Consumer源码解读
Consumer源码解读
本课程的核心技术点如下:
1、consumer初始化
2、如何选举Consumer Leader
3、Consumer Leader是如何制定分区方案
4、Consumer如何拉取数据
5、Consumer的自动偏移量提交
Consumer初始化
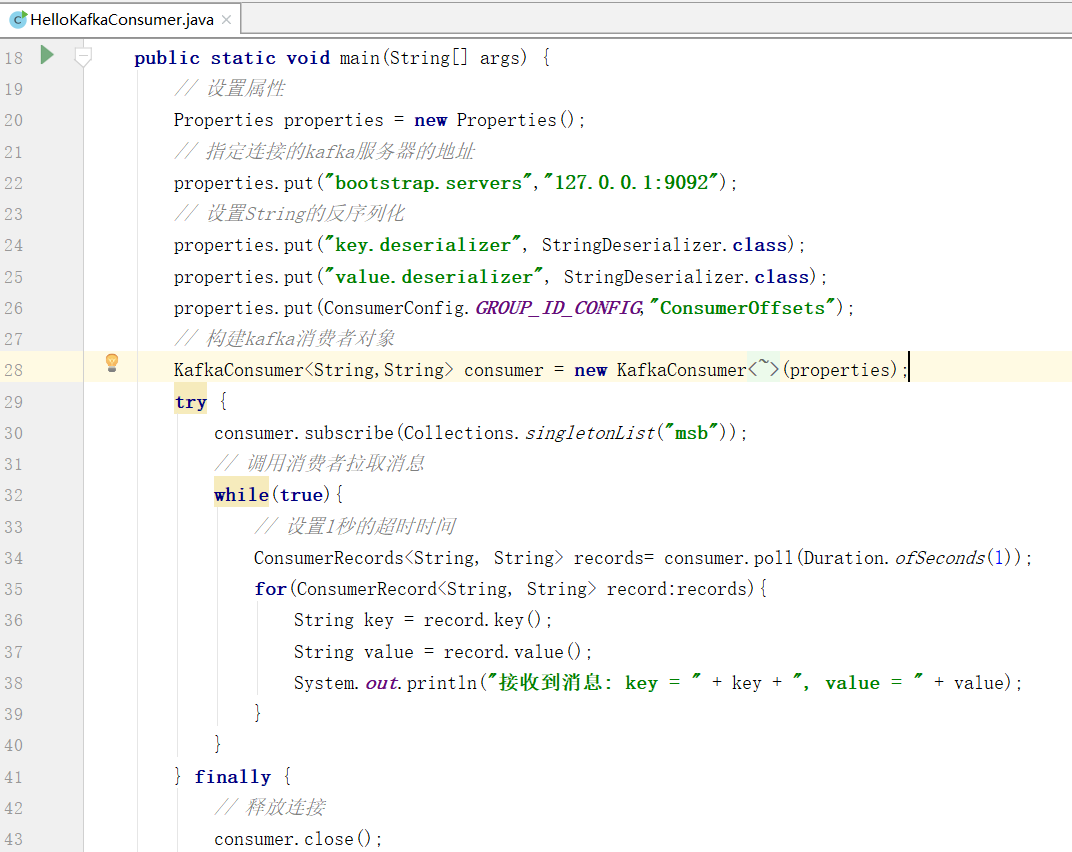
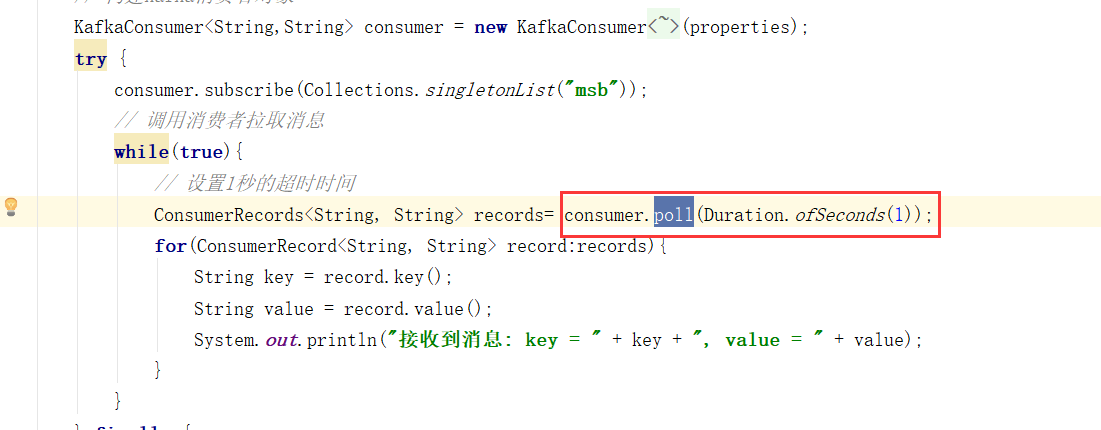
从KafkaConsumer的构造方法出发,我们跟踪到核心实现方法
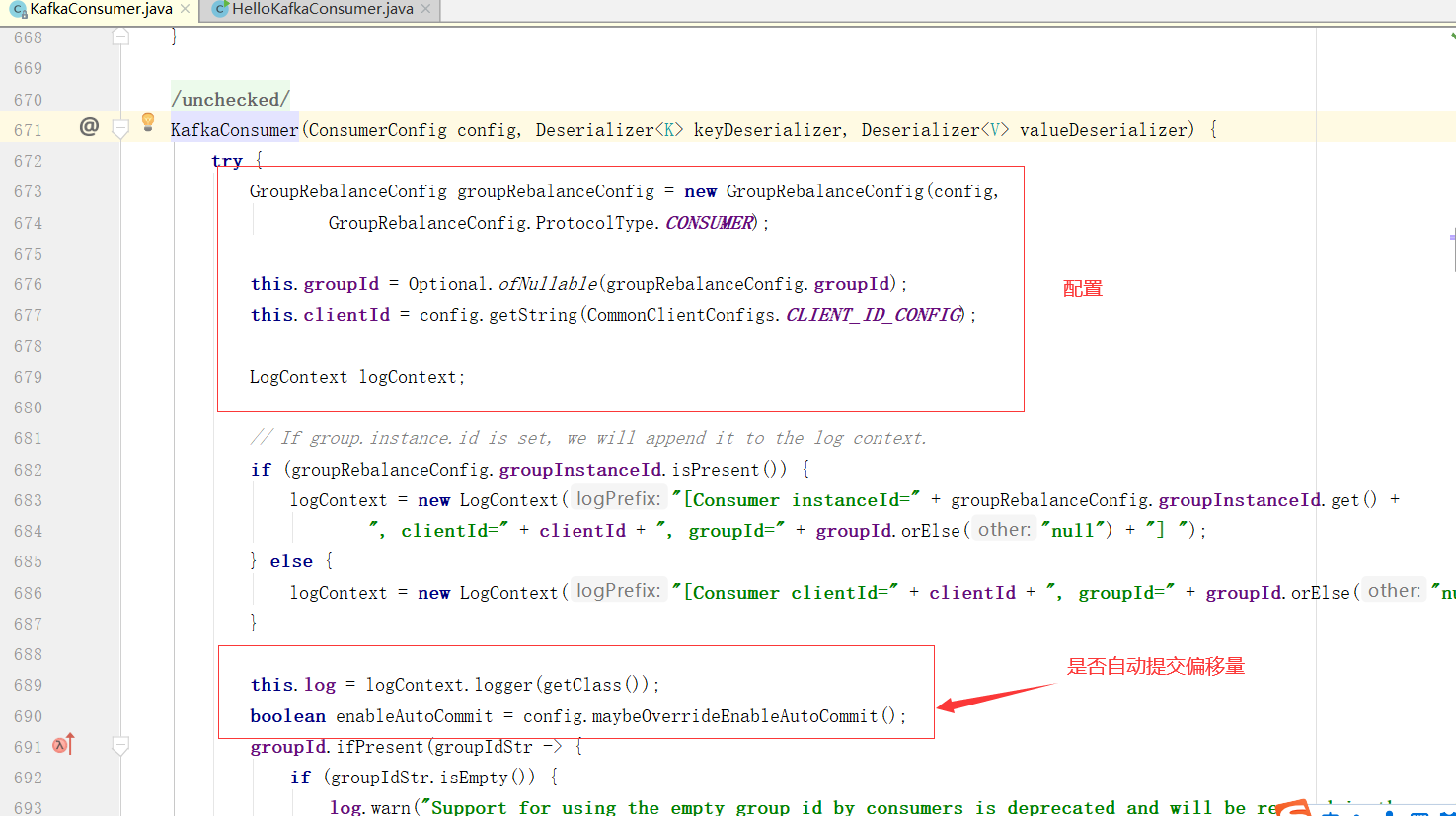
这个方法的前面代码部分都是一些配置,我们分析源码要抓核心,我把核心代码给摘出来
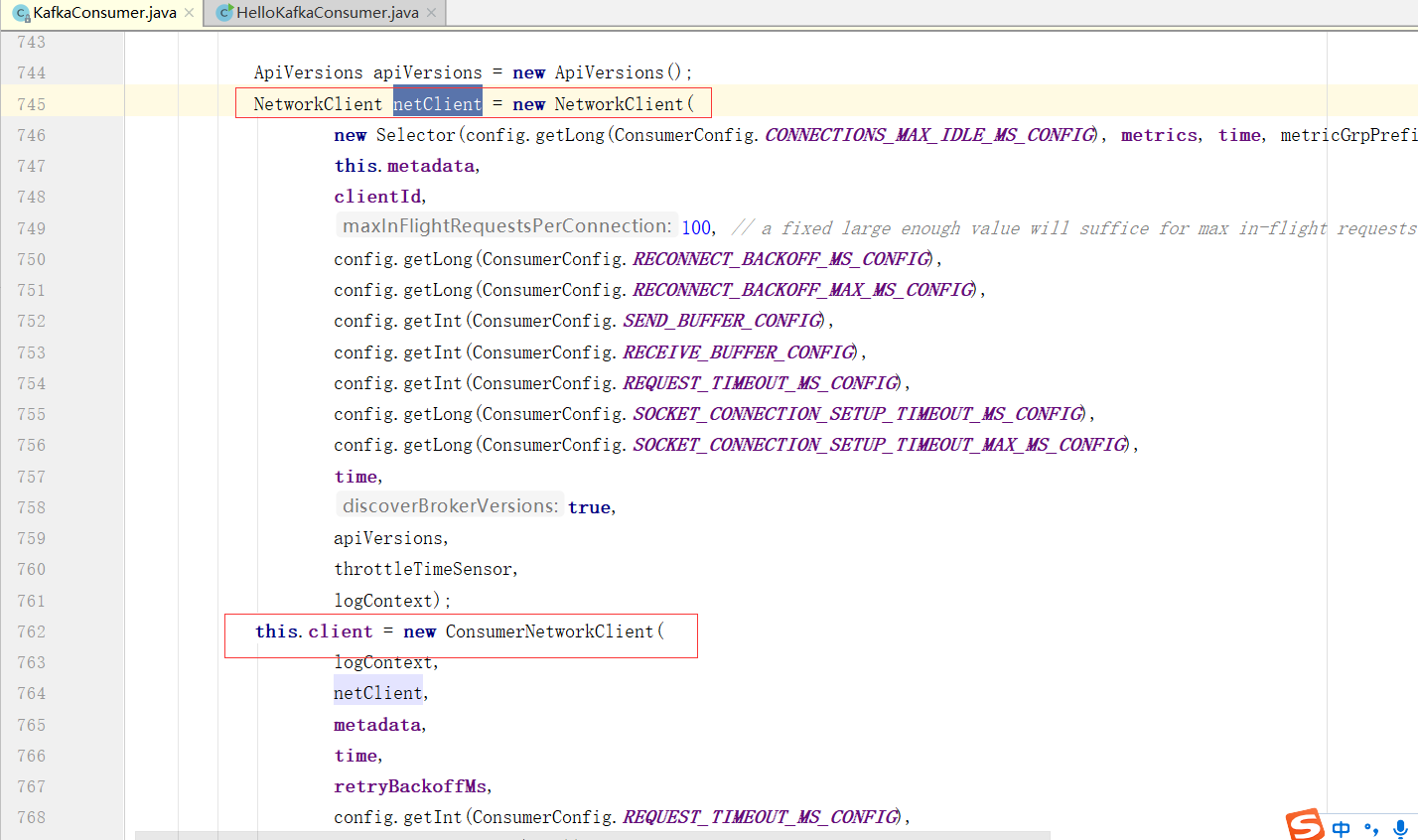
NetworkClient
Consumer与Broker的核心通讯组件
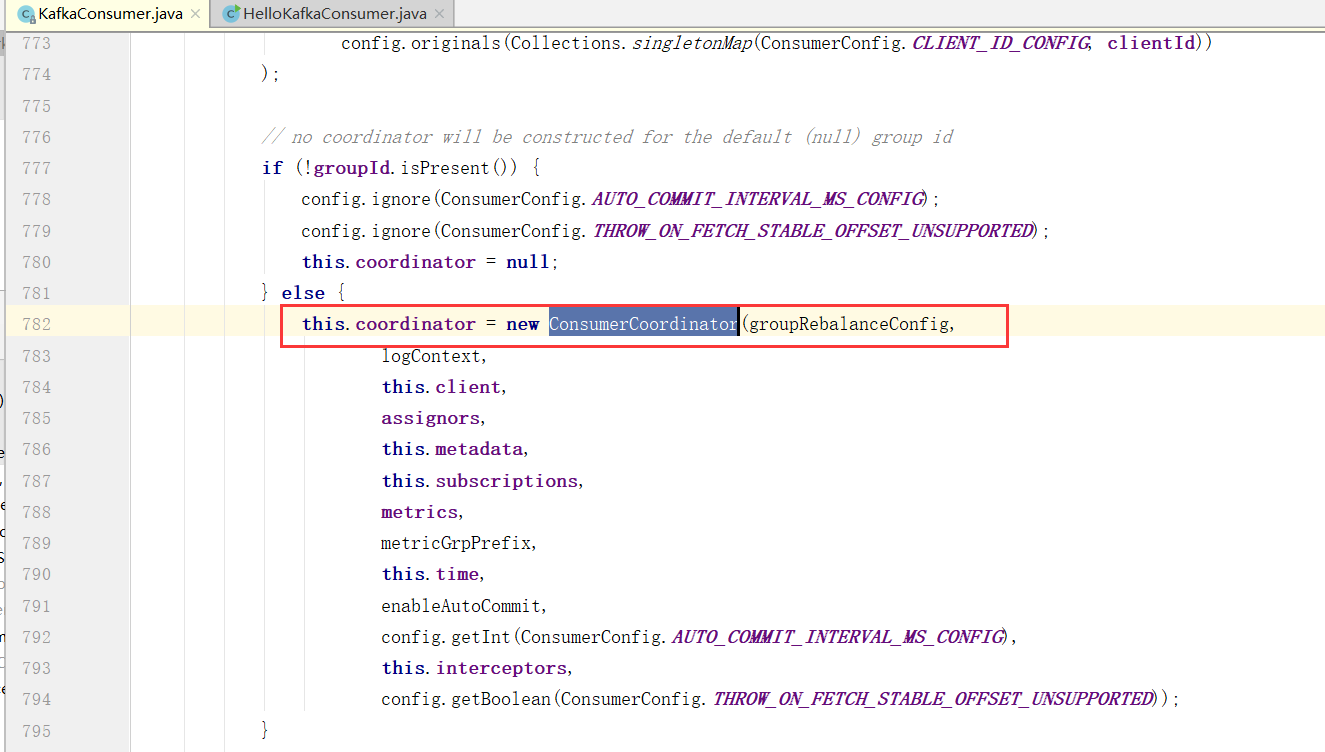
ConsumerCoordinator
