爬虫案例—表情党图片data-src抓取
发布时间:2024年01月13日
爬虫案例—表情党图片data-src抓取
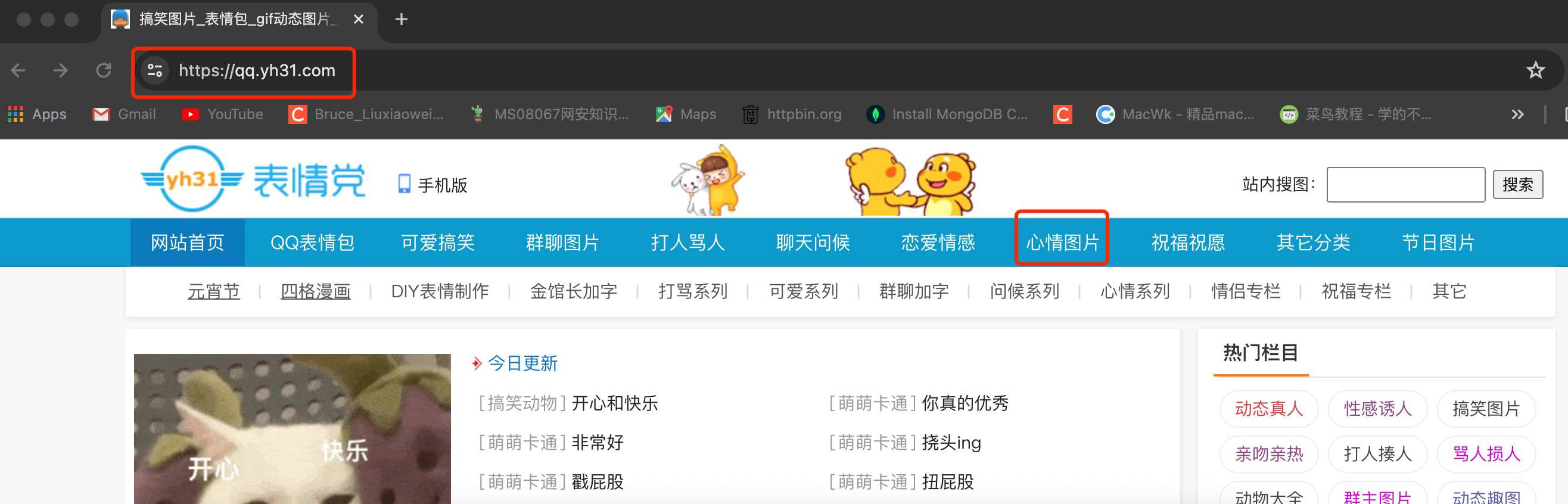
表情党网址:https://qq.yh31.com
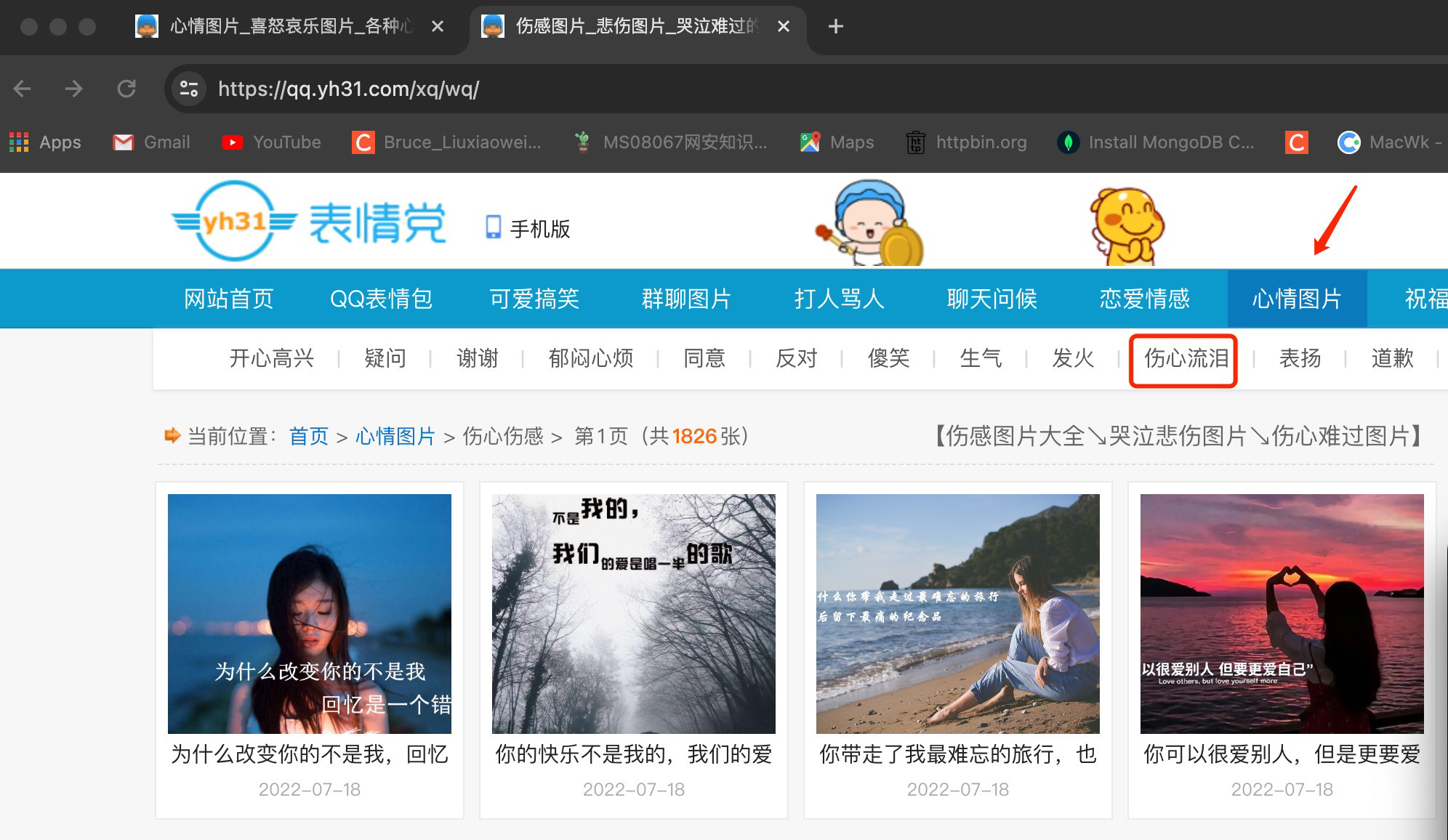
抓取心情板块的图片data-src
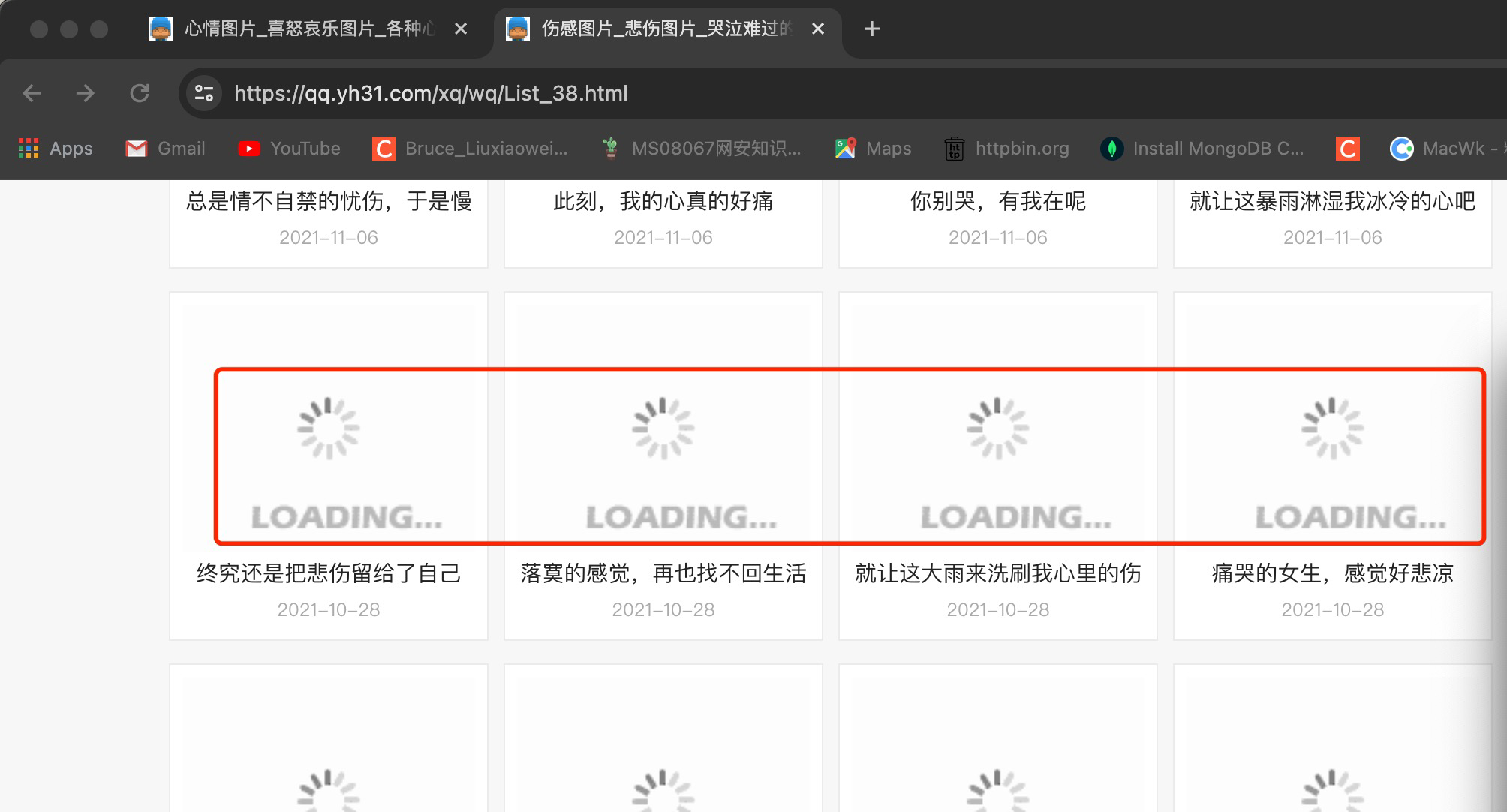
由于此页面采用的是懒加载技术,为了节省网络带宽和减轻服务器压力。不浏览的图片,页面不加载,统一显示LOADING…。如下图:
按F12(谷歌浏览器)通过分析,表情图片的真正链接为data-src
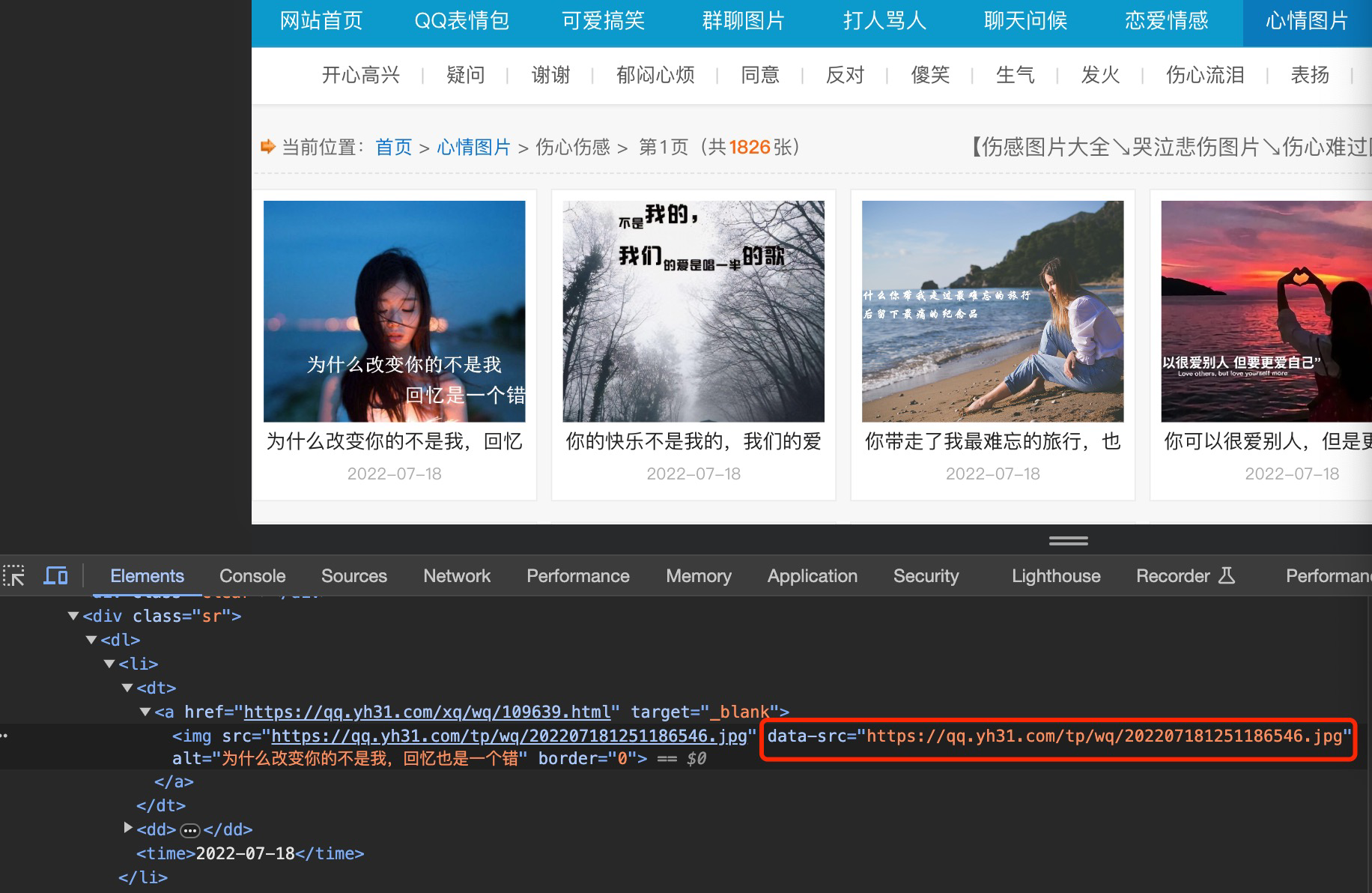
通过分析,在搜索框里输入如下的xpath路径,匹配到页面中所有的data-src,如下图:
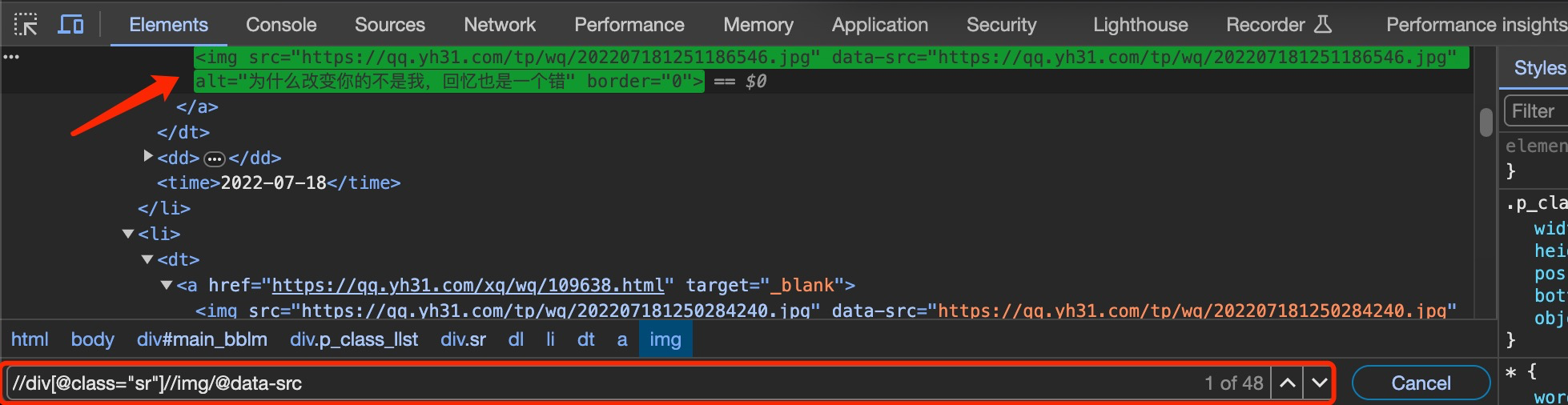
抓取data-src的源代码如下:
import requests
from lxml import etree
headers= {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
url = 'https://qq.yh31.com/xq/wq/'
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
data = res.text
tree = etree.HTML(data)
data_src_lst = tree.xpath('//div[@class="sr"]//dt/a/img/@data-src')
print(data_src_lst)
结果如下图:

文章来源:https://blog.csdn.net/weixin_41905135/article/details/135571771
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 银行家算法/Banker‘s Algorithm
- mapper.xml 使用 if else
- SylixOS 命令行下文件操作
- 2023我的编程之旅-地质人的山和水
- 【leetcode234】回文链表Java代码讲解
- 【视频图像篇】模糊图像处理之运动模糊造成的车牌号码图像模糊还原
- Android Google 开机向导定制 setup wizard
- 微信小程序---全局数据共享
- Github 2023-12-20 开源项目日报 Top10
- 反编译小程序