自学Python,需要注意哪些?
为什么要学习Python?
在学习Python之前,你不要担心自己没基础或“脑子笨”,我始终认为,只要你想学并为之努力,就能学好,就能用Python去做很多事情。在这个喧嚣的时代,很多技术或概念会不断兴起,我希望你能沉下心来去学习,不要急于求成,一步一个脚印。当你把某个技术学好、学精后,还是能做一些事情的,甚至能找到喜欢的工作或完成实践项目。
程序语言没有最好,只有最适合。作为一名初学者,我非常推荐你学习Python,为啥?一方面是因为它具有语法清晰、代码友好、易读性高的特点,同时Python拥有强大的第三方库函数,包括网络爬取、数据分析、可视化、人工智能等;另一方面Python既是一门解释性编程语言,又是面向对象的语言,其操作性和可移植性高,被广泛应用于数据挖掘、信息采集、人工智能、网络安全、自动化测试等领域。甚至,很多小学生、高中课程和计算机二级也都陆续增加了Python。
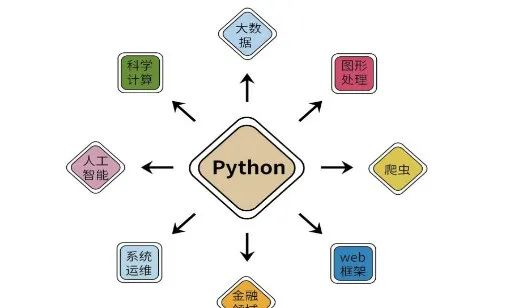
Python优势
Python最大的优势在于效率。有时候程序员或科研工作者的效率比机器的效率更重要,对于很多复杂性的功能,使用更加清晰的语言能给程序减少更多的负担,从而大大增强程序的质量,其易学性和扩展性也能让新手很快上手。虽然Python底层运行速度要比C语言慢,但Python清晰的结构能解放程序员的时间,同时很方便的和其他编程语言代码(如C语言)融合在一起。
所以,从来没有一种编程语言可以像Python这样同时扎根在这么多领域,并且Python支持跨平台操作,也支持开源,拥有强大的第三方库。尤其随着人工智能的持续火热,Python在IEEE近几年发布的最热门语言中多次排名第一,越来越多的程序爱好者、科技关注者也都开始学习Python。
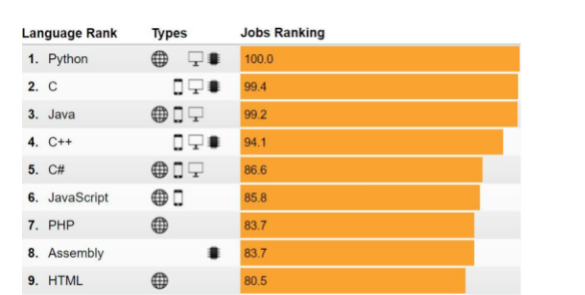
编程环境配置
Python是一种解释性语言,它使用解释器来解释和执行代码,这对用户来说省去了C或C++之类语言的编译步骤,直接从源代码即可运行,因此更容易编写和调试。工欲善其事,必先利其器。在学习Python编程之前,先让我们安装好相应的工具并对编程环境进行设置。
