机器学习:何为监督学习和无监督学习
目录
一、监督学习
? ? ? ? 介绍:监督学习是指学习输入到输出(x->y)映射的机器学习算法,监督即理解为:已知正确答案对其学习结果进行监督
? ? ? ? 原理:提供算法示例以供学习,通过查看 x->y 的正确示例,使得算法最终达到给定输入值 x 可以获得对于输出值 y 的合理预测或猜测结果
? ? ? ? 例子:监督学习主要包括分类问题和回归问题,如一个判断邮件是否为垃圾邮件、广告公司根据客户数据判断是否会点击广告、根据房子的面积拟合合适的线条预测房价,等等。
(一)回归
????????如下图是一个监督学习的特殊例子——回归,给定了算法一个数据集,其中对于每个面积 x,都有一个“正确答案”——y 标签,学习算法将持续进行学习,从无数个可能的输入对象预测结果
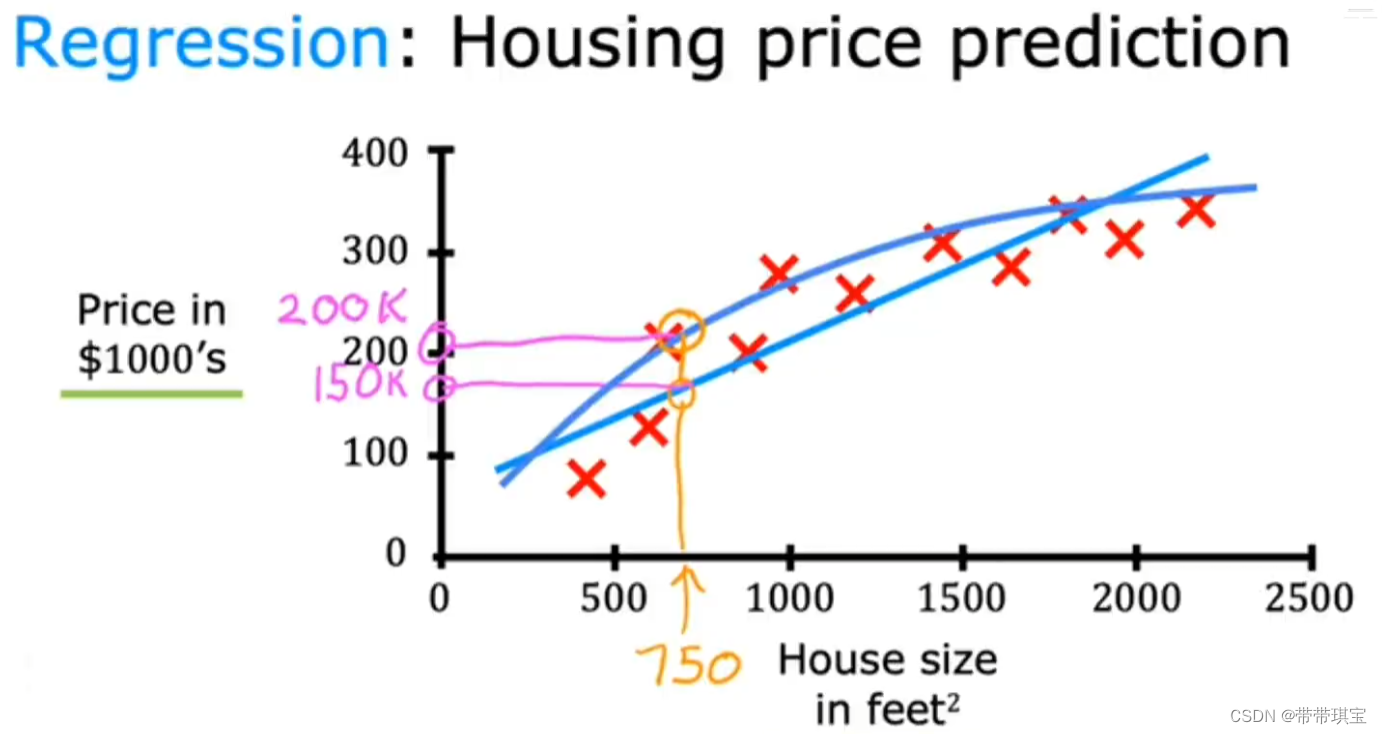
? ? ? ? 未来探讨的问题在于,如何选择合适的直线或其他曲线对模型拟合
(二)分类
? ? ? ? 如医生使用一个诊断工具,根据病人医疗记录数据判断肿瘤是否是恶性的还是良性的,从而检测一名病人是否患有乳腺癌
? ? ? ? 为了简便,假设可以通过肿瘤大小这一属性判断其性质,在过往数据集里,可能有各种各样大小的肿瘤,如下横轴代表肿瘤大小,标记代表两个值(O为良性,X为恶性),学习算法可以以此判断是否为恶性肿瘤
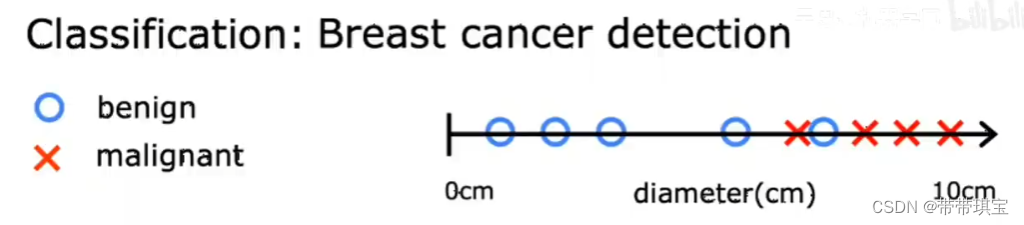
? ? ? ? 有可能会有多个输出类型

