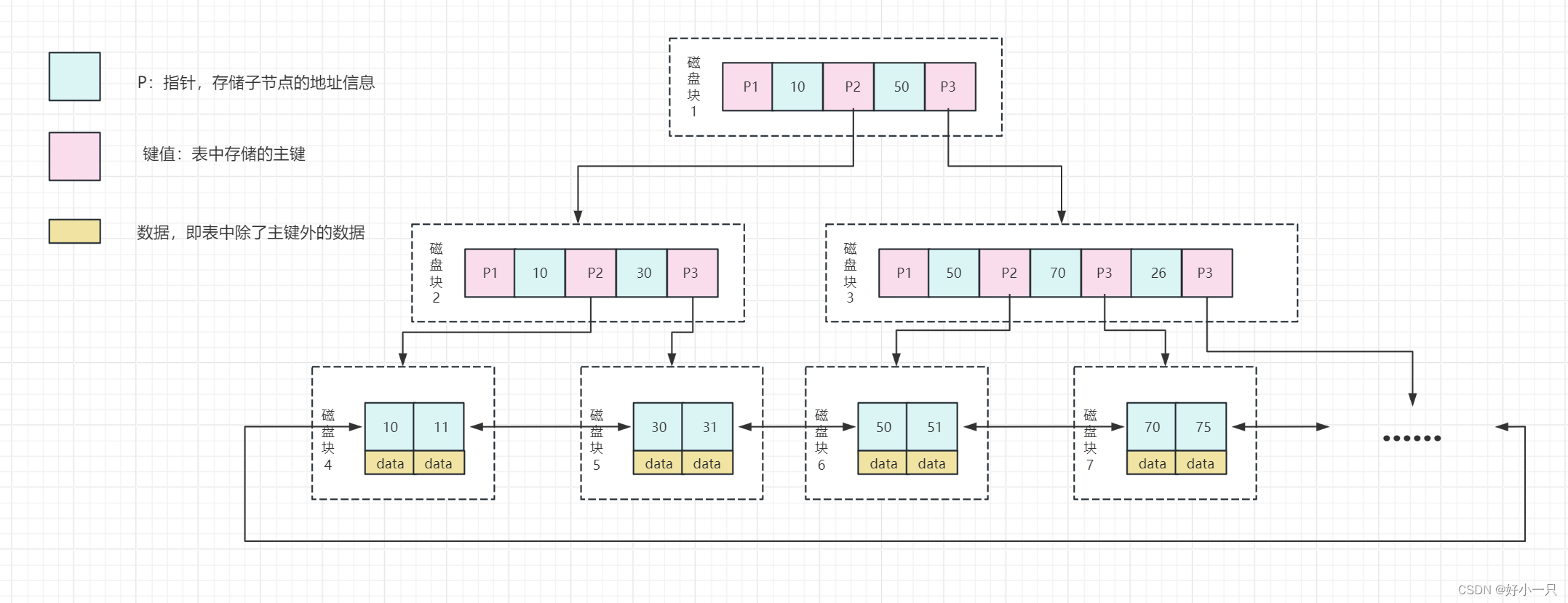
1 保留了B树的,一个节点扩充多个元素的特性。
2 非叶子节点不存data数据,空出更多的空间,让一个节点可以存储更多的元素。
3 非叶子节点只存储索引(冗余),冗余索引就是取每一页数据的第一个元素。
即磁盘块1中P2指针前一个元素是10,则P2指向的下一个块地址的第一个元素也是10,以此类推。
4 每一个节点,节点与节点之间,元素都是从左到右递增的;排好序的。
5 叶子节点包含所有索引字段,叶子节点用指针连接,提高区间访问的性能。
6 B+树:在B树的基础上,非叶子节点不存储data,只存储索引(冗余);
叶子节点包含所有索引字段;叶子节点用指针连接,提高区间访问的性能。
查找过程:
依然从根节点开始,把根节点数据,加载到内存里面,通过二分查找算费,快速查找出30的位置,找到对应的页;
再将这页数据,加载到内存面,二分查找,以此类推,找到对应的数据data。
5 HASH
1 对索引的key进行一次hash计算,就可以定位出数据存储的位置
2 很多时候Hash索引要比B+ 树索引更高效
3 缺点:仅能满足 “=”,“IN",不支持范围查找,会有hash冲突
0x56:索引所在的磁盘文件地址
查找流程,经过一次hash计算,直接找出对应的hash位置,找到对应的磁盘文件地址,找到对应的数据。
可能只需要一次hash计算,速度比比大小快。

四 常见问题
- 为什么B+树要把data数据放在子节点里面?
非叶子节点不存储数据,可以存储更多的索引,降低树高度;
- B树和B+树有什么区别?
1 非叶子节点:B树保留了data数据,B+树没有;B树没有冗余索引,B+树是存储的冗余索引;
2 叶子节点:B树没有完整的索引,B+树保留了完整的索引;B树叶子节点没有指针关联;B+树叶子节点通过指针关联。
3 B+tree 和B -tree 都具有相同的树深度;且数据不重复的特点;且数据从左到右有序排列
- 千万级数据表如何用B+树索引快速查找?
1 查找时比较费时的步骤是load节点到内存,而在内存查找数据是比较快的;
2 对于MySQL来说,每个(页)节点(root)分配的空间是16kb,高度为3的B+树整体可存储两千多万数据;
3 高度为3的B+树中,查找某一个元素,只经过3次磁盘IO即可找到;
4 B+树的结构,决定了即使是千万级数据表,仍可快速查找到元素
如有缺漏或不对的地方还请各位指正。
欢迎关注我的个人公众号

文章来源:https://blog.csdn.net/qq_37746483/article/details/135213808
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 全国计算机等级考试| 二级Python | 真题及解析(5)
- ls命令使用
- JAVA网络IO之简单聊聊Stream、Channel和零拷贝
- Servlet-执行流程&生命周期
- APP广告变现设置合理的广告频次的原因
- Redis相关面试题大全
- 华为MindStudio简介
- Golang八股文面试题
- initrd(4) - Linux man page initrd(4) - Linux 手册页
- 4点优势,昂首资本使用浮动差价不使用固定差价的原因