首先进入Python官方下载频道https://www.python.org/downloads,点击“Download Python 3.11.2”按钮进入下载页面(此数字会随着版本的升级而改变)。找到适合自己系统的下载链接,比如笔者为Windows的64位系统,所以选择下载了“Windows installer (64-bit)”。双击下载所得的EXE可执行文件启动Python安装向导。
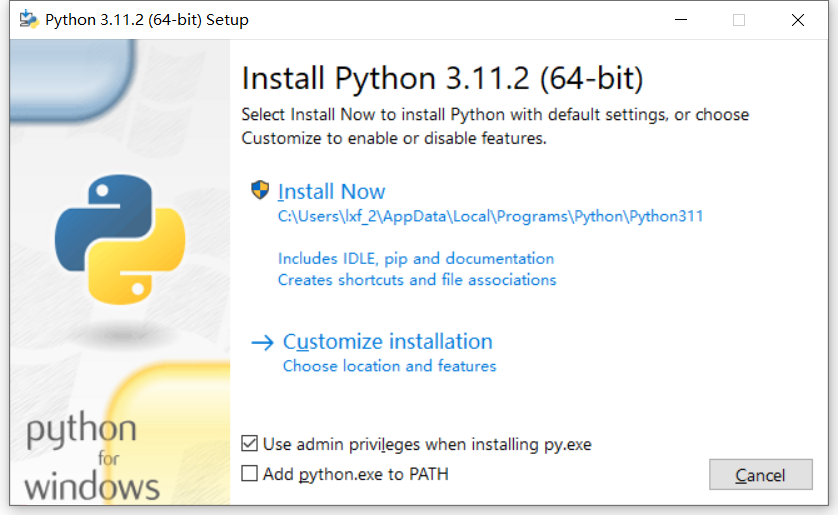
勾选“Add python.exe to PATH”项,这样就不用后期手动将Python程序添加到系统路径中了。点击“Install Now”即可自动安装。如果不希望安装到默认的C盘,可以点击“Customize installation”自定义安装项,根据向导提示一步步安装。
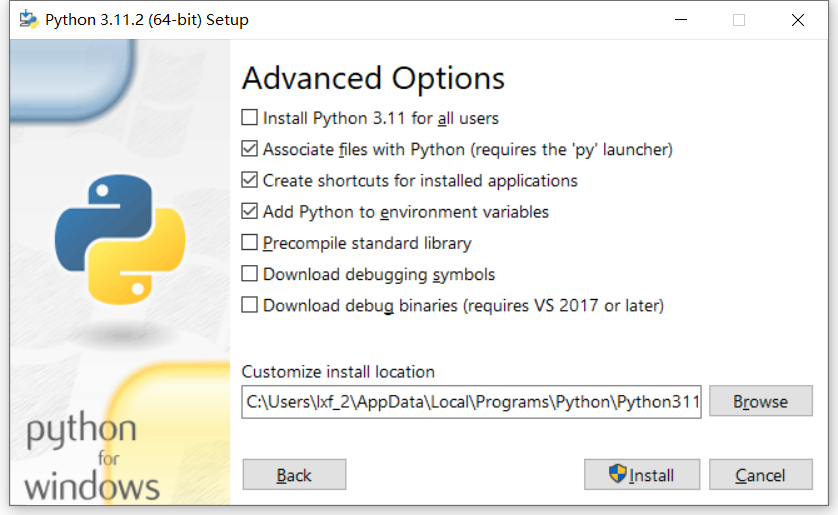
作为初学者选择默认安装选项即可。安装成功后,对于Windows系统将会有一个“Disable path length limit(禁用路径长度限制)”的提示,这是因为Windows系统能够处理的文件路径长度有一定的限制。点击禁用这一限制可以避免处理长文件路径时出现的调试问题,不过这也可能导致与旧版本Windows 10的兼容性问题。对于我们初学者来说可以暂时跳过此选项,因为以后有需要时还可以修改注册表来解决。
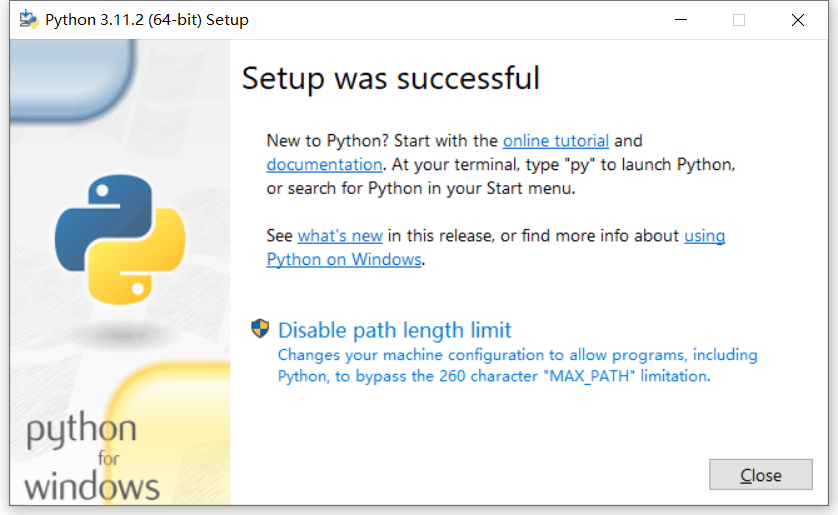
点击“Close”按钮关闭安装向导。现在我们测试Python是否安装成功。按Win+R键调出运行对话框,输入“cmd”后按回车键打开命令提示符窗口,然后输入“python”并按回车,如果能够显示出Python版本等信息内容,并且提示符变成了“>>>”,则表示安装成功了。此时可输入一行测试代码:
print("嗨,欢迎来到Python世界!")
