Hugging Face 介绍 & 快速搭建模型服务
Hugging Face 介绍 & 快速搭建模型服务
模型分类网站
你可以在这个网站找到各种类型的模型
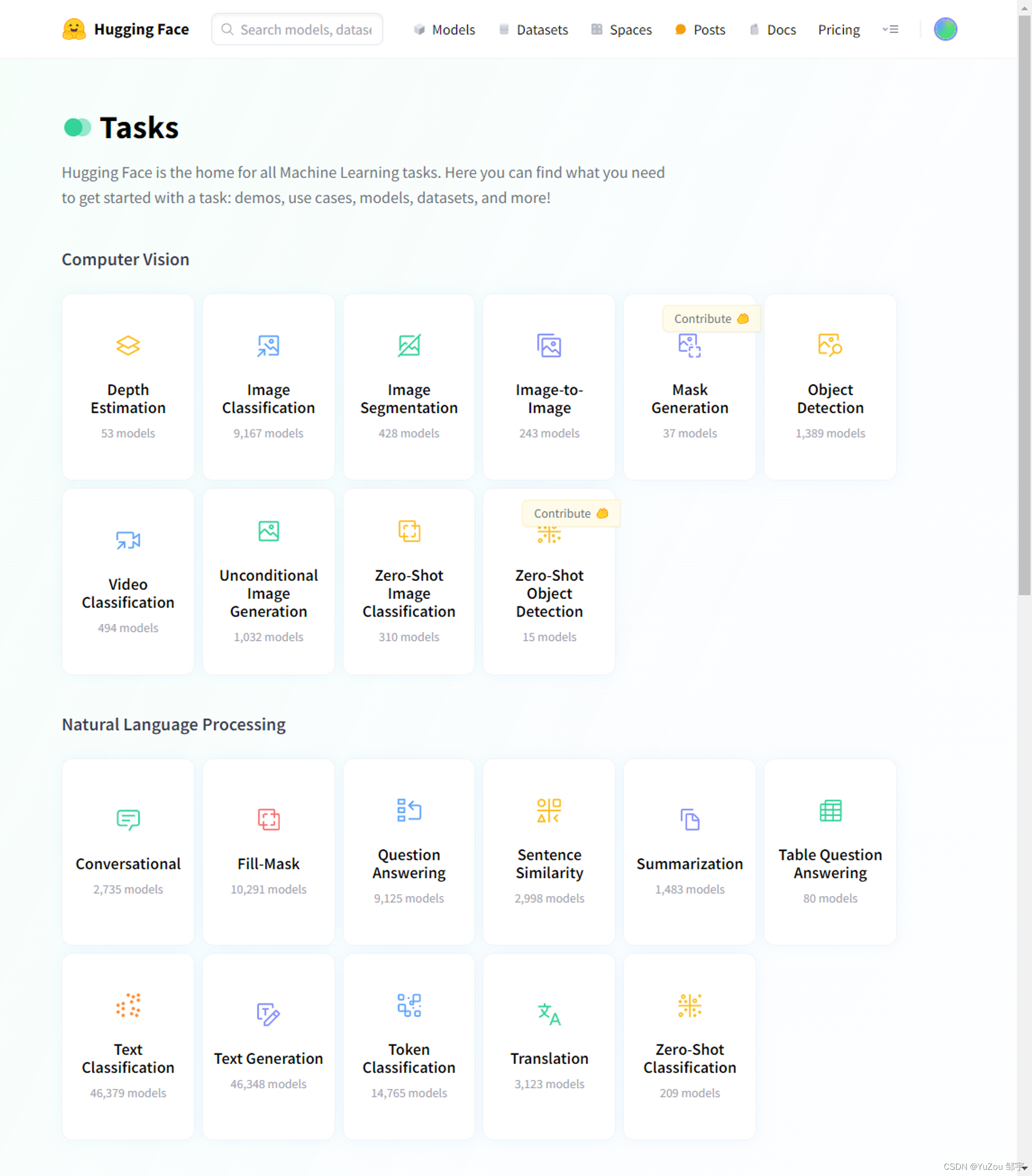
以Image To Text这个类别为例,其主要由以下几个部分构成:
- 类别介绍
- 模型尝试
- 模型列表
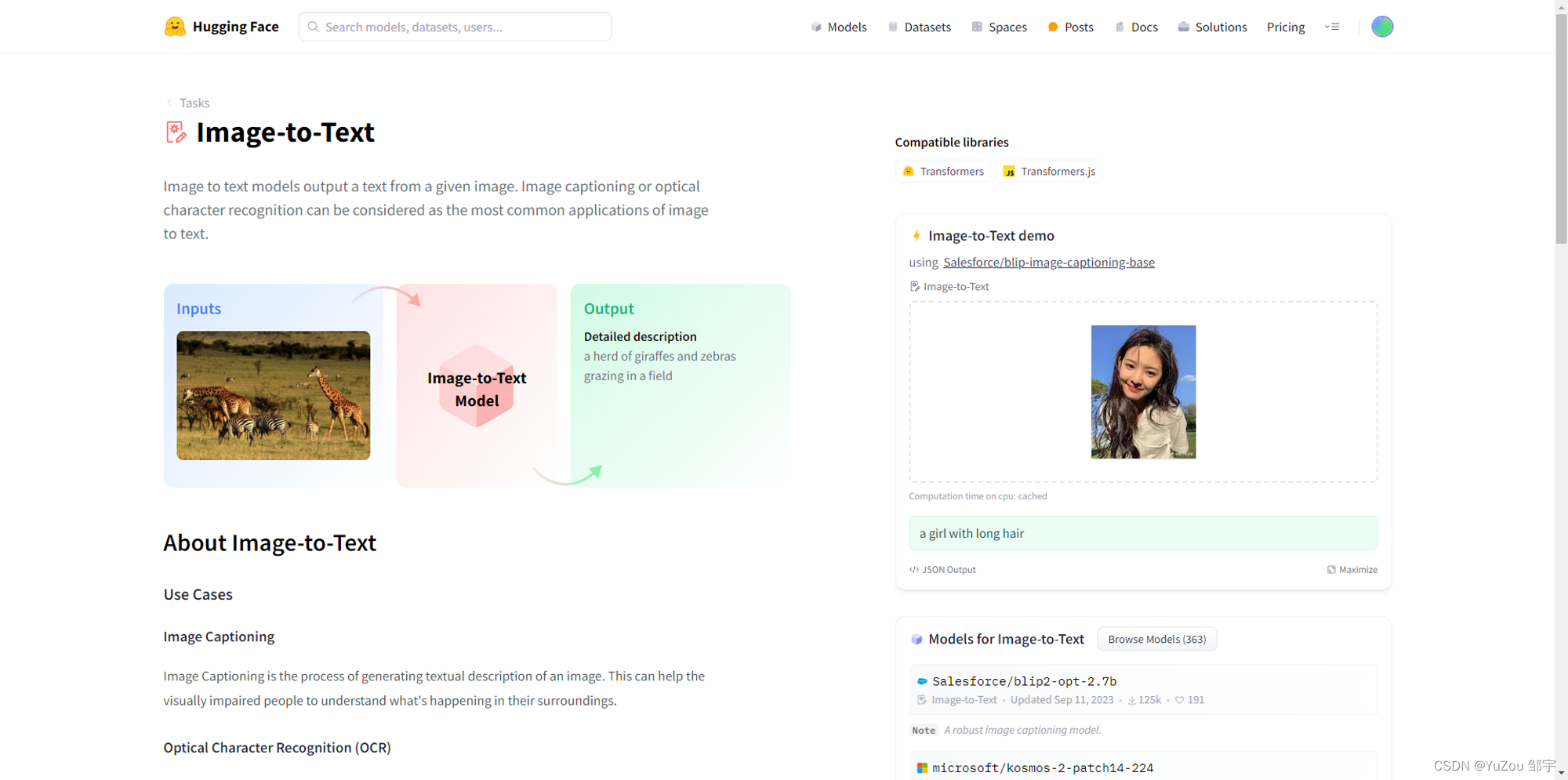
如何下载模型
huggingface-cli
[huggingface-cli](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli) 隶属于 huggingface_hub 库,不仅可以下载模型、数据,还可以可以登录huggingface、上传模型、数据等。
安装依赖
pip install -U huggingface_hub
注意:huggingface_hub 依赖于 Python>=3.8,此外需要安装 0.17.0 及以上的版本,推荐0.19.0+。
基本用法
huggingface-cli download --resume-download Salesforce/blip2-opt-2.7b --local-dir D:\HuggingFace\hub\blip2-opt-2.7b
这个命令是使用Hugging Face的命令行工具(huggingface-cli)来下载一个模型。让我一步一步详细介绍:
huggingface-cli: 这是Hugging Face提供的一个命令行工具,用于管理和下载模型、数据集等NLP资源。download: 这个命令告诉huggingface-cli你想要下载一个资源。-resume-download: 这个标志允许你在下载被中断后继续下载,如果之前的下载尚未完成,这个标志会尝试从之前下载的位置继续下载。Salesforce/blip2-opt-2.7b: 这是你要下载的模型的名称。在这种情况下,你正在下载一个由Salesforce发布的名为"blip2-opt-2.7b"的模型。这个模型可能用于自然语言处理(NLP)任务。-local-dir D:\HuggingFace\hub\blip2-opt-2.7b: 这个标志指定了下载后资源的本地目录。在这里,你将下载的模型资源保存到了本地目录"D:\HuggingFace\hub\blip2-opt-2.7b"中。
使用国内镜像

设置方法
Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"
Linux
export HF_ENDPOINT="https://hf-mirror.com"