协调器,在Kafka消费中是组消费,协调器在具体进行消费之前要做很多的组织协调工作。
Fetcher
提取器,因为Kafka消费是拉数据的,所以这个Fetcher就是拉取数据的核心类
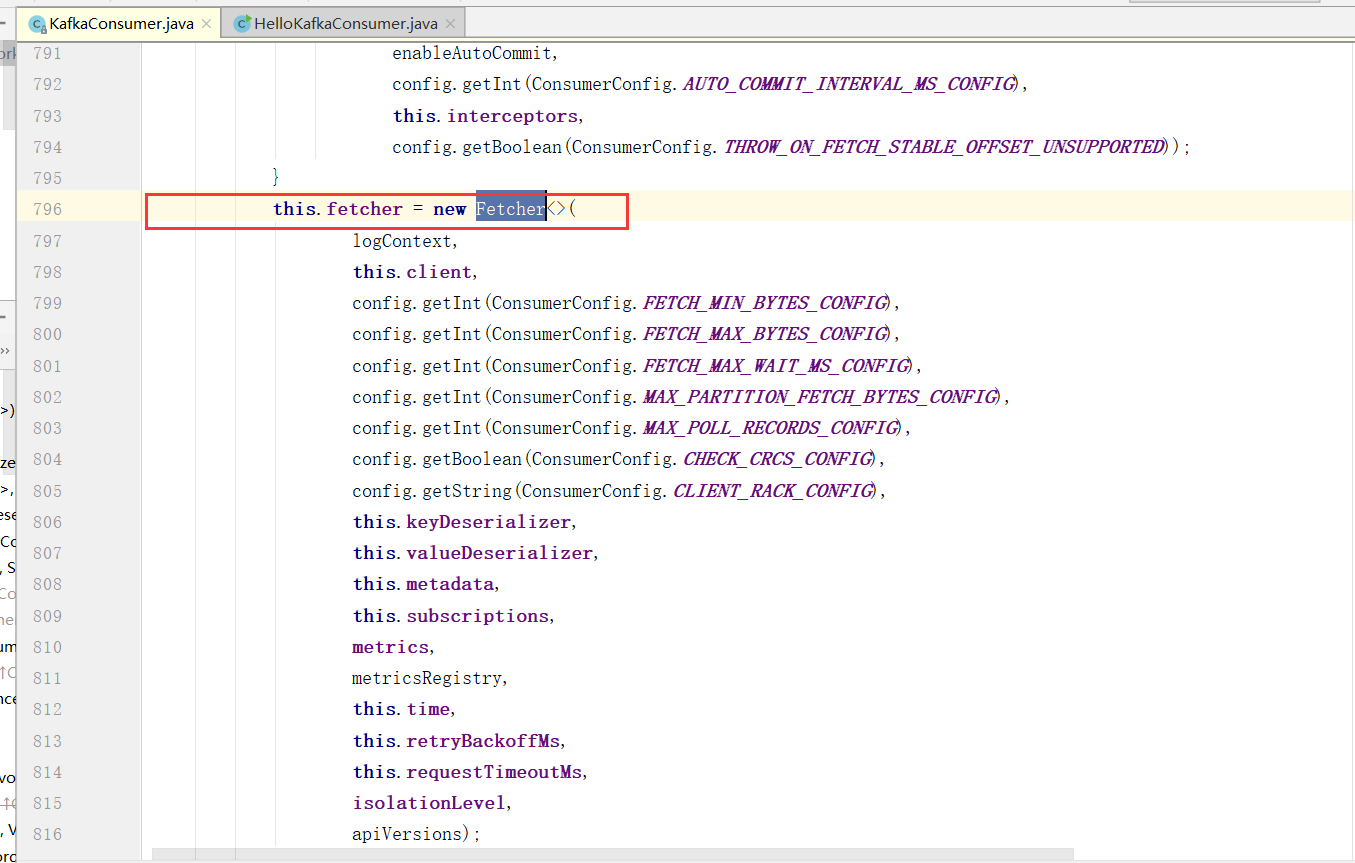
而在这个核心类中,我们发现有很多很多的参数设置,这些就跟我们平时进行消费的时候配置有关系了,这里我们挑一些核心重点参数来讲一讲
fetch.min.bytes
每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。缺省为1个字节。多消费者下,可以设大这个值,以降低broker的工作负载。
fetch.max.bytes
每次fetch请求时,server应该返回的最大字节数。这个参数决定了可以成功消费到的最大数据。
比如这个参数设置的是50M,那么consumer能成功消费50M以下的数据,但是最终会卡在消费大于50M的数据上无限重试。fetch.max.bytes一定要设置到大于等于最大单条数据的大小才行。
默认是50M

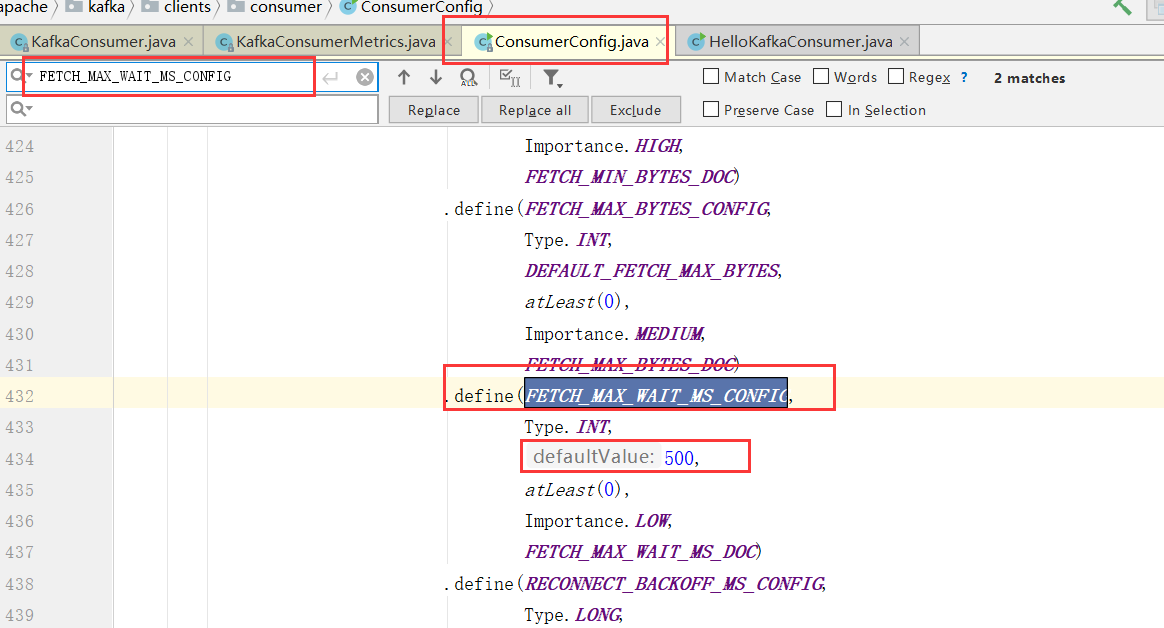