按回车键执行,即可得到“嗨,欢迎来到Python世界!”的显示信息。几乎每种编程语言教程中都会展示一下“hello, world!”程序,虽然很俗套,但不得不说Python的实现是如此的简单。紧接着执行代码“exit()”退出Python环境,完成此一阶段的测试。
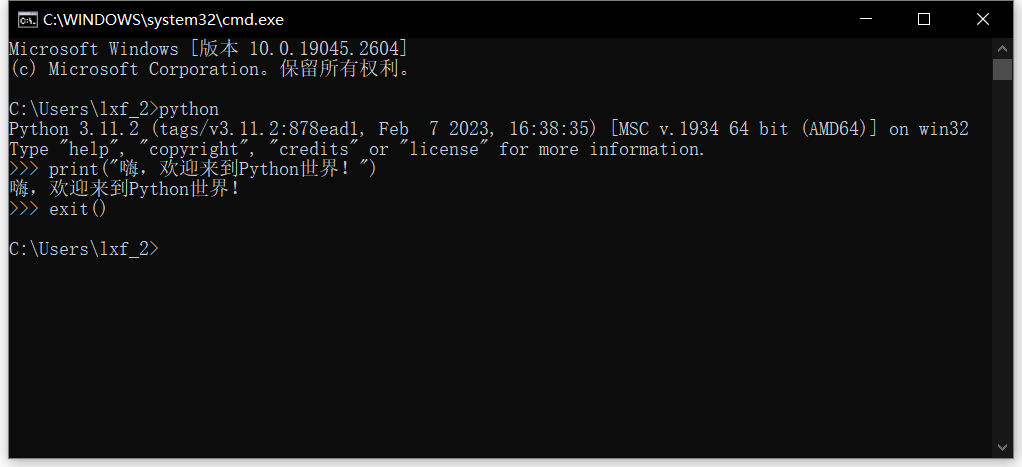
命令提示符的界面过于简陋,我们可以试试Python自带的IDLE交互式开发环境。点击系统“开始”按钮,在开始菜单顶部的最近添加中就可以看到“IDLE(Pyton 3.11 64-bit)”程序了,点击即可打开。
IDLE通过不同的颜色区分代码及执行结果,清晰明了。尤其方便的是,当我们输入某个函数时,它会智能显示参数提示,辅助我们输入代码,非常方便。
PyCharm 使用
IDE是Integrated Development Environment的缩写,意为集成开发环境,主要用来辅助程序开发。Python并不一定需要IDE,因为它可以在任何文本编辑器中编写并从命令行运行。但是IDE可以提供许多辅助功能,例如代码调试、智能完成和语法高亮显示等。另外,IDE还可以提供重构、代码导航和项目管理等工具,这些工具可以帮助我们更快、更轻松地编写Python代码,并且可以更轻松地调试和维护代码。
Python开发人员有多种IDE可用,相对来说PyCharm是个非常不错的选择,它可以让Python开发过程变得更加轻松和高效。值得称道的是,PyCharm提供一个强大的社区版本,可以免费使用,并且可以在网上获得免费支持。
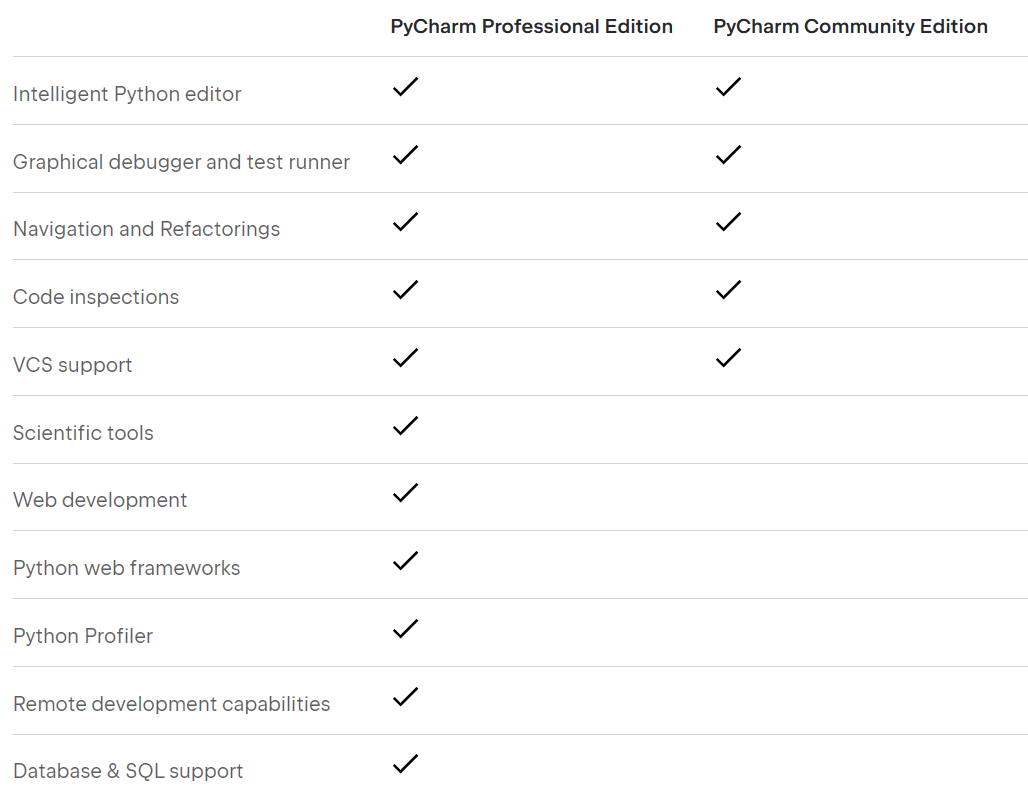
首先进入PyCharm主页https://www.jetbrains.com/pycharm,点击“DOWNLOAD”按钮进入下载频道,在“Windows”选项卡下可以看到“Professional(专业版)”和“Community(社区版)”两种版本,其中社区版是免费的,点击其下的“Download”按钮下载即可。比较而言,社区版缺少对科学工具、网站开发、Web框架、远程开发、数据库等的支持,不过对于一个初学者来说,这些影响不大。
