关于爬虫爬取网页时遇到的乱码问题的解决方案。
发布时间:2024年01月24日
前言
最近,我像爬取一下三国演义这本书籍的全部内容。
网站的网址为:https://www.shicimingju.com/book/sanguoyanyi.html
但是我爬取出来的结果是这样的
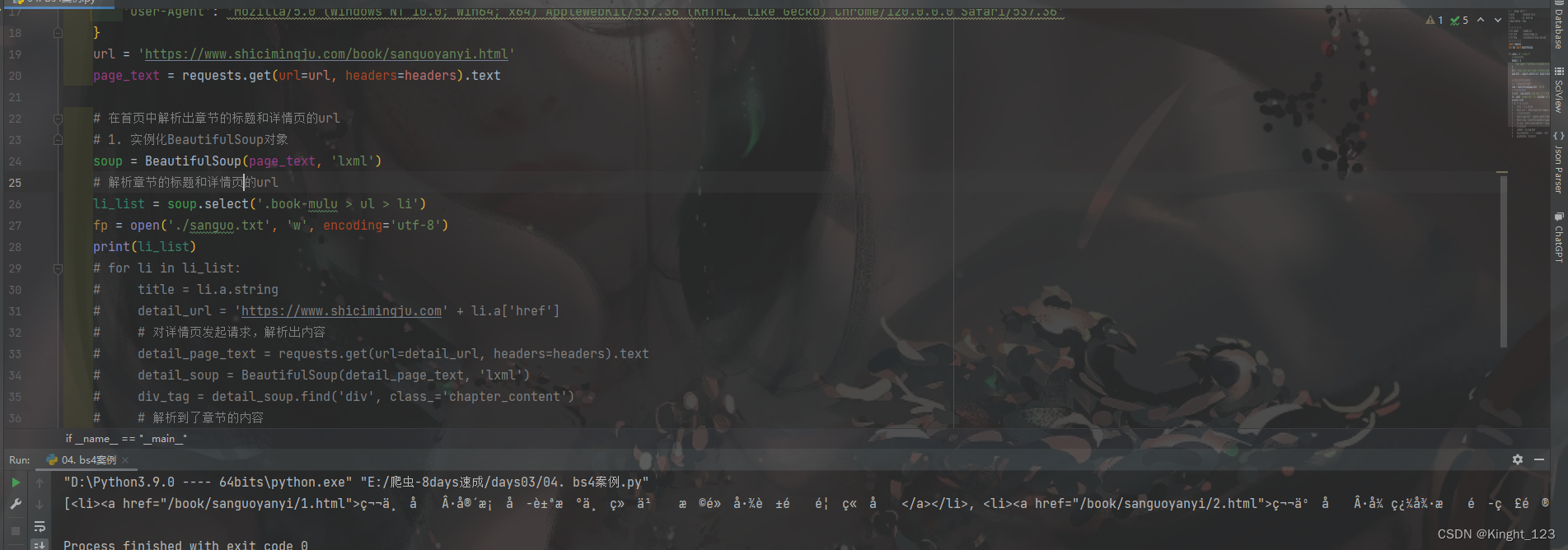
会遇到乱码。
经过我多方面的调试发现,就是网页的编码和我pycharm的编码不一致导致的。

网页的编码是ISO-8859-1,而pycharm的编码是‘utf-8’
解决措施
# encode编码,将ISO-8859-1编成unicode
page_text = page_text.encode('ISO-8859-1')
# decode解码,将unicode解码成utf-8
page_text = page_text.decode('utf-8')
通过重新编码和解码来达到网页和编译器的编码一致。
修改前的代码:
# -*- coding: utf-8 -*-
# @Time : 2024/1/24 20:16
# @File : 04. bs4案例.py
# @Description : None
# ----------------------------------------------
# ☆ ☆ ☆ ☆ ☆ ☆ ☆
# >>> Author : Kinght_123
# >>> Mail : 1304662247@qq.com
# >>> Blog : tim1304662247.blog.csdn.net
# ☆ ☆ ☆ ☆ ☆ ☆ ☆
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# 对首页的页面进行数据爬取
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url, headers=headers).text
# 在首页中解析出章节的标题和详情页的url
# 1. 实例化BeautifulSoup对象
soup = BeautifulSoup(page_text, 'lxml')
# 解析章节的标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt', 'w', encoding='utf-8')
print(li_list)
for li in li_list:
title = li.a.string
detail_url = 'https://www.shicimingju.com' + li.a['href']
# 对详情页发起请求,解析出内容
detail_page_text = requests.get(url=detail_url, headers=headers).text
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
div_tag = detail_soup.find('div', class_='chapter_content')
# 解析到了章节的内容
content = div_tag.text
fp.write(title + ':' + content + '\n')
print(title, '爬取成功!!!')