Python
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
注意os.environ得在import huggingface库相关语句之前执行。
如何应用模型
直接在代码中应用模型的本地路径即可,这里需要注意的是,下载模型的时候,要把huggingface上的所有文件全部下载下来。
参考代码如下:
import torch
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import gradio as gr
# 检查CUDA是否可用并设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
# 加载模型
local_model_path = "D:/HuggingFace/hub/models--Salesforce--blip2-opt-2.7b"
processor = Blip2Processor.from_pretrained(local_model_path)
model = Blip2ForConditionalGeneration.from_pretrained(local_model_path).to(device)
# 定义推理函数
def predict(image, question):
# 处理输入图像
image = Image.fromarray(image).convert('RGB')
inputs = processor(image, question, return_tensors="pt").to(device)
# 进行模型推理
out = model.generate(**inputs)
answer = processor.decode(out[0], skip_special_tokens=True).strip()
# 返回答案
return answer
# 创建Gradio界面
iface = gr.Interface(
fn=predict,
inputs=[gr.Image(type="numpy"), gr.Textbox(label="Question")], # 更新了这一行
outputs="text",
title="Image Question Answering",
description="Upload an image and ask a question about it."
)
# 启动Gradio应用
iface.launch()
这里我使用了Gradio做前端展示
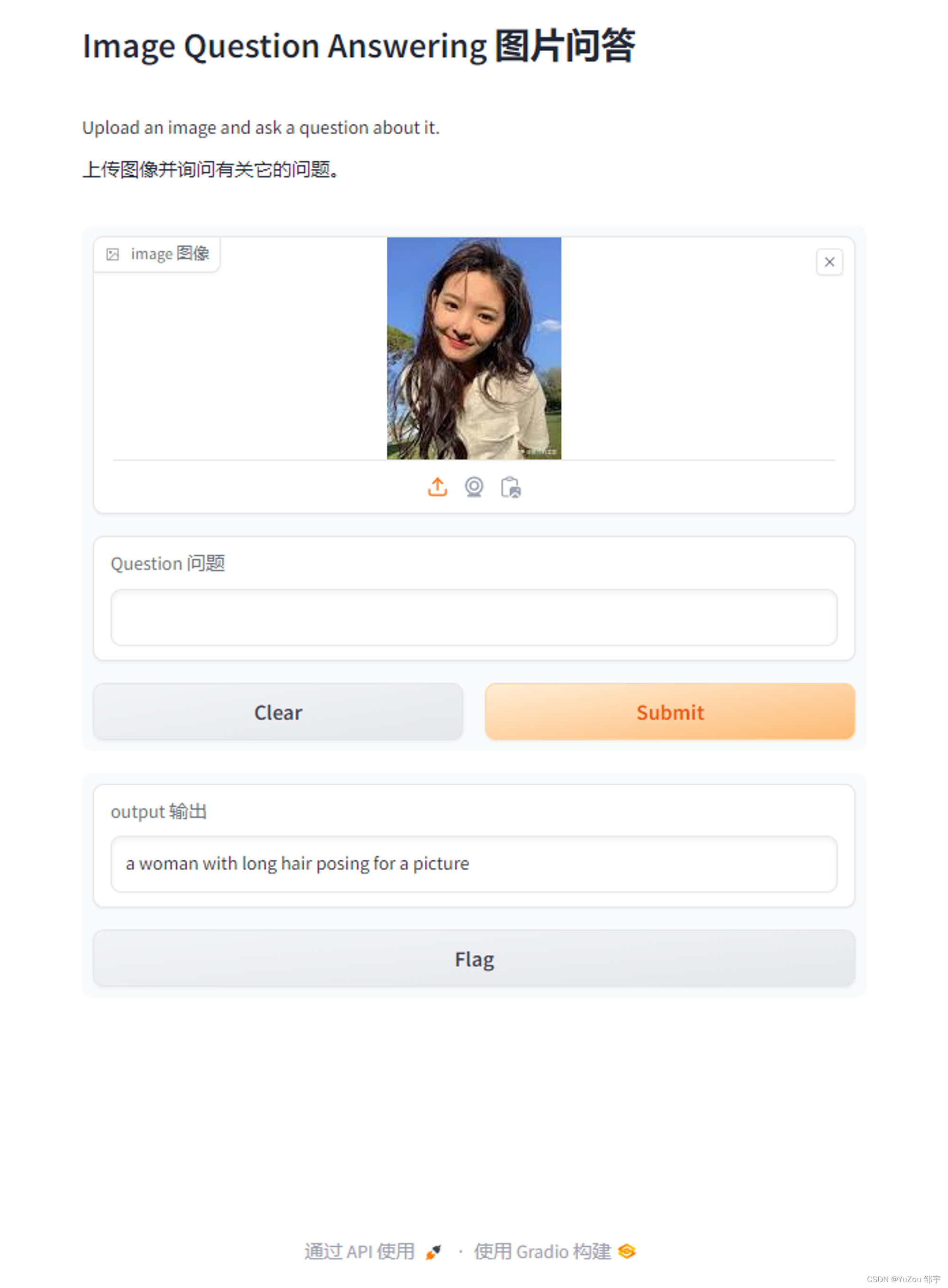