学习大纲
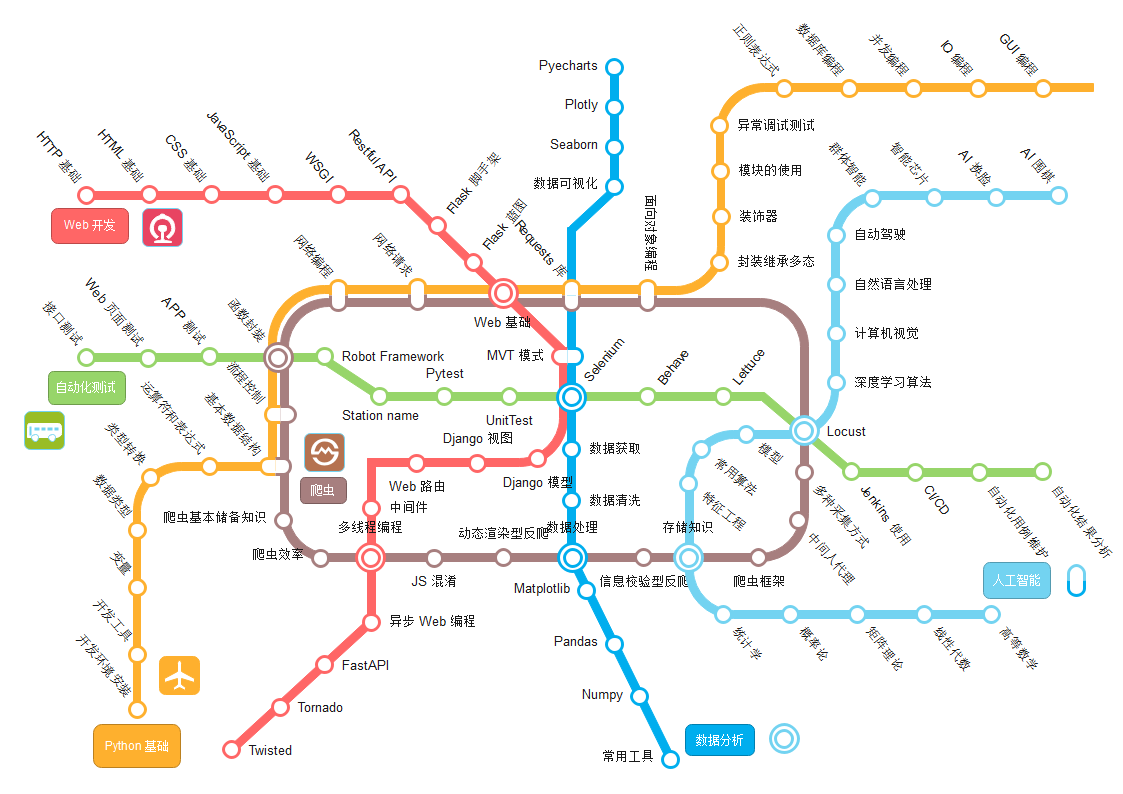
基本语法
对于底层基础,肯定是掌握得越多、越牢固越好~
- 环境搭建
- Python安装
- 开发工具 - PyCharm,VS Code,Jupyter Notebook
- 变量
- 定义变量
- 命名规则
- 基本数据类型
- 类型转换
- 运算符和表达式
- 基本数据结构
- 字符串
- 列表
- 字典
- 集合
- 元组
- 流程控制
- 条件
- 循环
- 函数
- 调用函数
- 定义函数
- 函数参数
- lambda 函数
- 作用域
- 重要内置函数
- 函数式编程
- 面向对象编程
- 类和对象
- 访问限制
- 装饰器
- 封装
- 继承
- 多态
- 类方法
- 实例方法
- 静态方法
- 反射
- 模块
- 使用模块
- 安装模块
- 常用模块
- 异常调试测试
- 异常捕获
- try…else…finally 结构
- 自定义异常
- 调试
- 单元测试
- 文档测试
- 进阶知识
- 正则表达式
- 数据库编程知识
- 并发编程
- 网络编程
- IO 编程
- 图形界面
Web 开发
- Web 基础
- HTTP 基础
- HTML 基础
- CSS 基础
- JavaScript 基础
- WSGI
- Restful API
- Flask
- 脚手架
- 蓝图
- Django
- MVT 模式
- 模板
- 模型
- 视图
- 路由
- 中间件
- FastAPI
爬虫
- 基础知识
- 爬虫概念
- 合法性
- 注意点
- 数据采集与解析
- HTTP 基础知识
- Web 基础知识
- Socket 知识
- Requets 库
- 正则表达式
- Xpath
- 多种采集方式
- 同步采集
- 异步采集
- Selenium
- AJAX
- Pyppeteer