fetch.wait.max.ms
如果没有足够的数据能够满足fetch.min.bytes,则此项配置是指在应答fetch请求之前,server会阻塞的最大时间。缺省为500个毫秒。和上面的fetch.min.bytes结合起来,要么满足数据的大小,要么满足时间,就看哪个条件先满足。
这里说一下参数的默认值如何去找:
max.partition.fetch.bytes
指定了服务器从每个分区里返回给消费者的最大字节数,默认1MB。
假设一个主题有20个分区和5个消费者,那么每个消费者至少要有4MB的可用内存来接收记录,而且一旦有消费者崩溃,这个内存还需更大。注意,这个参数要比服务器的message.max.bytes更大,否则消费者可能无法读取消息。
备注:1、Kafka入门笔记

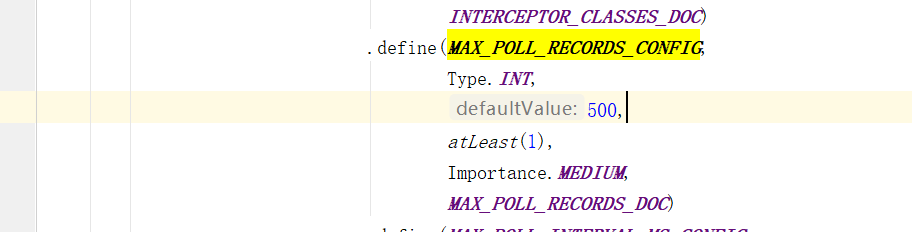
max.poll.records
控制每次poll方法返回的最大记录数量。
默认是500
如何选举Consumer Leader
回顾之前的内容

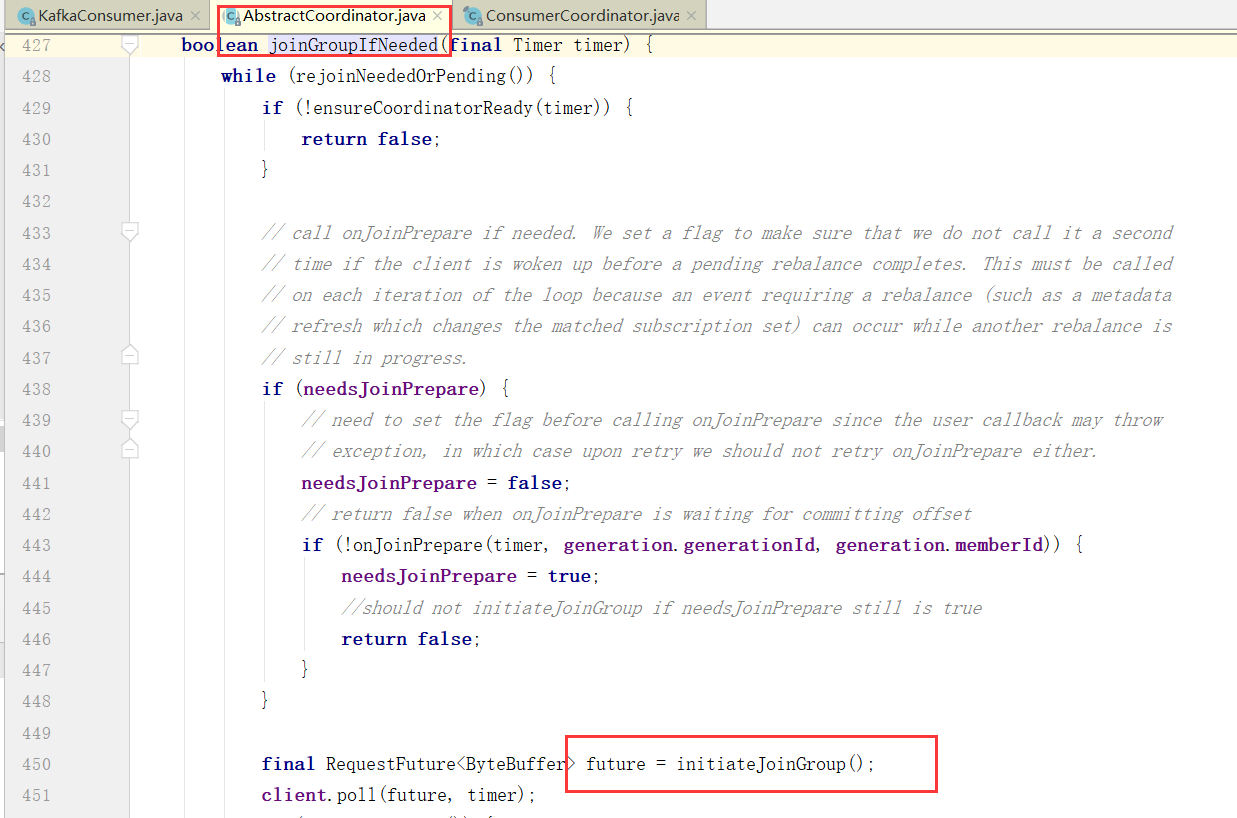