? ? ? ? 也可以有多个输入值来预测输出:如根据年龄和肿瘤大小两个属性判断是否恶性
? ? ? ? 基于这样的数据集,学习算法要做的是找到合适的边界区分恶性肿瘤和良性肿瘤

????????除此之外可能会有更多的属性进行协助判断并得出结果
? ? ? ? 分类与回归的最大区别:分类输出的是预测类别,小而有限(如0,1,2,则不能是除了这三类外的任意数字),而回归会从无线个可能的输入预测结果
二、无监督学习
聚类
? ? ? ? 监督学习中,每个示例 x 与输出标签 y 相关联(x->y),而在无监督学习中,数据并未和任意输出标签相关,我们也没有对输入值指定一个所谓的“正确答案”,而是,在数据集中发现其本身特有的结构或模式。
????????如在上述肿瘤检测的问题中,我们并未给定所谓“良性”或“恶性”的标签,而由聚类算法(无监督学习的一种)自己决定:如何把并未标记的数据集划分为不同集群
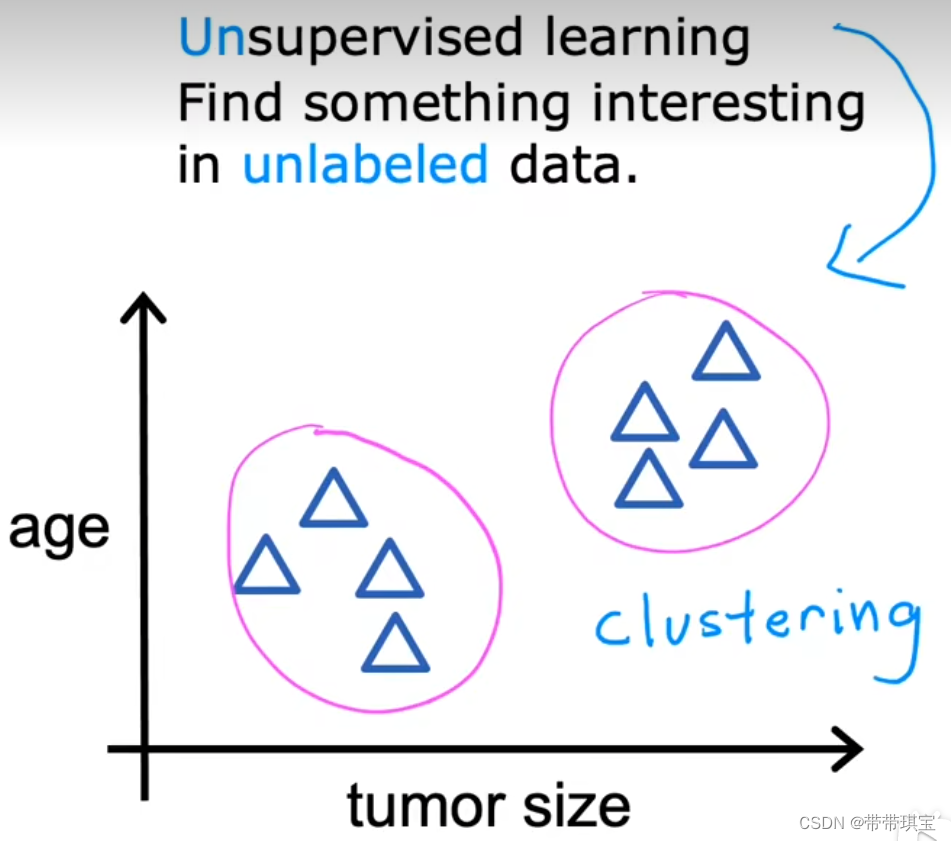
????????如对于一个“某一些人为什么想学习AI”这个问题,聚类算法会根据客户信息的数据库,在没有标签的情况下自动将客户划分为某些类别,这个过程并不需要人为干预

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 132基于matlab的采集信号模极大值以及李氏指数计算
- 基于JavaWeb+SSM+Vue基于微信小程序的消防隐患在线举报系统的设计与实现
- 30岁高薪转行鸿蒙,只因我做了这3件事
- AcWing P89:a^b(快速幂)
- Vue过滤器详解
- Flutter 与 Android原生 相互通信:BasicMessageChannel、MethodChannel、EventChannel
- 算法导论复习(二)
- 动态规划问题
- 华为无线ac双链路冷备和热备配置案例
- Linux系统报错锦集二: engine libaio not loadable