- 中间人代理
- Charles
- Mitmproxy
- HttpCanary
- 爬虫框架
- Scrapy
- Crawley
- Selenium
- PySpider
- 反爬虫
- 信息校验型
- 动态渲染型
- 文本混淆型
- 特征识别型
- 验证码
- JS 混淆
- 多终端爬虫
- Web 采集
- APP 采集
- 小程序采集
- 数据去重
- 断点采集
- 增量采集
- 存储知识
- 本地文件
- MySQL
- Redis
- MongoDB
- Pandas
自动化运维
- Linux 知识
- shell 知识
- 运维相关库
- ansible
- Paramiko
- psutil
- dnspython
- IPy
- 常用运维工具
自动化测试
- 测试基础
- 接口测试
- Web 页面测试
- App 测试
- Selenium
- Pytest
- UnitTest
- Robot Framework
- Behave
- Locust
- Lettuce
数据分析
- 常用工具
- Jupyter Notebook
- Conda
- 常用类库
- Numpy
- Pandas
- Matplotlib
- 数据处理
- 数据获取
- 数据清洗
- 数据合并/连接/聚合
- 数据可视化
- Seaborn
- Plotly
- Pyecharts
人工智能
- 数学知识
- 高等数学
- 线性代数
- 矩阵理论
- 概率论
- 统计学
- 机器学习
- 机器学习流程
- 特征工工程
- 模型
- 常用算法
- 常用库
- 深度学习
- 算法
- 重点技术分支
- 计算机视觉
- 自然语言处理
- 自动驾驶
- 群体智能
- 智能芯片
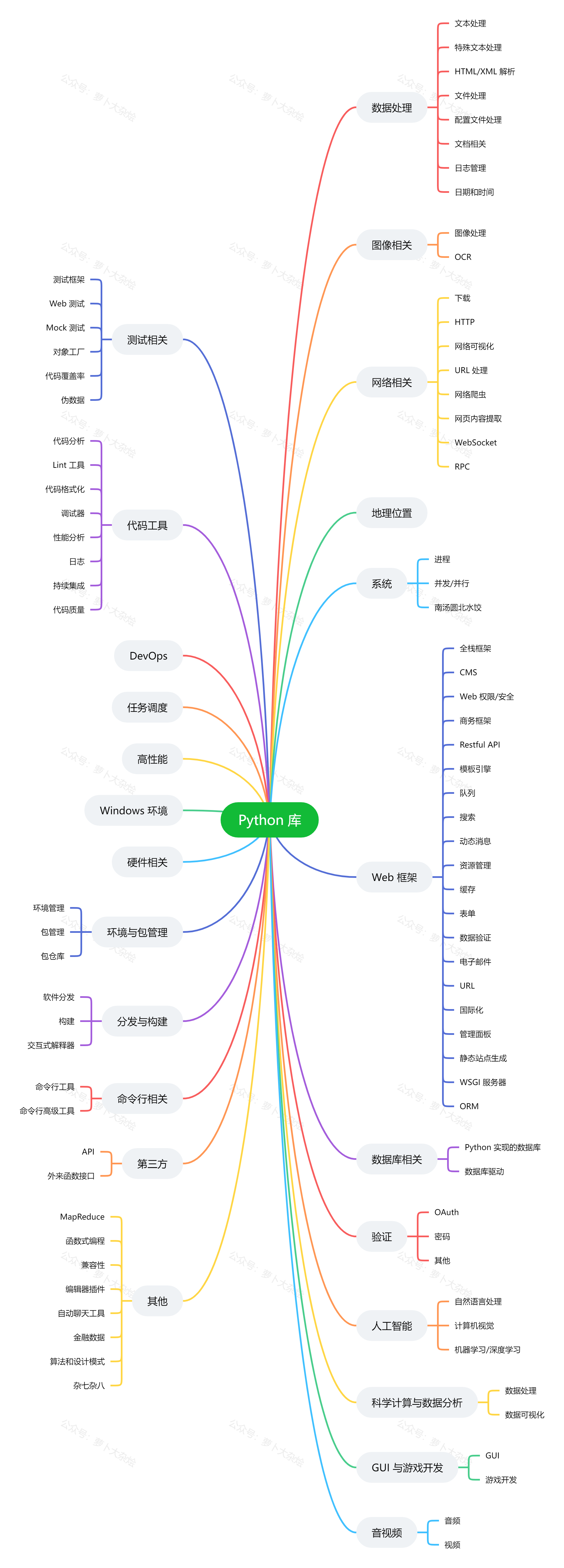
常用类库
Python 的各种第三方类库是非常丰富的,这也是 Python 能够如此流行的一大原因,基本我们要做什么东西都能找到对应的类库,直接看文档用就行了,大大提高开发效率!