那么如何完成以上的逻辑的,我们跟踪代码:
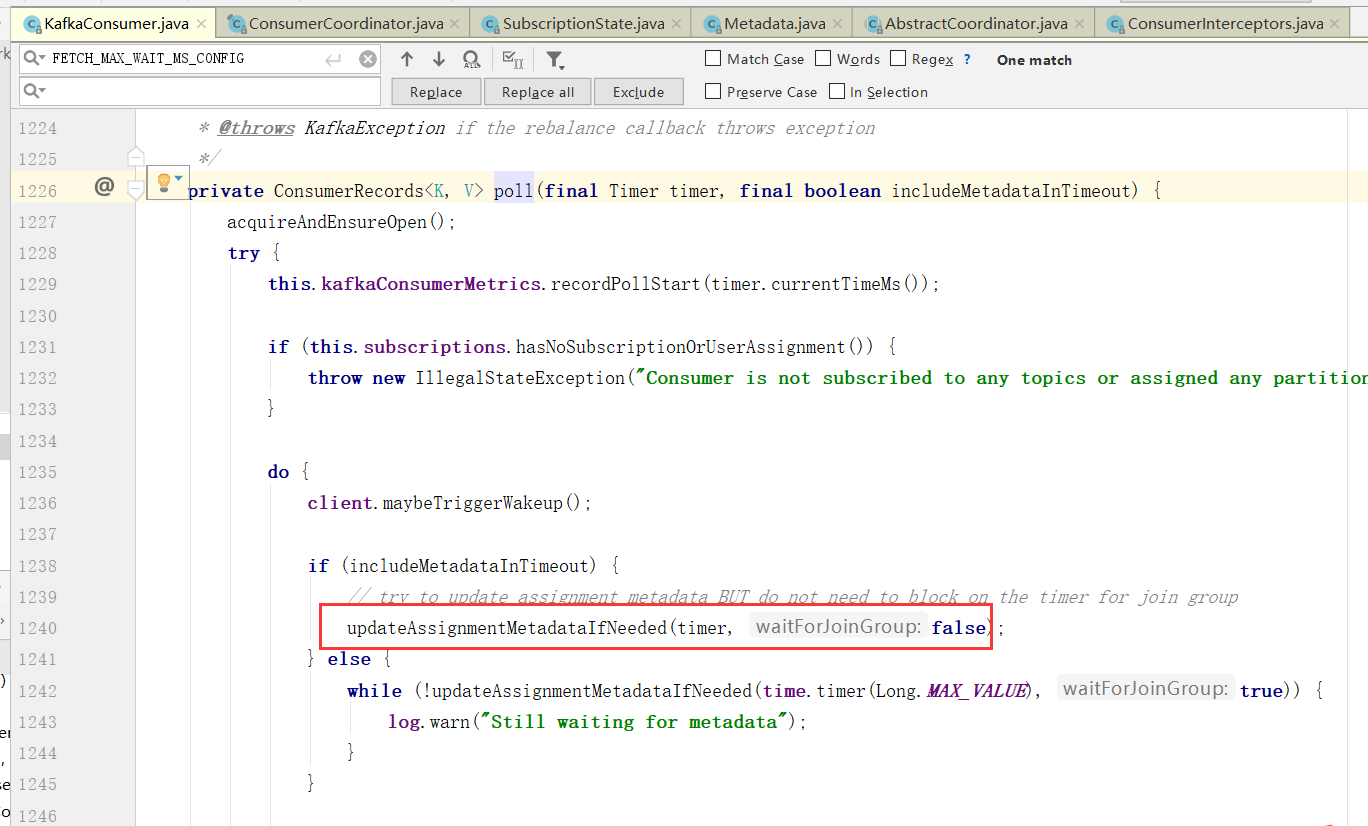
1、消费者协调器与组协调器的通讯

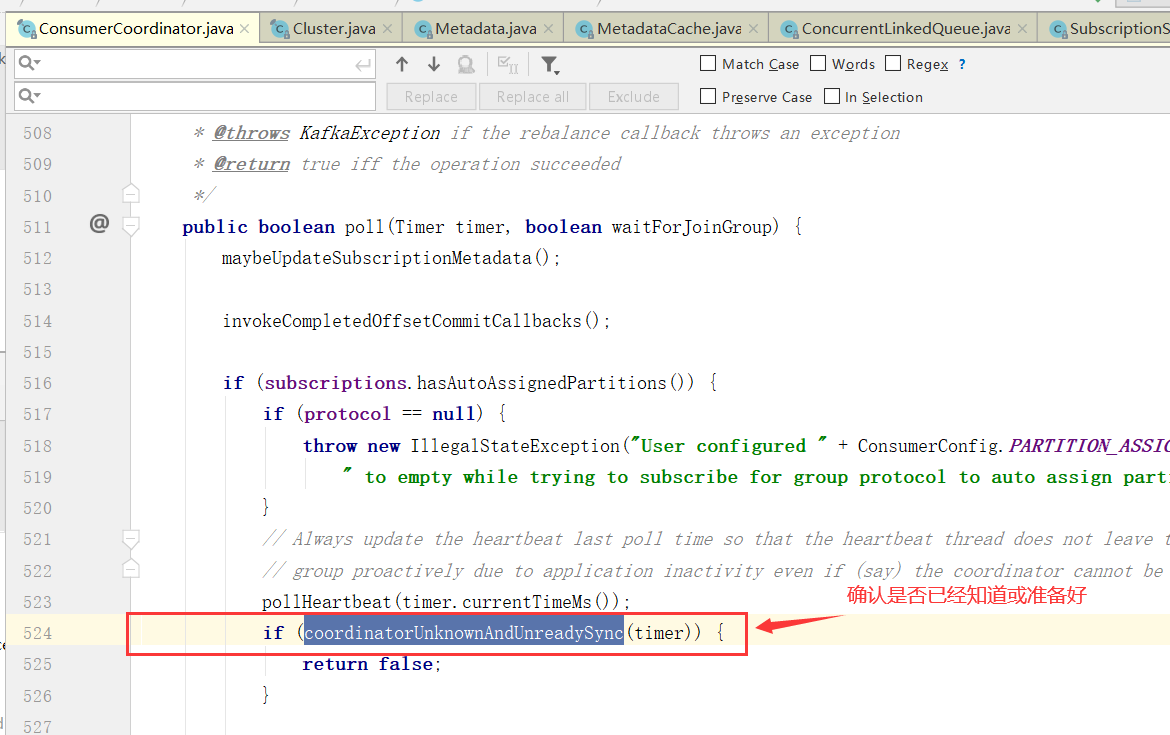

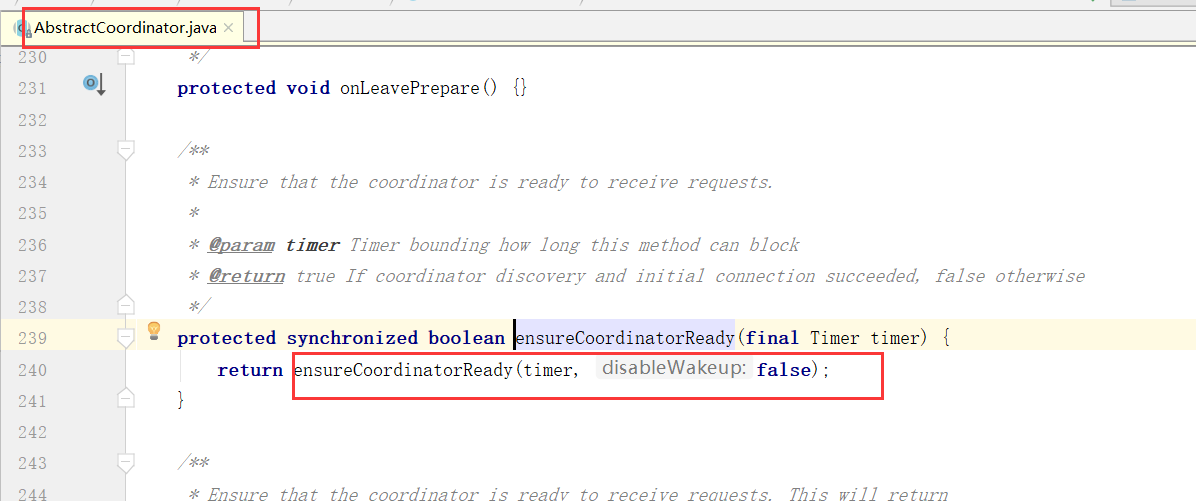
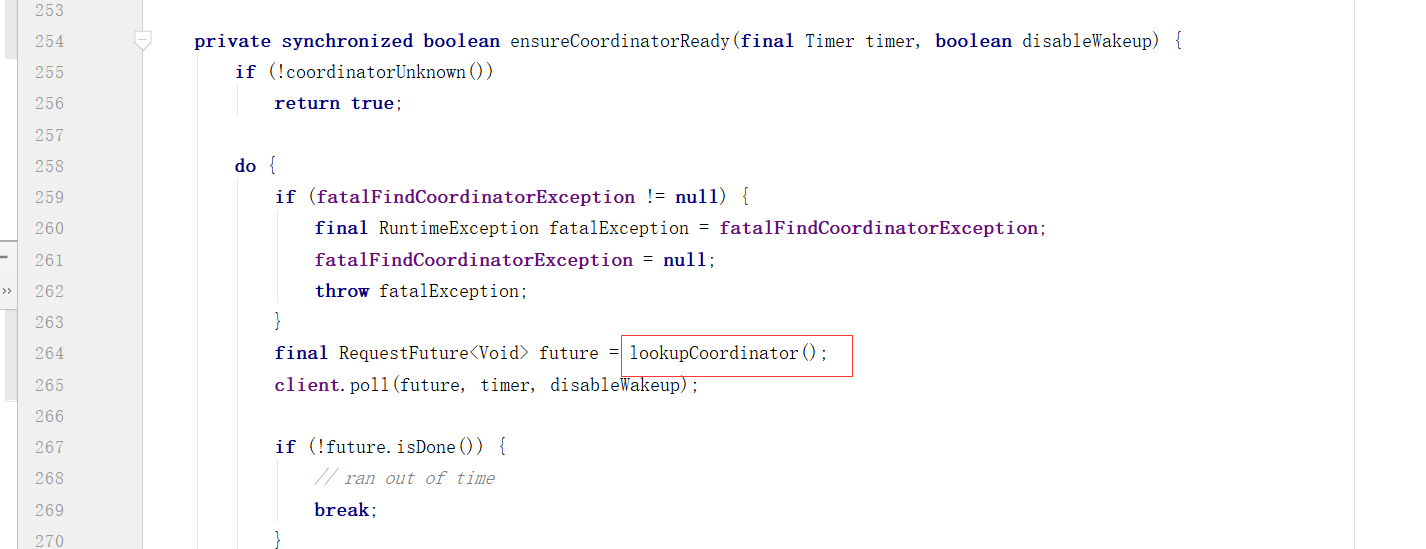
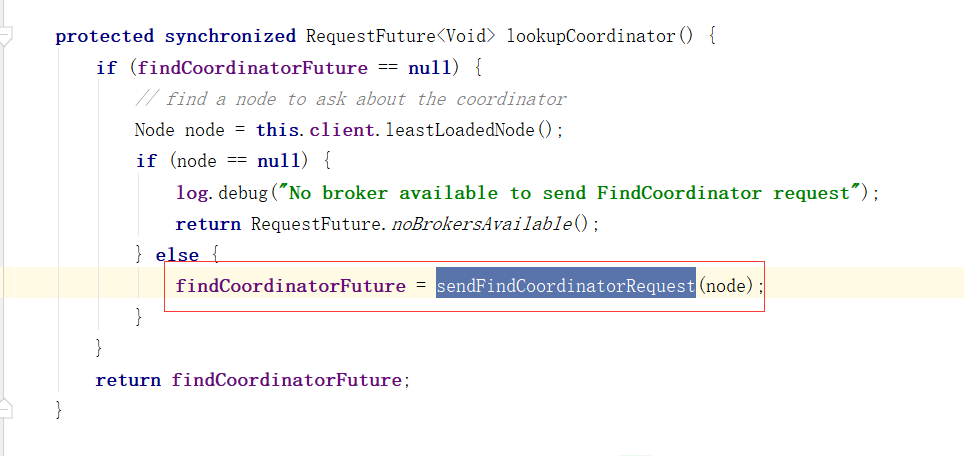
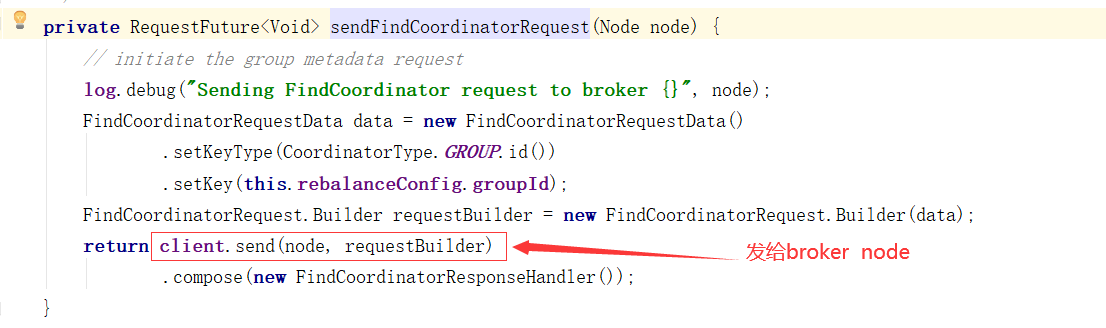
对Broker的响应进行处理
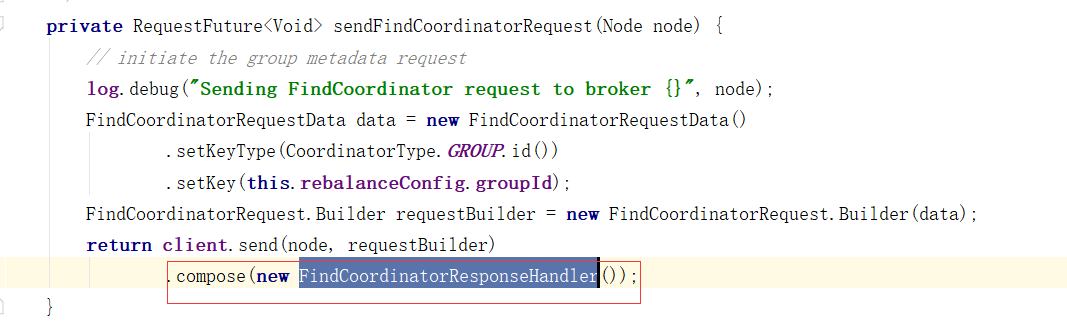
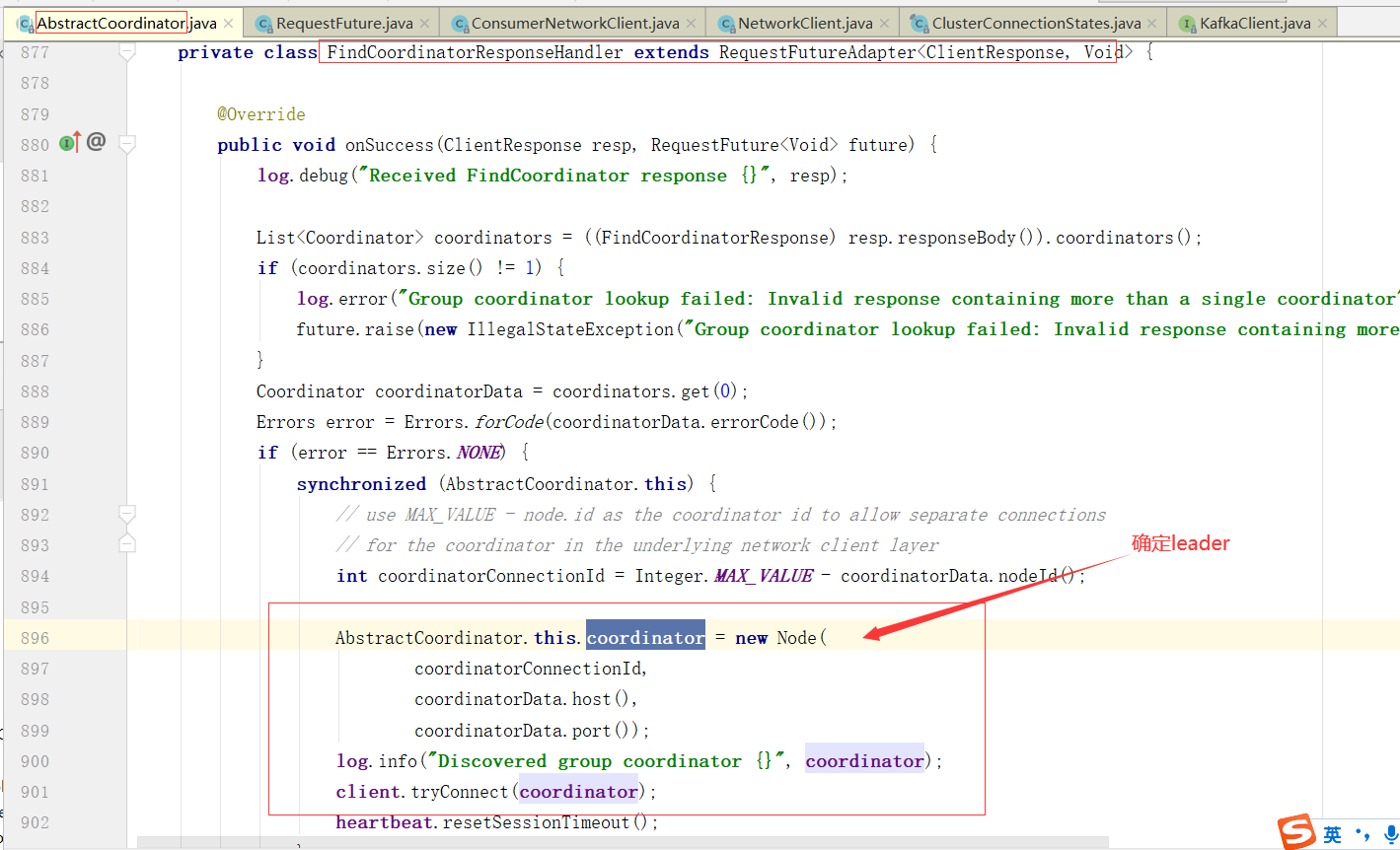
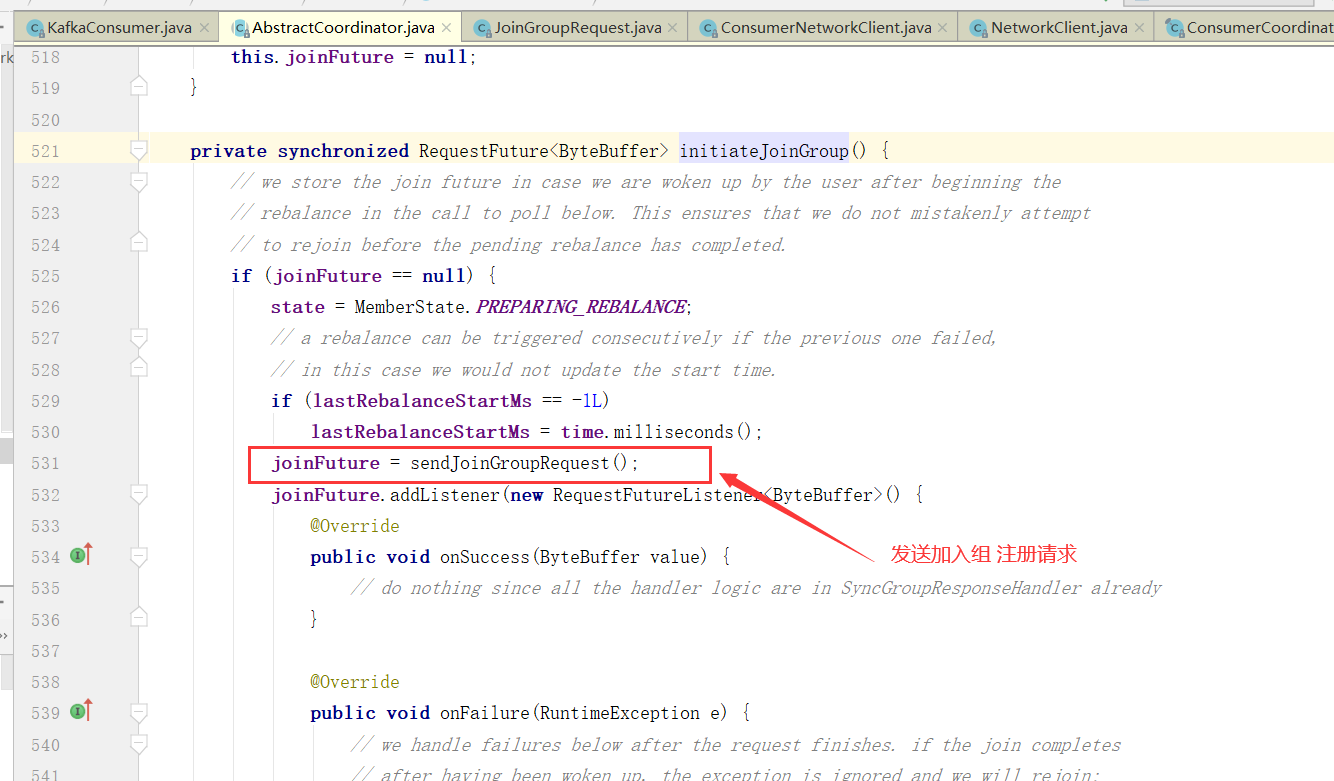
1、消费者协调器发起入组请求
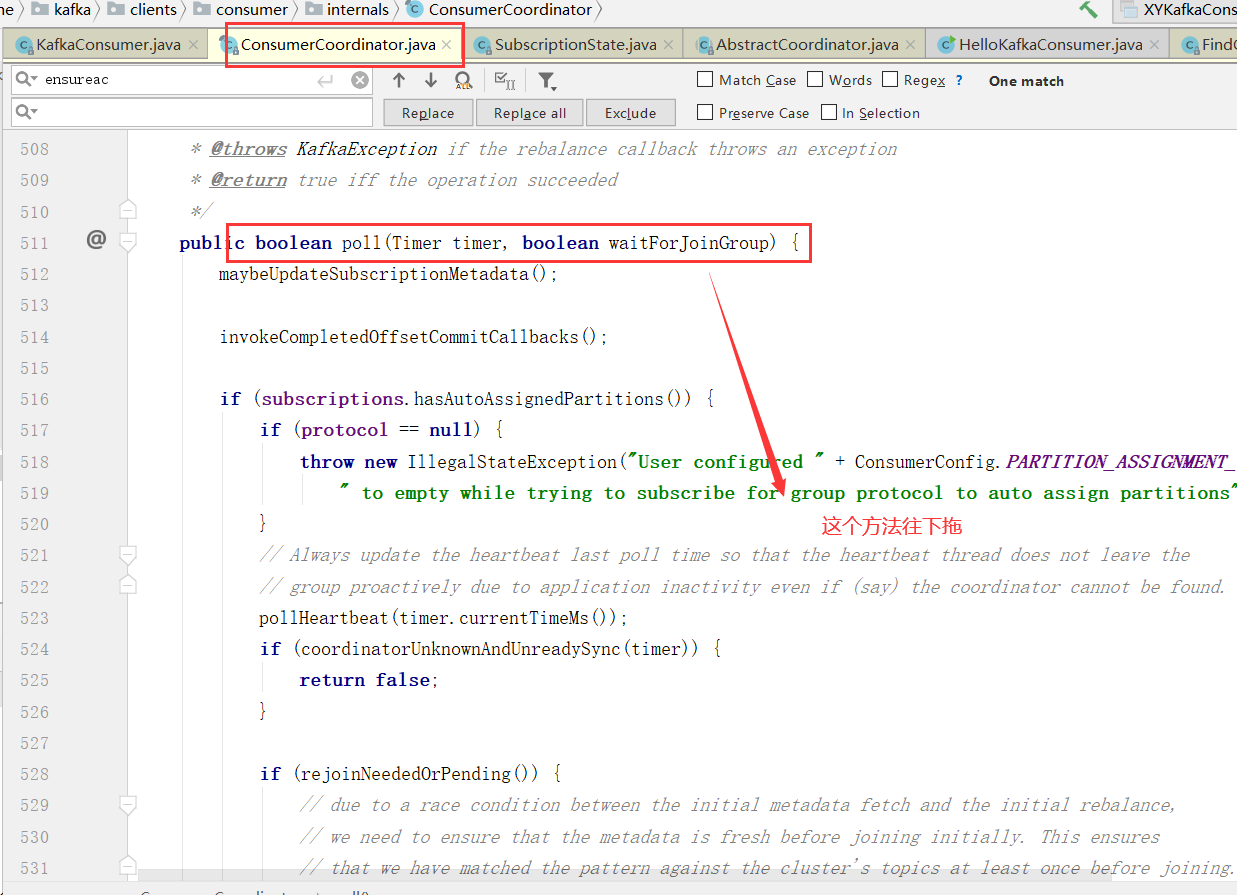
