数据分享|纯净音自然多轮对话数据集——语音大模型
发布时间:2024年01月12日
在过去的一年里,大语言模型一路高歌猛进,让人惊艳的产品不断被推出。语音大模型也迎来突破,其中就包括还原度越来越高的声音复刻技术。
优秀的语音复刻性能离不开高质量的训练数据支撑。语音大模型构建需要大量的自然数据,尽可能保证自然度,内容多样性,以及口音多样性。晴数智慧设计的纯净音自然多轮对话数据集,为语音大模型训练使用,录制环境安静纯净,录音人地区分布广泛,人数众多,领域设计广泛,版权清晰,是市面上不可多得的语音复刻/对话大模型的高品质选择。
数据概览

数据亮点
1、纯净录制环境
数据采集环节对环境进行了配置,确保采集环境相对安静,环境噪音少。
2、多风格自发对话
此数据集含有说话人在多种状态下的自发对话,包括商务工作、购物咨询、争议协商、闲聊等状态,帮助机器学习及掌握人类在多种对话状态下的发音特征和风格从而实现更好地拟合。
3、风格、领域多样性
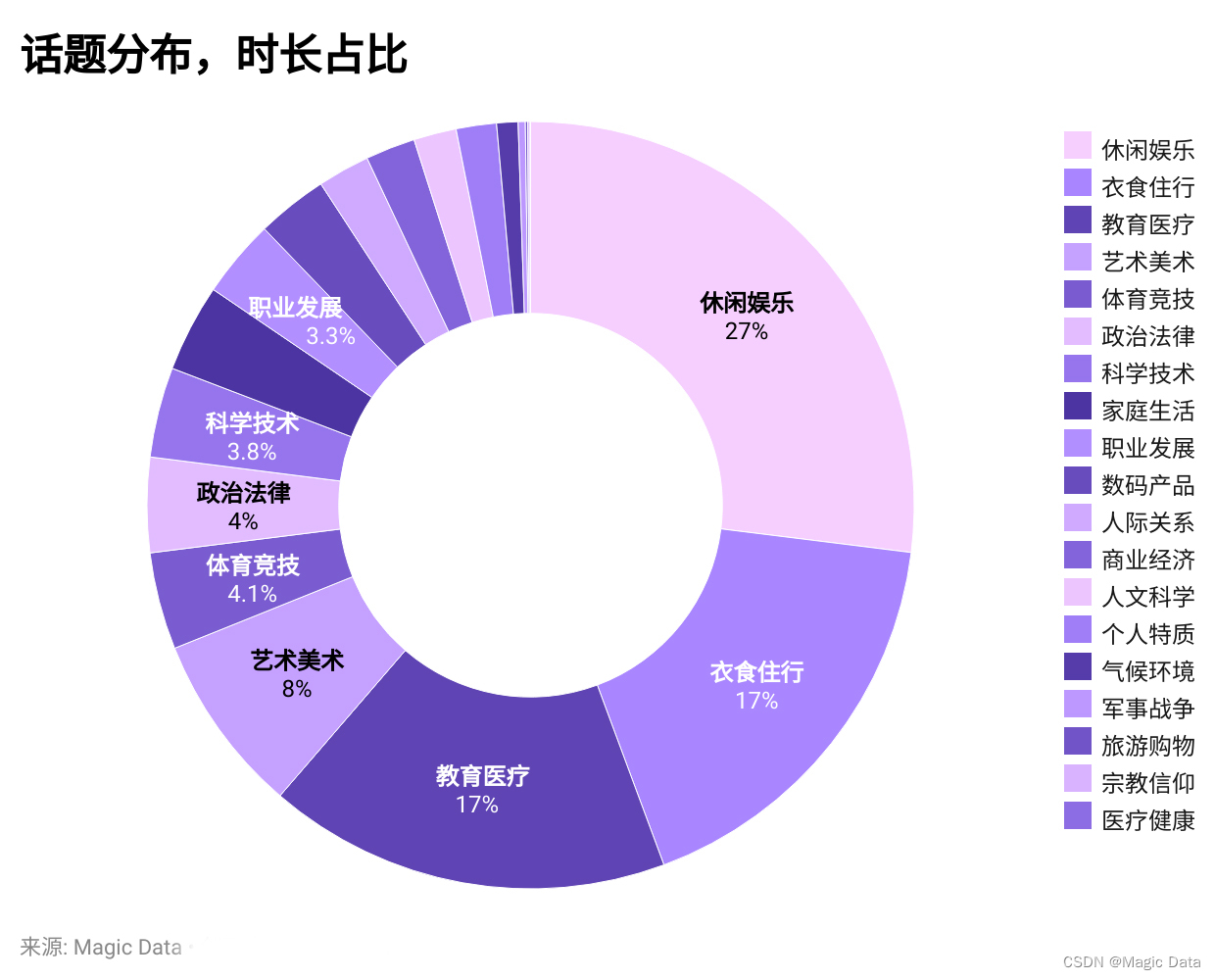
此数据集采集自来自中国30个省份的说话人,地域分布均衡,涵盖18-60岁的说话人,囊括了普遍的说话风格与特点;同时内容覆盖商业经济、数码产品等20类话题,具有极高的话题丰富度。


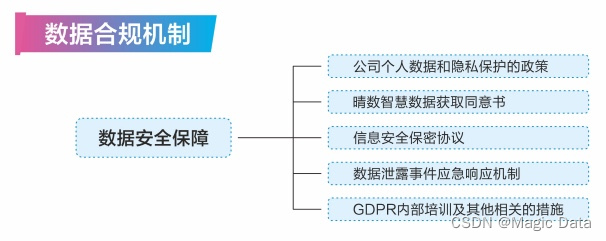
数据合规
晴数智慧高纯净音自然多轮对话数据集处理过程遵循完整的晴数智慧数据合规保障机制,在整个数据生命周期中,保证数据的流转可溯性,确保数据版权完整。
文章来源:https://blog.csdn.net/weixin_47718443/article/details/135556578
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MACD因子分析结果
- SpringBoot多环境配置以及热部署
- PDF控件Spire.PDF for .NET【安全】演示:从 PDF 中删除数字签名字段
- c++图像像素计算
- ElasticSearch--基本操作
- 面向对象进阶-多态
- 前端表格使用vxe-table进行渲染,使用el-select进行选择合适的条件查询,且给el-select默认赋值及使用i18n进行翻译
- 基于Java+SSM+Mysql的少儿编程教育网站系统[文档+讲解+调试等]
- 朋友圈,如何快速实现自动发布?
- 【Python期末】动态爬取电影Top250数据可视化处理(有GUI界面/无数据库)