类库太多了,直接看图片吧
高级脚本
每天我们都会面临许多需要高级编码的编程挑战。你不能用简单的 Python 基本语法来解决这些问题。下面分享 13 个高级 Python 脚本,它们可以成为你项目中的便捷工具。
1.使用 Python 进行速度测试
这个高级脚本帮助你使用 Python 测试你的 Internet 速度。只需安装速度测试模块并运行以下代码。
# pip install pyspeedtest
# pip install speedtest
# pip install speedtest-cli
#method 1
import speedtest
speedTest = speedtest.Speedtest()
print(speedTest.get_best_server())
#Check download speed
print(speedTest.download())
#Check upload speed
print(speedTest.upload())
# Method 2
import pyspeedtest
st = pyspeedtest.SpeedTest()
st.ping()
st.download()
st.upload()
2.在谷歌上搜索
你可以从 Google 搜索引擎中提取重定向 URL,安装以下提及模块并遵循代码。
# pip install google
from googlesearch import search
query = "Medium.com"
for url in search(query):
print(url)
3.制作网络机器人
该脚本将帮助你使用 Python 自动化网站。你可以构建一个可控制任何网站的网络机器人。查看下面的代码,这个脚本在网络抓取和网络自动化中很方便。
# pip install selenium
import time
from selenium import webdriver
from selenium.webdriver.common.keys
import Keysbot = webdriver.Chrome("chromedriver.exe")
bot.get('http://www.google.com')
search = bot.find_element_by_name('q')
search.send_keys("@codedev101")
search.send_keys(Keys.RETURN)
time.sleep(5)
bot.quit()
4.获取歌曲歌词
这个高级脚本将向你展示如何从任何歌曲中获取歌词。首先,你必须从 Lyricsgenius 网站获得免费的 API 密钥,然后,你必须遵循以下代码。
# pip install lyricsgenius
import lyricsgenius
api_key = "xxxxxxxxxxxxxxxxxxxxx"
genius = lyricsgenius.Genius(api_key)
artist = genius.search_artist("Pop Smoke",
max_songs=5,sort="title")
song = artist.song("100k On a Coupe")
print(song.lyrics)
5.获取照片的Exif数据
使用 Python Pillow 模块获取任何照片的 Exif 数据。查看下面提到的代码。我提供了两种方法来提取照片的 Exif 数据。
# Get Exif of Photo
# Method 1
# pip install pillow
import PIL.Image
import PIL.ExifTags
img = PIL.Image.open("Img.jpg")
exif_data =
{
PIL.ExifTags.TAGS[i]: j
for i, j in img._getexif().items()
if i in PIL.ExifTags.TAGS
}
print(exif_data)
# Method 2
# pip install ExifRead
import exifread
filename = open(path_name, 'rb')
tags = exifread.process_file(filename)
print(tags)
6.提取图像中的 OCR 文本
OCR 是一种从数字和扫描文档中识别文本的方法。许多开发人员使用它来读取手写数据,下面的 Python 代码可以将扫描的图像转换为 OCR 文本格式。
注意:你必须从 Github 下载 tesseract.exe
# pip install pytesseract
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
t=Image.open("img.png")
text = pytesseract.image_to_string(t, config='')
print(text)
7.将照片转换为Cartonize
这个简单的高级脚本会将你的照片转换为 Cartonize 格式。查看下面的示例代码并尝试一下。
# pip install opencv-python
import cv2
img = cv2.imread('img.jpg')
grayimg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
grayimg = cv2.medianBlur(grayimg, 5)
edges = cv2.Laplacian(grayimg , cv2.CV_8U, ksize=5)
r,mask =cv2.threshold(edges,100,255,cv2.THRESH_BINARY_INV)
img2 = cv2.bitwise_and(img, img, mask=mask)
img2 = cv2.medianBlur(img2, 5)
cv2.imwrite("cartooned.jpg", mask)
8.清空回收站
这个简单的脚本可以让你用 Python 清空你的回收站,查看下面的代码以了解如何操作。
# pip install winshell
import winshell
try:
winshell.recycle_bin().empty(confirm=False, /show_progress=False, sound=True)
print("Recycle bin is emptied Now")
except:
print("Recycle bin already empty")
9.Python 图像增强
使用 Python Pillow 库增强你的照片以使其看起来更好。在下面的代码中,我实现了四种方法来增强任何照片。
# pip install pillow
from PIL import Image,ImageFilter
from PIL import ImageEnhance
im = Image.open('img.jpg')
# Choose your filter
# add Hastag at start if you don't want to any filter below
en = ImageEnhance.Color(im)
en = ImageEnhance.Contrast(im)
en = ImageEnhance.Brightness(im)
en = ImageEnhance.Sharpness(im)# result
en.enhance(1.5).show("enhanced")
10.获取 Window 版本
这个简单的脚本将帮助你获得当前使用的完整窗口版本。
# Window Versionimport wmi
data = wmi.WMI()
for os_name in data.Win32_OperatingSystem():
print(os_name.Caption)
# Microsoft Windows 11 Home
11.将 PDF 转换为图像
使用以下代码将所有 Pdf 页转换为图像。
# PDF to Images
import fitz