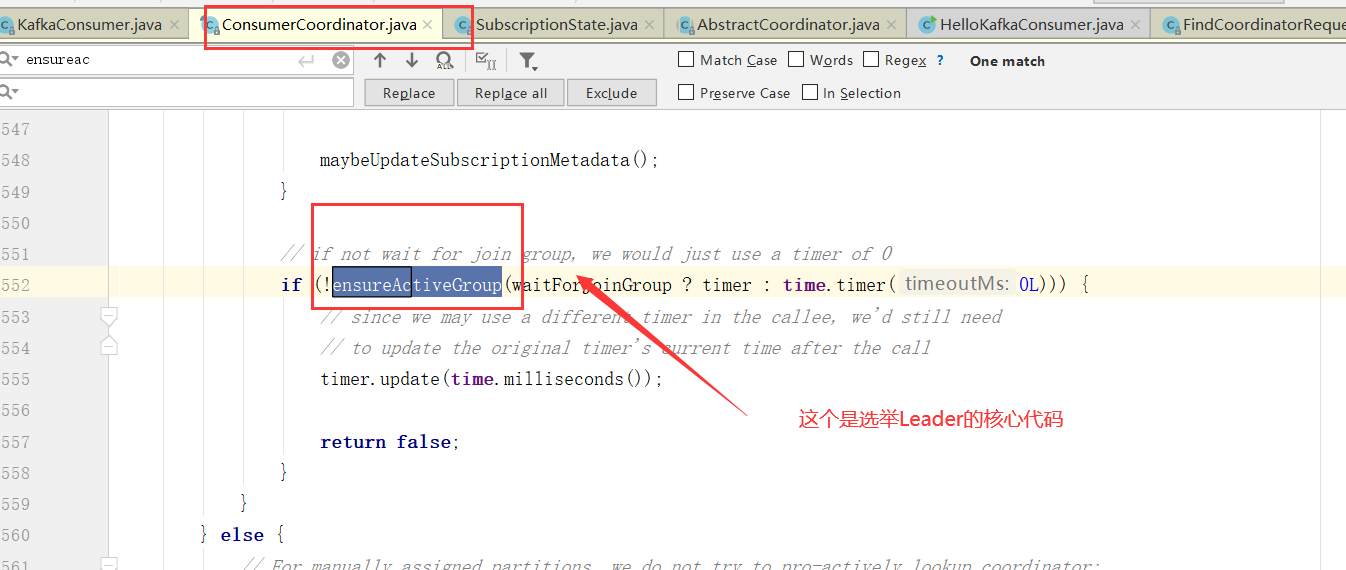
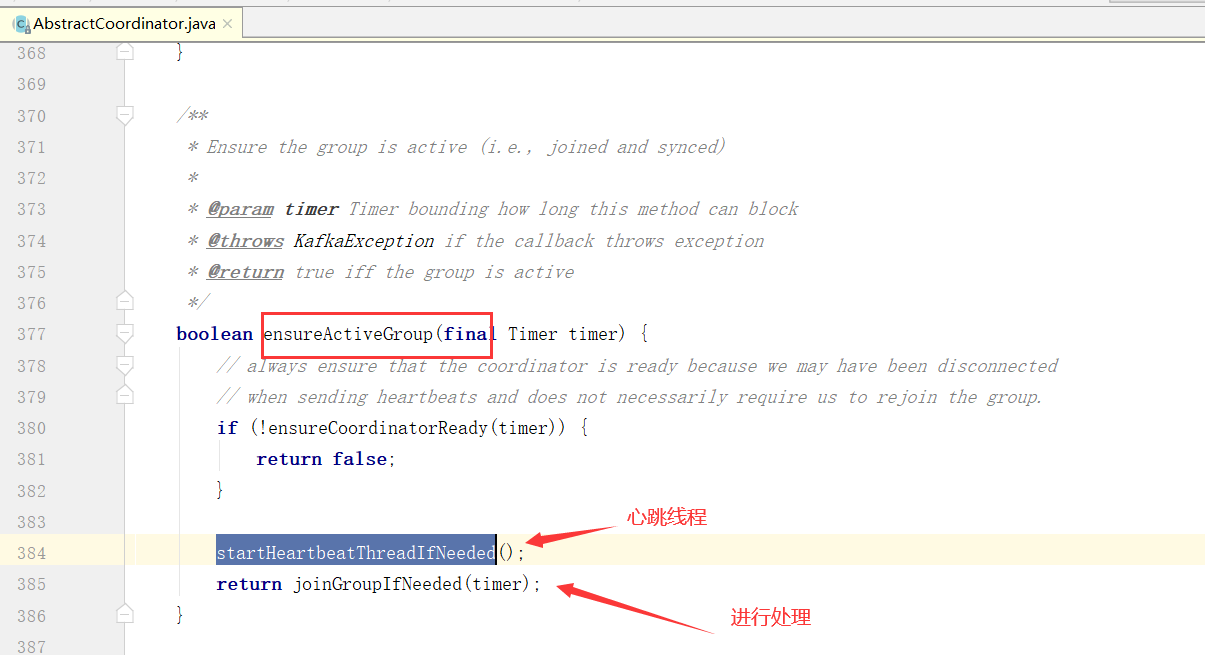
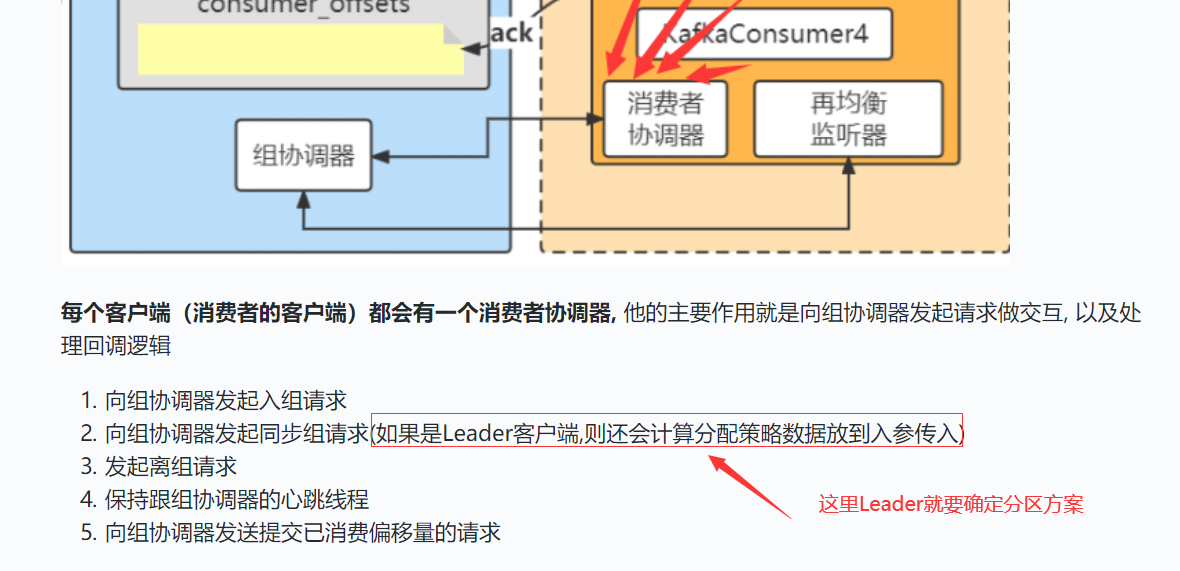
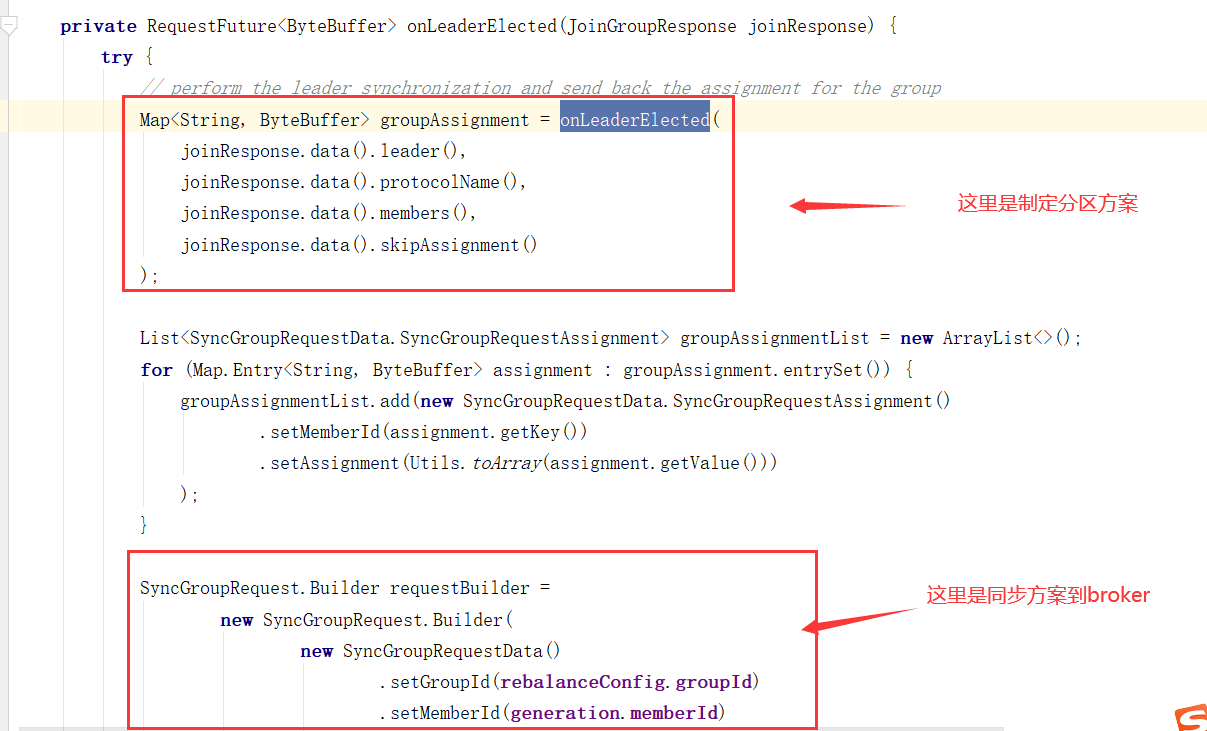
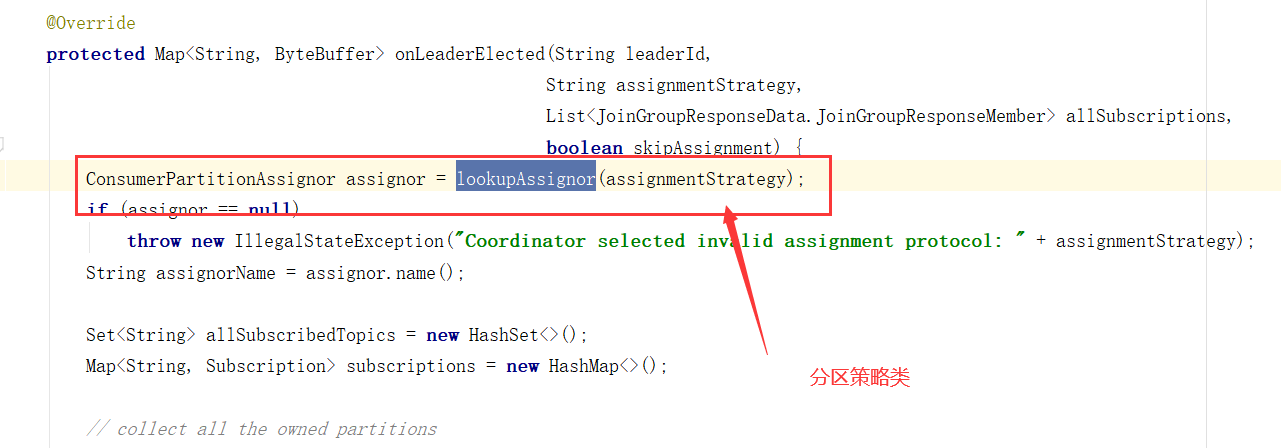
Consumer Leader如何制定分区方案
回顾之前的内容
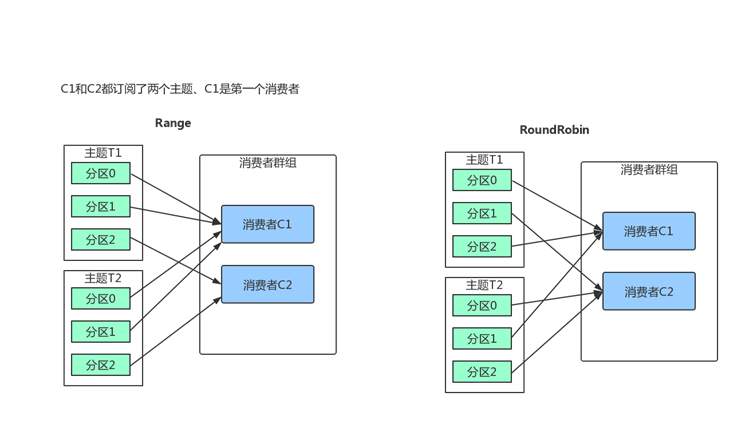
消费者分区策略
消费者参数
partition.assignment.strategy
分区分配给消费者的策略。默认为Range。允许自定义策略。
Range
把主题的连续分区分配给消费者。(如果分区数量无法被消费者整除、第一个消费者会分到更多分区)
RoundRobin
把主题的分区循环分配给消费者。
StickyAssignor
初始分区和RoundRobin是一样
粘性分区:每一次分配变更相对上一次分配做最少的变动.