如上。
但是每次启动脚本的时候,都会出现一个问题,就是加载模型需要很久很久很久……
部署和使用 Transformer 模型服务:使用 Flask 和 FastAPI
使用 Transformers 加载大型模型确实可能需要一些时间,尤其是在首次启动时。这是因为模型通常很大,需要从远程服务器下载到本地,之后还要在本地进行初始化。为了优化这一过程,你可以考虑以下几个策略:
- 使用持久化存储:在首次下载模型后,可以将其保存在本地硬盘上。这样,在之后的使用中就可以直接从本地加载模型,而无需再次从远程服务器下载。
- 使用 Flask 或 FastAPI:这两种框架都可以用来创建一个服务,该服务在启动时加载模型,并在之后的请求中重用已加载的模型。这意味着模型只需在服务启动时加载一次。
- Flask:Flask 是一个轻量级的 Web 应用框架。它简单易用,适合小到中型项目,以及在单个或少数几个服务器上运行的应用程序。
- FastAPI:FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API。它基于标准 Python 类型提示,支持异步编程,通常适合需要高性能和并发处理的场景。
选择 Flask 还是 FastAPI 取决于你的具体需求。如果你需要快速、简单地搭建一个 API,且不需要处理大量并发请求,Flask 可能是更好的选择。如果你的应用需要处理大量并发请求,或者你希望利用 Python 的异步特性,那么 FastAPI 可能更合适。
服务端编写
我会提供一个简单的例子,展示如何使用 Flask 或 FastAPI 来部署一个模型服务。这个服务将在启动时加载模型,并在之后的请求中重用已加载的模型。
使用 Flask
先来看一个 Flask 的例子。假设我们正在部署一个 Transformer 模型(例如 BERT)来执行某种任务(比如文本分类)。
from flask import Flask, request, jsonify
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
app = Flask(__name__)
# 加载模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
@app.route('/predict', methods=['POST'])
def predict():
# 解析请求数据
data = request.json
text = data['text']
# 分词和模型推理
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