pdf = 'sample_pdf.pdf'
doc = fitz.open(pdf)
for page in doc:
pix = page.getPixmap(alpha=False)
pix.writePNG('page-%i.png' % page.number)
12.转换:十六进制到 RGB
该脚本将简单地将 Hex 转换为 RGB。查看下面的示例代码。
# Conversion: Hex to RGB
def Hex_to_Rgb(hex):
h = hex.lstrip('#')
return tuple(int(h[i:i+2], 16) for i in (0, 2, 4))
print(Hex_to_Rgb('#c96d9d')) # (201, 109, 157)
print(Hex_to_Rgb('#fa0515')) # (250, 5, 21)
13.网站状态
你可以使用 Python 检查网站是否正常运行。检查以下代码,显示200 ,表示网站已启动,如果显示为 404 ,则表示网站已关闭。
# pip install requests
#method 1
import urllib.request
from urllib.request import Request, urlopenreq = Request('https://medium.com/@pythonians', headers={'User-Agent': 'Mozilla/5.0'})
webpage = urlopen(req).getcode()
print(webpage) # 200
# method 2
import requests
r = requests.get("https://medium.com/@pythonians")
print(r.status_code) # 200
祖传代码
这里再分享几段工作生活中常用的代码,都是最为基础的功能和操作,而且大多还都是出现频率比较高的,很多都是可以拿来直接使用或者简单修改就可以放到自己的项目当中
日期生成
很多时候我们需要批量生成日期,方法有很多,这里分享两段代码
获取过去 N 天的日期
import datetime
def get_nday_list(n):
before_n_days = []
for i in range(1, n + 1)[::-1]:
before_n_days.append(str(datetime.date.today() - datetime.timedelta(days=i)))
return before_n_days
a = get_nday_list(30)
print(a)
Output:
['2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26', '2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30', '2021-12-31', '2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04', '2022-01-05', '2022-01-06', '2022-01-07', '2022-01-08', '2022-01-09', '2022-01-10', '2022-01-11', '2022-01-12', '2022-01-13', '2022-01-14', '2022-01-15', '2022-01-16', '2022-01-17', '2022-01-18', '2022-01-19', '2022-01-20', '2022-01-21']
生成一段时间区间内的日期
import datetime
def create_assist_date(datestart = None,dateend = None):
# 创建日期辅助表
if datestart is None:
datestart = '2016-01-01'
if dateend is None:
dateend = datetime.datetime.now().strftime('%Y-%m-%d')
# 转为日期格式
datestart=datetime.datetime.strptime(datestart,'%Y-%m-%d')
dateend=datetime.datetime.strptime(dateend,'%Y-%m-%d')
date_list = []
date_list.append(datestart.strftime('%Y-%m-%d'))
while datestart<dateend:
# 日期叠加一天
datestart+=datetime.timedelta(days=+1)
# 日期转字符串存入列表
date_list.append(datestart.strftime('%Y-%m-%d'))
return date_list
d_list = create_assist_date(datestart='2021-12-27', dateend='2021-12-30')
d_list
Output:
['2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30']
保存数据到CSV
保存数据到 CSV 是太常见的操作了,分享一段我个人比较喜欢的写法
def save_data(data, date):
if not os.path.exists(r'2021_data_%s.csv' % date):
with open("2021_data_%s.csv" % date, "a+", encoding='utf-8') as f:
f.write("标题,热度,时间,url\n")
for i in data:
title = i["title"]
extra = i["extra"]
time = i['time']
url = i["url"]
row = '{},{},{},{}'.format(title,extra,time,url)
f.write(row)
f.write('\n')
else:
with open("2021_data_%s.csv" % date, "a+", encoding='utf-8') as f:
for i in data:
title = i["title"]
extra = i["extra"]
time = i['time']
url = i["url"]
row = '{},{},{},{}'.format(title,extra,time,url)
f.write(row)
f.write('\n')
带背景颜色的 Pyecharts
Pyecharts 作为 Echarts 的优秀 Python 实现,受到众多开发者的青睐,用 Pyecharts 作图时,使用一个舒服的背景也会给我们的图表增色不少
以饼图为例,通过添加 JavaScript 代码来改变背景颜色
def pie_rosetype(data) -> Pie:
background_color_js = (
"new echarts.graphic.LinearGradient(0, 0, 0, 1, "
"[{offset: 0, color: '#c86589'}, {offset: 1, color: '#06a7ff'}], false)"
)
c = (
Pie(init_opts=opts.InitOpts(bg_color=JsCode(background_color_js)))
.add(
"",
data,
radius=["30%", "75%"],
center=["45%", "50%"],
rosetype="radius",
label_opts=opts.LabelOpts(formatter="{b}: {c}"),
)
.set_global_opts(title_opts=opts.TitleOpts(title=""),
)
)
return c
requests 库调用
据统计,requests 库是 Python 家族里被引用的最多的第三方库,足见其江湖地位之高大!