目标:
1、分区的分配尽量的均衡
2、每一次重分配的结果尽量与上一次分配结果保持一致
当这两个目标发生冲突时,优先保证第一个目标
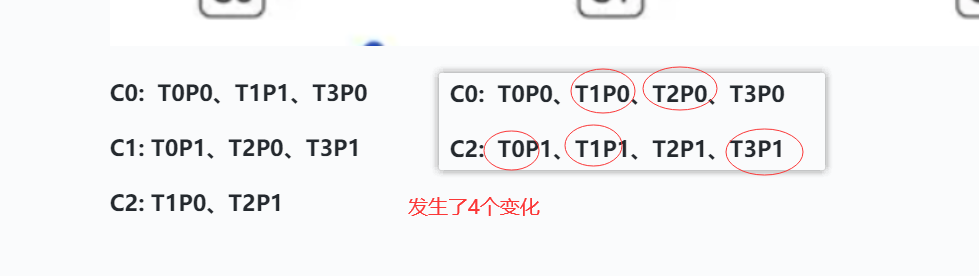
比如有3个消费者(C0、C1、C2)、4个topic(T0、T1、T2、T34),每个topic有2个分区(P1、P2)
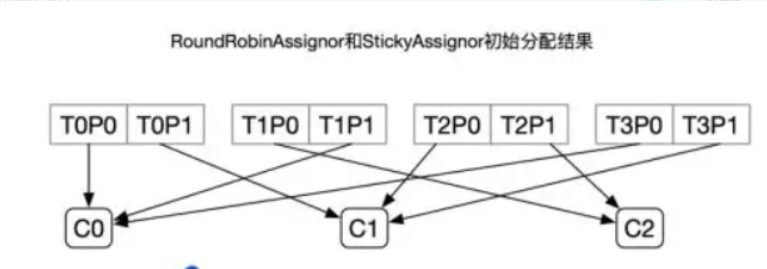
C0: T0P0、T1P1、T3P0
C1: T0P1、T2P0、T3P1
C2: T1P0、T2P1
如果C1下线 、如果按照RoundRobin
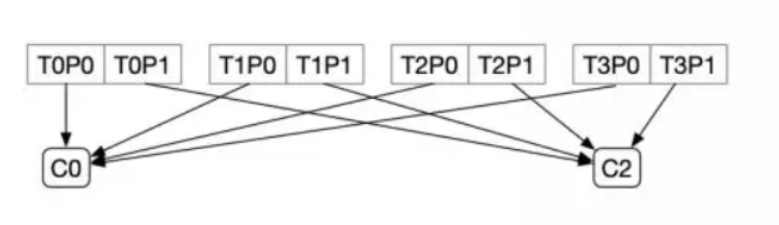
C0: T0P0、T1P0、T2P0、T3P0
C2: T0P1、T1P1、T2P1、T3P1
对比之前
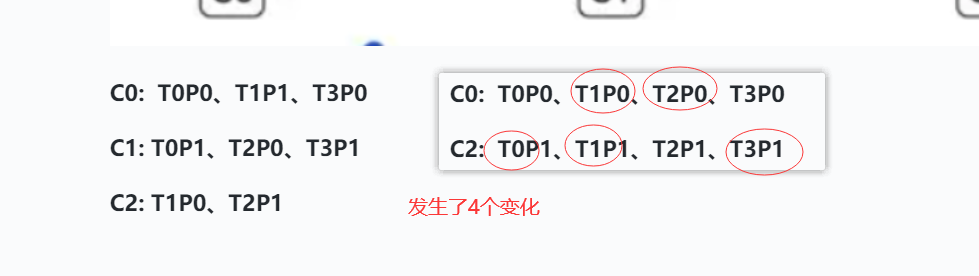
如果C1下线 、如果按照StickyAssignor
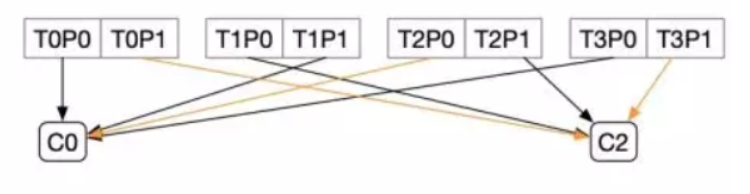
C0: T0P0、T1P1、T2P0、T3P0
C2: T0P1、T1P0、T2P1、T3P1
对比之前

自定义策略
extends 类AbstractPartitionAssignor,然后在消费者端增加参数:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,类.class.getName());