修改后的代码:
# -*- coding: utf-8 -*-
# @Time : 2024/1/24 20:16
# @File : 04. bs4案例.py
# @Description : None
# ----------------------------------------------
# ☆ ☆ ☆ ☆ ☆ ☆ ☆
# >>> Author : Kinght_123
# >>> Mail : 1304662247@qq.com
# >>> Blog : tim1304662247.blog.csdn.net
# ☆ ☆ ☆ ☆ ☆ ☆ ☆
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
# 对首页的页面进行数据爬取
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url, headers=headers).text
# encode编码,将ISO-8859-1编成unicode
page_text = page_text.encode('ISO-8859-1')
# decode解码,将unicode解码成utf-8
page_text = page_text.decode('utf-8')
# 在首页中解析出章节的标题和详情页的url
# 1. 实例化BeautifulSoup对象
soup = BeautifulSoup(page_text, 'lxml')
# 解析章节的标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt', 'w', encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'https://www.shicimingju.com' + li.a['href']
# 对详情页发起请求,解析出内容
detail_page_text = requests.get(url=detail_url, headers=headers).text
detail_soup = BeautifulSoup(detail_page_text, 'lxml')
div_tag = detail_soup.find('div', class_='chapter_content')
# 解析到了章节的内容
content = div_tag.text
fp.write(title + ':' + content + '\n')
print(title, '爬取成功!!!')
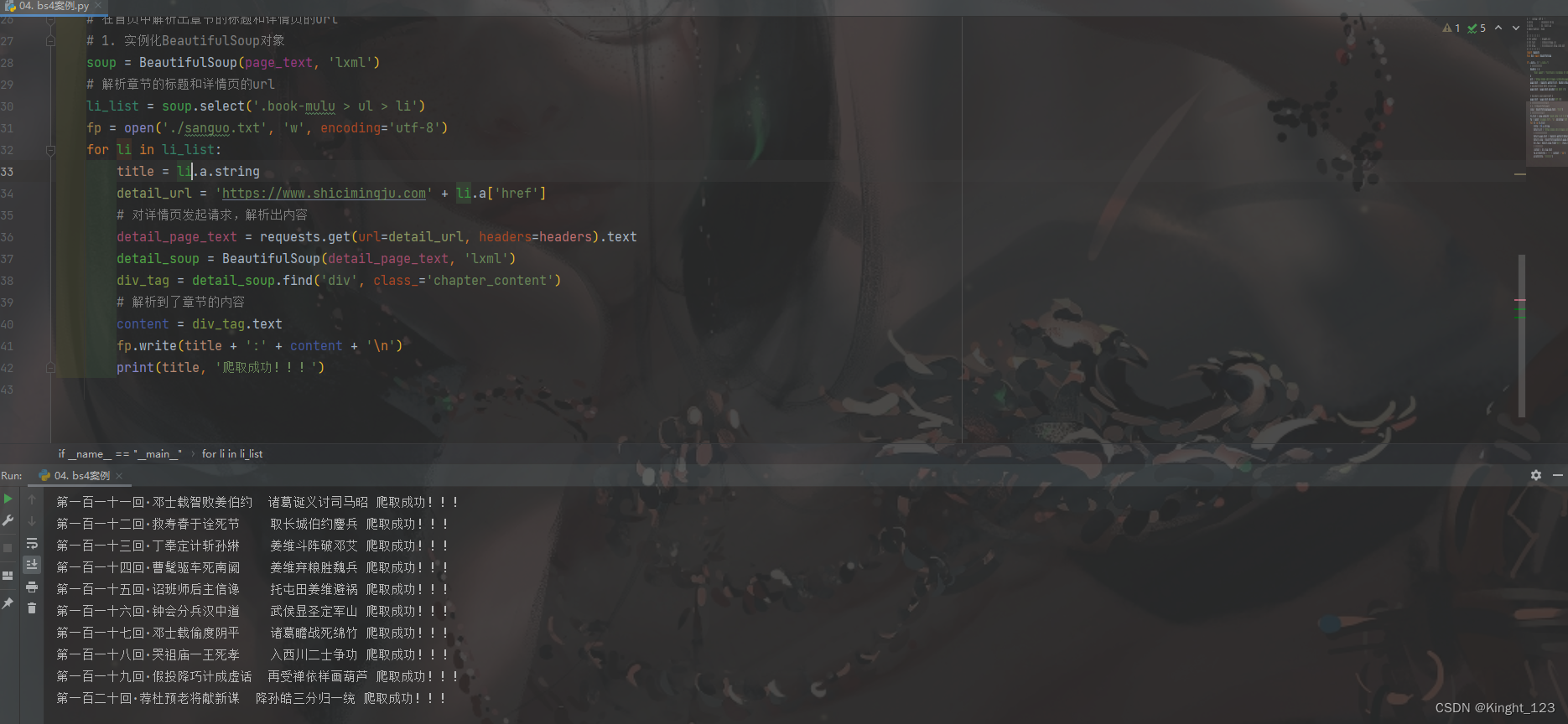
最终显示的结果是这样的:

文章来源:https://blog.csdn.net/Kinght_123/article/details/135831207
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CRM的request管理笔记
- 代码随想录算法训练营第五十七天 _ 动态规划_647.回文子串、5. 最长回文子串、516.最长回文子序列。
- 案例103:基于微信小程序的移动网赚项目设计与实现
- SpringCloudAlibaba系列之Nacos实战
- Linux操作系统—进程和服务管理
- 《现代操作系统》第十一章习题答案
- MaxKey 单点登录认证系统——集成CAS应用
- 基于Spring Cloud + Spring Boot的企业电子招标采购系统源码
- K8S学习指南(10)-k8s中为pod分配CPU和内存资源
- OpenCV图像处理——遍历图像像素的几种方式比对