机器学习系列12:减少过拟合——降维(特征选择)
对于不支持正则化的模型来说,我们可以通过降低数据的特征维度来减小模型复杂度,从而避免过拟合。
有两种降维方法:
-
特征选择(feature selection):从原始特征集中选择一部分特征子集。
-
特征抽取(feature extraction):从现有的特征集中抽取信息形成新的特征空间。
顺序特征选择是一种贪心算法,它通过自动选择与问题最相关的特征子集来提升计算效率,剔除不相关的特征或噪声数据来降低模型泛化误差(这对那些不支持正则化的算法来说非常有用)。最终将原始特征从 d 维降低到 k 维。
经典的特征选择算法是顺序反向选择(Sequential Backward Selection,SBS),它旨在通过牺牲一点点模型性能来降低原始数据集的特征维度。在某种程度上,SBS 可以提升过拟合模型的预测性能。
SBS 算法很简单:不断从原始的特征空间中移除特征,直到剩余的特征数达到既定的阈值。
我们需要定义一个判别函数来确定每次移除哪个特征。比如我们可以以移除某个特征之前和之后模型的性能差异作为判别指标。
在 scikit-learn 中实现了两种顺序特征选择算法:顺序反向选择(Sequential Backward Selection,SBS)和顺序前向选择(Sequential Forward Selection,SFS)。
SFS是一种从底向上的方法,第一个特征选择单独最优的特征,第二个特征从其余所有特征中选择与第一个特征组合在一起后表现最优的特征,后面的每一个特征都选择与已经入选的特征组合最优的特征。
scikit-learn 默认使用的是 SFS,所以我们需要指定方向参数为 direction='forward'。

我从 1 开始依次选择红酒数据集的全部 13 个特征,从下图可以看到当特征数量增加到 3 个之后,再增加特征数量模型在训练集上就不会再有明细的性能提升了。
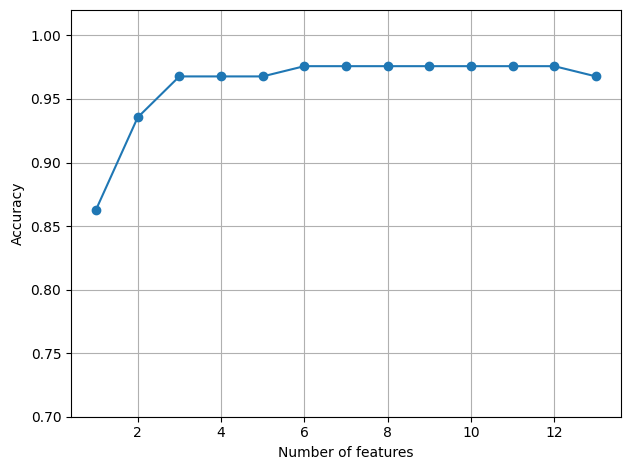
我们可以看是哪 3 个特征能产生这么好的贡献。

通过以下结果可以看到,模型在测试集上仅仅损失了一点点性能。
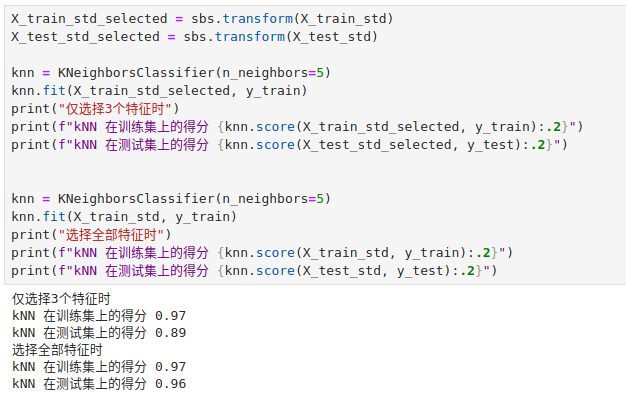
在实际工作中我们可以牺牲一点点泛化能力来节约大量的计算资源。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 乙级 1001 害死人不偿命的(3n+1)猜想
- FairyGUI-Cocos Creator官方Demo源码解读
- 深度学习第一课 TensorFlow2.0开发首选API - Keras
- 计算由CHON构成的分子的分子量
- 如何通过MT-Bench评估大模型
- 百模大战中的AI行业新趋势:技术、应用与变革的全方位剖析
- ZooKeeper 高级应用
- vue 使用js实现面包屑中实现右击菜单,并通过右击菜单的命令实现关闭其他、关闭左侧和关闭右侧的功能
- 不知道题目是啥
- 2023 年 10 款最佳 Windows 免费分区管理器软件