即可。
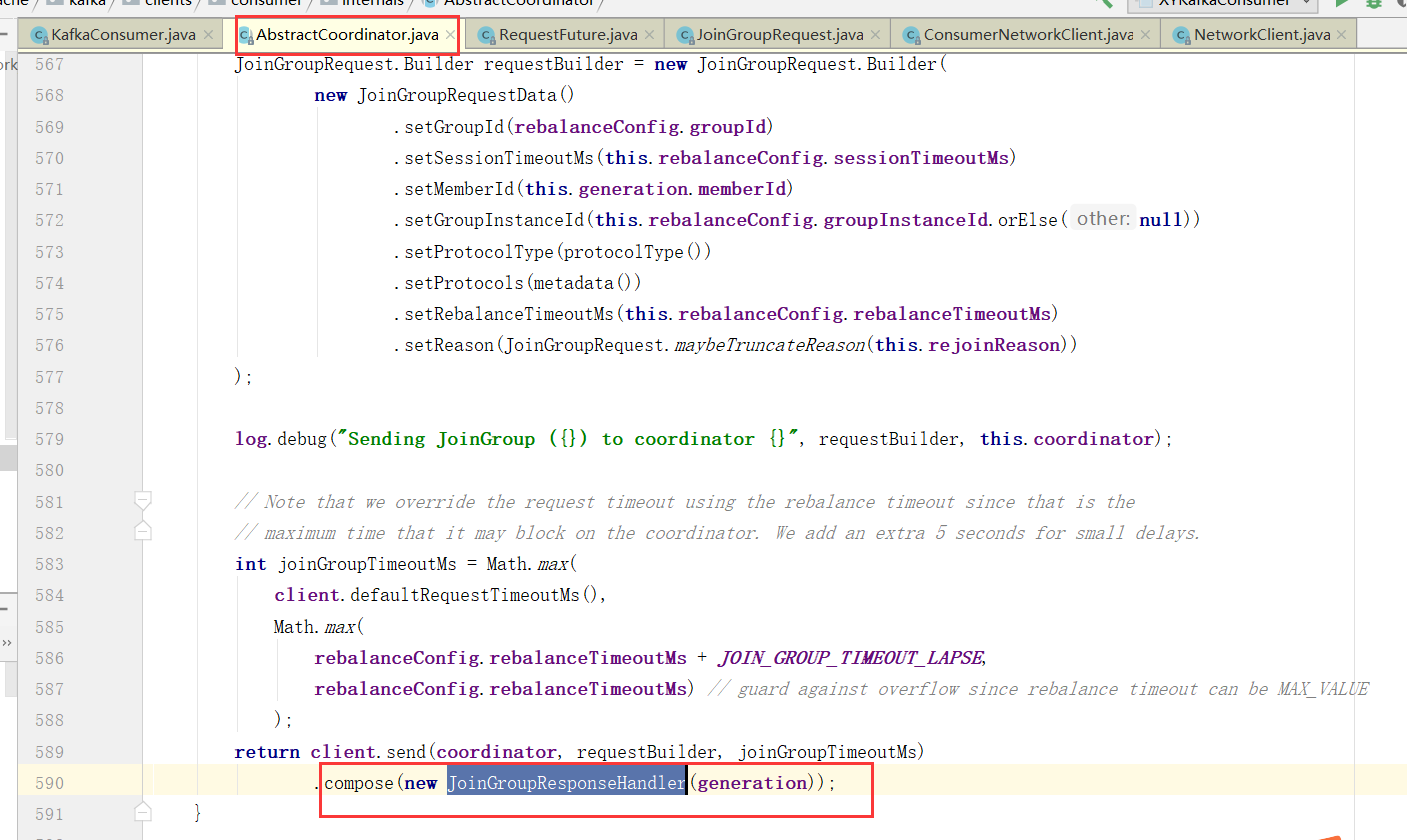
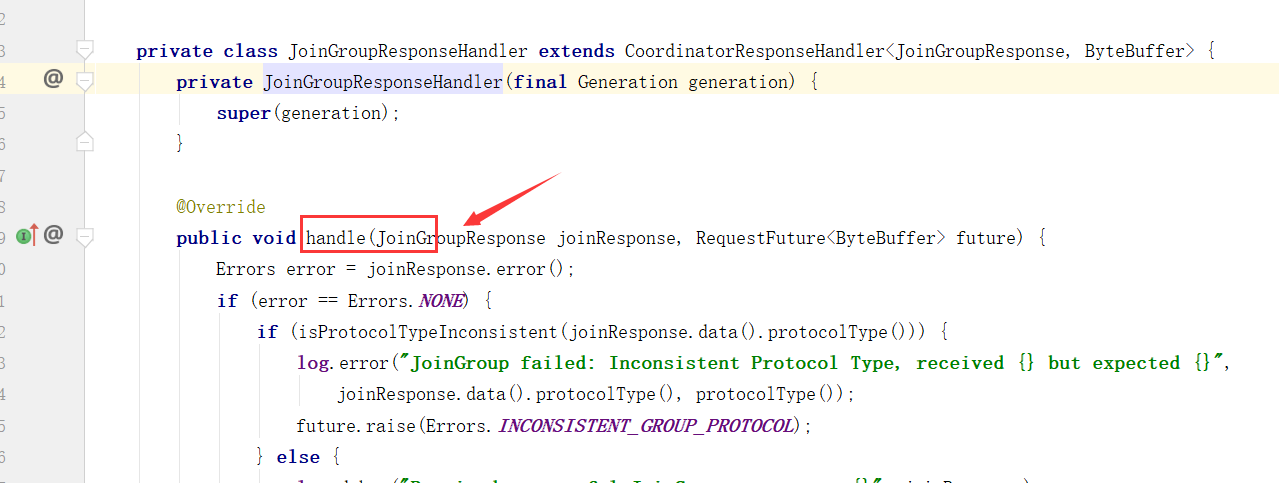
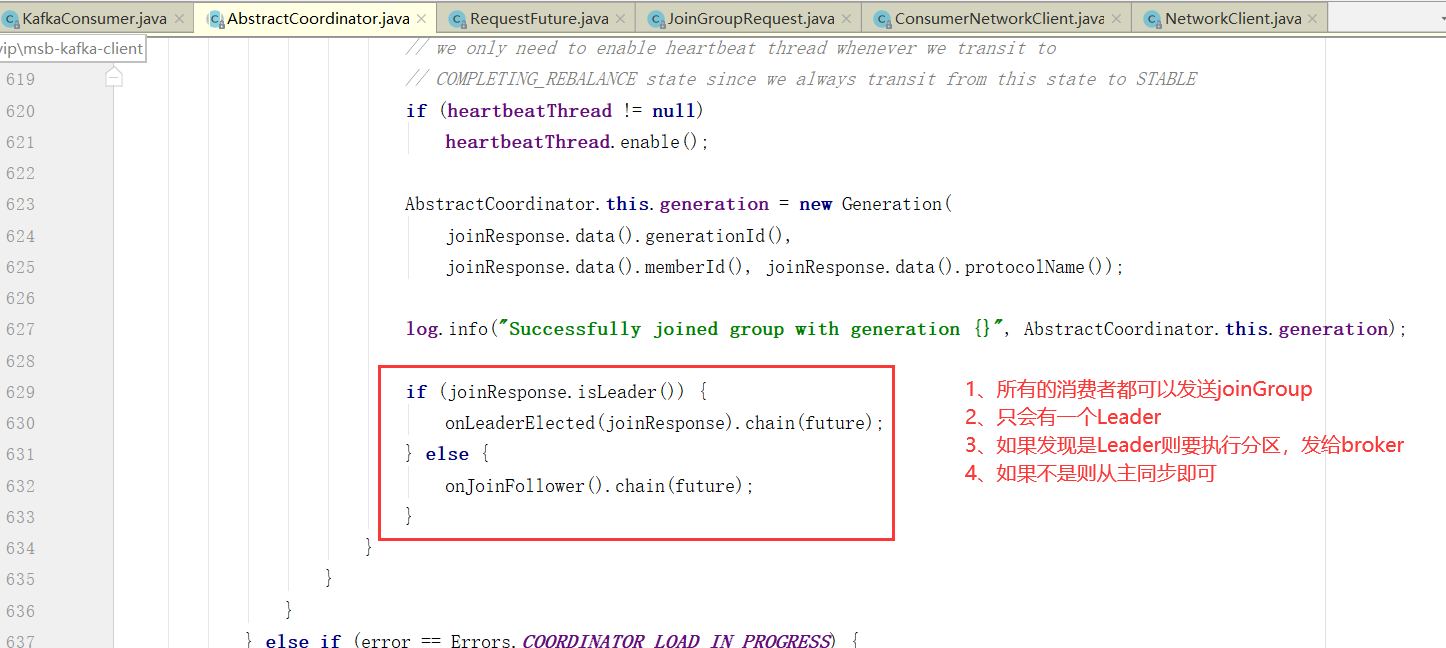
消费者分区策略源码分析
接着上个章节的代码。
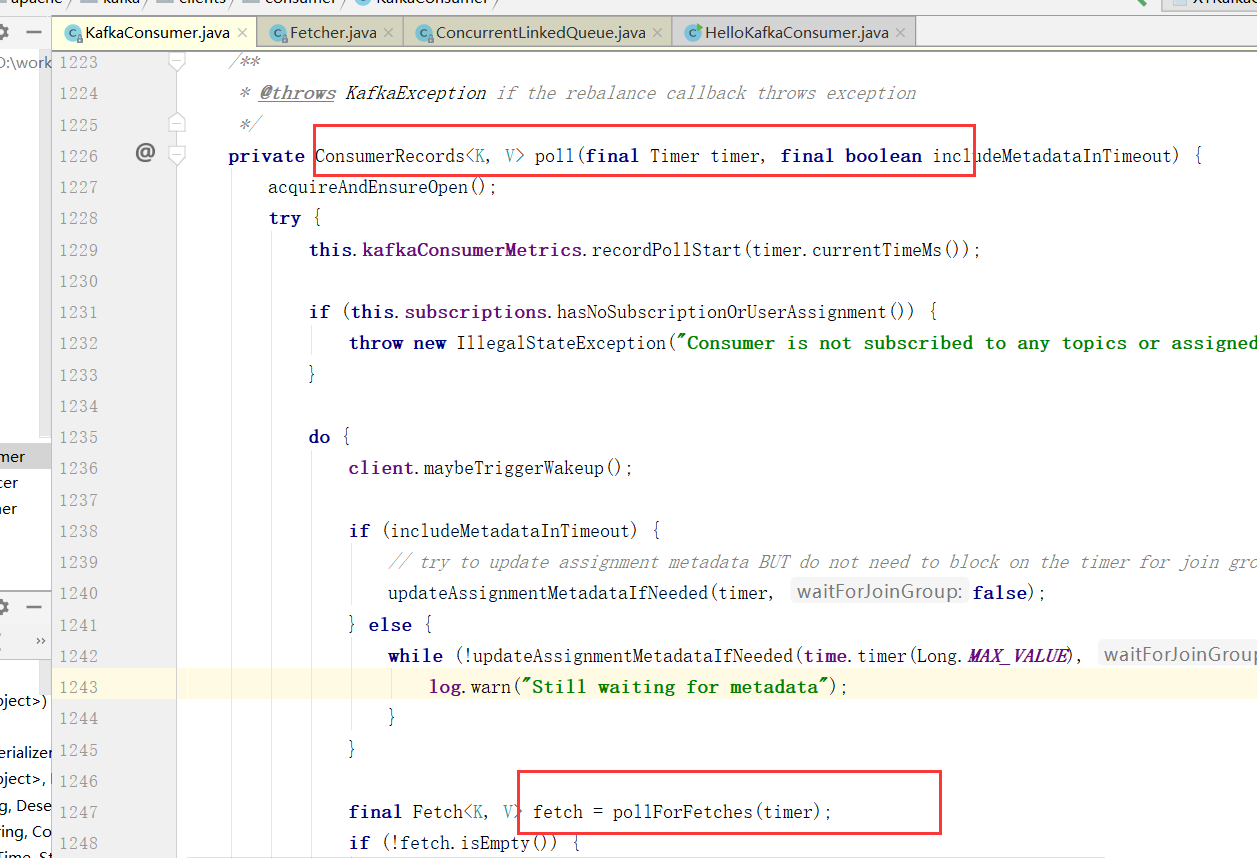
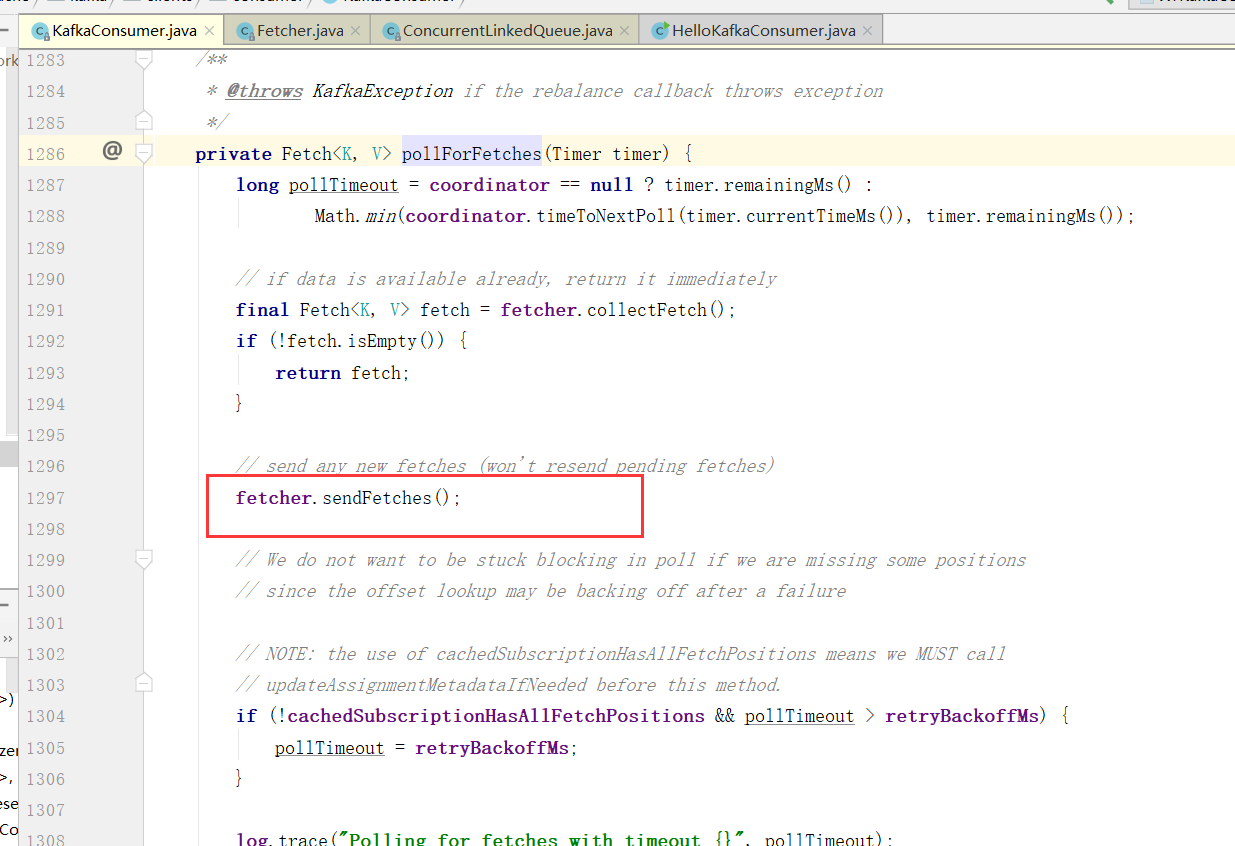
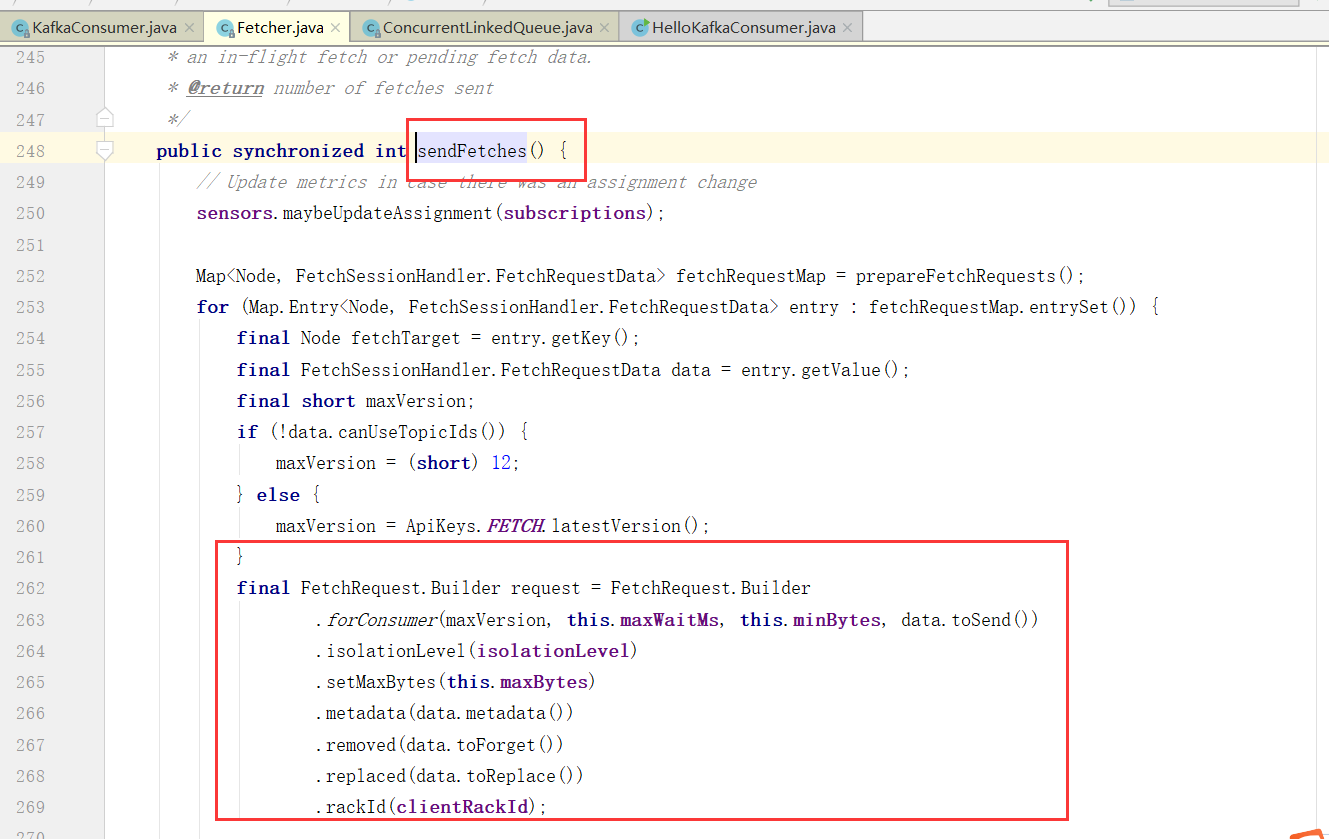
Consumer拉取数据
这里就是拉取数据,核心Fetch类
自动提交偏移量
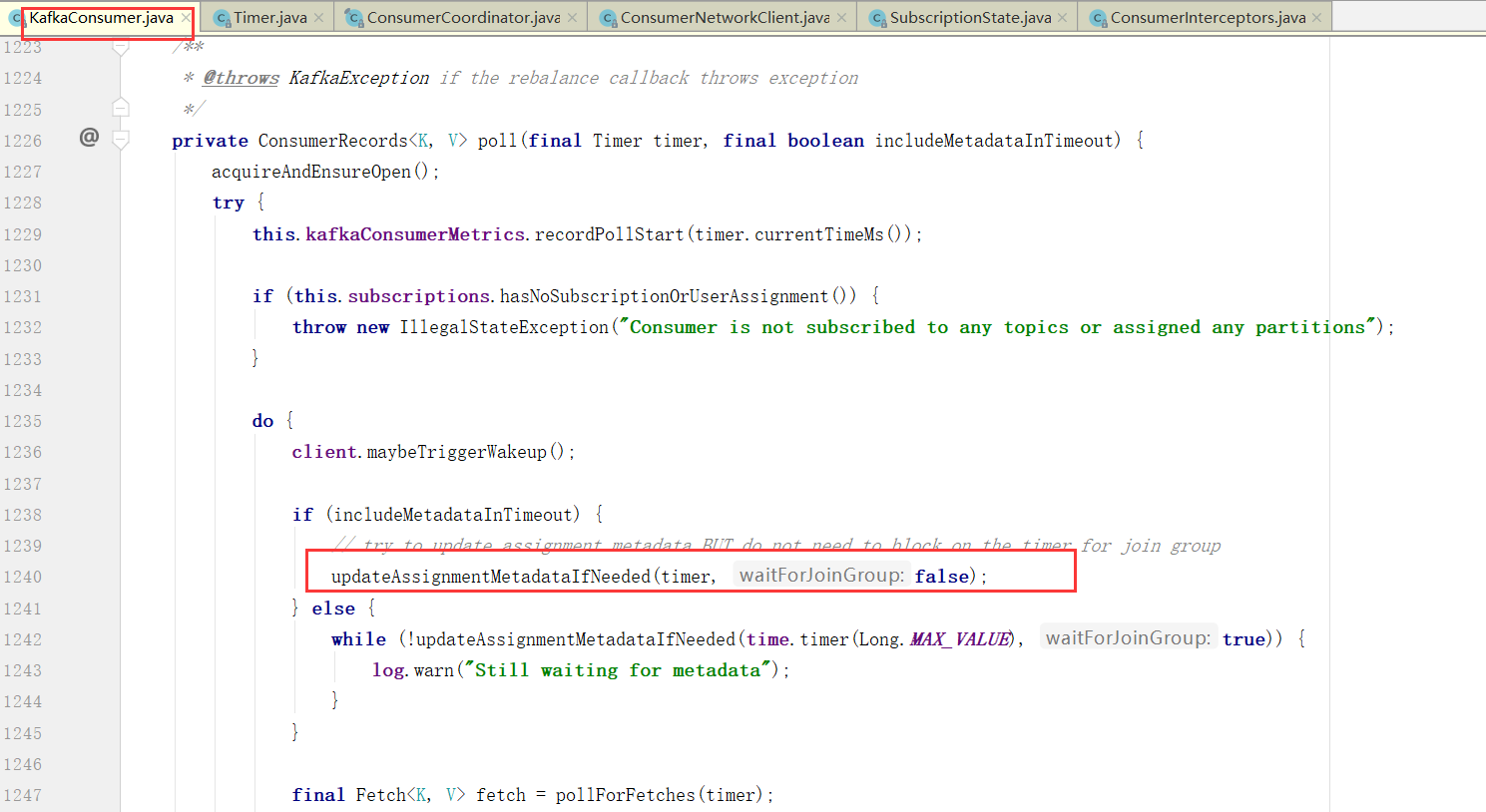
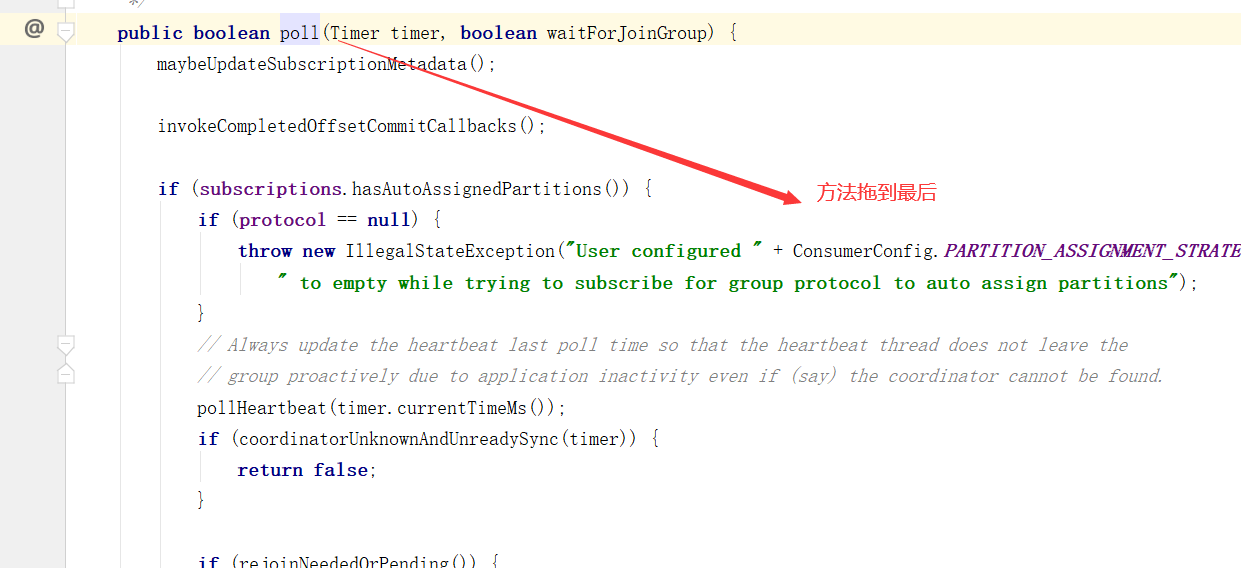
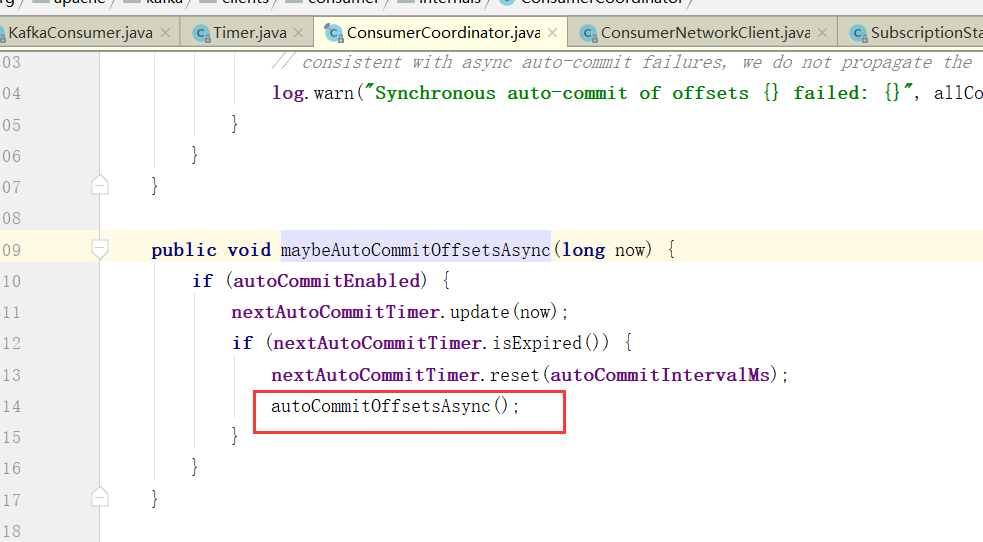
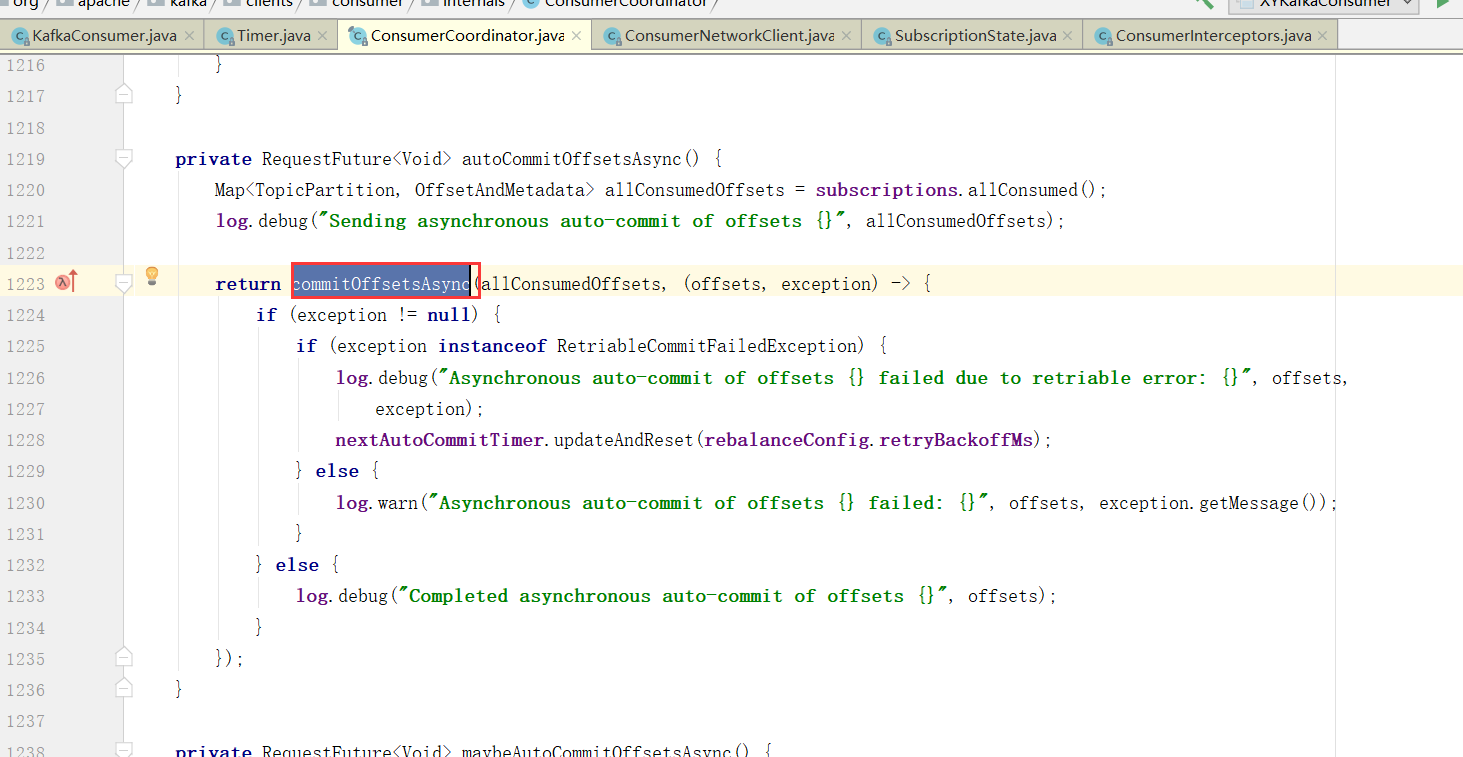
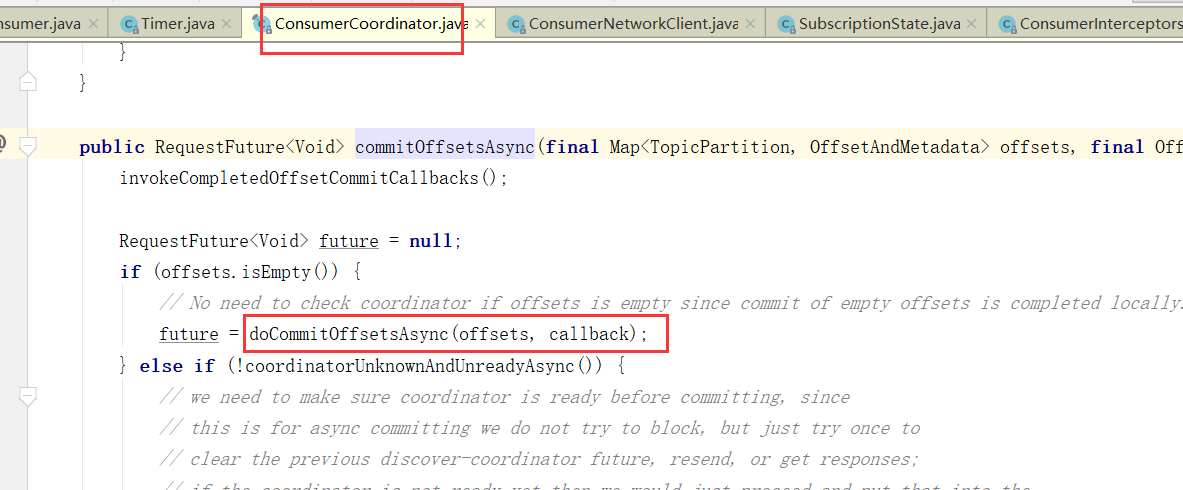

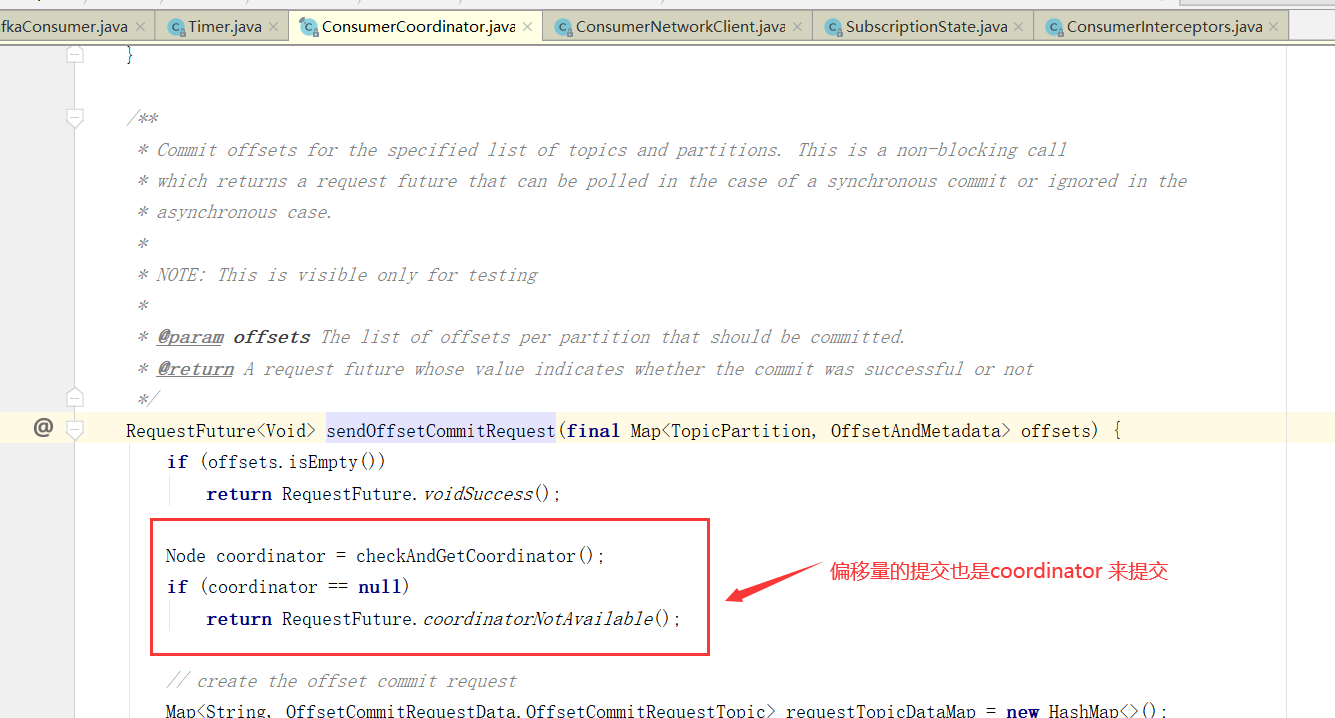
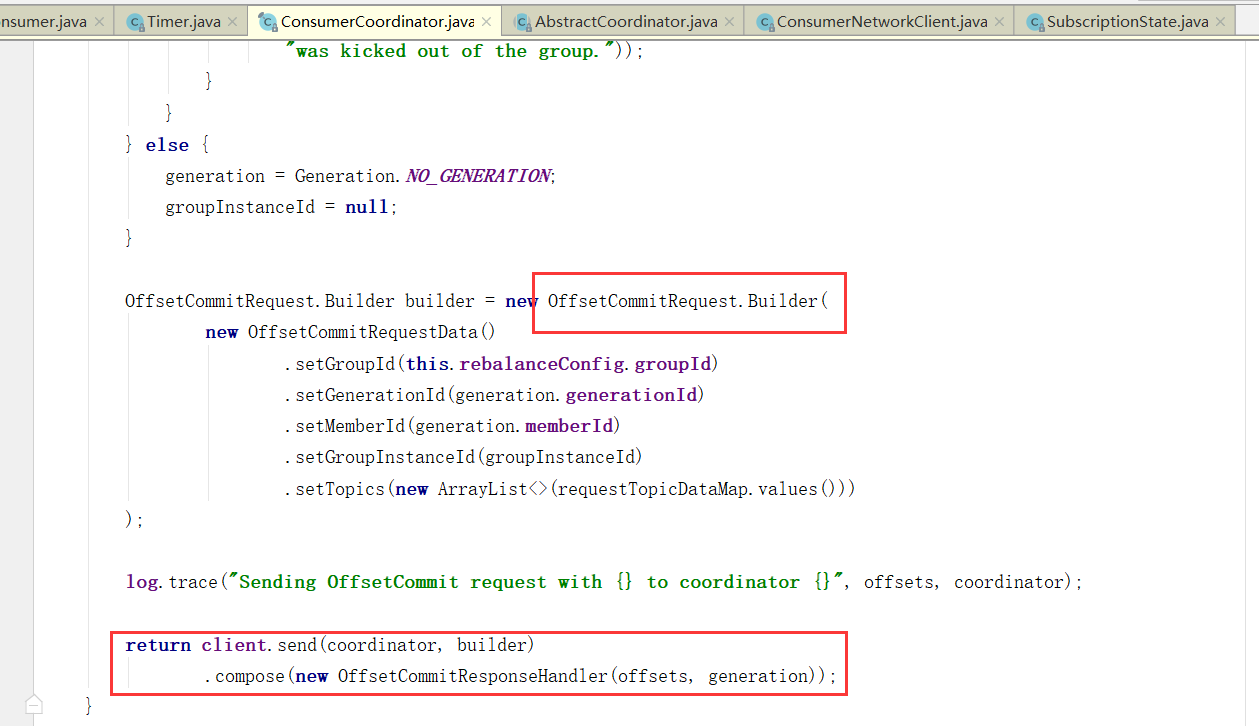