prediction = model(**inputs)
# 提取并返回预测结果
predicted_class = torch.argmax(prediction.logits).item()
return jsonify({'class': predicted_class})
if __name__ == '__main__':
app.run(debug=True)
这个 Flask 应用在启动时会加载模型和分词器。当接收到 POST 请求 /predict 时,它会对提供的文本进行预测,并返回预测的类别。
使用 FastAPI
下面是一个使用 FastAPI 的例子。FastAPI 通常提供更快的性能和自动生成的 API 文档。
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
app = FastAPI()
# 加载模型和分词器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
class Item(BaseModel):
text: str
@app.post("/predict/")
async def predict(item: Item):
# 分词和模型推理
inputs = tokenizer(item.text, return_tensors='pt')
with torch.no_grad():
prediction = model(**inputs)
# 提取并返回预测结果
predicted_class = torch.argmax(prediction.logits).item()
return {"class": predicted_class}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
这个 FastAPI 应用与 Flask 示例类似,它在启动时加载模型和分词器,并在接收到 POST 请求 /predict/ 时处理预测。
注释
在这两个例子中,都使用了 transformers 库来加载预训练的 BERT 模型及其分词器。这些模型在应用启动时加载,并在处理请求时重复使用。请求中的文本数据经过分词器处理后输入到模型中,模型的输出用于生成预测响应。
请注意,这些示例代码假设你已经安装了所需的依赖项(如 flask, fastapi, transformers 等),并且你的环境能够运行这些模型。此外,这些示例仅作为基本演示,可能需要根据你的具体应用场景进行调整和优化。
客户端调用
接下来,我将解释如何从客户端调用刚刚创建的 Flask 或 FastAPI 服务来获取模型预测。这通常涉及向服务发送一个包含所需数据的 HTTP 请求,并接收返回的响应。
