【无标题】

Tags: Diagnosis Prediction
Authors: Chuanqi Tan, Songfang Huang, Zheng Yuan
Created Date: January 10, 2024 2:48 PM
Status: Reading
organization: Alibaba Group, Tsinghua University
publisher : ACL
year: 2022
code: https://github.com/ganjinzero/icd-msmn
paper: https://aclanthology.org/2022.acl-short.91.pdf
介绍
过去的工作通常使用标签注意力来匹配相关的文本片段。本文认为编码的同义词能提供更加丰富的信息,因为电子病历中的表达方式通常与ICD编码的描述不一致。因此作者将ICD编码与UMLS中的概念进行了对齐,并收集了一些同义词。
文中样例:编码244.9的icd描述为“Unspecified hypothyroidism “,但在电子病历中通常与”low t4“和“subthyroidism”相关。
方法
代码同义词
作者首先将ICD编码与UMLS中的医学概念进行对齐,然后从UMLS中选择相应的英文词汇的同义词,这些同义词具有相同的概念唯一标识符(CUIs),并通过去除连字符和“NOS”(Not Otherwise Specified)一词添加附加的同义词。
这里有个超参M,表示每个ICD编码有M个描述(包括原始描述)
编码
文中表示使用诸如BERT等预训练模型对提升最终性能没啥帮助,因此使用多层双向LSTM。
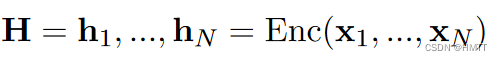
其中N为单词个数。
对于每个编码的同义词,作者使用相同编码器加上一个最大池化层来获取表示:
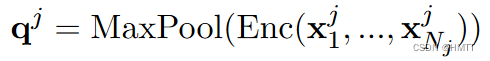
多同义词注意力(Multi-synonyms Attention)
为了增加文本与同义词的交互,作者提出了一种多同义词注意力。
首先设置超参M,即有M个同义词,将表示H分成M份:
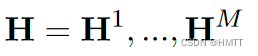
其中:
![]()
然后,将qj与Hj对应起来,求注意力得分αlj(l表示某个标签,j表示第j个同义词,α的维度为Nx1)。
再使用最大池化球的当前标签的特征(code-wise text representations)vl:
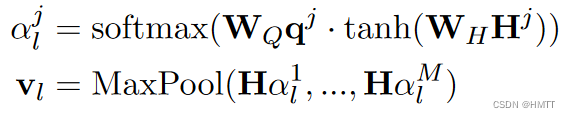
分类器
用同义词特征的最大池化作为编码表示,然后计算最终得分
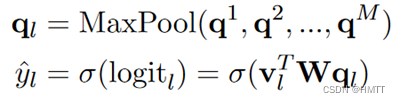
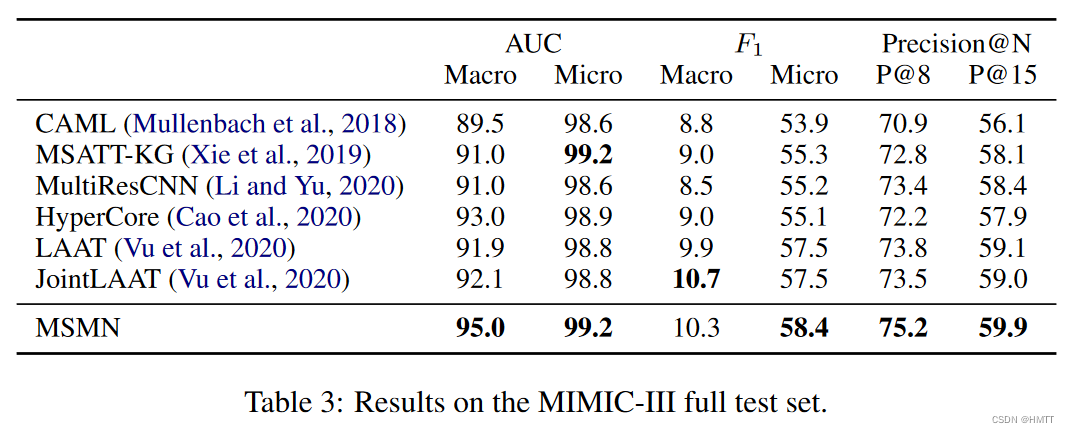
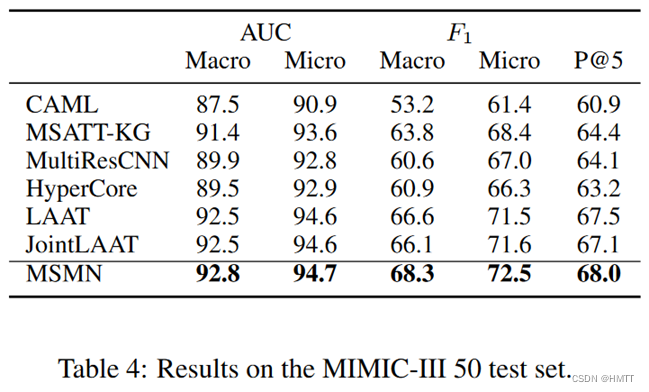
实验结果
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [软件工具][windows]yolov8自动标注工具自动打标签工具
- 1.10 实战:Postman生成在线接口文档
- vue3二次封装element-ui中的table组件
- 生成并压缩多个word文件,写入response
- NFC9180 LED三防平台灯50W
- 面试算法57:值和下标之差都在给定的范围内
- 翻译: LLMs新的工作流程和新的机会 New workflows and new opportunities
- 微信小程序嵌入H5页面,在H5页面中分享base64的pdf文件给微信好友
- MySQL数据库 约束
- 201.【2023年华为OD机试真题(C卷)】最长子字符串的长度(一)(滑动窗口算法-Java&Python&C++&JS实现)