当然,自动提交auto.commit.interval.ms

默认5s
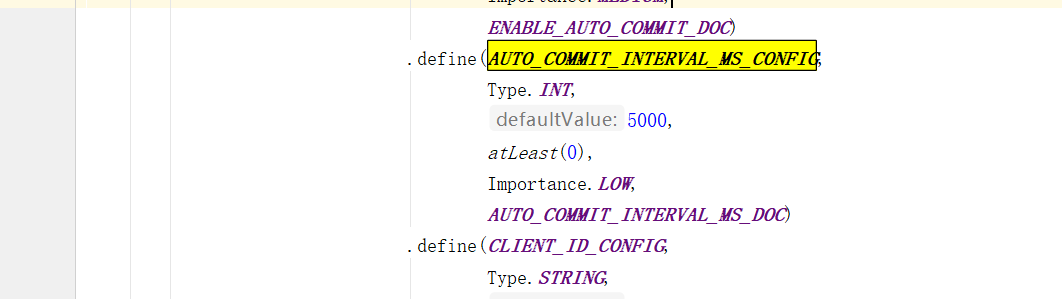
从源码上也可以看出
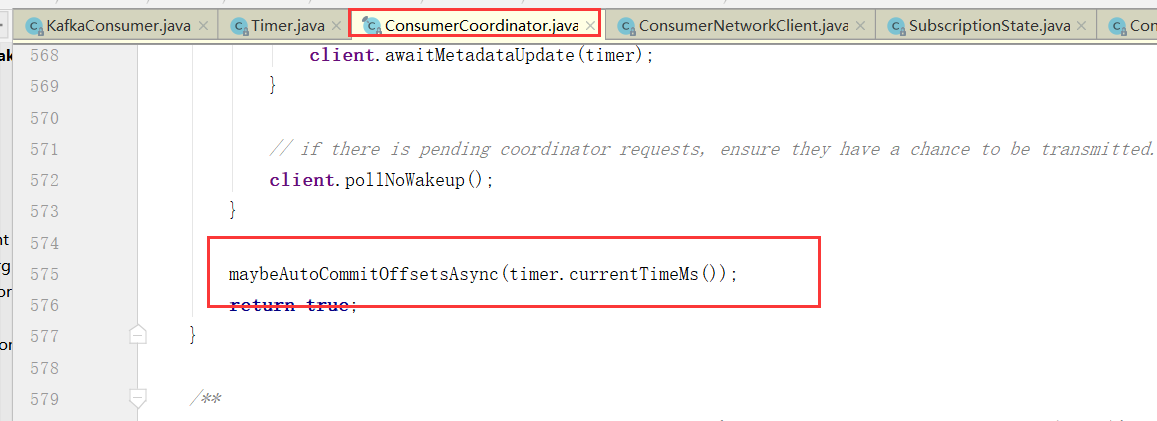
maybeAutoCommitOffsetsAsync 最后这个就是poll的时候会自动提交,而且没到auto.commit.interval.ms间隔时间也不会提交,如果没到下次自动提交的时间也不会提交。
这个autoCommitIntervalMs就是auto.commit.interval.ms设置的
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 幻兽帕鲁服务器搭建
- RocketMq查看消息轨迹
- 在未来的一个时期,阿里将会和AI电商联系在一起
- 【ARMv8M Cortex-M33 系列 7 -- RA4M2 移植 RT-Thread 问题总结】
- JavaScript基础01
- 【.NET Core】Linq查询运算符(三)
- 【python股票价格预测】基于Naive、MA和ARIMA的股票价格预测(附python代码)
- 羊奶从牧场到餐桌都有哪些工序
- wordpress打包小程序并能分享转发
- Linux mdu命令教程:如何有效地使用mdu命令(附实例教程和注意事项)