调用 Flask 服务
假设 Flask 服务正在本地运行,并且监听的端口是默认的 5000 端口。你可以使用 Python 的 requests 库来调用该服务。下面是一个例子:
import requests
# Flask 服务的 URL
url = "http://127.0.0.1:5000/predict"
# 准备要预测的数据
data = {"text": "Your text here"}
# 发送 POST 请求到 Flask 服务
response = requests.post(url, json=data)
# 打印响应
print(response.json())
在这个例子中,我们首先导入 requests 库,然后指定 Flask 服务的 URL。接着,我们创建一个字典 data,包含我们想要模型进行预测的文本。之后,我们使用 requests.post 方法向 Flask 服务发送 POST 请求,并将 data 作为 JSON 数据发送。最后,我们打印出从服务接收到的响应。
调用 FastAPI 服务
假设 FastAPI 服务正在本地运行,并且监听的端口是 8000 端口。调用方法与 Flask 类似:
import requests
# FastAPI 服务的 URL
url = "http://127.0.0.1:8000/predict/"
# 准备要预测的数据
data = {"text": "Your text here"}
# 发送 POST 请求到 FastAPI 服务
response = requests.post(url, json=data)
# 打印响应
print(response.json())
这个例子与 Flask 的例子非常相似。主要区别在于服务的 URL 可能不同,因为它们运行在不同的端口上。
注意事项
- 确保 Flask 或 FastAPI 服务正在运行,否则你的请求将失败。
- 如果服务部署在不同的主机或端口上,请相应地更改 URL。
- 这些示例代码假设你已经安装了
requests库。如果没有安装,可以通过运行pip install requests来安装它。 - 这些调用示例仅用于演示基本的服务调用,可能需要根据实际情况进行调整和扩展。
通过使用 Flask 或 FastAPI,我们可以有效地部署 Transformer 模型作为服务,并通过简单的 API 调用进行交互。这种方法在处理大型模型或需要频繁重用模型的情况下特别有用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!