发送 GET 请求
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'cookie': 'some_cookie'
}
response = requests.request("GET", url, headers=headers)
发送 POST 请求
import requests
payload={}
files=[]
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'cookie': 'some_cookie'
}
response = requests.request("POST", url, headers=headers, data=payload, files=files)
根据某些条件循环请求,比如根据生成的日期
def get_data(mydate):
date_list = create_assist_date(mydate)
url = "https://test.test"
files=[]
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'cookie': ''
}
for d in date_list:
payload={'p': '10',
'day': d,
'nodeid': '1',
't': 'itemsbydate',
'c': 'node'}
for i in range(1, 100):
payload['p'] = str(i)
print("get data of %s in page %s" % (d, str(i)))
response = requests.request("POST", url, headers=headers, data=payload, files=files)
items = response.json()['data']['items']
if items:
save_data(items, d)
else:
break
Python 操作各种数据库
操作 Redis
连接 Redis
import redis
def redis_conn_pool():
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
rd = redis.Redis(connection_pool=pool)
return rd
写入 Redis
from redis_conn import redis_conn_pool
rd = redis_conn_pool()
rd.set('test_data', 'mytest')
操作 MongoDB
连接 MongoDB
from pymongo import MongoClient
conn = MongoClient("mongodb://%s:%s@ipaddress:49974/mydb" % ('username', 'password'))
db = conn.mydb
mongo_collection = db.mydata
批量插入数据
res = requests.get(url, params=query).json()
commentList = res['data']['commentList']
mongo_collection.insert_many(commentList)
操作 MySQL
连接 MySQL
import MySQLdb
# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )
# 使用cursor()方法获取操作游标
cursor = db.cursor()
执行 SQL 语句
# 使用 execute 方法执行 SQL 语句
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取一条数据
data = cursor.fetchone()
print "Database version : %s " % data
# 关闭数据库连接
db.close()
Output:
Database version : 5.0.45
本地文件整理
整理文件涉及需求的比较多,这里分享的是将本地多个 CSV 文件整合成一个文件
import pandas as pd
import os
df_list = []
for i in os.listdir():
if "csv" in i:
day = i.split('.')[0].split('_')[-1]
df = pd.read_csv(i)
df['day'] = day
df_list.append(df)
df = pd.concat(df_list, axis=0)
df.to_csv("total.txt", index=0)
多线程代码
多线程也有很多实现方式,我们选择自己最为熟悉顺手的方式即可
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.delay, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
异步编程代码
异步爬取网站
import asyncio
import aiohttp
import aiofiles
async def get_html(session, url):
try:
async with session.get(url=url, timeout=8) as resp:
if not resp.status // 100 == 2:
print(resp.status)
print("爬取", url, "出现错误")
else:
resp.encoding = 'utf-8'
text = await resp.text()
return text
except Exception as e:
print("出现错误", e)
await get_html(session, url)
使用异步请求之后,对应的文件保存也需要使用异步,即是一处异步,处处异步
async def download(title_list, content_list):
async with aiofiles.open('{}.txt'.format(title_list[0]), 'a',
encoding='utf-8') as f:
await f.write('{}'.format(str(content_list)))
好了,这就是今天分享的全部内容,喜欢就点个赞吧~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【优质】「web开发网页制作」—html+css+js实现学校官网网页制作(带轮播效果5页面)【附源码】
- 电视盒子哪款好?年货节热销电视盒子品牌排行榜
- Spring Boot入门
- 正向代理和反向代理有什么区别?作为技术你知道吗
- Android逆向学习(六)绕过app签名校验,通过frida,io重定向(上)
- DDPM具体步骤
- FFMPEG解码实时流,支持cpu、gpu解码
- 长宁区科协常务副主席张正行一行到访深兰科技
- 第二十一章 网络编程
- 腾讯开源AppAgent,手机的大模型智能代理